.png)
Estado del arte de la clonación de voz: una reseña




Introducción
Prepárate para explorar los últimos avances en la tecnología de clonación de voz con esta revisión exhaustiva de los avances más recientes. En este blog, profundizaremos en el estado actual de la tecnología de clonación de voz, incluidas las investigaciones y los desarrollos más avanzados en este campo. También analizaremos las posibles aplicaciones y las consideraciones éticas de la clonación de voz, así como los desafíos que aún deben abordarse para mejorar las implementaciones disponibles. Por último, vamos a explorar Tortoise: una herramienta específica para la clonación de voz. Si eres investigador, desarrollador o simplemente estás interesado en las tendencias actuales de la tecnología, este blog es para ti. Así que únete a nosotros para explorar el fascinante mundo de la clonación de voz.
¿Qué es la clonación de voz?
La clonación de voz se refiere al proceso de creación de una voz sintética que es casi idéntica a una voz humana real. A diferencia de la síntesis de voz, que genera un discurso realista con voces predefinidas, la tecnología de clonación de voz es capaz de reproducir la voz, el tono y las inflexiones únicos de una persona.
Texto: Este es un ejemplo de lo que se puede hacer con la clonación de voz y en qué se diferencia de la síntesis de voz.
¿Por qué es relevante?
Esta tecnología es relevante por varios motivos. En primer lugar, tiene el potencial de revolucionar la forma en que interactuamos con la tecnología. Con la clonación de voz, podríamos crear asistentes virtuales, chatbots y otros dispositivos con capacidad de voz realistas y parecidos a los humanos. Esto significa que podemos mantener conversaciones más naturales y atractivas con estos dispositivos, lo que los hace más fáciles y agradables de usar.
Además, esta tecnología puede ser utilizada por personas con problemas o discapacidades del habla. Esto podría permitirles crear voces sintéticas que se parezcan mucho a sus voces naturales, mejorando su capacidad de comunicarse de manera efectiva. Además, la clonación de voces se puede utilizar para preservar las voces de las personas que corren el riesgo de perderlas debido a afecciones médicas. Por último, esta tecnología tiene implicaciones para las industrias del entretenimiento y los medios de comunicación. En particular, permitirá crear voces en off más realistas y convincentes para películas, videojuegos y más.
En resumen, la clonación de voz tiene el potencial de mejorar la calidad de vida de muchas personas, mejorar la experiencia del usuario con la tecnología y crear nuevas posibilidades en diversas industrias.
Implicaciones éticas en torno a la clonación de voz
El desarrollo de la tecnología de clonación de voz plantea preocupaciones éticas en torno a cuestiones relacionadas con el consentimiento y la identidad. La obtención del consentimiento es una consideración importante, ya que es posible que no siempre quede claro si las personas han dado su consentimiento para que se utilice su voz. Es necesario establecer directrices claras sobre la obtención del consentimiento para la clonación de voz para garantizar que las personas tengan derecho a controlar el uso de su voz.
Además, una voz sintética se puede usar para hacerse pasar por personas y causar daño cuando es indistinguible de una voz real. Por lo tanto, para evitar el uso indebido de la tecnología de clonación de voz, se deben establecer algunas regulaciones. Al abordar estas consideraciones éticas, podemos garantizar que se aprovechen los beneficios potenciales de la tecnología de clonación de voz y, al mismo tiempo, minimizar los posibles riesgos y daños.
Estado del arte
El estado del arte avanza rápidamente, por lo que es difícil mantenerse al día. A continuación se presenta una descripción general de algunos de los últimos artículos más relevantes que querrá conocer.
ZSE-VITS: un método de clonación de voz expresiva sin ningún tipo de disparo basado en VITS - Febrero de 2023
Este es un método novedoso que se basa en el modelo de síntesis de voz de extremo a extremo, el codificador automático variacional condicional con aprendizaje contradictorio para conversión de texto a voz (VITS) de extremo a extremo. La base de la arquitectura propuesta es el modelo VITS y, como codificador de altavoces, se añade el modelo de reconocimiento de altavoces TitaNet, que permite la clonación sin necesidad de hacer nada. El modelo supera a las arquitecturas anteriores en cuanto a la similitud de timbre entre los altavoces visibles e invisibles, y mejora la expresividad y la capacidad de control de la prosodia en la voz clonada. El siguiente diagrama muestra el proceso completo del modelo propuesto. Este sistema toma como entrada un espectrograma mel de referencia que contiene la prosodia deseada, los fonemas del texto a generar y el audio de referencia del sujeto a clonar. Luego, como salida, genera un archivo de audio en el que la voz objetivo pronuncia el texto deseado con la prosodia deseada.
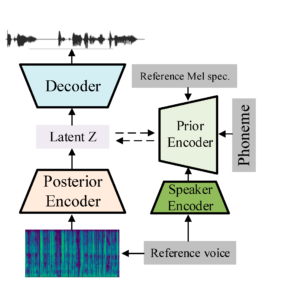
Estructura general del modelo propuesto.
Los modelos de lenguaje de códecs neuronales son sintetizadores de texto a voz de tiro cero - Enero de 2023
Este modelo también se conoce como VALL-E y fue construido por el equipo de Microsoft. Junto con el artículo, los autores publicaron una demostración de los resultados obtenidos en este enlace. Lo más destacado de este sistema es que puede generar voz de alta calidad con solo una grabación de 3 segundos. Esto ha establecido un récord en cuanto a la cantidad de tiempo requerida para la clonación de voz. Además, la calidad parece sobresaliente. Además, VALL-E supera a los sistemas Zero-Shot de última generación en términos de naturalidad del habla y similitud de los hablantes. Otro punto a destacar es que preserva la emoción del orador y el entorno acústico de la grabación de 3 segundos. A continuación se presenta una descripción general del sistema del modelo VALL-E. Toma como entrada el mensaje de texto y la grabación de 3 segundos y emite la voz clonada.
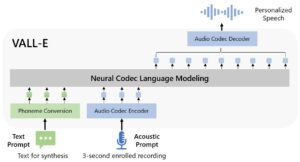
Descripción general del sistema de clonación de voz propuesto.
TTS multilingüe de bajos recursos y con varios altavoces sin disparos - Octubre de 2022
En este trabajo, se combinan las tareas de la clonación inmediata y la conversión de texto a voz (TTS) multilingüe de bajos recursos. Los autores intentaron evaluar si esta última opción se puede utilizar para lograr la primera en un escenario de bajos recursos. Además, su objetivo era demostrar que es posible que un sistema aprenda un nuevo idioma con solo 5 minutos de datos de entrenamiento sin perder la capacidad de clonar las voces de hablantes desconocidos. Esto es importante porque la cantidad de datos necesaria para los enfoques anteriores generalmente no era factible para la gran mayoría de los idiomas del mundo.
Para lograr todo esto, propusieron cambios en un codificador TTS para gestionar mejor los datos multilingües y separar los idiomas de los hablantes. Además, demostraron que el procedimiento previo al aprendizaje del metaaprendizaje (LAML, por sus siglas en inglés), independiente del lenguaje, se puede utilizar para formar modelos condicionados por hablantes generalistas. La idea básica de LAML es tratar los diferentes lenguajes como tareas independientes y refinar de forma iterativa un punto de inicialización que sea adecuado para todas las tareas del entrenamiento. Esto lo haría adecuado para tareas invisibles (es decir, idiomas o voces invisibles en la fase de prueba). Lo importante de este documento es que el uso de este procedimiento previo a la formación podría sentar las bases para futuros sistemas multilingües y multilingües de alta calidad y bajos recursos.
Por último, los autores proporcionaron un conjunto de herramientas para la enseñanza, la capacitación y el uso de modelos de síntesis de voz llamado Tucán.
Tortoise: una herramienta disponible que produce buenos resultados
Tortuga, lanzado en abril de 2022, es un programa de TTS que tiene la capacidad de imitar voces basándose en entre 2 y 4 ejemplos dados. Está compuesto por 5 redes neuronales entrenadas de forma independiente y luego combinadas para generar el resultado final. En particular, se utiliza una combinación de decodificadores autorregresivos y modelos probabilísticos de difusión y reducción de ruido (DDPM), ya que los autores creen que, cuando se les plantea el problema de generar datos continuos, estos modelos tienen algunas ventajas evidentes. La arquitectura completa se basó en un conjunto de datos con aproximadamente 49 000 horas de audio, que tardó casi un año en completarse.
Las principales ventajas de esta herramienta son que sus resultados tienen una buena calidad de sonido y es de código abierto. Además, se proporciona un Jupyter Notebook fácil de usar junto con el completo implementación. Este código permite a cualquier persona usar este marco para clonar cualquier voz y sintetizar el habla. Sin embargo, este cuaderno no puede sintetizar textos largos ya que la implementación requiere una gran cantidad de espacio. Por lo tanto, utilizamos otro código para probar este marco. Este segundo código puede sintetizar textos grandes dividiéndolos en oraciones y concatenando los resultados de cada oración.
¿Qué tan bien funciona?
Para empezar a evaluar el rendimiento del modelo, queríamos realizar una clonación de voz para varios altavoces. Para ello, generamos una voz clonada para 4 altavoces. Primero les pedimos que grabaran frases específicas generando 4 archivos de audio que oscilaban entre 6 y 15 segundos por altavoz. Luego, estos audios se usaron como entrada para el sistema. Finalmente, generamos varios textos con la voz clonada. Ahora presentaremos una comparación entre los resultados y la verdad básica.
Texto 1: La inteligencia artificial se ha vuelto cada vez más importante en el mundo actual porque permite a las máquinas realizar tareas que normalmente requieren inteligencia humana.
En general, el audio generado tiene muy buena calidad, aunque en ocasiones carece de expresividad. En ocasiones, el audio incluye respiraciones en lugares apropiados dentro de las oraciones. Sin embargo, hay ocasiones en las que los resultados tienen pausas inadecuadas. Esto suele ocurrir cuando los audios utilizados para la clonación contienen pausas mal colocadas. En cuanto a la entonación, es correcta en algunos casos, pero en otros es un poco plana. Los resultados también muestran que la pronunciación en inglés de cada individuo no está clonada. Además, el audio generado puede incluir ruidos extraños, como es el caso del altavoz 2 con el texto 2.
Texto 2: Esta tecnología tiene el potencial de revolucionar las industrias y mejorar muchos aspectos de nuestras vidas, como la atención médica, el transporte y la educación.
Hay casos en los que la voz clonada puede sonar robótica, como es el caso del altavoz 2 con el texto 3. En general, aunque el audio generado no es perfecto, permite a cualquier usuario clonar una voz objetivo con poco audio y proporciona buenos resultados.
Texto 3: El gato dormía plácidamente en el alféizar de la ventana, disfrutando del calor del sol.
¿Puede generar frases largas?
Al generar oraciones más largas, a veces el resultado puede contener palabras repetidas, esto sucedió con el orador 2 con el texto 4.
Texto 4: El color del cielo aparece azul durante el día debido a la forma en que la atmósfera terrestre dispersa la luz solar. La luz azul se dispersa más que otros colores debido a su longitud de onda más corta, lo que la hace más visible para el ojo humano. A medida que el sol se pone o sale, la luz debe atravesar una mayor parte de la atmósfera, dispersando más luz azul y permitiendo que se vean más rojos y naranjas, lo que da como resultado un cielo colorido.
¿Qué pasa con la producción de texto en otros idiomas?
Como el modelo estaba entrenado en inglés, queríamos probar el rendimiento del sistema con audio en otro idioma. Para ello, lo alimentamos con 4 archivos de audio en español y luego sintetizamos otros textos en español e inglés.
Texto 5: La luz del sol ilumina suavemente el paisaje, creando sombras y reflejos en las hojas de los árboles y en el agua del río cercano.
Texto 6: El color del cielo aparece azul durante el día debido a la forma en que la atmósfera terrestre dispersa la luz solar. La luz azul se dispersa más que otros colores debido a su longitud de onda más corta, lo que la hace más visible para el ojo humano. A medida que el sol se pone o sale, la luz debe atravesar una mayor parte de la atmósfera, dispersando más luz azul y permitiendo que se vean más rojos y naranjas, lo que da como resultado un cielo colorido.
Estos resultados muestran que Tortoise no puede generar texto en otros idiomas. En particular, el discurso generado a veces no se pronuncia correctamente y la mayoría de las veces no tiene sentido alguno. Sin embargo, cuando se entrena con un hispanohablante, es capaz de clonar la voz objetivo y generar el discurso en inglés. A partir de esto, llegamos a la conclusión de que, aunque Tortoise no puede generar texto en otros idiomas, puede usarse para generar audio con una voz objetivo en un idioma que el sujeto no hable.
¿Cuánto tiempo lleva generar un audio?
El autor informó de una proporción de 1 a 10 entre la duración del audio generado y el tiempo de generación. Para verificar esta afirmación, realizamos varias pruebas para generar audio con diferentes duraciones. A partir de esto, descubrimos que la afirmación es cierta, el sistema es bastante lento. Esto hace que no sea apto para aplicaciones en tiempo real y, sin duda, justifica el nombre del marco.
Desafíos actuales
La tecnología de clonación de voz ha logrado avances significativos en los últimos años, pero aún quedan algunos desafíos técnicos por abordar. Uno de los principales desafíos es la capacidad de generar voz sintetizada de alta calidad que suene natural y similar a la humana. Si bien los modelos actuales han mostrado resultados prometedores, todavía hay margen de mejora.
Otros desafíos incluyen la necesidad de grandes cantidades de datos de entrenamiento para desarrollar clones de voz precisos y confiables. Los modelos de clonación de voz requieren grandes conjuntos de datos (miles de horas) de grabaciones de alta calidad para conocer las características únicas de la voz de una persona. Sin embargo, obtener estos conjuntos de datos puede llevar mucho tiempo y ser caro, especialmente para clonar a personas sin datos disponibles.
Otro desafío en este campo es el tema de la variabilidad de los hablantes. Los modelos de clonación de voz generalmente se entrenan con la voz de un solo hablante. Esto puede limitar su capacidad para clonar con precisión otros altavoces con diferentes patrones de voz y acentos. Para abordar este problema, los investigadores están explorando técnicas como el entrenamiento con varios hablantes y la adaptación de dominios.
Por último, la cuestión de la clonación de voz en tiempo real sigue siendo un desafío. Si bien los modelos actuales pueden generar voz sintetizada de alta calidad, todavía no son capaces de producirla en tiempo real. Esto limita sus posibles casos de uso en aplicaciones como los asistentes de voz y los chatbots. Abordar estos desafíos técnicos será crucial para el avance continuo y la adopción generalizada de esta tecnología.
Otras alternativas de clonación de voz
Para ahorrarle tiempo, aquí hay otros recursos que no se mencionan en este artículo con los que puede tropezar.
Alternativas de código abierto
- Discurso de pádel: Kit de herramientas de código abierto en la plataforma PaddlePaddle para una variedad de tareas críticas de voz y audio. En el GitHub de la biblioteca, descubrimos que el código proporcionado no es de principio a fin.
- Coqui TTS: Se describe como una biblioteca para la generación avanzada de conversión de texto a voz. Sin embargo, los audios resultantes tienden a sonar ruidosos, con interrupciones antinaturales en la voz y un sonido metálico. Haga clic aquí para encontrar la demo del autor.
- HuggingFace: Se pueden encontrar varias demostraciones de clonación de voz de diferentes autores. Estas implementaciones no se acercan al rendimiento alcanzado por Tortoise. Se pueden encontrar algunos ejemplos en los siguientes enlaces: Enlace 1, Enlace 2.
Implementaciones privadas
- Aprendizaje autosupervisado para una clonación de voz sólida: Este artículo presenta un algoritmo que se puede entrenar en un conjunto de datos sin etiquetar con cualquier número de hablantes. Los resultados presentados se aproximan al rendimiento básico de los altavoces con funciones previamente entrenadas en las tareas de verificación de altavoces. Los autores no han proporcionado ninguna implementación hasta la fecha.
- Clonación de voz de formato largo sin disparo con atención de convolución dinámica: El modelo propuesto en este artículo se basa en el Tacotron 2 y utiliza un mecanismo de atención basado en la energía (atención de convolución dinámica) combinado con un conjunto de modificaciones para el sintetizador del Tacotron 2. Los autores concluyeron que el modelo propuesto puede producir un discurso sintético inteligible, preservando al mismo tiempo la naturalidad y la similitud. No encontramos ningún código para este marco durante el curso de esta investigación.
- Estudio NVIDIA Riva: Le permite clonar voces utilizando solo 30 minutos de grabaciones de audio sin ningún tipo de código. Sin embargo, esta herramienta aún se encuentra en una fase de acceso anticipado y su uso está limitado a los desarrolladores que trabajan en la conversión de texto a voz.
Servicios de pago
- Se parecen a la IA: Su generador de voz afirma generar voces en off similares a las humanas en segundos y te permite clonar tu voz de forma gratuita. Ten en cuenta que tardaron más de 3 semanas en generar una voz con la prueba gratuita. El proceso de clonación de voz se basa inicialmente en 25 grabaciones de audio de la voz objetivo con texto predefinido. También proporcionan una alternativa de pago que permite a los usuarios mejorar la voz clonada añadiendo más muestras de audio. Además, recientemente se agregó un marco de clonación rápida de voz a partir de solo 10 segundos de audio de referencia. Según nuestra experiencia, esto proporcionó un audio con una entonación plana con poca semejanza con la voz original.
- Neural Voice Lite personalizado: Herramienta de Microsoft Azure que permite a los usuarios clonar voces a partir de 5 minutos de voz grabada. Tiene tres requisitos de uso principales. En primer lugar, debe tener una suscripción a Microsoft Azure. Además, debe completar una solicitud y debe ser aprobada, este paso puede demorar hasta 10 días. Por último, debe cumplir con las pautas de usuario propuestas por el equipo de Microsoft.
- API de conversión de texto a voz en la nube: Este es un servicio que ofrece voces personalizadas. Te permite entrenar un modelo de voz personalizado utilizando tus propias grabaciones de audio para crear una voz única. A continuación, puedes usar tu voz personalizada para sintetizar el audio mediante la API. Ten en cuenta que se trata de un servicio de pago, pero puedes probarlo inscribiéndote en una prueba gratuita.
Reflexiones finales
En resumen, la tecnología de clonación de voz ha recorrido un largo camino y está en camino de revolucionar varias industrias. Por un lado, vimos que los avances más recientes incluyen el método de clonación expresiva de voz sin disparo basado en VITS, VALL-E y el TTS con múltiples altavoces Zero-Shot de bajos recursos.
Además, identificamos las consideraciones éticas relacionadas con el consentimiento y la identidad que deben abordarse para evitar el uso indebido de esta tecnología. Además, profundizamos en la mejor herramienta de clonación de voz de código abierto disponible, analizando sus puntos fuertes y débiles. TorToise es una herramienta que está fácilmente disponible y que produce buenos resultados.
Para concluir, todos estos avances recientes demuestran el potencial de la clonación de voz para crear voz personalizada de alta calidad con un mínimo de datos, por lo que es fácil ver que esta tecnología va por la vía rápida hacia el éxito.



.png)