
Búsqueda de productos: Encontrar algunas agujas en un pajar




Introducción
¿Alguna vez te has preguntado qué tan rápido puedes enseñarles a tus amigos ese impresionante sofá que acabas de comprar sin guardar el enlace a la publicación de antemano? ¿Y cómo encontraste ese sofá en particular entre una amplia variedad de sofás que ni siquiera sabías que existían? Ahí es donde entra en juego la búsqueda de productos. La búsqueda de productos es un caso de uso en los motores de búsqueda. Estos motores nos permiten escribir una consulta en lenguaje natural y realizar el trabajo pesado por nosotros: buscar entre millones e incluso miles de millones de resultados posibles y seleccionar los que son más relevantes para nuestra consulta de búsqueda. Pero, ¿cómo pueden estos motores de búsqueda analizar muchos resultados posibles casi en tiempo real y, aun así, obtener resultados relevantes? ¿Cómo identifican la relevancia? Estamos abordando estos problemas y más a lo largo de este blog, primero desde una perspectiva de alto nivel y luego profundizando en detalles más técnicos.
¿Qué son los motores de búsqueda?
Motores de búsqueda frente a sistemas de recomendación
Cuando buscamos ciertos productos, generalmente podemos encontrar dos tipos de resultados. Uno puede estar relacionado con el producto en sí, digamos que quieres comprar un teléfono móvil nuevo, por lo que escribes la consulta «iPhone 12". Entonces, los resultados más relevantes podrían ser diferentes variaciones del iPhone 12, en términos de capacidad de memoria, color y otros factores. Sin embargo, también pueden obtenerse otros resultados, como fundas para iPhone 12 y vidrio templado para proteger su teléfono. Se trata de otro tipo de resultados, más relacionados con las recomendaciones que con la búsqueda de productos en sí. El primer problema lo gestionan los motores de búsqueda de productos, mientras que el segundo lo hace Recommender Systems. A primera vista, la diferencia entre un motor de búsqueda y un sistema de recomendación (RecSys) puede resultar un poco borrosa, sin embargo, tienen diferentes propósitos. Los sistemas de recomendación o sistemas de recomendación hacen sugerencias relacionadas con el historial de búsqueda de cada usuario creando perfiles de clientes y almacenando los metadatos pertinentes, ya sea comparando los elementos en función de experiencias anteriores (filtrado basado en contenido), mediante el uso de información de otros usuarios con un comportamiento similar en línea (filtrado colaborativo), o un enfoque híbrido que incluya a estos dos. Los sistemas de recomendación tienden a centrarse en resolver problemas como:
- Escasez de datos: para tener un sistema eficaz, normalmente es necesario que un gran número de usuarios interactúen con el sitio web. Estas personas podrían tener una gran influencia en el funcionamiento del motor de recomendación.
- Big Data: Por lo general, los sitios web que utilizan RecSys tienen que procesar enormes cantidades de datos, incluidos los datos de los elementos, los datos de los usuarios, los metadatos y más.
- Arranque en frío: si un nuevo usuario o un producto totalmente diferente al resto ingresa a este mar de información, es imposible asociar su información a otras entidades relacionadas. Además, según el minorista, pueden pasar meses hasta que se acumulen suficientes datos de comportamiento para empezar a crear un RecSys personalizado. De ahí viene este problema de arranque en frío.
Los motores de búsqueda tienden a centrarse en resolver problemas como:
- Indexación eficiente: se utiliza para localizar datos rápidamente sin tener que revisar cada fila de una tabla de base de datos cada vez que se accede a la tabla.
- Reglas de clasificación de atributos: clasificar los resultados según su relevancia esperada para la consulta de cada usuario, mediante una combinación de métodos dependientes e independientes de la consulta.
- Limpieza de datos: a partir de la consulta del usuario, recupera la información más importante, sin tener en cuenta aquellas palabras que no añaden valor a la intención de la consulta o al significado semántico en sí mismo. Algunas técnicas, como detener la eliminación de palabras y eliminar acentos y caracteres especiales, son muy útiles.
- Coincidencia difusa: coincidencias aproximadas de cadenas (por ejemplo, «iphone» vs «iphone»). Existen varias técnicas para resolver este problema, aunque la más común podría ser usar Distancia de Levensthein.
- Coincidencia no difusa: para capturar palabras que normalmente hacen referencia a conceptos similares pero que no se escriben casi exactamente igual. Estas técnicas incluyen: la derivación, la lematización y la tokenización.
En resumen, mientras los motores de búsqueda ayudan a los usuarios a encontrar lo que buscan, los sistemas de recomendación ayudan a los usuarios a encontrar más de lo que les gusta o alternativas relevantes. Sin embargo, los motores de búsqueda tienden a adoptar un cierto grado de recomendación entre sus resultados, por lo que no es raro que los usuarios vean ambos resultados de búsqueda mezclados con recomendaciones. Veamos un ejemplo para mayor claridad:

RESULTADOS DE BÚSQUEDA



En este caso, podemos observar que las tres mesas de comedor son mesas nórdicas negras, donde las dos primeras pueden ser del mismo producto pero con imágenes diferentes tomadas y la tercera mesa es rectangular en lugar de redondeada.
RESULTADOS DEL RECOMENDADOR


Aquí podemos ver sillas y decoraciones que tienen sentido dada la búsqueda. En otras palabras, entendemos correctamente lo que busca el usuario y pensamos en nuevos artículos que podría tener sentido considerar comprar al mismo tiempo, mientras que en los resultados de búsqueda solo nos centramos en lo que la persona está buscando.
Casos de uso de motores de búsqueda
Usamos motores de búsqueda a diario. Desde esos podcasts que escuchas mientras te levantas, hasta esa serie de Netflix que tu mejor amigo te ha estado recomendando durante meses y la buscaste para, por fin, empezar a verla. Vamos a profundizar en algunos ejemplos reales de motores de búsqueda con los que solemos interactuar.
Este no necesita presentación, ya que más del 86% de la cuota de mercado de búsquedas, Google tenía que ocupar el primer lugar de la lista. La búsqueda en Google se divide en tres fases, dos de las cuales tienen lugar mucho antes de que se ejecute una consulta de búsqueda:
- Arrastrándose: La primera etapa consiste en averiguar qué páginas existen en la web. Como no hay un registro de todas las páginas web, el primer paso es averiguar qué webs existen. Una vez que Google descubre una página nueva, puede «rastrearla» para recuperar la información relevante y averiguar qué contiene.
- Indexación: La segunda etapa consiste en guardar toda esta información, «indexarla» para poder encontrarla rápidamente.
- Sirviendo los resultados de la búsqueda: La etapa final consiste en buscar índices cuyo contenido coincida y arrojar los resultados que se consideran de mayor calidad y más relevantes para el usuario. La relevancia viene determinada por cientos de factores, entre los que se incluyen la ubicación, el idioma y el dispositivo del usuario (ordenador de sobremesa o teléfono). Por ejemplo, al buscar»talleres de reparación de bicicletas«mostraría resultados diferentes a un usuario de Buenos Aires y a un usuario de Montevideo.
YouTube
A pesar de algunos conceptos erróneos sobre los algoritmos de YouTube, no utilizan imágenes y vídeos para la búsqueda, solo texto y código. Esto se debe a una sencilla razón: los vídeos son colecciones de imágenes apiladas de forma secuencial, y las imágenes son mucho más costosas desde el punto de vista computacional y de procesamiento que el texto. Si sumamos esto al volumen de vídeos de la plataforma, es casi imposible lograr buenos resultados en aplicaciones prácticamente reales mediante el análisis de vídeos. Sin embargo, hay varias fuentes que este buscador tiene en cuenta para los resultados de clasificación: títulos, etiquetas, descripciones, subtítulos, entre otros.
Amazon
Cuando se trata de compras en línea, la búsqueda de productos en Amazon es la ganadora indiscutible, incluso en comparación con Google. Alrededor del 61% de los consumidores estadounidenses comienzan a buscar productos en Amazon, casi el 45% en un motor de búsqueda como Google (y otros) y el 32% en Walmart. Además, cuando buscan productos en un motor de búsqueda, Amazon suele aparecer entre los principales resultados de búsqueda recomendados. ¿Qué datos utiliza Amazon en sus motores de búsqueda? Algunas de las variables utilizadas son: las palabras clave, las impresiones sobre el producto, las ventas, la tasa de clics (CTR), la tasa de conversión y las opiniones de los clientes, entre otras.
Otras menciones honoríficas
Otras empresas conocidas que utilizan motores de búsqueda con los que interactuamos a diario son:
- Facebook: cuando buscas un amigo, un grupo e incluso en Marketplace.
- Linkedin: principalmente para buscar entre cientos de millones de candidatos.
- Baidu: es el buscador más utilizado en China, con grandes inversiones en IA para diferentes propósitos.
- Pinterest: esta plataforma se creó para descubrir una amplia gama de contenido que se centra en la estética, desde ideas (recetas de cocina, decoración del hogar, etc.) hasta productos.
Conceptos y desafíos principales
Recordemos el objetivo del algoritmo de los motores de búsqueda: para presentar un conjunto relevante de resultados de búsqueda de alta calidad para cumplir con las consultas de los usuarios lo más rápido posible.
Intención de la consulta
La intención de la consulta responde a la pregunta: ¿cuál es la intención del usuario al realizar esta consulta? Estas intenciones se pueden agrupar, en líneas generales, en cuatro categorías:
- Consultas exactas (de navegación): se producen cuando el usuario sabe a qué producto quiere llegar y utiliza la consulta de búsqueda como medio para encontrar el producto deseado.
«Nevera Samsung Frost Free RF27T5501SG con inversor»
- Consultas de dominio (informativas): se producen cuando el usuario quiere informarse sobre diferentes productos que están agrupados dentro de un determinado dominio o grupo de productos. El objetivo no es comprar, aunque esto podría suceder, sino adquirir conocimiento de las opciones disponibles.
«Plantas de interior»
- Consultas sintomáticas: esto ocurre cuando el usuario tiene un problema que quiere resolver, pero no tiene un conocimiento claro de qué producto puede resolver el problema.
«Alfombra manchada»
- Consultas temáticas: estas consultas suelen ser difíciles de definir, ya que son de naturaleza intrínsecamente vaga y algunas incluyen algunos límites difusos, que hacen referencia a ubicaciones, condiciones estacionales o ambientales, eventos especiales o promocionales, entre otros.
«Vasos de plástico de Halloween»
Principales desafíos
Algunos de los principales desafíos a tener en cuenta al tratar con los motores de búsqueda de productos son:
- Velocidad: los resultados suelen mostrarse entre 0,5 y 3 segundos mientras se carga la página web.
- Escasez: hay muchos productos con los que comparar, de ahí el uso de prefiltros e indexaciones para comparar la consulta con las más relevantes.
- Idioma: las consultas pueden ser o contener palabras de diferentes idiomas. Tener capacidades multilingües podría ser deseable, más aún si el sitio web atrae a usuarios de diferentes países.
- Unidades de medida: cuando un usuario busca un producto capilar con 0,7 L de volumen, el buscador debe asociar que 700 ml se refieren al mismo valor de la misma magnitud.Robustez en la ortografía: esto podría incluir:
-
- Errores ortográficos: «granada» en lugar de «granada».
- Errores de escritura: al intercambiar letras o escribir mal las letras que están cerca una de la otra en el teclado. Por ejemplo: «sofá negro» o «lámpara de pie».
- Sinónimos: «piscina inflable circular» y «piscina inflable redondeada»
- Variaciones morfológicas: «rojo» y «rojizo»
-
- Dificultades que dependen del idioma: también hay algunas dificultades adicionales que pueden surgir según los idiomas con los que trabajemos. Por ejemplo, en alemán, es habitual apilar muchas palabras para crear una nueva (palabras compuestas), lo que podría ocasionar algunos problemas.
Es bueno tenerlo
También podría ser conveniente:
- Comprenda la forma de escribir de cada usuario para comprender mejor la intención y el contenido relevante de sus consultas.
- Captura palabras fonéticamente similares: «bluetooth» y «blututh».
- Tenga cierta capacidad de interpretación de los resultados para detectar dónde hay margen de mejora en futuras iteraciones del motor de búsqueda.
- Enfoques de estacionalidad, que utilizan tendencias según las cuales es más probable que se busquen los productos según la estación del año.
¿Cómo funcionan los motores de búsqueda de productos?
En esta sección nos adentraremos en aspectos más técnicos para analizar en profundidad cómo se diseñan estas soluciones. Como los productos deben mostrarse en un orden determinado, esto introduce la noción de clasificación, es decir, ordenar los documentos (en este caso, los productos) por relevancia para encontrar contenidos de interés con respecto a la consulta del usuario. Este es un problema fundamental en el campo de Recuperación de información. Los modelos de clasificación suelen funcionar prediciendo una puntuación de relevancia (s) para cada entrada (x), donde la entrada depende de una consulta (q) y un documento (d).
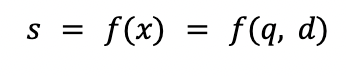
Una vez que tenemos la relevancia de cada documento, podemos ordenar (es decir, clasificar) los documentos de acuerdo con estas puntuaciones, para mostrar primero los resultados más relevantes. El modelo de puntuación se puede implementar utilizando varios enfoques, pero dos de los más populares son:
- Aprender a clasificar (LTR): utilizando un algoritmo de aprendizaje automático como XGBoost, en el que el modelo aprende a predecir la puntuación de la asociación a partir de una consulta y un documento, aprendiendo a minimizar ciertas pérdidas que se introducirán en breve.
- Modelos espaciales vectoriales: estos modelos calculan una incrustación vectorial (por ejemplo, usando TF-IF, Word2Vec o BERTA) para cada consulta y documento y, a continuación, calcule la puntuación de relevancia con alguna métrica de distancia entre las incrustaciones vectoriales, como similitud de coseno.
Limpieza de datos
Antes de utilizar cualquier tipo de modelo, es conveniente realizar una limpieza de datos y utilizar un poco de preprocesamiento de texto a medida que los usuarios escriben las consultas, que suelen tener errores tipográficos, ortográficos y otros tipos de ruido en el modelo. Esta es la razón por la que muchos periódicos recomiendan realizar algunas limpiezas, entre ellas:
- Preprocesamiento básico de texto: convierte texto a minúsculas, elimina las acentuaciones como guiones en español, elimina los espacios en blanco finales, los caracteres especiales, entre otras transformaciones. En este sentido, Código Unidecode puede ser extremadamente útil.
- Procedimiento/lematización: Estas técnicas se pueden utilizar para hacer variaciones de la misma palabra raíz y convertirlas en la misma palabra escrita exacta, lo que puede ayudar al algoritmo a entrenar para asociar estas palabras, ya que tienen significados semánticos similares. Una de nuestras herramientas favoritas para este tipo de tareas es Espacio Y.
- Eliminación de palabras clave: en algunos casos, puede resultar útil eliminar palabras que no añadan valor a la intención semántica de la consulta. Una vez más, SPACy puede ayudar en esta tarea.
- Estandarización de unidades de medida: en el comercio electrónico en particular, es bastante común tener diversas unidades de medida y posibles conversiones. Esto también podría ir en detrimento de la capacidad de aprendizaje de los modelos, de ahí la necesidad de un buen preprocesamiento mediante la estandarización de los mismos. Bibliotecas como 1 pinta y Quantum 3 es muy útil para este paso.
Aprender a clasificar
Teniendo en cuenta que, para la búsqueda de productos, nuestros documentos (d) representar los productos y las consultas (q) son la consulta de búsqueda escrita por el usuario, los enfoques más comunes para entrenar un modelo LTR son:
- Métodos puntuales: donde el problema de aprendizaje supervisado se considera un problema de regresión, donde para cada par consulta-documento, hay una etiqueta de tipo flotante que representa qué tan similares son la consulta y el documento, y el modelo intenta aprender estos patrones en los datos. También hay versiones discretas de los métodos Pointwise en las que la similitud se discretiza entre un rango determinado, por ejemplo, del 1 al 10.
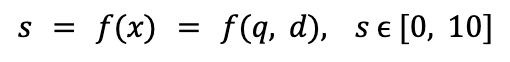
- Métodos por pares: aunque la tarea de regresión puede considerarse la más intuitiva, es muy poco probable que tenga datos etiquetados para esa forma de entrenamiento. Por lo tanto, otro enfoque consiste en determinar qué producto es más similar a la consulta si hay dos productos (d1 y d2).
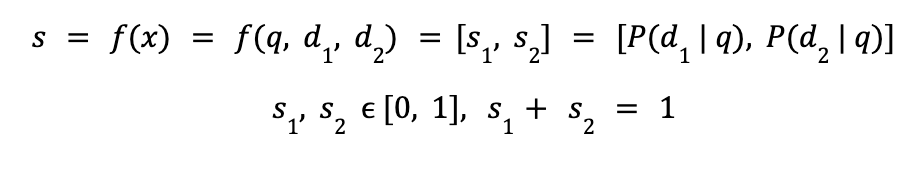
- Métodos por listas: en estos métodos, en lugar de transformar el problema de clasificación en una tarea de regresión o clasificación, los métodos Listwise resuelven el problema de forma más directa al maximizar la métrica de evaluación.
Modelos espaciales vectoriales
Estos enfoques son métodos estadísticos tradicionales, como el TF-IDF, o dependen del entrenamiento de un modelo de aprendizaje automático en una tarea auxiliar para aprender una representación deseable de consultas y documentos en un espacio vectorial. Por lo general, esta tarea auxiliar es una tarea de clasificación, pero al eliminar la última capa de clasificación (o incluso alguna más), el modelo puede convertir las entradas de estas prácticas representaciones de datos, denominadas incrustaciones.
Word2Vec
La eficacia de Word2Vec proviene de su capacidad para agrupar vectores de palabras similares. Esto se basa en la hipótesis de que cada palabra de una frase está condicionada por las palabras de su entorno (contexto). Hay dos formas principales de entrenar Word2Vec, pero veamos la más intuitiva: Continuous Bag of Words (CBOW).

Arquitectura CBOW, tomada del documento Word2Vec
En la imagen de arriba, la entrada es una frase con cinco palabras, donde la palabra central no se asigna al modelo, y el objetivo del modelo es predecir qué palabra debe estar en el medio de esa frase. De manera inherente, esto hace que los parámetros aprendan las frecuencias y correlaciones entre las palabras que se suelen usar juntas en las frases, y que los vectores que representan cada palabra tengan algunas propiedades semánticas y sintácticas deseables, como las que se muestran a continuación:
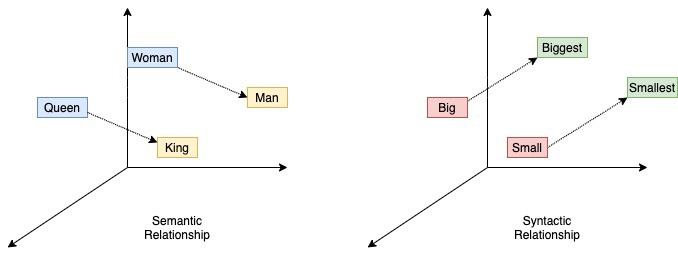
Incrustaciones de palabras: relaciones semánticas y sintácticas
Luego, con estas representaciones, podemos crear incrustaciones para cada palabra y usar algunas heurísticas para definir una incrustación para toda la consulta o el producto. Luego, comparamos estas incrustaciones para determinar la clasificación que se mostrará.
Codificadores
Hemos mencionado BERTA ya que es una de las arquitecturas de transformadores de codificación más utilizadas, pero cualquier codificador podría tener el mismo propósito. La idea subyacente es utilizar BERT como columna vertebral de la arquitectura y, a continuación, añadir un cabezal de clasificación o regresión para entrenar el modelo tal como se indica en los métodos PointWise y Pairwise. Veamos un ejemplo de la arquitectura:
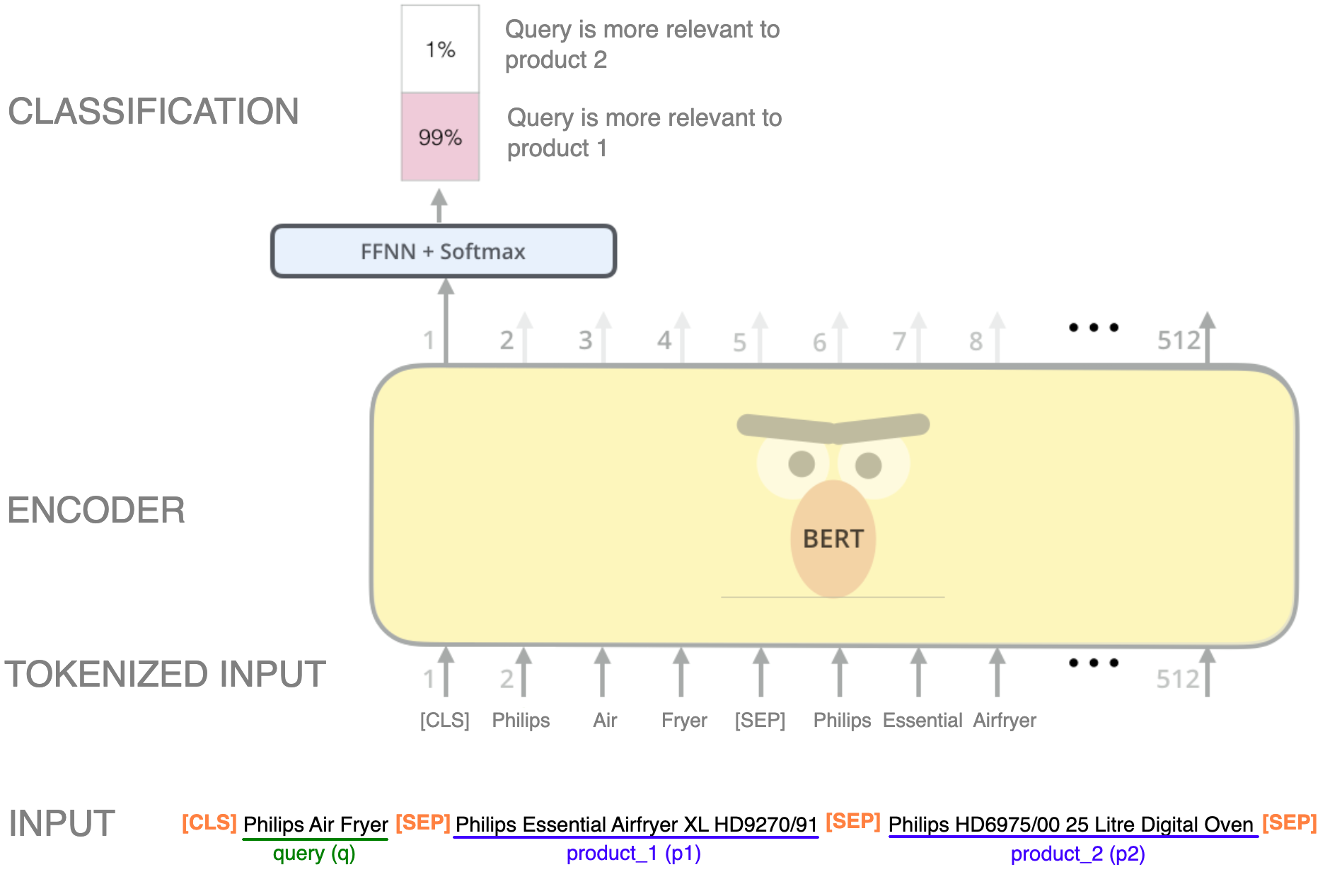
Imagen modificada de Jay's Alammar blog en BERT.
En este ejemplo, utilizamos un enfoque por pares para clasificar si la consulta es más relevante para el producto 1 o para el producto 2. Para lograrlo, una posibilidad es entrenar el modelo utilizando una estructura similar a la de la predicción de la próxima oración (NSP), que es una de las formas en que se preentrena el BERT, pero con tres frases: la consulta, el producto 1 y el producto 2, cada una separada por el símbolo de separación especial [SEP]. Por lo general, se evitan los transformadores debido a que son modelos pesados con millones de parámetros. Pero en algunos casos, con tan solo reducir el número de capas de codificación dentro de su arquitectura, se pueden obtener buenos resultados y se reduce la secuencialidad, que requiere más tiempo y recursos. El documento en el que se presentó la arquitectura de los transformadores,»La atención es todo lo que necesitas«, usa 6 capas codificadoras apiladas para el bloque codificador, pero con 1 o 2 capas podría ser suficiente para este propósito. Un ejemplo de esto se puede ver en el artículo titulado»Transformador de secuencia de comportamiento para la recomendación de comercio electrónico en Alibaba«del grupo de búsqueda y recomendación de Alibaba de Alibaba. Aunque este artículo hace referencia a un sistema de recomendación, los mismos conceptos se pueden aplicar a los motores de búsqueda. Sin embargo, al igual que en el ejemplo en el que los productos deben indicarse por pares, en el momento de utilizar la inferencia del modelo, también se deben dar estos dos productos. Otras opciones son usar este entrenamiento como entrenamiento previo y ajustar el codificador para otra tarea posterior, o simplemente usar el codificador sin el cabezal de clasificación, como hicimos con Word2Vec. Si se utiliza este tipo de datos, el número de comparaciones puede crecer de forma exponencial, por lo que este modelo solo podría utilizarse cuando se recuperen primero los productos más relevantes, por ejemplo, unos cientos de productos para realizar una comparación detallada. Al igual que en Word2Vec, la última capa de clasificación con la función de activación de Softmax se puede eliminar para obtener consultas e incrustar documentos.
Literatura relevante
La siguiente es una lista seleccionada de artículos que resultaron interesantes para investigar soluciones viables de búsqueda de productos que pudieran escalarse en millones e incluso miles de millones de productos de catálogo y, al mismo tiempo, tener un excelente rendimiento.
Búsqueda semántica de productos
En este artículo, la relevancia de los productos en una consulta de búsqueda se modeló como un problema de regresión utilizando una red siamesa:
- Los autores utilizan Bolsa de palabras (BoW) compartido junto con las consultas y los productos, para luego crear un espacio de incrustación compartido con una agrupación promedio. Esta es la base para entrenar a la red siamesa con la similitud de cosenos.
- A 3 partes Pérdida de bisagra se utiliza para distinguir entre productos comprados, productos en los que no se ha hecho clic y productos en los que no se ha hecho clic. En un primer momento, probaron un Hinge Loss en dos partes con productos en los que se hacía clic y en los que no, pero la información de compra les dio una visión extremadamente útil para el modelo a seguir.
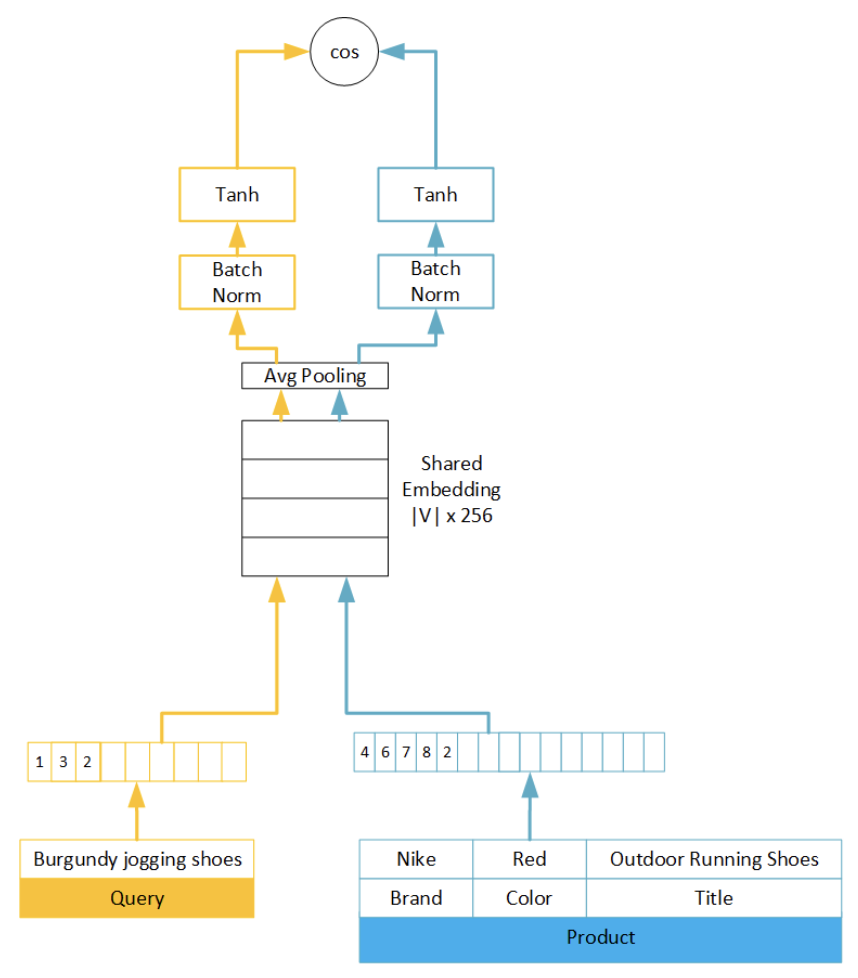
Imagen tomada del documento Semantic Product Search
Relevancia estacional en la búsqueda de comercio electrónico
Este artículo se centra en la idea de que muchos productos tienen un componente intrínsecamente estacional en sus ventas. Esto lleva a que surjan consultas que posiblemente coincidan con estas tendencias temporales, por lo que es más probable que un usuario busque un jersey de invierno a principios de invierno que en verano.
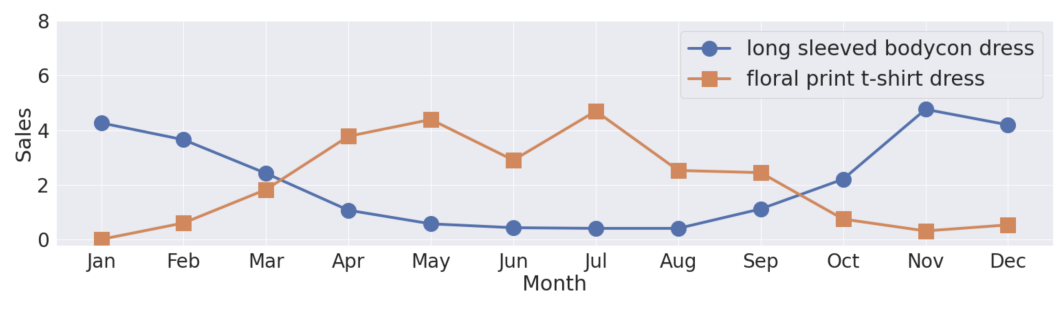
Imagen extraída del artículo de búsqueda sobre la relevancia estacional en el comercio electrónico
Aspectos destacados:
- Los autores muestran que el 39% de las consultas realizadas por los usuarios se alinean con estos componentes de estacionalidad de los productos.
- De ahí la idea de proponer características de estacionalidad para su uso en los algoritmos de búsqueda.
- Proponen una red simple de clasificación multiclase de Feed-Forward con mecanismos de atención apilados, que solo toma la consulta de entrada como entrada a la red, crea incrustaciones con Fasttext y agrega un término de estacionalidad a la pérdida categórica de entropía cruzada.
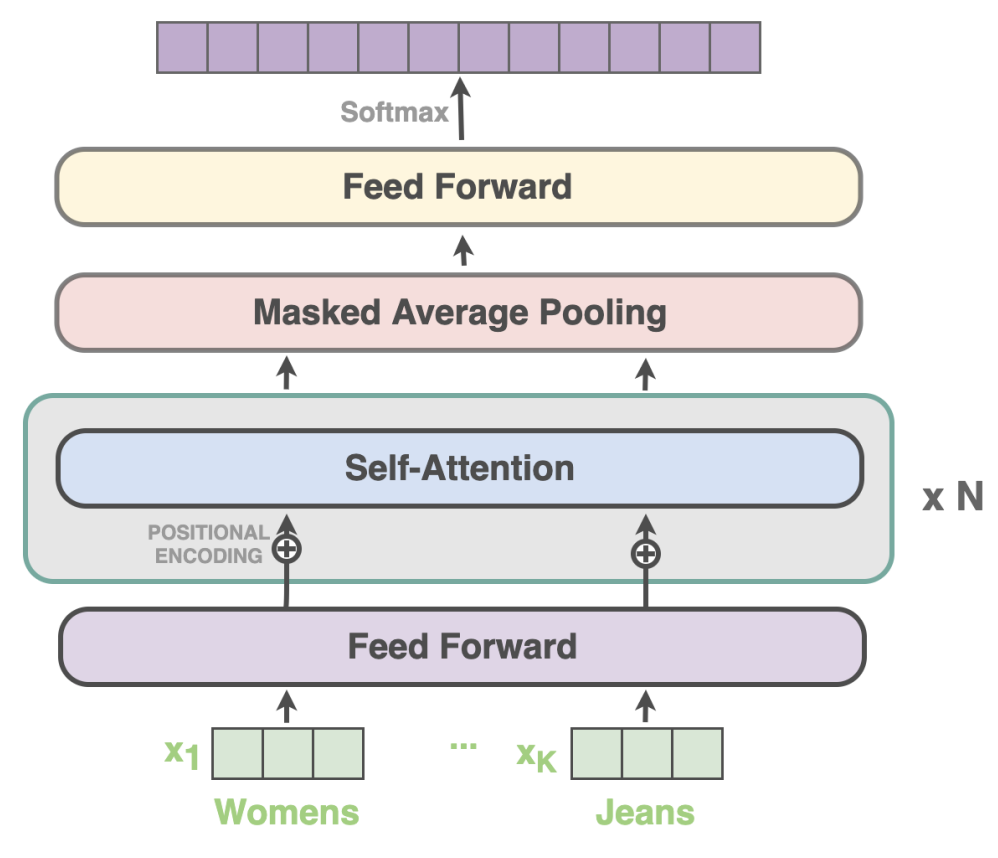
Imagen tomada del documento de búsqueda de corrección ortográfica mediante fonética en comercio electrónico
ROSE: Cachés robustos para la búsqueda de productos de Amazon
Este documento es un poco diferente del resto, ya que no se centra en el diseño del modelo, sino en cómo mejorar la experiencia del usuario con el uso de cachés inteligentes resistentes a errores tipográficos, faltas de ortografía y fenómenos similares (consultas de baja calidad) para reducir la latencia cuando los usuarios realizan búsquedas. Aspectos destacados:
- Este sistema de caché se encuentra actualmente en producción para Amazon.
- Los autores proponen mapear consultas de baja calidad con consultas de alta calidad, manteniendo solo las consultas de alta calidad en caché. Para indexar y capitalizar la similitud semántica de estas consultas, un Hashing sensible a la localidad (LSH) se celebra, según lo propuesto por el enfoque de vecinos más cercanos aproximados (ANN).
- Algunas palabras, como los atributos del producto, se ponderan más que otras para mantener esta similitud semántica, utilizando Reconocimiento de entidades nombradas (NER) técnicas.
Corrección ortográfica mediante fonética en la búsqueda de comercio electrónico
En este artículo, los autores hablan de la realidad de que la mayoría de las soluciones que involucran a los motores de búsqueda se centran en las ruidosas consultas de texto que los usuarios escriben, pero no tienen en cuenta los errores fonéticos. Por ejemplo, cuando una pareja de ancianos intenta encontrar los auriculares con la palabra «blutut» que su nieta quería para Navidad. Aspectos destacados:
- Los problemas con el texto se pueden resolver con una distancia de edición, n-gramas o incluso incrustaciones de palabras, pero los errores fonéticos son bastante más difíciles de abordar.
- Al igual que la distancia de Levenshtein para la similitud textual de las palabras, los autores proponen el uso de la distancia entre el sonido de las palabras, como Soundex.
- Proponen utilizar un modelo basado en árboles, como XGBoost, para corregir la consulta escrita teniendo en cuenta ambas distancias (textual y sonora) con un algoritmo de búsqueda de candidatos eficiente.
Por ejemplo:
Sin similitud fonética: la consulta «blutut sant systam» obtuvo 82 resultados, corrigiéndola a «blututh sent system»
Añadiendo similitud fonética: la consulta «blutut sant systam» obtuvo más de 9000 resultados, corrigiéndola a «sistema de sonido bluetooth»
Reflexiones finales
¡Esa fue mucha información para asimilar! Pero esperamos que con este blog hayas podido comprender, a un nivel superior, los conceptos clave en torno a la búsqueda de productos, las diferencias entre los motores de búsqueda y los sistemas de recomendación y los principales aspectos y desafíos a tener en cuenta al crear un motor de búsqueda de productos. Si te interesaba lo suficiente como para continuar con los detalles más técnicos sobre lo último en búsqueda de productos, esperamos que este blog te haya dado algunas ideas sobre las decisiones que hay que tomar para crear un motor de búsqueda escalable y eficaz, junto con algunas ideas sobre cómo podemos empezar a probar a la hora de modelar estas soluciones. ¡Estén atentos para obtener más contenido!
Referencias
- Alexander Reelsen, «Una búsqueda moderna de comercio electrónico» (junio de 2020). https://spinscale.de/posts/2020-06-22-implementing-a-modern-ecommerce-search.html
- Baymard Institute, «Deconstruyendo la experiencia de usuario de búsqueda de comercio electrónico: los 8 tipos de consultas de búsqueda más comunes (el 42% de los sitios tienen problemas)» (julio de 2022). https://baymard.com/blog/ecommerce-search-query-types
- Francesco Casalegno, «Aprender a clasificar: una guía completa para clasificar mediante el aprendizaje automático» (febrero de 2022). https://towardsdatascience.com/learning-to-rank-a-complete-guide-to-ranking-using-machine-learning-4c9688d370d4
- Central de búsquedas de Google,»Guía detallada sobre cómo funciona la Búsqueda de Google» (octubre de 2022). https://developers.google.com/search/docs/fundamentals/how-search-works
- Loop 54, «La diferencia entre los motores de búsqueda de productos y los motores de recomendación de productos» (octubre de 2016). https://www.loop54.com/knowledge-base/product-search-engines-product-recommendation-engines-differences
- Mangool, «Motores de búsqueda» (enero de 2021). https://mangools.com/blog/search-engines
- Pinterest,»Todo sobre Pinterest» (julio de 2022). https://help.pinterest.com/en/guide/all-about-pinterest #
- Revista de motores de búsqueda,»Conoce los 7 motores de búsqueda más populares del mundo» (marzo de 2021). https://www.searchenginejournal.com/seo-guide/meet-search-engines
- Telus,»¿Qué son los motores de búsqueda en el aprendizaje automático?» (febrero de 2021). https://www.telusinternational.com/articles/what-are-search-recommendation-systems-in-machine-learning #
- Interpretación web,»Conoce el motor de búsqueda de Amazon para impulsar más ventas» (Agosto de 2022). https://www.webinterpret.com/us/blog/ecommerce-product-searches-amazon-google/



.png)