.png)
Pujas en tiempo real: un enfoque de aprendizaje automático para encontrar precios de oferta óptimos




Introducción
Las ofertas en tiempo real (RTB) son un escenario común en la publicidad digital. Mientras un usuario navega por la web, surgen diferentes oportunidades para presentar un anuncio. Estas oportunidades se subastan entre los anunciantes. Ofrecer un precio óptimo es clave para mejorar el rendimiento de las campañas y aumentar las ganancias.
Esta publicación presenta un recorrido por el proceso de RTB y sus desafíos. Nos centraremos especialmente en el lado del anunciante y presentaremos las estrategias típicas para optimizar su precio de oferta.
El resto de esta revisión se organiza de la siguiente manera: En la primera sección revisaremos algunos conceptos clave del ecosistema RTB. A continuación, profundizaremos en algunas soluciones de última generación para la fijación de precios de inventario. Por último, analizaremos la eliminación de las cookies de terceros y su efecto en el mundo de la RTB y presentaremos una posible estrategia para superarlo.
¿Cómo funciona el RTB?
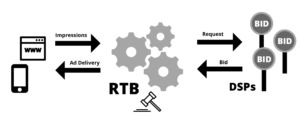
Una subasta de RTB suele ser así:
- El usuario navega por una página. Después de cierto tiempo, el navegador envía una solicitud para cargar un anuncio.
- Se subasta el espacio publicitario. El editor establece un precio mínimo para el espacio.
- Los anunciantes evalúan la impresión en función de sus requisitos de segmentación y hacen sus ofertas.
- Si el precio de la oferta es superior al precio de reserva, el anunciante con la oferta más alta gana el espacio. El precio pagado por el espacio dependerá del tipo de subasta.
- El anuncio ganador se muestra al usuario.
Para garantizar una experiencia en tiempo real, los SSP imponen una restricción de tiempo muy estricta al proceso de RTB. Las ofertas recibidas después de este plazo no se considerarán en la subasta. El tiempo de respuesta a las ofertas incluye tanto el tiempo de cálculo necesario para ejecutar los algoritmos de optimización de las ofertas como la latencia de la red. Las restricciones de latencia para todo el proceso normalmente oscilan entre 80 y 120 ms[1] [2] según la aplicación y el tipo de subasta, pero podría ser incluso menor 😱
Tipos de subastas
Subasta de primer precio
En este caso, el mejor postor ganará la subasta y se le cobrará exactamente esa cantidad. Como los DSP se ven obligados a adivinar cuánto pujará su competencia, la subasta puede generar precios de oferta extremadamente altos. Para evitar pagar de más, los DSP deben ser conscientes del justo valor de mercado de las impresiones por las que están pujando.
Subasta de segundo precio
En este escenario, el participante que haga la oferta más alta será el ganador de la subasta y se le cobrará el segundo precio de oferta más alto. Cuando un DSP gane la subasta, sabrá tanto el precio ganador como el precio de pago. Mientras que cuando un DSP pierde, no recibe ninguna respuesta del servidor de anuncios y, por lo tanto, no tiene ni idea de qué tan alto fue el precio ganador. Solo sabe que es más alto que su precio de oferta. Este escenario se conoce como «censura».
Sombreado de aves
Para minimizar el riesgo de pagar de más por las impresiones en las subastas con el primer precio, se introdujo el concepto de sombreado de ofertas. Consiste en utilizar algoritmos predictivos para obtener un precio de oferta óptimo. Este mecanismo pretende cerrar la brecha entre lo que los compradores están dispuestos a pagar por una impresión y lo que realmente tienen que pagar. Al determinar el precio final, los algoritmos de sombreado de ofertas tienen en cuenta una amplia gama de factores, como los datos de precios, las tasas de ganancia, el sitio, el tamaño del anuncio y la dinámica competitiva.
El ecosistema RTB
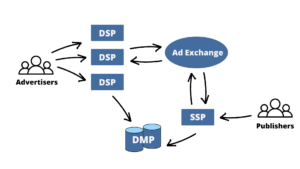
Ahora, repasemos los actores clave del proceso de RTB.
- Plataformas del lado de la oferta (SSP) tienen por objeto ayudar a los editores (vendedores) a gestionar y comercializar las impresiones de sus anuncios. Permiten a los editores conectar su inventario a varios intercambios de anuncios y redes al mismo tiempo. Los SSP reciben la solicitud de anuncios desde el navegador web o la aplicación. A continuación, analizan su información de usuario (cookies, ubicación, etc.) y la transmiten al intercambio de anuncios.
- Intercambios de anuncios (ADX) consisten en un mercado en línea donde los editores y los anunciantes pueden interactuar. Su objetivo es simplificar la interacción entre las dos partes. Los ADX reciben la información de los SSP y la transmiten al plataformas del lado de la demanda.
- Plataformas del lado de la demanda (DSP) proporcionan tecnología a los anunciantes (compradores) automatizando y centralizando el proceso de licitación. Permiten que el proceso de toma de decisiones sea significativamente más rápido y eficiente. Los DSP pueden realizar varias ofertas en nombre de diferentes anunciantes en función de sus preferencias. Cuando un DSP recibe la oportunidad de los ADX, la analiza y produce una oferta basada en la impresión.
- Plataformas de administración de datos (DMP) proporciona datos históricos de usuario a DSP, SSP y ADX
Estrategias de optimización del precio de las ofertas
En el caso de un DSP, predecir correctamente el precio ganador, lo que se conoce como Precios de inventario, es la clave para ganar la subasta de RTB. Este problema suele formularse como una previsión de la distribución probabilística del precio de mercado en cada escenario de subasta. Mientras que en las subastas a segundo precio, la censura se toma como una consideración adicional al problema.
Tradicionalmente, Análisis de supervivencia —una rama de las estadísticas para analizar el tiempo esperado hasta que se produzca un evento— fue el enfoque preferido para abordar el problema óptimo de predicción del precio de las ofertas. Estos métodos se denominan puntos Estimadores ya que devuelven un valor de precio único como recomendación. Por lo tanto, no proporcionan un panorama de la distribución de precios y, por lo tanto, obligan a los DSP a ofrecer directamente el precio estimado, lo que elimina la posibilidad de una oferta más estratégica.
Luego se adoptaron modelos probabilísticos para satisfacer la necesidad de incorporar más información en las decisiones de precios (panorama de precios) y poder responder a preguntas más específicas, tales como:»¿cuánto debo pujar si quiero ganar una cantidad determinada de impresiones? »[4]. En este sentido, los enfoques recientes implican adoptar un supuesto heurístico de las formas de distribución de precios de las ofertas ganadoras y utilizar modelos que se ajusten a sus parámetros clave. Sin embargo, estas suposiciones previas pueden afectar gravemente a la eficacia del modelo.
«El formulario de distribución de precios adecuado puede variar según los distintos conjuntos de datos e incluso según las diferentes dimensiones de los anuncios. Es casi imposible utilizar una hipótesis de distribución fija para describir con precisión el panorama de precios». [4]
Otro aspecto clave del ecosistema RTB es el requisito de baja latencia para lograr el servicio en línea. Las soluciones no solo deben adaptarse con precisión al panorama de precios, sino que también deben ofrecer una respuesta a la altura de un milisegundo: lo que significa que los algoritmos involucrados deberían poder ofrecer una oferta óptima en 10 ms o incluso menos 🤯. Para cumplir con este ambicioso requisito de tiempo de respuesta, los diseños suelen consistir en un módulo fuera de línea para la capacitación, que concentra la complejidad del modelo, y un módulo en línea simple para las operaciones en tiempo real.
Ahora revisemos algunos enfoques avanzados para este problema, ¿de acuerdo?
Previsión de paisajes profundos
Esta técnica utiliza el aprendizaje profundo para modelar la distribución de probabilidades del precio de las ofertas y utiliza el análisis de supervivencia para gestionar la censura. Se basa en un artículo publicado en 2021: «Previsión del panorama profundo para la publicidad de ofertas en tiempo real». En este caso, los autores proponen un marco RNN para modelar de manera flexible la probabilidad de ganancia condicional para cada precio de oferta sin necesidad de ninguna suposición previa.
En el marco presentado, la información recopilada de los registros de ofertas se representa como un conjunto de triples (x, b, z):
- x — características de la solicitud de oferta (información del usuario, tamaño del anuncio, posición del anuncio, etc.)
- b — precio de oferta propuesto
- z — precio de mercado observado (nulo si el DSP nunca ha ganado la subasta)
El modelado se transforma de un espacio continuo a un espacio discreto. Por lo tanto, el rango de precios se divide uniformemente en un conjunto de L intervalos Vl. Luego, el modelo DLF se basa en una red neuronal recurrente cuya arquitectura se presenta en la figura siguiente.
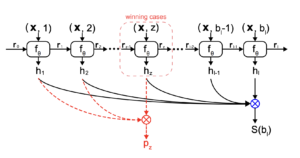
En cada intervalo Vl la l-th La celda RNN predice la probabilidad de ganar condicional hl dado un precio de oferta determinado bl y las funciones de solicitud x. Entonces, la función RNN f es un LSTM estándar que toma (bl, x) como entrada y hl como salida. El vector rl-1 representa el vector oculto calculado a partir de la última célula RNN. Para mejorar la eficiencia, el rango de precios se divide en varios intervalos triviales, lo que aumenta linealmente los pasos del LSTM en la red.
La solución presentada se probó en dos conjuntos de datos públicos: YOYI e iPinYou. A continuación, se comparó con nueve modelos de referencia y se obtuvieron resultados prometedores: una mejora media del 13% en las métricas del ANLP (probabilidad logarítmica negativa media) y del índice C (índice de concordancia). Sin embargo, el tiempo de respuesta resultante de esta solución no se ajusta al SLA estándar de 10 ms. Los autores afirmaron haber logrado una respuesta promedio de 22 ms, lo que podría comprometer el rendimiento en tiempo real en algunos escenarios.
Modelado de distribución arbitraria
El marco de modelado de distribución arbitraria (ADM) se presentó en 2021 con la publicación del artículo «Modelado de distribución arbitraria con censura en la publicidad de ofertas en tiempo real». En la misma línea que el DLF, este enfoque también busca modelar la distribución de los precios de las ofertas de forma independiente para cada escenario de RTB, pero con la novedad de una arquitectura simplista para lograr la eficiencia en la inferencia en línea.
Al igual que en el marco del DLF, la información recopilada de los registros de ofertas se representa como un conjunto de triples (x, b, z), donde las funciones de la solicitud de oferta se clasifican además en cuatro categorías:
- xp — funciones del editor, incluida la información del sitio web (URL, dominio, tamaño del anuncio, etc.)
- xu — funciones de usuario que incluyen información relacionada con el espectador (edad, ubicación, dispositivo, etc.)
- xun — funciones publicitarias que representan la información que el DSP quiere ofrecer (industria, género, duración del anuncio, etc.)
- xc — características del contexto, que es la información neutral (marca de tiempo, día de la semana, etc.)
El rango de precios también se discretiza en grupos, como lo hacía el método DLF. El ancho de cada cubo depende de la precisión requerida para cada negocio específico. El marco ADM se basa en el modelo de perceptrón multicapa (MLP) e incorpora una nueva pérdida de función denominada pérdida de probabilidad de vecindad (NLL), que ayuda a conocer con precisión el panorama de precios. Su estructura simple garantiza su eficiencia en términos de latencia. Partiendo del supuesto de que, para ganar una subasta (de segundo precio), los precios de oferta del DSP suelen estar cerca de los precios ganadores reales, la función de pérdidas de NLL proporciona una orientación precisa para guiar el modelo a partir de las observaciones. Como se muestra en el siguiente diagrama, el marco se compone de dos niveles: Feature Extractor y Landscape Predictor.

Extractor de características (3 capas): En primer lugar, mapea las características originales en el espacio latente, donde las características categóricas se incrustan (mediante una codificación en caliente) y se concatenan con características numéricas normalizadas. Luego, el extractor de características de segundo orden extrae de él las entidades de segundo orden. Para las entidades de orden superior, se aplica un conjunto de capas totalmente conectadas.
Predictor de paisaje: concatena los vectores de características de primer, segundo y orden superior y los introduce en una capa Softmax para predecir las probabilidades de que el precio ganador caiga en cada grupo de precios.
Los autores probaron la solución propuesta utilizando los conjuntos de datos públicos IPinYou y YOYI, y luego la compararon con seis líneas de base conocidas, incluido el modelo DLF. En cuanto a las métricas del índice ANLP y C, el ADM supera al DLF en ambos conjuntos de datos. Además, los tiempos de ejecución informados fueron del orden de 5 ms en el 99% de los casos de prueba, en perfecta concordancia con el SLA habitual de 10 ms. 😎
Desafíos futuros para la industria del RTB
Es evidente que el auge del anonimato en Internet se está convirtiendo en un arduo desafío para la industria de la publicidad digital. Si bien a los usuarios se les garantiza una experiencia mejorada y sin necesidad de rastreo a través de la web, los anunciantes se ven obligados a encontrar nuevas formas de generar contenido personalizado y a adoptar el RTB.
Como habrás oído, Google ha anunciado la eliminación de las cookies de terceros para 2023. En consecuencia, los anunciantes no podrán utilizar cookies de terceros para rastrear a los usuarios en el navegador Chrome, que actualmente representa más del 63% de la cuota de mercado mundial.
Huellas dactilares de tráfico
Sobre este tema, en mayo de 2022 con la presentación del artículo «Mejorar la rentabilidad de los anuncios utilizando huellas digitales de tráfico», el concepto de huellas dactilares de tráfico se introdujo como una forma de representar el tráfico diario de una web. El objetivo principal era mejorar el rendimiento de la campaña sin depender de la información de los usuarios, impulsados por la idea de erradicar las cookies de terceros.
Según la definición de los autores, huellas dactilares de tráfico consisten en vectores normalizados de 24 dimensiones que tienen como objetivo representar la distribución diaria del tráfico del sitio web. En otras palabras, la cantidad de clics recolectados por hora por sitio. El uso de estos vectores permite detectar dominios publicitarios no rentables.
«El objetivo principal del algoritmo es seleccionar páginas web (dominios) que no sean rentables y se debe impedir que los anuncios aparezcan en esas páginas web». [5]
Una vez huellas dactilares de tráfico se recopilan, el algoritmo propuesto es el siguiente:
- Clusterización: basados en las huellas dactilares del tráfico, los dominios se dividen en grupos mediante la agrupación k-means.
- Reglas de negocio: mediante el análisis de las estadísticas del clúster y la evaluación de su rendimiento cada hora, se crean reglas empresariales para determinar qué grupos obtuvieron peores resultados y en qué período de tiempo.
- Bloqueo temporal: Los clústeres que muestran un rendimiento deficiente se bloquean temporalmente de los algoritmos RTB en intervalos de tiempo específicos.
Al adoptar estas estrategias, los autores informaron haber logrado un aumento del 40% en las ganancias 🤑
Reflexiones finales
En resumen, hemos explorado el marco RTB y los conceptos clave que lo sustentan. La publicación tiene como objetivo destacar lo que consideramos las soluciones más prometedoras en términos de optimización del precio de las ofertas.
Sin duda, uno de sus mayores desafíos radica en la extrema sensibilidad temporal que implica la respuesta de DSP durante la subasta. En este sentido, el marco del modelado de distribución adaptativo (ADM) parece ser un enfoque innovador y perspicaz. Además, la adopción de las estrategias gratuitas de cookies en el marco parece ser una decisión acertada, especialmente después del anuncio de Google.
Las ofertas en tiempo real (RTB) son un tema difícil y, sin duda, una excelente oportunidad para aplicar técnicas de aprendizaje profundo. A medida que la industria se hace más madura, surgen más desafíos y oportunidades de investigación fructíferas.
Referencias
[1] Google: Mejores prácticas para aplicaciones de RTB [2] Cómo afecta la latencia de la red al proceso de RTB para Adtech [3] Previsión profunda del panorama para la publicidad de ofertas en tiempo real [4] Modelado de distribución arbitraria con censura en la publicidad de ofertas en tiempo real [5] Mejora de la rentabilidad de los anuncios mediante huellas digitales de tráfico



.png)