.png)
Estado da arte em clonagem de voz: uma revisão




Introdução
Prepare-se para explorar os últimos avanços na tecnologia de clonagem de voz com esta análise abrangente dos avanços mais recentes. Neste blog, mergulharemos no estado atual da tecnologia de clonagem de voz, incluindo pesquisas e desenvolvimentos de ponta no campo. Também discutiremos as possíveis aplicações e as considerações éticas da clonagem de voz, bem como os desafios que ainda precisam ser enfrentados para melhorar as implementações disponíveis. Por fim, vamos explorar o Tortoise: uma ferramenta específica para clonagem de voz. Se você é pesquisador, desenvolvedor ou simplesmente está interessado nas tendências atuais da tecnologia, este blog é para você. Então, junte-se a nós enquanto exploramos o fascinante mundo da clonagem de voz.
O que é clonagem de voz?
A clonagem de voz se refere ao processo de criação de uma voz sintética que é quase idêntica a uma voz humana real. Ao contrário da síntese de voz, que gera fala realista com vozes predefinidas, a tecnologia de clonagem de voz é capaz de replicar a voz, o tom e as inflexões únicas de uma pessoa.
Texto: Esse é um exemplo do que pode ser feito com a clonagem de voz e como ela é diferente da síntese de fala.
Por que isso é relevante?
Essa tecnologia é relevante por vários motivos. Em primeiro lugar, ele tem o potencial de revolucionar a forma como interagimos com a tecnologia. Com a clonagem de voz, seríamos capazes de criar assistentes virtuais, chatbots e outros dispositivos realistas e humanos. Isso significa que podemos ter conversas mais naturais e envolventes com esses dispositivos, tornando-os mais fáceis e agradáveis de usar.
Além disso, essa tecnologia pode ser usada por indivíduos com problemas de fala ou deficiências. Isso poderia permitir que eles criassem vozes sintéticas que se assemelham muito às suas vozes naturais, melhorando sua capacidade de se comunicar de forma eficaz. Além disso, a clonagem de voz pode ser usada para preservar as vozes de pessoas que correm o risco de perdê-las devido a problemas médicos. Finalmente, essa tecnologia tem implicações para as indústrias de entretenimento e mídia. Em particular, permitirá criar dublagens mais realistas e convincentes para filmes, videogames e muito mais.
Em resumo, a clonagem de voz tem o potencial de melhorar a qualidade de vida de muitas pessoas, aprimorar a experiência do usuário com a tecnologia e criar novas possibilidades em vários setores.
Implicações éticas em torno da clonagem de voz
O desenvolvimento da tecnologia de clonagem de voz levanta questões éticas em torno de questões relacionadas ao consentimento e à identidade. A obtenção do consentimento é uma consideração importante, pois nem sempre fica claro se os indivíduos deram seu consentimento para que sua voz fosse usada. Estabelecer diretrizes claras sobre a obtenção do consentimento para a clonagem de voz é necessário para garantir que os indivíduos tenham o direito de controlar como sua voz é usada.
Além disso, uma voz sintética pode ser usada para se passar por indivíduos e causar danos quando é indistinguível de uma voz real. Assim, para evitar o uso indevido da tecnologia de clonagem de voz, algumas regulamentações devem ser estabelecidas. Ao abordar essas considerações éticas, podemos garantir que os benefícios potenciais da tecnologia de clonagem de voz sejam realizados e, ao mesmo tempo, minimizar os riscos e danos potenciais.
Estado da arte
O estado da arte está se movendo rapidamente, por isso é difícil se manter atualizado. A seguir está uma visão geral de alguns dos artigos mais recentes mais relevantes que você vai querer conhecer.
ZSE-VITS: um método de clonagem de voz expressiva Zero-Shot baseado no VITS - Fevereiro de 2023
Este é um novo método baseado no modelo de síntese de fala de ponta a ponta Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech (VITS). A espinha dorsal da arquitetura proposta é o modelo VITS e o modelo de reconhecimento de alto-falantes TitaNet é adicionado como codificador de alto-falante, o que permite a clonagem de disparo zero. O modelo supera as arquiteturas anteriores em similaridade de timbre em alto-falantes visíveis e invisíveis e melhora a expressividade e a capacidade de controle da prosódia na fala clonada. O diagrama a seguir mostra o pipeline completo do modelo proposto. Esse sistema usa como entrada um espectrograma de mel de referência contendo a prosódia desejada, os fonemas do texto a ser gerado e o áudio de referência do sujeito a ser clonado. Em seguida, como saída, ele gera um arquivo de áudio da voz alvo falando o texto pretendido com a prosódia desejada.
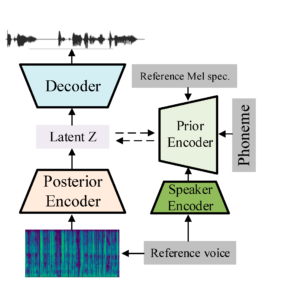
Estrutura geral do modelo proposto.
Os modelos de linguagem de codecs neurais são sintetizadores Zero-Shot de Texto para Fala - Janeiro de 2023
Esse modelo também é conhecido como VALL-E e foi construído pela equipe da Microsoft. Junto com o artigo, os autores publicaram uma demonstração dos resultados alcançados em este link. O principal destaque desse sistema é que ele pode gerar fala de alta qualidade com apenas 3 segundos de gravação. Isso estabeleceu um recorde no que diz respeito ao tempo necessário para a clonagem de voz. Além disso, a qualidade parece ser excelente. Além disso, o VALL-E supera os sistemas zero-shot de última geração em termos de naturalidade de fala e semelhança de alto-falantes. Outro destaque é que ele preserva a emoção do locutor e o ambiente acústico da gravação de 3 segundos. A seguir está uma visão geral do sistema do modelo VALL-E. Ele usa como entrada o prompt de texto e os 3 segundos de gravação e emite a fala clonada.
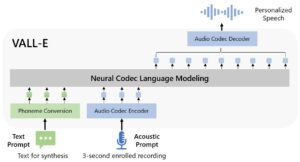
Visão geral do sistema de clonagem de voz proposto.
TTS multilíngue com poucos recursos e com vários alto-falantes Zero-Shot - Outubro de 2022
Neste trabalho, as tarefas de clonagem zero e conversão de texto em fala (TTS) multilíngue de baixo recurso são reunidas. Os autores tentaram avaliar se o último pode ser usado para alcançar o primeiro em um cenário de poucos recursos. Além disso, eles pretendiam mostrar que é possível que um sistema aprenda um novo idioma com apenas 5 minutos de dados de treinamento sem perder a capacidade de clonar as vozes de falantes invisíveis. Isso é importante porque a quantidade de dados necessária para abordagens anteriores geralmente não era viável para a grande maioria dos idiomas do mundo.
Para conseguir tudo isso, eles propuseram mudanças em um codificador TTS para lidar melhor com dados multilíngues e separar os idiomas dos alto-falantes. Além disso, eles mostraram que o procedimento de pré-treinamento do Language Agnostic Meta Learning (LAML) pode ser usado para treinar modelos gerais condicionados por alto-falantes. A ideia básica do LAML é tratar diferentes linguagens como tarefas separadas e refinar iterativamente um ponto de inicialização que seja adequado para todas as tarefas vistas no treinamento. Isso o tornaria adequado para tarefas não vistas (ou seja, idiomas ou vozes invisíveis na fase de teste). O que é importante sobre este artigo é que o uso desse procedimento de pré-treinamento pode abrir caminho para futuros sistemas multilíngues/multialto-falantes de alta qualidade/baixo recurso.
Finalmente, os autores forneceram um kit de ferramentas para ensino, treinamento e uso de modelos de síntese de fala chamado Tucano.
TortoiSE: Uma ferramenta disponível que produz bons resultados
Tartaruga, lançado em abril de 2022, é um programa TTS que tem a capacidade de imitar vozes com base em 2 a 4 exemplos fornecidos. É composto por 5 redes neurais treinadas de forma independente e depois combinadas para gerar a saída final. Em particular, uma combinação de decodificadores autorregressivos e modelos probabilísticos de difusão de redução de ruído (DDPMs) é usada porque os autores acreditam que, quando confrontados com o problema de geração de dados contínuos, esses modelos têm algumas vantagens distintas. A arquitetura completa foi treinada em um conjunto de dados com aproximadamente 49 mil horas de áudio, que levou quase um ano para ser concluído.
As principais vantagens dessa ferramenta são que seus resultados têm uma boa qualidade de som e são de código aberto. Além disso, um Jupyter Notebook fácil de usar é fornecido junto com o implementação. Esse código permite que qualquer pessoa use essa estrutura para clonar qualquer voz e sintetizar a fala. No entanto, este notebook não pode sintetizar texto longo, pois a implementação requer uma grande quantidade de espaço. Assim, usamos outro código para testar essa estrutura. Esse segundo código pode sintetizar textos grandes dividindo-os em frases e concatenando os resultados de cada frase.
Isso funciona bem?
Para começar a avaliar o desempenho do modelo, queríamos realizar a clonagem de voz para vários alto-falantes. Para isso, geramos uma voz clonada para 4 alto-falantes. Primeiro, fizemos com que eles gravassem frases específicas, gerando 4 arquivos de áudio que variavam entre 6 e 15 segundos por alto-falante. Em seguida, esses áudios foram usados como entrada para o sistema. Finalmente, geramos vários textos com a voz clonada. Agora, apresentaremos uma comparação entre os resultados e a verdade fundamental.
Texto 1: A inteligência artificial se tornou cada vez mais importante no mundo atual porque permite que as máquinas executem tarefas que normalmente exigem inteligência humana.
No geral, o áudio gerado tem uma qualidade muito boa, embora às vezes não tenha expressividade. Ocasionalmente, o áudio inclui respirações em locais apropriados dentro das frases. No entanto, há momentos em que os resultados apresentam pausas impróprias. Isso tende a acontecer quando os áudios usados para clonagem contêm pausas colocadas incorretamente. Em relação à entonação, ela está correta em alguns casos, mas em outros, é um pouco plana. Os resultados também mostram que a pronúncia em inglês de cada indivíduo não é clonada. Além disso, o áudio gerado pode incluir ruídos estranhos, como é o caso do alto-falante 2 com o texto 2.
Texto 2: Essa tecnologia tem o potencial de revolucionar indústrias e melhorar muitos aspectos de nossas vidas, incluindo saúde, transporte e educação.
Há casos em que a voz clonada pode parecer robótica, como é o caso do alto-falante 2 com o texto 3. Em suma, embora o áudio gerado não seja perfeito, ele permite que qualquer usuário clone uma voz alvo com pouco áudio e fornece bons resultados.
Texto 3: O gato dormiu em paz no parapeito da janela, curtindo o calor do sol.
Isso pode gerar frases longas?
Ao gerar frases mais longas, às vezes o resultado pode conter palavras repetidas, o que aconteceu com o locutor 2 com o texto 4.
Texto 4: A cor do céu parece azul durante o dia devido à forma como a atmosfera da Terra dispersa a luz solar. A luz azul é mais dispersa do que outras cores devido ao seu menor comprimento de onda, tornando-a mais visível ao olho humano. Conforme o sol se põe ou nasce, a luz deve passar por mais da atmosfera, espalhando mais luz azul e permitindo que mais vermelhos e laranjas sejam visíveis, resultando em um céu colorido.
Que tal produzir texto em outros idiomas?
Como o modelo foi treinado em inglês, queríamos testar o desempenho do sistema com áudio em outro idioma. Para isso, alimentamos 4 arquivos de áudio em espanhol e depois sintetizamos outros textos em espanhol e inglês.
Texto 5: A luz do sol ilumina suavemente a paisagem, criando sombras e reflexos nas folhas das árvores e na água do rio cercano.
Texto 6: A cor do céu parece azul durante o dia devido à forma como a atmosfera da Terra dispersa a luz solar. A luz azul é mais dispersa do que outras cores devido ao seu menor comprimento de onda, tornando-a mais visível ao olho humano. Conforme o sol se põe ou nasce, a luz deve passar por mais da atmosfera, espalhando mais luz azul e permitindo que mais vermelhos e laranjas sejam visíveis, resultando em um céu colorido.
Esses resultados mostram que o Tortoise não pode gerar texto em outros idiomas. Em particular, a fala gerada às vezes não é pronunciada corretamente e, na maioria das vezes, é pura bobagem. No entanto, quando treinado com um falante de espanhol, ele é capaz de clonar a voz alvo e gerar fala em inglês. A partir disso, concluímos que, embora o Tortoise não possa gerar texto em outros idiomas, ele pode ser usado para gerar áudio com uma voz alvo em um idioma não falado pelo sujeito.
Quanto tempo leva para gerar um áudio?
O autor relatou uma proporção de 1 a 10 entre a duração do áudio gerado e o tempo de geração. Para verificar essa afirmação, executamos vários testes gerando áudio com durações diferentes. A partir disso, descobrimos que a afirmação é verdadeira, o sistema é bem lento. Isso o torna impróprio para aplicativos em tempo real e certamente justifica o nome do framework.
Desafios atuais
A tecnologia de clonagem de voz fez progressos significativos nos últimos anos, mas ainda há alguns desafios técnicos a serem enfrentados. Um grande desafio é a capacidade de gerar uma fala sintetizada de alta qualidade que soe natural e humana. Embora os modelos atuais tenham mostrado resultados promissores, ainda há espaço para melhorias.
Outros desafios incluem a necessidade de grandes quantidades de dados de treinamento para desenvolver clones de voz precisos e confiáveis. Os modelos de clonagem de voz exigem grandes conjuntos de dados (milhares de horas) de gravações de alta qualidade para aprender as características únicas da voz de uma pessoa. No entanto, obter esses conjuntos de dados pode ser demorado e caro, especialmente para clonar indivíduos sem dados disponíveis.
Outro desafio na área é a questão da variabilidade dos alto-falantes. Os modelos de clonagem de voz geralmente são treinados na voz de um único locutor. Isso pode limitar sua capacidade de clonar com precisão outros falantes com diferentes padrões de fala e sotaques. Para resolver isso, os pesquisadores estão explorando técnicas como treinamento com vários alto-falantes e adaptação de domínio.
Por fim, a questão da clonagem de voz em tempo real continua sendo um desafio. Embora os modelos atuais possam gerar fala sintetizada de alta qualidade, eles ainda não são capazes de produzi-la em tempo real. Isso limita seus possíveis casos de uso em aplicativos como assistentes de voz e chatbots. Enfrentar esses desafios técnicos será crucial para o avanço contínuo e a adoção generalizada dessa tecnologia.
Outras alternativas de clonagem de voz
Para economizar tempo, aqui estão outros recursos não mencionados neste artigo que você pode encontrar.
Alternativas de código aberto
- Discurso de remo: Kit de ferramentas de código aberto na plataforma PaddlePaddle para uma variedade de tarefas críticas em fala e áudio. No GitHub da biblioteca, descobrimos que o código fornecido não é de ponta a ponta.
- Coqui TTS: É descrita como uma biblioteca para geração avançada de texto em fala. No entanto, os áudios resultantes tendem a soar ruidosos, com quebras não naturais na voz e um toque metálico. Clique aqui para encontrar a demonstração do autor.
- HuggingFace: Várias demonstrações de clonagem de voz podem ser encontradas, de diferentes autores. Essas implementações não chegam nem perto do desempenho alcançado pelo Tortoise. Alguns exemplos podem ser encontrados nos links a seguir: Ligação 1, Ligação 2.
Implementações privadas
- Aprendizado autosupervisionado para clonagem de voz robusta: Este artigo apresenta um algoritmo que pode ser treinado em um conjunto de dados sem rótulo com qualquer número de alto-falantes. Os resultados apresentados estão próximos do desempenho básico dos recursos de alto-falantes pré-treinados em tarefas de verificação de alto-falantes. Os autores não forneceram nenhuma implementação até o momento.
- Clonagem de voz de formato longo Zero-Shot com atenção dinâmica de convolução: O modelo proposto neste artigo é baseado no Tacotron 2 e usa um mecanismo de atenção baseado em energia (Dynamic Convolution Attention) combinado com um conjunto de modificações para o sintetizador do Tacotron 2. Os autores concluíram que o modelo proposto pode produzir fala sintética inteligível, preservando a naturalidade e a semelhança. Não encontramos nenhum código para essa estrutura durante o curso desta pesquisa.
- Estúdio NVIDIA Riva: Permite clonar vozes usando apenas 30 minutos de gravações de áudio com uma abordagem sem código. No entanto, essa ferramenta ainda está em um estágio de acesso inicial e seu uso é limitado aos desenvolvedores que trabalham com conversão de texto em fala.
Serviços pagos
- Semelhante à IA: Seu gerador de voz afirma gerar locuções semelhantes às humanas em segundos e permite que você clone sua voz gratuitamente. Lembre-se de que foram necessárias mais de três semanas para eles gerarem uma voz usando o teste gratuito. O processo de clonagem de voz é baseado inicialmente em 25 gravações de áudio da voz alvo com texto predefinido. Eles também oferecem uma alternativa paga que permite aos usuários melhorar a voz clonada adicionando mais amostras de áudio. Além disso, há uma estrutura de clonagem rápida de voz adicionada recentemente com apenas 10 segundos de áudio de referência. Em nossa experiência, isso proporcionou um áudio de entonação plana com pouca semelhança com a voz original.
- Neural Voice Lite personalizado: Ferramenta do Microsoft Azure que permite aos usuários clonar vozes de 5 minutos de fala gravada. Ele tem três requisitos principais de uso. Primeiro, você deve ter uma assinatura do Microsoft Azure. Além disso, você deve preencher uma solicitação e ela deve ser aprovada. Essa etapa pode levar até 10 dias. Finalmente, você deve seguir as diretrizes de usuário propostas pela equipe da Microsoft.
- API de conversão de texto em voz na nuvem: Este é um serviço que oferece vozes personalizadas. Ele permite que você treine um modelo de voz personalizado usando suas próprias gravações de áudio para criar uma voz exclusiva. Em seguida, você pode usar sua voz personalizada para sintetizar áudio usando a API. Lembre-se de que esse é um serviço pago, mas você pode experimentá-lo inscrevendo-se para um teste gratuito.
Considerações finais
Resumindo, a tecnologia de clonagem de voz já percorreu um longo caminho e está a caminho de revolucionar vários setores. Por um lado, vimos que os avanços mais recentes incluem o método de clonagem de voz expressiva com zero disparo baseado em VITS, VALL-E e o TTS multi-alto-falante Zero-Shot de baixo recurso.
Além disso, identificamos considerações éticas relacionadas ao consentimento e à identidade que devem ser abordadas para evitar o uso indevido dessa tecnologia. Além disso, analisamos a melhor ferramenta de clonagem de voz de código aberto disponível, analisando seus pontos fortes e fracos. O Tortoise é uma ferramenta que está prontamente disponível e produz bons resultados.
Para concluir, todas essas descobertas recentes demonstram o potencial da clonagem de voz para criar fala personalizada de alta qualidade com o mínimo de dados, portanto, é fácil ver que essa tecnologia está no caminho certo para o sucesso.



.png)