.png)
Técnicas de aprendizaje profundo para el resumen automático de textos




Introducción
Vivimos en un mundo en el que la disponibilidad de datos crece exponencialmente cada día. Nunca antes habíamos tenido que procesar tantos documentos de texto. Si bien los datos son una moneda muy poderosa, tener demasiados datos disponibles afecta directamente a nuestra capacidad de consumirlos. Como dice un viejo refrán:»demasiada información mata la información». Este problema se conoce comúnmente como sobrecarga de datos.
Tratar manualmente una cantidad tan gigantesca de información es una tarea sumamente abrumadora, lo que implica tener una enorme cantidad de tiempo y recursos destinados a ello. Además, dado que las nuevas fuentes de información se acumulan a diario, parece casi imposible hacer un seguimiento de los temas significativos y los puntos clave. ¿No sería fantástico poder extraer toda la información relevante sin tener que leer una lista interminable de documentos? Aquí es donde Resumen automático de texto (ATS) es útil 😉
Los resúmenes automáticos no solo reducen significativamente el tiempo de procesamiento y lectura, sino que también ayudan a descubrir de manera eficiente la información relevante y a consumirla más rápido. Además, en comparación con el rendimiento humano, los sistemas de resumen automáticos tienden a ser menos sesgados. El objetivo de esta publicación es presentar un recorrido por algunas técnicas de resumen abstracto de última generación y comprender sus principales desafíos.
¿Qué es ATS?
Como se mencionó anteriormente, Resumen automático de texto (ATS) proporciona una forma eficaz de resolver la sobrecarga de datos. Es un proceso de PNL que tiene como objetivo reducir la cantidad de texto de una entrada determinada y, al mismo tiempo, preservar su información más esencial y su significado contextual. Se centra en generar resúmenes concisos y legibles que contengan la información básica de un texto de entrada. En general, el ATS se divide en dos familias de técnicas: extractivo y abstractivo resumen.
Resumen extractivo consiste en seleccionar frases casi exactas del texto de entrada para crear el resumen final. Puede verse como un clasificador binario cuyo objetivo es decidir si se debe incluir o no la oración en el resumen. Estos enfoques son siempre consistentes con el documento fuente y no modifican el texto original. Por lo tanto, estos métodos suelen carecer de la capacidad de generar resúmenes fluidos y concisos.
Resumen abstracto por otro lado, tiene como objetivo generar un resumen conciso y completamente parafraseado a partir del texto de entrada, que capture su idea principal, a la vez que sea breve y fácil de leer. Al tener en cuenta toda la información proporcionada, los resumidores abstractos generan nuevas frases para captar la esencia del documento. Nos centraremos en estos modelos a lo largo del resto de esta publicación.
Resumen abstracto es una de las tareas más desafiantes de la PNL, ya que implica comprender segmentos largos, comprimir datos y generar texto. Se puede formular como secuencia a secuencia tarea en la que el texto de origen (entrada) se asigna al resumen de destino (salida). Los enfoques más recientes se basan en Transformadores, que consiste en un codificador-decodificador arquitectura.
¿Cómo podemos evaluar el rendimiento de nuestros modelos?
Evaluar la calidad del resumen no es una tarea sencilla. La necesidad de encontrar métricas automáticas adecuadas para calificar numéricamente la fidelidad de un resumen generado entran en juego dos tipos de métricas: las métricas sintácticas basadas en n-gramas, como COLORETE, y métricas semánticas basadas en incrustaciones contextuales como Puntuación de Bert.
COLORETE
COLORETE (Subestudio orientado a la revocación para la evaluación general) es un conjunto estándar de métricas de evaluación que se utilizan con frecuencia para las tareas de resumen. Su objetivo es evaluar la similitud entre los resúmenes generados por el modelo y los resúmenes anotados. Las puntuaciones ROUGE se dividen en las puntuaciones ROUGE-N, ROUGE-L y ROUGE-S.
- ROUGE-N: mide el número de N-gramas coincidentes entre los resúmenes de referencia y los de los candidatos.
- ROJO-L: mide las palabras de subsecuencia común más largas (LCS) entre los resúmenes de referencia y los de los candidatos. Cuando decimos LCS, nos referimos a los símbolos de palabras que están en secuencia, pero no necesariamente de forma consecutiva.
- ROJO-S: También conocida como métrica de concurrencia de saltos de gramo, es, con mucho, la puntuación ROUGE menos popular. Permite buscar palabras consecutivas del texto de referencia que aparecen en la salida del modelo pero que están separadas por una o más palabras.
Aunque COLORETE es una excelente métrica de evaluación, que tiene algunos inconvenientes. En particular, no tiene en cuenta diferentes palabras que tienen el mismo significado, ya que mide las coincidencias sintácticas en lugar de la semántica. Tampoco evalúa la fluidez, por lo que funciona mal en comparación con la evaluación humana. Veamos esto con más detalle a través de algunos ejemplos.
Supongamos que tenemos la siguiente frase escrita: «El veloz gato negro se subió al viejo roble». Y queremos compararlo con oraciones generadas de manera similar usando COLORETE métricas. Oración generada 1: «El gato se subió al roble».Rouge-1 Rouge-2 Rouge-LSemántica 80,0 46,2 80.0 Preciso
En este primer escenario, COLORETE da una buena indicación, ya que el resultado generado es semánticamente preciso y logra una puntuación alta.
Frase generada 2: «El veloz felino oscuro ascendió al árbol antiguo». Rouge-1Rouge-2Rouge-LSemantics 23,5 0,0 23.5 Preciso
En este segundo ejemplo, el resumen generado por la máquina es correcto desde el punto de vista fáctico, pero COLORETE la puntuación es en realidad muy baja y, por lo tanto, la califica erróneamente como un resumen mediocre.
Oración generada 3: «El rápido roble negro se metió en el viejo gato».
Rouge-1 Rouge-2 Rouge-LSemántica 100,0 62,5 77.8 Inexacto
En nuestro último escenario podemos ver cómo COLORETE podría dar erróneamente una puntuación alta a un resumen generado que claramente es incorrecto desde el punto de vista fáctico.
Puntuación BERT
Puntuación BERT es una métrica automática para la generación de texto. A diferencia de los métodos populares existentes (como ROUGE) que calculan la similitud sintáctica a nivel de token, BertScore se centra en la informática similitud semántica entre fichas de frases candidatas y de referencia incorporando incrustaciones contextuales. La idea principal que subyace a este enfoque es comprender primero el significado del texto generado y su referencia correspondiente, y luego realizar la comparación.
El método consiste en pasar los textos de referencia y candidatos a través de un modelo BERT previamente entrenado, a fin de generar incrustaciones contextuales para cada palabra. A esto le sigue un cálculo de similitud cosinusoidal por pares de cada una de las palabras partiendo de la referencia a cada una de las palabras del candidato.
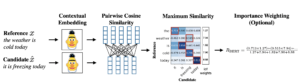
Diagrama de cálculo de la puntuación BERT extraído del artículo original [1]
La idea de estas métricas funciona bien sobre el papel, pero en realidad puede resultar engañosa, ya que la mayoría de las veces no reflejan la calidad real de la producción generada. La evaluación humana sigue siendo necesaria para evaluar el verdadero rendimiento del modelo del modelo.
Resumidores de secuencias cortas
Cuando se trata de documentos breves, los resumidores abstractivos más avanzados suelen basarse en un clásico Transformador arquitectura de tipos, combinación codificador-decodificador bloques con un mecanismo de autoatención para la generación de texto.
Transformers mecanismo de autoatención compara todos los elementos de una secuencia de entrada entre sí, mide su similitud para obtener ponderaciones y combina estas ponderaciones para obtener una salida. Por lo tanto, el algoritmo escala cuadráticamente con respecto al tamaño de la entrada. Si quieres familiarizarte más con cómo Transformadores obra que puede consultar a nuestra anterior correo para obtener más detalles.
Los ejemplos más comunes de resumidores abstractivos incluyen BART, PEGASO y T5, entre otros. Desde el punto de vista arquitectónico, estos modelos son muy parecidos, lo que suele cambiar son los objetivos utilizados en la formación previa. Por ejemplo, PEGASUS usa Generación de frases inexistentes mientras que BART usa transformaciones de relleno de texto y permutación de oraciones.
Hemos optado por usar T5 para ilustrar el rendimiento de este tipo de modelos.
Ejemplo de resumen con T5
Supongamos que queremos resumir lo siguiente noticias sobre la nueva adquisición de propiedades de Jeff Bezos en Manhattan. Para resumir este artículo de 300 palabras, hemos usado un texto grande versión del modelo T5 previamente entrenado en el conjunto de datos xSum y logra el siguiente resultado:
El fundador de Amazon, Jeff Bezos, compró un segundo apartamento en la ciudad de Nueva York, según la escritura presentada en la oficina de registros inmobiliarios y de propiedad de la ciudad. El acuerdo tiene un valor estimado de 16,8 millones de dólares.
Hasta ahora todo bien, al ejecutar el modelo T5 pudimos capturar con éxito la idea principal del artículo en solo unas pocas líneas.
Ahora, piense en la variedad de textos con los que tratamos a diario, como informes, encuestas, artículos, libros, etc. La mayoría de ellos se componen de documentos más largos que suelen tener mucha más varianza de datos internos y cambios de tema. Ahora, ¿qué pasa si tenemos textos de entrada más largos? ¿Podemos seguir usando el modelo T5 para resumir estos largos textos de entrada? Bueno, en realidad, debido a los mecanismos cuadráticos de autoatención, este tipo de modelos se limitan a secuencias cortas, normalmente de hasta 512 fichas.
Un enfoque simplista para abordar esta deficiencia podría ser dividir el texto de entrada en fragmentos de texto más pequeños. ¿Es esto efectivo? Los algoritmos de fragmentación controlan qué parte del documento más grande pasamos a un sumador en función del máximo de fichas permitido por el modelo. Los fragmentos más pequeños permiten comprender mejor cada fragmento, pero aumentan el riesgo de que la información contextual se divida.
Ejemplo con fragmentación
Supongamos que ahora queremos resumir esto pieza, que tiene alrededor de 1200 palabras. Para poder procesarlo, hemos dividido el texto en tres partes. El modelo T5 se ejecutó en cada fragmento y, a continuación, sus resultados se concatenaron, obteniendo el siguiente resultado:
Francia ha llegado a la final de la Copa del Mundo por primera vez en su historia, al derrotar a Marruecos por 2-0 en las semifinales del torneo en Doha, Qatar, el Viernes por la noche para organizar un enfrentamiento con Argentina y Brasil. Francia llegó a las semifinales de la Copa del Mundo por primera vez en su historia como Kylian Mbappé y Lionel Messi marcó un triplete de goles para enviar a su país a la final contra Argentina. El entrenador de Francia, Didier Deschamps, instó a sus jugadores a disfrutar del último partido del Mundial 2018 mientras se preparan para el último partido del domingo contra Argentina en Doha, Qatar, el domingo por la noche (julio de 2022).
También podríamos intentar volver a aplicar nuestro modelo al resultado para ver si podemos mejorar la narrativa y hacer que el texto sea más fluido.
Francia ha instado a sus jugadores a disfrutar del último partido del Copa Mundial 2018 mientras se preparan para la final del domingo contra Argentina en Doha, Qatar, el domingo por la noche (julio de 2022). Lea más sobre Didier Deschamps.
Es evidente que este enfoque no ha generado resultados precisos. Algunas relaciones contextuales se pierden durante la división. Además, implica un mayor tiempo de inferencia, ya que el modelo debe ejecutarse varias veces.
¿Hay una mejor manera de superar la restricción de longitud de entrada? Afortunadamente SÍ 😎
Resumidores de secuencias largas
Para poder procesar secuencias más largas, modelos como LED o T5 largo han modificado la arquitectura tradicional de los transformadores con una operación de autoatención que escala linealmente con la longitud de la secuencia. Ambos modelos utilizan estrategias similares; son capaces de combinar la atención local con la atención global mediante la aplicación de las siguientes técnicas:
LED se presentó en el documento Longformer: el transformador de documentos largos. Introduce un mecanismo de atención que combina atención local por ventana con atención global motivada por la tarea.
El mecanismo consta de tres partes principales:
- Ventana corredera: Emplea una ventana de atención de tamaño fijo alrededor de cada token. Con un tamaño de ventana fijo w, cada ficha tiene 1/2 w fichas en cada cara.
- Ventana corredera dilatada: La ventana deslizante se puede «dilatar», lo que significa que el núcleo se expande insertando huecos (de tamaño de dilatación d) entre sus elementos consecutivos. Esta técnica permite un campo receptivo mayor sin aumentar la computación.
- Atención global: Para ganar flexibilidad, se añade la «atención global» en algunos lugares preseleccionados. Este mecanismo es simétrico, es decir, un token con una atención global presta atención a todos los símbolos de la secuencia y todos los símbolos de la secuencia prestan atención a ella.
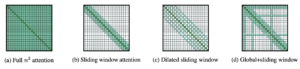
Mecanismos de atención LED [6]
Los LED son de larga duración puede gestionar secuencias 32 veces más grandes de lo que era posible anteriormente con la autoatención tradicional de los transformadores.
T5 largo extiende el original T5 codificador para gestionar entradas más largas de hasta ~16 000 fichas. Concretamente, el modelo integra los mecanismos de atención de los transformadores de entrada larga (ETCÉTERA), y estrategias previas a la capacitación a partir del resumen de la capacitación previa (PEGASO) en el T5 arquitectura.
Se presentaron dos variaciones del mecanismo de atención para T5 largo:
- Atención local: Sustituye la operación de autoatención del codificador en T5 con una escasa atención local por ventanas corredizas. Dado un radio local r, el algoritmo asigna r fichas a la izquierda y a la derecha de cada señal. El artículo sugiere usar r=127.
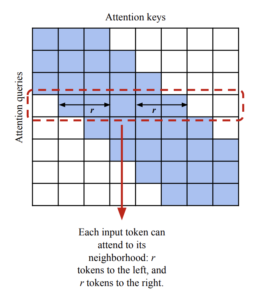
Mecanismo de atención local T5 largo [7]
- Atención global transitoria (tGlobal): Es una modificación de la atención global-local de ETC en un patrón de «bloques fijos». Divide la secuencia de entrada en bloques de k fichas y, para cada bloque, calcula una ficha global sumando (y luego normalizando) las incrustaciones de cada una de las fichas del bloque.
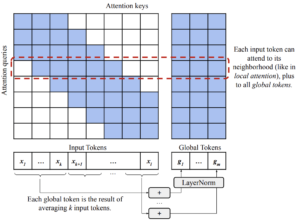
Mecanismo de atención global Long T5 T [7]
La siguiente tabla compara LED y Largo T5 en términos de tamaños de entrada y número de parámetros entrenables.
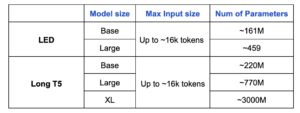
Veamos estos modelos en acción, ¿de acuerdo?
Modelos base
Ejemplo de base T5 larga: preentrenada en BookSum
El miércoles, Francia vence a Marruecos por 2-0 en el final para ganar el torneo por cuarta vez en cuatro años. Es la primera vez que un equipo africano llega a la final desde que ganó el oro en el mismo torneo en Rusia. Luego, el último día del torneo, se enfrentan a Argentina en la final.
Ejemplo de base LED: preentrenada en BookSum
Francia acaba con los sueños de Marruecos en la Copa Mundial 2022 con un 2-1 victoria en el estadio Al Bayt el miércoles. Se sentía como el cuartos de final se jugaba en otro lugar y no en Casablanca, que es donde se encuentra el equipo francés. Fue un poco decepcionante para Francia, que fue abucheada, silbada y, en general, ignorada por el público local. Sin embargo, Deschamps está contento con la forma en que su equipo ha acabado con las esperanzas de Marruecos. Les dice a su cuerpo técnico y a sus jugadores que disfruten del momento y de la ocasión.
Modelos de gran tamaño
Ejemplo: Long T5 large: preentrenado en PubMed
Durante el torneo de la Copa Mundial de 2022, Theo Hernández marcó a los cinco minutos con un final acrobático, con el suplente Ranal Kolo Muani tocando en casa tarde cuando Francia llegó a su cuarta final de la Copa del Mundo solo cuatro años después de ganar en Rusia. Sin embargo, Marruecos, el primer equipo africano en llegar a las semifinales de la Copa del Mundo, puede irse a casa con la cabeza bien alta después de superar a Francia por delante de Kolo.
Ejemplo: LED grande, preentrenado en BookSum
Francia acaba con el sueño de Marruecos de la Copa Mundial 2022 al derrotarlo 2-0 en las semifinales. El primer gol es el más rápido anotado por un suplente en la historia de la Copa Mundial, mientras que la segunda parte es de un solo sentido, ya que ambos equipos buscan el empate. Los Leones del Atlas no pudieron encontrar ninguno y, en el minuto final, el suplente Kolo Muani marcó su primer gol internacional. Francia se enfrentará a Lionel Messi y Argentina en la final del domingo.
De los ejemplos presentados anteriormente, hemos derivado las siguientes observaciones:
- En los modelos más grandes, la calidad de los resúmenes resultantes mejora considerablemente.
- LED grande los resultados mostraron una mejor narrativa, mientras que Largo T5 Grande parece ser más extractivo. Esto podría atribuirse en parte al hecho de que este último había recibido formación previa en el conjunto de datos de artículos médicos (PubMed) y no en libros.
- LED grande llegó a algunos detalles engañosos. Por ejemplo, la frase «El primer gol es el más rápido que haya marcado un suplente» no es exacta:
- De hecho, era el segundo gol: el que marcó un suplente
- Y este objetivo era, de hecho, el objetivo era el el tercero más rápido gol para un suplente
¿Qué pasa con el GPT-3?
Cuando se trata de modelos lingüísticos grandes (LLM), Transformador generativo preentrenado 3 (GPT-3) es una de las primeras cosas que nos vienen a la mente. Es uno de los modelos de transformadores más grandes disponibles que aprovecha el aprendizaje profundo para generar texto similar al humano. GPT-3 tiene aproximadamente 175 B de parámetros y ha sido entrenado con aproximadamente 45 TB de datos de texto de múltiples fuentes que cubren una amplia variedad de campos de aplicación. Puede gestionar secuencias de entrada muy largas (hasta 4096 fichas) y, naturalmente, gestiona grandes cantidades de varianza de datos.
Con el fin de evaluar más a fondo T5 largo y LED actuaciones, hemos seguido el mismo ejemplo en el Área de juegos GPT-3 y utilízalo como base.
Francia juega la final del Mundial contra Argentina. Francia ganó la última Copa del Mundo y está intentando convertirse en el primer equipo en ganar dos partidos seguidos desde que Brasil lo hizo hace 60 años. Los jugadores y el entrenador están disfrutando del éxito y quieren saborear el momento.
Del resultado presentado anteriormente, GPT-3 (text-da-vinci-003) claramente supera a ambos T5 largo y LED enfoques. Pero en realidad no se trata en absoluto de una comparación justa. El aprendizaje se produce en función de parámetros. A medida que aumenta el número de parámetros, el modelo adquiere un conocimiento más detallado y puede mejorar sus predicciones. GPT-3 tiene, de hecho, mil veces más parámetros que el Largo T5 y LED versiones que hemos probado. Por lo tanto, parece correcto que logre lograr, con mucho, un rendimiento mejor.
Reflexiones finales
Sin duda, todavía queda un largo camino por recorrer en términos de resumen automático de textos cuando se trata de documentos extensos. Estas son algunas de las principales conclusiones:
- Mientras GPT-3 domina este campo, el hecho de que no sea de código abierto anima a las personas a encontrar otras soluciones.
- LED y Largo T5 han demostrado ser capaces de producir resultados decentes teniendo en cuenta que tienen muchos menos parámetros que GPT-3.
- El tamaño del modelo importa. Como hemos observado, el rendimiento de nuestros modelos aumenta notablemente cuando pasamos de la versión básica a la versión grande. Los modelos más grandes logran una mejor narrativa y son capaces de reflejar las relaciones entre las entidades con mayor precisión. Sin embargo, los modelos más grandes exigen mayores recursos computacionales, lo que se traduce en costos más altos.
- El rendimiento del modelo es muy sensible al entrenamiento previo. Como se observa al comparar las versiones de PubMed y BookSum, el estilo narrativo y el rendimiento general del modelo se ven fuertemente afectados por los datos utilizados durante la fase previa al entrenamiento.
- La mayoría de las veces, las puntuaciones automáticas no reflejan realmente la calidad del resumen. Se recomienda la inferencia manual para evaluar el rendimiento del modelo.
Espero que hayas disfrutado de este post. ¡Estén atentos para más información!
Referencias
- [1] BertScore: Evaluación de la generación de texto con BERT
- [2] Reimplementación de ROUGE en Google Research
- [3] BART: Eliminación de ruido del entrenamiento previo de secuencia a secuencia para la generación, traducción y comprensión del lenguaje natural
- [4] PEGASUS: Entrenamiento previo con oraciones separadas extraídas para un resumen abstracto
- [5] Explorando los límites del aprendizaje por transferencia con un transformador unificado de texto a texto
- [6] Longformer: el transformador de documentos largos
- [7] LongT5: transformador eficiente de texto a texto para secuencias largas



.png)