.png)
Técnicas de aprendizado profundo para resumo automático de texto




Intro
Vivemos em um mundo em que a disponibilidade de dados cresce exponencialmente a cada dia. Nunca antes tivemos tantos documentos de texto para processar. Embora os dados sejam uma moeda muito poderosa, ter muitos dados disponíveis afeta diretamente nossa capacidade de consumi-los. Como diz um velho ditado,”muita informação mata informações”. Esse problema é comumente conhecido como sobrecarga de dados.
Lidar manualmente com uma quantidade tão gigantesca de informações é uma tarefa extremamente árdua, o que implica ter uma enorme quantidade de tempo e recursos destinados a ela. Além disso, à medida que novas fontes de informação se acumulam diariamente, acompanhar tópicos significativos e pontos-chave parece quase impossível. Não seria ótimo poder extrair todas as informações relevantes sem precisar ler uma lista interminável de documentos? Aqui é onde Sumarização automática de texto (ATS) é útil 😉
Os resumos automáticos não apenas reduzem significativamente o tempo de processamento e leitura, mas também ajudam a descobrir informações relevantes com eficiência e a consumi-las mais rapidamente. Além disso, quando comparados ao desempenho humano, os sistemas de resumo automático tendem a ser menos tendenciosos. O objetivo desta postagem é apresentar um passo a passo de algumas técnicas de resumo abstrativo de última geração e entender seus principais desafios.
O que é ATS?
Como mencionado anteriormente, Sumarização automática de texto (ATS) fornece uma maneira eficaz de resolver a sobrecarga de dados. É um processo de PNL que visa reduzir a quantidade de texto de uma determinada entrada, preservando suas informações mais essenciais e o significado contextual. Ele se concentra na geração de resumos concisos e legíveis contendo as principais informações de um texto de entrada. Geralmente, o ATS é dividido em duas famílias de técnicas: extrativo e abstrativo resumo.
Sumarização extrativa consiste em selecionar frases quase exatas do texto de entrada para criar o resumo final. Ele pode ser visto como um classificador binário cujo objetivo é decidir se deve ou não extrair a frase no resumo. Essas abordagens são sempre consistentes com o documento fonte e não modificam o texto original. Assim, esses métodos geralmente não têm a capacidade de gerar resumos fluentes e concisos.
Resumo abstrativo por outro lado, visa gerar um resumo completamente parafraseado e conciso do texto de entrada, capturando sua ideia principal, ao mesmo tempo em que é curto e fácil de ler. Ao levar em conta todas as informações fornecidas, os resumos abstrativos geram novas frases para capturar a essência do documento. Vamos nos concentrar nesses modelos no restante desta postagem.
Resumo abstrativo é uma das tarefas mais desafiadoras da PNL, pois envolve a compreensão de segmentos longos, compressão de dados e geração de texto. Pode ser formulado como sequência a sequência tarefa em que o texto de origem (entrada) é mapeado para o resumo de destino (saída). As abordagens mais recentes são baseadas em Transformadores, consistindo em um codificador-decodificador arquitetura.
Como podemos avaliar o desempenho de nossos modelos?
Avaliar a qualidade do resumo não é uma tarefa simples. Na necessidade de encontrar métricas automáticas adequadas para qualificar numericamente a fidelidade de um resumo gerado, dois tipos de métricas entram em jogo: métricas sintáticas baseadas em n-gramas, como VERMELHOe métricas semânticas baseadas em incorporações contextuais, como Bert Score.
VERMELHO
VERMELHO (Recall-Oriented Understudy for Gisting Evaluation) é um conjunto padrão de métricas de avaliação frequentemente usado para tarefas de resumo. O objetivo é avaliar a semelhança entre os resumos gerados pelo modelo e os resumos anotados. As pontuações ROUGE são ramificadas em pontuações ROUGE-N, ROUGE-L e ROUGE-S.
- ROUGE-N: mede o número de N-gramas correspondentes entre os resumos de referência e candidatos.
- ROUGE-L: mede as palavras de subseqüência comum mais longa (LCS) entre os resumos de referência e candidatos. Por LCS, nos referimos aos símbolos de palavras que estão em sequência, mas não necessariamente consecutivos.
- ROUGE-S: Também conhecida como métrica de concorrência de skip-gram, é de longe a pontuação menos popular do ROUGE. Ele permite pesquisar palavras consecutivas do texto de referência que aparecem na saída do modelo, mas são separadas por uma ou mais outras palavras.
Apesar VERMELHO é uma ótima métrica de avaliação, mas apresenta algumas desvantagens. Em particular, ele não leva em consideração palavras diferentes que tenham o mesmo significado, pois mede correspondências sintáticas em vez de semânticas. Ele também falha em avaliar a fluência e, portanto, tem um desempenho ruim em comparação com a avaliação humana. Vamos ver isso com mais detalhes por meio de alguns exemplos.
Suponha que tenhamos a seguinte frase escrita: “O rápido gato preto subiu no velho carvalho.” E queremos avaliá-lo em relação a frases geradas semelhantes usando VERMELHO métricas. Frase gerada 1: “O gato subiu no carvalho.”Semântica Rouge-1Rouge-2Rouge-LS 80,0 46,2 80.0Preciso
Nesse primeiro cenário, VERMELHO dá uma boa indicação, pois o resultado gerado é semanticamente preciso e atinge uma pontuação alta.
Frase gerada 2: “O rápido felino escuro subiu à árvore antiga.” Rouge-1rouge-2rouge-lsemantics 23,5 0,0 23.5 Preciso
Neste segundo exemplo, o resumo gerado pela máquina está factualmente correto, mas o VERMELHO a pontuação é, na verdade, muito baixa e, portanto, a qualifica erroneamente como um resumo medíocre.
Frase gerada 3: “O rápido carvalho preto entrou no velho gato.”
Semântica Rouge-1Rouge-2Rouge-LS 100,0 62,5 77.8 Impreciso
Em nosso último cenário, podemos ver como VERMELHO pode erroneamente dar uma pontuação alta a um resumo gerado que claramente está factualmente incorreto.
Pontuação BERT
Pontuação BERT é uma métrica automática para geração de texto. Ao contrário dos métodos populares existentes (como o ROUGE) que calculam a similaridade sintática em nível de token, o BertScore se concentra na computação semelhança semântica entre símbolos de frases candidatas e de referência, incorporando incorporações contextuais. A ideia principal subjacente a essa abordagem é primeiro entender o significado do texto gerado e sua referência correspondente e, em seguida, realizar a comparação.
O método consiste em passar textos de referência e candidatos por meio de um modelo BERT pré-treinado, a fim de gerar incorporações contextuais para cada palavra. Isso é seguido por um cálculo de similaridade cossenoidal de pares de cada uma das palavras a partir da referência a cada uma das palavras no candidato.
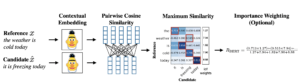
Diagrama de cálculo da pontuação BERT extraído do artigo original [1]
A ideia dessas métricas funciona bem no papel, mas, na realidade, pode ser enganosa, pois na maioria das vezes elas não refletem a qualidade real da saída gerada. A avaliação humana ainda é necessária para avaliar o verdadeiro desempenho do modelo.
Resumos de sequências curtas
Quando se trata de documentos curtos, resumos abstrativos de última geração geralmente são baseados em um clássico Transformador arquitetura de tipos, combinando codificador-decodificador blocos com um mecanismo de autoatenção para geração de texto.
Transformadores mecanismo de autoatenção compara todos os elementos de uma sequência de entrada entre si, mede sua semelhança para obter pesos e combina esses pesos para fornecer uma saída. Assim, o algoritmo escala quadraticamente em relação ao tamanho da entrada. Se você quiser se familiarizar mais com como Transformadores trabalho, você pode consultar nosso trabalho anterior publicar para obter mais detalhes.
Os exemplos mais comuns de resumos abstrativos incluem BART, PÉGASO e T5, entre outros. Arquitetonicamente, esses modelos são muito parecidos, o que geralmente muda são os objetivos usados no pré-treinamento. Por exemplo, o PEGASUS usa Geração de frases lacunas enquanto o BART usa transformações de preenchimento de texto e permutação de frases.
Nós escolhemos usar T5 para ilustrar o desempenho desses tipos de modelos.
Exemplo de resumo com T5
Suponha que queiramos resumir o seguinte notícias sobre a aquisição de uma nova propriedade por Jeff Bezos em Manhattan. Para resumir esse texto de 300 palavras, usamos um grande versão do modelo T5 pré-treinado no conjunto de dados xSum e obtenha o seguinte resultado:
Jeff Bezos, fundador da Amazon, comprou um segundo apartamento na cidade de Nova York, de acordo com a escritura registrada no escritório de registros imobiliários e imobiliários da cidade. O negócio vale cerca de 16,8 milhões de dólares.
Até aí tudo bem, ao executar o modelo T5, conseguimos capturar com sucesso a ideia principal do artigo em apenas algumas linhas.
Agora, pense na variedade de textos com os quais lidamos diariamente, como relatórios, pesquisas, artigos, livros e assim por diante. A maioria deles consiste em documentos mais longos que geralmente têm muito mais variação interna de dados e oscilações de tópico. Agora, o que acontece se tivermos textos de entrada mais longos? Ainda podemos usar o modelo T5 para resumir esses longos textos de entrada? Bem, na verdade, devido aos mecanismos quadráticos de autoatenção, esses tipos de modelos são limitados a sequências curtas, geralmente de até 512 tokens.
Uma abordagem simplista para resolver essa lacuna pode ser dividir o texto de entrada em pedaços menores de texto. Isso é eficaz? Os algoritmos de fragmentação controlam quanto do documento maior passamos para um resumido com base no máximo de tokens que o modelo permite. Pedaços menores permitem maior compreensão por bloco, mas aumentam o risco de divisão de informações contextuais.
Exemplo com fragmentação
Suponha que agora queiramos resumir isso peça, que tem cerca de 1200 palavras. Para poder processá-lo, dividimos o texto em três partes. O modelo T5 foi executado em cada bloco e suas saídas foram então concatenadas, chegando ao seguinte resultado:
A França chegou à final da Copa do Mundo pela primeira vez em sua história ao vencer Marrocos por 2 a 0 nas semifinais do torneio em Doha, Catar, em Sexta-feira à noite para marcar um confronto com Argentina e Brasil. A França chegou às semifinais da Copa do Mundo pela primeira vez em sua história como Kylian Mbappé e Lionel Messi marcou um hat-trick de gols para levar seu país à final contra a Argentina. O técnico da França, Didier Deschamps, pediu a seus jogadores que aproveitem a partida final da Copa do Mundo de 2018 enquanto se preparam para o jogo final de domingo contra a Argentina em Doha, Catar, na noite de domingo (julho de 2022).
Também podemos tentar reaplicar nosso modelo ao resultado para ver se podemos melhorar a narrativa e tornar o texto mais fluente.
A França exortou seus jogadores a aproveitarem a partida final do Copa do Mundo 2018 enquanto se preparam para a final de domingo contra a Argentina em Doha, Catar, na noite de domingo (Julho de 2022). Leia mais sobre Didier Deschamps.
Claramente, essa abordagem não gerou resultados precisos. Algumas relações contextuais são perdidas durante a divisão. Além disso, envolve maior tempo de inferência, pois o modelo precisa ser executado várias vezes.
Existe uma maneira melhor de superar a restrição de comprimento de entrada? Felizmente, SIM 😎
Resumos de sequência longa
Para poder processar sequências mais longas, modelos como CONDUZIU ou T5 longo modificaram a arquitetura tradicional de transformadores com uma operação de autoatenção que escala linearmente com o comprimento da sequência. Ambos os modelos usam estratégias semelhantes; eles são capazes de combinar a atenção local com a atenção global aplicando as seguintes técnicas:
CONDUZIU foi introduzido no jornal Longformer: O transformador de documentos longos. Ele introduz um mecanismo de atenção que combina atenção local com atenção global motivada por tarefas.
O mecanismo consiste em três partes principais:
- Janela deslizante: Ele emprega uma janela de atenção de tamanho fixo ao redor de cada token. Dado um tamanho de janela fixo w, cada token atende a tokens de 1/2w em cada lado.
- Janela deslizante dilatada: A janela deslizante pode ser “dilatada”, o que significa que o kernel é expandido inserindo espaços (de dilatação de tamanho d) entre seus elementos consecutivos. Essa técnica permite um campo receptivo maior sem aumentar a computação.
- Atenção global: Para obter flexibilidade, a “atenção global” é adicionada em alguns locais pré-selecionados. Esse mecanismo é simétrico, ou seja, um token com atenção global atende a todos os tokens da sequência e todos os tokens na sequência atendem a ele.
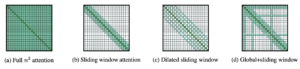
Mecanismos de atenção do LED [6]
LEDs Longformer pode lidar com sequências 32 vezes maiores do que o que era possível anteriormente com a autoatenção tradicional do transformador.
T5 longo estende o original T5 codificador para lidar com entradas mais longas de até 16k tokens. Especificamente, o modelo integra mecanismos de atenção de transformadores de entrada longa (ETC) e estratégias de pré-treinamento a partir do pré-treinamento resumido (PÉGASO) para o T5 arquitetura.
Duas variações do mecanismo de atenção foram apresentadas para T5 longo:
- Atenção local: Substitui a operação de autoatenção do codificador em T5 com uma escassa janela deslizante, atenção local. Dado um raio local r, o algoritmo atende aos tokens r à esquerda e à direita de cada token. O artigo sugere o uso de r = 127.
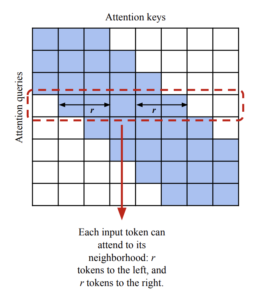
Mecanismo de atenção local T5 longo [7]
- Atenção global transitória (global): É uma modificação da atenção global-local da ETC em um padrão de “blocos fixos”. Ele divide a sequência de entrada em blocos de k tokens e, para cada bloco, calcula um token global somando (e depois normalizando) as incorporações de cada token no bloco.
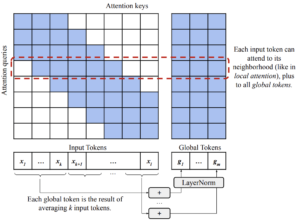
Mecanismo de atenção global Long T5 [7]
A tabela a seguir compara CONDUZIU e T5 longo em termos de tamanhos de entrada e número de parâmetros treináveis.
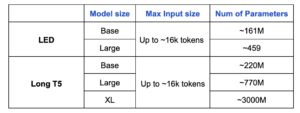
Vamos ver esses modelos em ação, não é?
Modelos básicos
Exemplo de base T5 longa - pré-treinada no BookSum
Na quarta-feira, a França venceu o Marrocos por 2 a 0 no final vencer o torneio pela quarta vez em quatro anos. É a primeira vez que uma equipe africana chega à final desde que ganhou o ouro no mesmo torneio na Rússia. Então, no último dia do torneio, eles enfrentam a Argentina na final.
Exemplo de base de LED - pré-treinada no BookSum
A França encerra os sonhos da Copa do Mundo de 2022 de Marrocos com um 2-1 vitória no estádio Al Bayt na quarta-feira. Parecia que o quartas de final estava sendo jogado em outro lugar, e não em Casablanca, que é onde a equipe francesa está localizada. Foi um pouco chato para a França, que foi vaiada, assobiada e geralmente ignorada pela torcida da casa. Mas Deschamps está feliz com a forma como sua equipe acabou com as esperanças de Marrocos. Ele diz à sua equipe e aos jogadores que aproveitem o momento e aproveitem a ocasião.
Modelos grandes
Exemplo: Long T5 large - pré-treinado no PubMed
Durante o torneio da copa do mundo de 2022, Theo Hernández marcou aos cinco minutos com uma finalização acrobática, com o substituto Ranal Kolo Muani batendo em casa tarde, quando a França chegou à quarta final da Copa do Mundo, apenas quatro anos depois de vencer na Rússia. Mas Marrocos, a primeira seleção africana a chegar à fase semifinal da copa do mundo, pode voltar para casa com a cabeça erguida depois de correr contra a França antes de Kolo.
Exemplo de LED grande - pré-treinado no BookSum
A França encerra o sonho de Marrocos na Copa do Mundo de 2022 ao derrotá-los por 2 a 0 nas semifinais. O gol de abertura é o mais rápido já marcado por um substituto na história da Copa do Mundo, enquanto o segundo tempo é um tráfego de mão única, pois as duas equipes pressionam pelo empate. O Atlas Lions não conseguiu encontrar um e, no último minuto, o substituto Kolo Muani marcou seu primeiro gol internacional. A França enfrentará Lionel Messi e a Argentina na final de domingo.
A partir dos exemplos apresentados acima, derivamos as seguintes observações:
- Em modelos maiores, a qualidade dos resumos resultantes é amplamente aprimorada.
- LED grande os resultados mostraram uma melhor narrativa, enquanto Longo T5 Grande parece ser mais extrativo. Isso pode ser parcialmente atribuído ao fato de que o último foi pré-treinado no conjunto de dados de artigos médicos (PubMed) e não em livros.
- LED grande chegou a alguns detalhes enganosos. Por exemplo, a frase “O gol de abertura é o mais rápido já marcado por um substituto” não é precisa:
- Na verdade, foi o segundo gol aquele que foi marcado por um substituto
- E esse objetivo era, de fato, o objetivo era o terceiro mais rápido gol para um substituto
E quanto ao GPT-3?
Quando se trata de modelos de linguagem grande (LLMs), Transformador generativo pré-treinado 3 (GPT-3) é uma das primeiras coisas que vem à nossa mente. É um dos maiores modelos de transformadores disponíveis, aproveitando o aprendizado profundo para gerar texto semelhante ao humano. GPT-3 tem ~ 175 B de parâmetros e foi treinado com cerca de 45 TB de dados de texto de várias fontes, cobrindo uma grande variedade de campos de aplicação. Ele pode lidar com sequências de entrada muito longas (até 4096 tokens) e gerencia naturalmente grandes quantidades de variação de dados.
A fim de avaliar melhor T5 longo e CONDUZIU performances, executamos o mesmo exemplo no Parque infantil GPT-3 e use isso como nossa linha de base.
A França está jogando na final da Copa do Mundo contra a Argentina. A França venceu a última Copa do Mundo e está tentando se tornar a primeira equipe a vencer duas vezes consecutivas desde que o Brasil venceu há 60 anos. Os jogadores e o técnico estão curtindo o sucesso e querem saborear o momento.
A partir do resultado apresentado acima, GPT-3 (text-da-vinci-003) claramente supera ambos T5 longo e CONDUZIU abordagens. Mas essa não é realmente uma comparação justa. O aprendizado acontece com base em parâmetros. À medida que o número de parâmetros aumenta, o modelo ganha mais conhecimento granular e é capaz de melhorar suas previsões. GPT-3 tem, na verdade, mil vezes mais parâmetros do que o T5 longo e CONDUZIU versões que testamos. Portanto, parece certo que ele consiga alcançar um desempenho muito melhor.
Considerações finais
Certamente, ainda há um longo caminho a percorrer em termos de resumo automático de texto quando se trata de documentos longos. Aqui estão algumas das principais conclusões:
- Enquanto GPT-3 domina esse campo, o fato de não ser de código aberto incentiva as pessoas a encontrarem outras soluções.
- CONDUZIU e T5 longo demonstraram ser capazes de produzir resultados decentes, considerando que têm muito menos parâmetros do que GPT-3.
- O tamanho do modelo é importante. Como observamos, o desempenho de nossos modelos aumenta notoriamente quando mudamos das versões básicas para as grandes. Modelos maiores alcançam uma narrativa melhor e são capazes de refletir os relacionamentos entre entidades com mais precisão. No entanto, modelos maiores demandam maiores recursos computacionais, o que se traduz em custos mais altos.
- O desempenho do modelo é muito sensível ao pré-treinamento. Conforme observado ao comparar as versões PubMed e BookSum, o estilo narrativo e o desempenho geral do modelo são fortemente afetados pelos dados usados durante a fase de pré-treinamento.
- Na maioria das vezes, as pontuações automáticas não refletem verdadeiramente a qualidade do resumo. A inferência manual é recomendada para avaliar o desempenho do modelo.
Espero que você tenha gostado desse post. Fique ligado para saber mais!
Referências
- [1] BertScore: Avaliando a geração de texto com o BERT
- [2] Reimplementação do ROUGE pelo Google Research
- [3] BART: Pré-treinamento de eliminação de ruído de sequência a sequência para geração, tradução e compreensão de linguagem natural
- [4] PEGASUS: Pré-treinamento com frases de lacunas extraídas para resumo abstrativo
- [5] Explorando os limites do aprendizado por transferência com um transformador unificado de texto para texto
- [6] Longformer: O transformador de documentos longos
- [7] LongT5: Transformador eficiente de texto para texto para sequências longas



.png)