.png)
Licitação em tempo real: uma abordagem de aprendizado de máquina para encontrar os melhores preços de licitação




Intro
A licitação em tempo real (RTB) é um cenário comum na publicidade digital. Enquanto um usuário navega na web, surgem diferentes oportunidades de apresentar um anúncio. Essas oportunidades são leiloadas entre os anunciantes. Oferecer um preço ideal é fundamental para melhorar o desempenho da campanha e aumentar os lucros.
Esta postagem apresenta um passo a passo do processo RTB e seus desafios. Vamos nos concentrar especialmente no lado do anunciante e apresentar estratégias típicas para otimizar seu preço de licitação.
O restante desta análise está organizado da seguinte forma: Na primeira seção, analisaremos alguns conceitos-chave do ecossistema RTB. A seguir, vamos nos aprofundar em algumas soluções de última geração para preços de estoque. Finalmente, discutiremos a remoção de cookies de terceiros, seu efeito no mundo do RTB e apresentaremos uma possível estratégia para superá-la.
Como funciona o RTB?
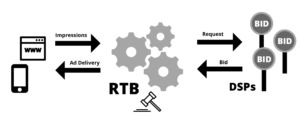
Um leilão RTB geralmente é assim:
- O usuário navega por uma página. Depois de um certo tempo, o navegador envia uma solicitação para carregar um anúncio.
- O espaço publicitário é leiloado. O editor define um preço mínimo para o espaço.
- Os anunciantes avaliam a impressão de acordo com seus requisitos de segmentação e fazem seus lances.
- Se o preço do lance for maior do que o preço de reserva, o anunciante com o lance mais alto ganha o espaço. O preço pago pelo espaço dependerá do tipo de leilão.
- O anúncio vencedor é exibido para o usuário.
Para garantir a experiência em tempo real, os SSPs impõem uma restrição de tempo muito rígida no processo de RTB. Quaisquer lances recebidos após esse prazo não são considerados no leilão. O tempo de resposta do lance envolve tanto o tempo de computação para realizar algoritmos de otimização de lances quanto a latência da rede. As restrições de latência para todo o processo normalmente variam entre 80 e 120 ms[1] [2] dependendo da aplicação e do tipo de leilão, mas pode ser ainda menor 😱
Tipos de leilões
Leilão de primeiro preço
Nesse cenário, o licitante com lance mais alto vencerá o leilão e será cobrado exatamente esse valor. Como os DSPs são forçados a adivinhar quanto seus concorrentes licitarão, o leilão pode levar a preços de licitação extremamente altos. Para evitar pagar demais, os DSPs precisam estar cientes do valor justo de mercado das impressões pelas quais estão licitando.
Leilão de segundo preço
Nesse cenário, o participante que fizer o lance mais alto é o vencedor do leilão e é cobrado pelo segundo maior preço de licitação. Quando um DSP vencer o leilão, ele saberá o preço vencedor e o preço pago. Por outro lado, quando um DSP perde, ele não recebe nenhuma resposta do servidor de anúncios e, portanto, não tem ideia de quão alto foi o preço do prêmio. Só sabe que é maior do que o preço de licitação. Esse cenário é conhecido como “Censura”.
Sombreamento de pássaros
Para minimizar o risco de pagar demais por impressões em cenários de leilão de primeiro preço, foi introduzido o conceito de sombreamento de lances. Consiste em usar algoritmos preditivos para obter um preço de licitação ideal. Esse mecanismo pretende fechar a lacuna entre o que os compradores estão dispostos a pagar por uma impressão e o que eles realmente precisam pagar. Ao determinar o preço final, os algoritmos de sombreamento de lances levam em consideração uma ampla variedade de fatores, como: dados de preços, taxas de ganho, site, tamanho do anúncio e dinâmica competitiva.
O ecossistema RTB
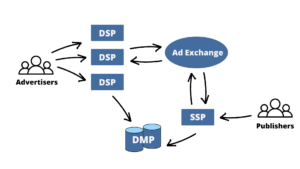
Agora, vamos analisar os principais participantes do processo de RTB.
- Plataformas do lado da oferta (SSP) têm como objetivo ajudar os editores (vendedores) a gerenciar e comercializar suas impressões de anúncios. Eles permitem que os editores conectem seu inventário a várias redes e trocas de anúncios ao mesmo tempo. Os SSPs recebem a solicitação de anúncio do navegador ou aplicativo da web. Eles então analisam as informações do usuário (cookies, localização, etc.) e as passam para o troca de anúncios.
- Trocas de anúncios (ADX) consistem em um mercado on-line onde editores e anunciantes podem interagir. O objetivo é simplificar a interação entre as duas partes. Os ADXs recebem as informações dos SSPs e as passam para o plataformas do lado da demanda.
- Plataformas do lado da demanda (DSP) forneça tecnologia aos anunciantes (compradores) automatizando e centralizando o processo de licitação. Eles permitem que o processo de tomada de decisão seja significativamente mais rápido e eficiente. Os DSPs podem fazer vários lances em nome de diferentes anunciantes com base em suas preferências. Quando um DSP recebe a oportunidade do ADxS, ele a analisa e produz uma oferta sobre a impressão.
- Plataformas de gerenciamento de dados (DMP) fornece dados históricos do usuário para DSP, SSP e ADX
Estratégias de otimização de preços de licitação
Para um DSP, prever com sucesso o preço vencedor, conhecido como Preços de inventário, é a chave para ganhar o leilão RTB. Esse problema geralmente é formulado como uma previsão da distribuição de probabilidade do preço de mercado em cada cenário de leilão. Nos leilões de segundo preço, a censura é considerada uma consideração adicional ao problema.
Tradicionalmente, Análise de sobrevivência — um ramo de estatísticas para analisar a duração esperada até que um evento ocorra — foi a abordagem preferida para resolver o problema ideal de previsão de preços de licitação. Esses métodos são chamados de Point. Estimadores pois eles retornam um único valor de preço como recomendação. Assim, eles falham em fornecer um panorama da distribuição de preços e, portanto, forçam os DSPs a licitar diretamente o preço estimado, eliminando a possibilidade de uma oferta mais estratégica.
Modelos probabilísticos foram então adotados para atender à necessidade de incorporar mais informações nas decisões de preços (cenário de preços) e ser capaz de responder a perguntas mais específicas, como:”quanto devo licitar se quiser ganhar uma certa quantidade de impressões? ”[4]. Nesse sentido, abordagens recentes envolvem a adoção de uma suposição heurística das formas de distribuição de preços da licitação vencedora e o uso de modelos para ajustar seus principais parâmetros. No entanto, essas premissas podem afetar gravemente a eficácia do modelo.
“O formulário apropriado de distribuição de preços pode variar para diferentes conjuntos de dados e até mesmo para diferentes dimensões de anúncio. É quase impossível usar uma suposição de distribuição fixa para descrever com precisão o cenário de preços.” [4]
Outro aspecto importante do ecossistema RTB é o requisito de baixa latência para obter atendimento on-line. As soluções não precisam apenas se ajustar com precisão ao cenário de preços, mas também fazer isso com uma resposta em nível de milissegundos — o que significa que os algoritmos envolvidos devem ser capazes de fornecer uma oferta ideal em 10 ms ou até menos 🤯. Para atingir esse ambicioso requisito de tempo de resposta, os projetos geralmente consistem em um módulo offline para treinamento, que concentra a complexidade do modelo; e um módulo on-line simples para operações em tempo real.
Agora, vamos revisar algumas abordagens de última geração para esse problema, não é?
Previsão de paisagens profundas
Essa técnica usa aprendizado profundo para modelar a distribuição de probabilidade de preços de licitações e usa análise de sobrevivência para lidar com a censura. É baseado em um artigo publicado em 2021: “Previsão profunda do cenário para publicidade em licitações em tempo real”. Aqui, os autores propõem uma estrutura RNN para modelar de forma flexível a probabilidade de vitória condicional para cada preço de licitação sem qualquer suposição prévia necessária.
Na estrutura apresentada, as informações coletadas dos registros de licitações são representadas como um conjunto de triplos (x, b, z):
- x — características da solicitação de lance (informações do usuário, tamanho do anúncio, posição do anúncio etc.)
- b — preço de licitação proposto
- z — preço de mercado observado (nulo se o leilão nunca tiver sido ganho pelo DSP)
A modelagem é transformada de espaço contínuo em espaço discreto. Assim, a faixa de preço é uniformemente dividida em um conjunto de L intervalos Vl. Em seguida, o modelo DLF é baseado em uma rede neural recorrente cuja arquitetura é apresentada na figura abaixo.
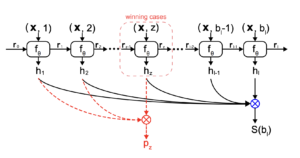
Em cada intervalo Vl a l-ésimo A célula RNN prevê a probabilidade de vitória condicional hl dado um determinado preço de oferta bl e os recursos de solicitação x. Então, a função RNN f é um LSTM padrão que aceita (bl, x) como entrada e hl como saída. O vetor rl-1 representa o vetor oculto calculado a partir da última célula RNN. Para melhorar a eficiência, a faixa de preço é dividida em vários intervalos triviais, o que aumenta linearmente as etapas do LSTM na rede.
A solução introduzida foi testada em dois conjuntos de dados públicos: YOYI e IPinYou. Em seguida, foi comparado com nove modelos básicos que alcançaram resultados promissores: uma melhoria de 13% nas métricas ANLP (probabilidade média de log negativo) e índice C (índice de concordância) em média. No entanto, o tempo de resposta resultante dessa solução está fora do SLA padrão de 10 ms. Os autores afirmaram ter alcançado uma resposta média de 22 ms, o que pode comprometer o desempenho em tempo real em alguns cenários.
Modelagem de distribuição arbitrária
A estrutura de Modelagem de Distribuição Arbitrária (ADM) foi apresentada em 2021 com a publicação do artigo “Modelagem de distribuição arbitrária com censura na publicidade de licitações em tempo real”. Na mesma linha da DLF, essa abordagem também busca modelar a distribuição de preços de licitação de forma independente para cada cenário de RTB, mas com a novidade de uma arquitetura simplista para obter eficiência na inferência on-line.
Como na estrutura DLF, as informações coletadas nos registros de licitações são representadas como um conjunto de triplos (x, b, z), onde as características da solicitação de licitação são posteriormente classificadas em quatro categorias:
- xp — recursos do editor, incluindo informações do site (URL, domínio, tamanho do anúncio etc.)
- xu — recursos do usuário que incluem informações relacionadas ao espectador (idade, localização, dispositivo etc.)
- xuma — recursos de anúncios que representam as informações que o DSP deseja fornecer (setor, gênero, duração do anúncio etc.)
- xc — características de contexto que são as informações neutras (data e hora, dia da semana, etc.)
A faixa de preço também é discretizada em grupos, como fez o método DLF. A largura de cada caçamba depende da precisão necessária para cada negócio específico. A estrutura ADM é baseada no modelo Multi Layer Perceptron (MLP) e incorpora uma nova perda de função, considerada perda de probabilidade de vizinhança (NLL), que ajuda a aprender o cenário preciso de preços. Sua estrutura simples garante sua eficiência em termos de latência. Com base na suposição de que, para ganhar um leilão (segundo preço), os preços de licitação do DSP geralmente estão próximos dos preços reais vencedores, a função de perda NLL fornece uma direção precisa para orientar o modelo que aprende com as observações. Conforme mostrado no diagrama a seguir, a estrutura consiste em duas camadas: Feature Extractor e Landscape Predictor.

Extrator de características (3 camadas): Primeiro, ele mapeia os recursos originais no espaço latente, onde os recursos categóricos são incorporados (por codificação one-hot) e concatenados com recursos numéricos normalizados. Em seguida, os recursos de 2ª ordem são extraídos dele pelo Extrator de Recursos de 2ª ordem. Para os recursos de alta ordem, um conjunto de camadas totalmente conectadas é aplicado.
Preditor de paisagem: concatena os vetores de características de 1ª, 2ª e alta ordem e os alimenta em uma camada Softmax para prever as probabilidades de o preço vencedor cair em cada balde de preço.
Os autores testaram a solução proposta usando conjuntos de dados públicos IPinYou e YOYI e, em seguida, a compararam com seis linhas de base conhecidas, incluindo o modelo DLF. Para métricas de ANLP e índice C, o ADM supera o DLF em ambos os conjuntos de dados. Além disso, os tempos de execução relatados foram da ordem de 5 ms para 99% dos casos de teste, em perfeita concordância com o SLA usual de 10 ms. 😎
Desafios futuros para o setor de RTB
A ascensão do anonimato na Internet está claramente se tornando um árduo desafio para o setor de publicidade digital. Embora os usuários tenham a garantia de uma melhor experiência sem rastreamento na web, os anunciantes são forçados a encontrar novas maneiras de gerar conteúdo personalizado e adotar o RTB.
Como você deve ter ouvido, O Google anunciou a remoção de cookies de terceiros para 2023. Consequentemente, os anunciantes não poderão usar cookies de terceiros para rastrear usuários no navegador Chrome, que atualmente representa mais de 63% da participação de mercado global.
Impressões digitais de trânsito
Sobre este assunto, em maio de 2022 com a submissão do artigo “Melhorando a lucratividade dos anúncios usando impressões digitais de tráfego”, o conceito de impressões digitais de trânsito foi introduzido como uma forma de representar o tráfego diário de uma web. O objetivo principal era melhorar o desempenho da campanha sem depender das informações do usuário — impulsionado pela ideia de um cenário de erradicação de cookies de terceiros.
Conforme definido pelos autores, impressões digitais de trânsito consistem em vetores normalizados de 24 dimensões que visam representar a distribuição diária do tráfego do site. Em outras palavras, a quantidade de cliques recuperados por hora por site. O uso desses vetores permite a detecção de domínios de anúncios não lucrativos.
“O principal objetivo do algoritmo é selecionar páginas da web (domínios) que não sejam lucrativas e os anúncios devem ser impedidos de aparecer nessas páginas da web.” [5]
Uma vez impressões digitais de trânsito são coletados, o algoritmo proposto é o seguinte:
- Clusterização: com base em impressões digitais de tráfego, os domínios são divididos em grupos usando o agrupamento k-means.
- Regras de negócios: ao analisar as estatísticas do cluster e avaliar seu desempenho de hora em hora, regras de negócios são criadas para determinar quais grupos tiveram pior desempenho e em qual período de tempo.
- Bloqueio temporal: clusters que apresentam baixo desempenho são então temporariamente bloqueados dos algoritmos RTB em intervalos de tempo específicos.
Ao adotar essas estratégias, os autores relataram ter alcançado um aumento de 40% no lucro 🤑
Considerações finais
Concluindo, exploramos a estrutura RTB e os principais conceitos por trás dela. O post tem como objetivo destacar o que consideramos as soluções mais promissoras em termos de otimização de preços de licitações.
Certamente, um de seus maiores desafios está na extrema sensibilidade temporal envolvida nas respostas da DSP durante o leilão. Nesse assunto, a estrutura de Modelagem de Distribuição Adaptativa (ADM) parece ser uma abordagem perspicaz de última geração. Além disso, a adoção das estratégias gratuitas de cookies na estrutura parece ser uma medida sensata, especialmente após o anúncio do Google.
A licitação em tempo real (RTB) é uma questão desafiadora e, definitivamente, uma excelente oportunidade para aplicar técnicas de aprendizado profundo. À medida que o setor se torna mais maduro, surgem mais desafios e oportunidades de pesquisa frutíferas.
Referências
[1] Google: melhores práticas para aplicativos RTB [2] Como a latência de rede afeta o processo RTB da Adtech [3] Previsão profunda do cenário para publicidade em licitações em tempo real [4] Modelagem de distribuição arbitrária com censura em anúncios de licitações em tempo real [5] Melhorando a lucratividade dos anúncios usando impressões digitais de tráfego



.png)