
Pesquisa de produto: Encontrando algumas agulhas em um palheiro




Introdução
Você já se perguntou com que rapidez você pode mostrar aos seus amigos aquele sofá deslumbrante que você acabou de comprar sem salvar o link da postagem de antemão? E como você encontrou aquele sofá em particular em uma grande variedade de sofás que você nem sabia que existiam? Essa é a Pesquisa de Produtos entrando em cena. A pesquisa de produtos é um caso de uso nos mecanismos de pesquisa. Esses mecanismos nos permitem digitar uma consulta em linguagem natural e realizar o trabalho pesado para nós, analisando milhões e até bilhões de resultados possíveis e selecionando aqueles que são mais relevantes para nossa consulta de pesquisa. Mas como esses mecanismos de pesquisa analisam muitos resultados possíveis quase em tempo real e ainda obtêm resultados relevantes? Como eles identificam a relevância? Estamos abordando esses problemas e muito mais ao longo deste blog, primeiro de uma perspectiva de alto nível e depois nos aprofundando em detalhes mais técnicos.
O que são mecanismos de pesquisa?
Mecanismos de pesquisa versus sistemas de recomendação
Quando procuramos determinados produtos, geralmente dois tipos de resultados podem ser encontrados. Uma pode estar relacionada ao produto em si, digamos que você queira comprar um celular novo, então você digita a consulta “iPhone 12”. Então, os resultados mais relevantes podem ser diferentes variações do iPhone 12, em termos de capacidade de memória, cor e outros fatores. No entanto, outros resultados também podem surgir, como capas para iPhone 12 e vidro temperado para proteger seu telefone. Esses são outros tipos de resultados, mais relacionados às recomendações do que à busca de produtos em si. O primeiro problema está sendo tratado pelos mecanismos de busca de produtos, enquanto o segundo pela Recommender Systems. À primeira vista, a diferença entre um mecanismo de pesquisa e um sistema de recomendação (RecSys) pode ser um pouco confusa, mas eles servem a propósitos diferentes. Sistemas de recomendação ou sistemas de recomendação fazem sugestões relacionadas ao histórico de pesquisa de cada usuário criando perfis de clientes e armazenando metadados relevantes, comparando itens com base em experiências anteriores (filtragem baseada em conteúdo), usando informações de outros usuários com comportamento on-line semelhante (filtragem colaborativa), ou uma abordagem híbrida envolvendo esses dois. Os sistemas de recomendação tendem a se concentrar na solução de problemas como:
- Esparsidade de dados: para ter um sistema eficaz, você geralmente precisa ter um grande número de usuários interagindo com o site. Essas pessoas podem ter uma grande influência no funcionamento do mecanismo de recomendação.
- Grande volume de dados: normalmente, os sites que usam o RecSys precisam lidar com grandes quantidades de dados, incluindo dados de itens, dados de usuários, metadados e muito mais.
- Arranque a frio: se um novo usuário ou um produto totalmente diferente dos demais entrar nesse mar de informações, é impossível associar suas informações a outras entidades relacionadas. Além disso, dependendo do varejista, pode levar meses para acumular dados de comportamento suficientes para começar a criar um RecSys personalizado, daí esse problema de inicialização a frio.
Os mecanismos de pesquisa tendem a se concentrar na solução de problemas como:
- Indexação eficiente: usado para localizar dados rapidamente sem precisar percorrer cada linha em uma tabela de banco de dados toda vez que a tabela é acessada.
- Regras de classificação de atributos: classificando os resultados de acordo com a relevância esperada para a consulta de cada usuário, usando uma combinação de métodos dependentes e independentes da consulta.
- Limpeza de dados: a partir da consulta do usuário, recupere as informações mais importantes, desconsiderando aquelas palavras que não agregam valor à intenção da consulta ou ao significado semântico em si. Algumas técnicas, como remoção de palavras interrompidas e remoção de acentos e caracteres especiais, são muito úteis.
- Correspondência difusa: correspondências aproximadas de strings (por exemplo, “iphone” vs “iphone”). Existem várias técnicas para lidar com esse problema, enquanto a mais comum pode ser usar Distância de Levensthein.
- Correspondência não difusa: para capturar palavras que geralmente se referem a conceitos semelhantes, mas não são escritas quase exatamente da mesma forma. Essas técnicas incluem: derivação, lematização e tokenização.
Em resumo, enquanto os mecanismos de pesquisa ajudam os usuários a encontrar o que querem, os sistemas de recomendação ajudam os usuários a encontrar mais do que gostam ou alternativas relevantes. No entanto, os mecanismos de pesquisa tendem a adotar um certo grau de recomendação entre seus resultados, portanto, não é incomum que os usuários vejam os dois resultados da pesquisa misturados às recomendações. Vamos dar uma olhada em um exemplo para maior clareza:

RESULTADOS DA PESQUISA



Nesse caso, podemos observar que todas as três mesas de jantar são mesas de jantar pretas da Northern, onde as duas primeiras podem ser o mesmo produto, mas com imagens diferentes tiradas, e a terceira mesa é retangular em vez de arredondada.
RESULTADOS RECOMENDADOS


Aqui podemos ver cadeiras e decorações que fazem sentido, dada a pesquisa. Em outras palavras, entendemos corretamente o que o usuário está procurando e pensamos em novos itens que podem fazer sentido considerar comprar ao mesmo tempo, enquanto nos resultados da pesquisa nos concentramos apenas no que a pessoa está procurando.
Casos de uso de mecanismos de pesquisa
Usamos mecanismos de busca diariamente. Desde os podcasts que você ouve enquanto acorda até a série da Netflix que seu melhor amigo recomenda há meses e você pesquisou para finalmente começar a assistir. Vamos nos aprofundar em alguns exemplos reais de mecanismos de pesquisa com os quais geralmente interagimos.
Este quase não precisa de introdução, com mais de 86% da participação no mercado de buscas, o Google tinha que estar no topo da lista. A pesquisa do Google é dividida em três fases, duas das quais acontecem muito antes de uma consulta de pesquisa ser executada:
- Rastejando: A primeira etapa é descobrir quais páginas existem na web. Como não há um registro de todas as páginas da web, o primeiro passo é descobrir quais sites existem. Quando o Google descobre uma nova página, ele pode “rastreá-la” para recuperar as informações relevantes e descobrir o que está nela.
- Indexação: A segunda etapa é salvar todas essas informações, “indexá-las”, para poder encontrá-las rapidamente.
- Exibindo resultados de pesquisa: A etapa final é pesquisar índices cujo conteúdo corresponda e retornar os resultados considerados de maior qualidade e mais relevantes para o usuário. A relevância é determinada por centenas de fatores, incluindo a localização, o idioma e o dispositivo (desktop ou telefone) do usuário. Como exemplo, pesquisando por”oficinas de conserto de bicicletas“mostraria resultados diferentes para um usuário em Buenos Aires e um usuário em Montevidéu.
YouTube
Apesar de alguns equívocos sobre os algoritmos do YouTube, eles não usam imagens e vídeos para pesquisar, apenas texto e código. Isso se deve a um motivo simples: os vídeos são coleções de imagens empilhadas sequencialmente, e as imagens são muito mais computacionalmente e custam mais tempo de processar do que o texto. Somando isso ao volume de vídeos na plataforma, é quase impossível obter bons resultados para aplicativos quase reais analisando vídeos. No entanto, existem várias fontes que esse mecanismo de pesquisa leva em consideração para classificar os resultados: títulos, tags, descrições, legendas, entre outras.
Amazônia
Quando se trata de compras on-line, a pesquisa de produtos na Amazon é a vencedora indiscutível; mesmo em comparação com o Google. Cerca de 61% dos consumidores dos EUA começam sua busca por produtos na Amazon, quase 45% em um mecanismo de busca como o Google (e outros) e 32% no Walmart. Além disso, ao procurar produtos em um mecanismo de pesquisa, a Amazon geralmente aparece nos principais resultados de pesquisa recomendados. Quais dados a Amazon usa em seus mecanismos de pesquisa? Algumas das variáveis usadas são: palavras-chave, impressões sobre o produto, vendas, taxa de cliques (CTR), taxa de conversão e avaliações de clientes, entre outras.
Outras menções honrosas
Algumas outras empresas conhecidas que usam mecanismos de pesquisa com os quais interagimos diariamente são:
- Facebook: ao procurar um amigo, um grupo e até mesmo no Marketplace.
- LinkedIn: principalmente para pesquisar entre centenas de milhões de candidatos.
- Baidu: é o mecanismo de busca mais usado na China, com grandes investimentos em IA para diferentes propósitos.
- Pinterest: esta plataforma foi construída para descobrir uma ampla gama de conteúdo com foco na estética, desde ideias (receitas culinárias, decoração doméstica, etc.) até produtos.
Principais conceitos e desafios
Vamos relembrar o objetivo do algoritmo do mecanismo de busca: para apresentar um conjunto relevante de resultados de pesquisa de alta qualidade para atender às consultas dos usuários o mais rápido possível.
Intenção da consulta
A intenção da consulta responde à pergunta: qual é a intenção do usuário ao fazer essa consulta? Essas intenções podem ser amplamente agrupadas em quatro categorias:
- Consultas exatas (de navegação): elas ocorrem quando o usuário sabe qual produto deseja alcançar e usa a consulta de pesquisa como meio de encontrar o produto desejado.
“Refrigerador Samsung Frost Free RF27T5501SG com inversor”
- Consultas de domínio (informativas): elas ocorrem quando o usuário deseja se informar sobre diferentes produtos que estão agrupados em um determinado domínio ou grupo de produtos. O objetivo não é comprar, embora isso possa acontecer, mas adquirir conhecimento das opções disponíveis.
“Plantas de interior”
- Consultas sintomáticas: elas acontecem quando o usuário tem um problema que deseja resolver, mas não tem conhecimento claro de qual produto pode resolver o problema.
“Tapete manchado”
- Consultas temáticas: essas consultas geralmente são difíceis de definir, pois são inerentemente vagas por natureza e algumas incluem alguns limites confusos, fazendo referência a locais, condições sazonais ou ambientais, eventos especiais ou promocionais, entre outros.
“Copos de plástico de Halloween”
Principais desafios
Alguns dos principais desafios que você deve conhecer ao lidar com mecanismos de busca de produtos são:
- Velocidade: os resultados geralmente são mostrados entre 0,5 e 3 segundos enquanto a página é carregada.
- Esparsidade: existem muitos produtos com os quais comparar, daí o uso de pré-filtragem e indexação para comparar a consulta com as mais relevantes.
- Idioma: as consultas podem ser ou conter palavras de diferentes idiomas. Ter recursos multilíngues pode ser desejável, ainda mais se o site atrair usuários de diferentes países.
- Unidades de medida: quando um usuário pesquisa por um produto para cabelo com 0,7 L de volume, o mecanismo de busca deve associar que 700 mL se refere ao mesmo valor da mesma magnitude.Robustez em relação à ortografia: isso pode incluir:
-
- Erros ortográficos: “romã” em vez de “romã”.
- Erros de digitação: trocando letras ou digitando incorretamente letras próximas umas das outras no teclado. Por exemplo: “sofá preto” ou “luminária de chão”.
- Sinônimos: “piscina inflável circular” e “piscina inflável arredondada”
- Variações morfológicas: “vermelho” e “avermelhado”
-
- Dificuldades dependentes do idioma: também existem algumas dificuldades adicionais que podem ser encontradas dependendo dos idiomas com os quais estamos trabalhando. Por exemplo, em alemão, é comum juntar muitas palavras para criar uma nova palavra (palavras compostas) e isso pode causar alguns problemas.
É bom ter
Também pode ser desejável:
- Entenda a maneira de escrever de cada usuário, a fim de entender melhor a intenção e o conteúdo relevante de suas consultas.
- Capture palavras foneticamente semelhantes: “bluetooth” e “blututh”.
- Tenha certa interpretabilidade dos resultados para detectar onde há espaço para melhorias em novas iterações do mecanismo de pesquisa.
- Abordagens de sazonalidade, usando tendências sobre quais produtos têm maior probabilidade de serem pesquisados de acordo com a estação do ano.
Como funcionam os mecanismos de busca de produtos?
Nesta seção, abordaremos de forma mais técnica a fim de analisar em um nível mais profundo como essas soluções são projetadas. Como os produtos precisam ser mostrados em uma determinada ordem, isso introduz a noção de ranking, ou seja, classificar documentos (neste caso, produtos) por relevância para encontrar conteúdos de interesse em relação à consulta do usuário. Este é um problema fundamental no campo da Recuperação de informações. Os modelos de classificação geralmente funcionam prevendo uma pontuação de relevância (s) para cada entrada (x), onde a entrada depende de uma consulta (q) e um documento (d).
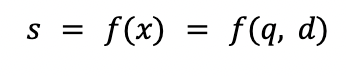
Quando tivermos a relevância de cada documento, podemos classificar (ou seja, classificar) os documentos de acordo com essas pontuações, para mostrar primeiro os resultados mais relevantes. O modelo de pontuação pode ser implementado usando várias abordagens, mas duas das mais populares são:
- Aprendendo a classificar (LTR): usando um algoritmo de aprendizado de máquina, como o XGBoost, em que o modelo aprende a prever a pontuação da associação dada uma consulta e um documento, aprendendo a minimizar certas perdas que serão introduzidas em breve.
- Modelos de espaço vetorial: esses modelos calculam uma incorporação vetorial (por exemplo, usando TF-IDF, Word2Vec ou BERT) para cada consulta e documento e, em seguida, calcule a pontuação de relevância com alguma métrica de distância entre as incorporações vetoriais, como a similaridade do cosseno.
Limpeza de dados
Antes de usar qualquer tipo de modelo, é desejável fazer alguma limpeza de dados e usar algum pré-processamento de texto, pois as consultas são escritas pelos usuários, que tendem a ter erros de digitação, erros ortográficos e outros tipos de ruído no modelo. É por isso que muitos jornais recomendam fazer algumas limpezas, incluindo:
- Pré-processamento básico de texto: converta texto em minúsculas, elimine acentuações como hífens em espanhol, remova espaços em branco à direita, caracteres especiais, entre outras transformações. Nesse sentido, Unidecode pode ser extremamente útil.
- Provocação/Lematização: essas técnicas podem ser usadas para fazer variações da mesma palavra raiz, para serem convertidas exatamente na mesma palavra escrita, o que pode ajudar o algoritmo durante o treinamento para associar essas palavras, pois elas têm significados semânticos semelhantes. Uma das nossas ferramentas favoritas para esse tipo de tarefa é Espaço Cy.
- Remoção de palavras paradas: em alguns casos, pode ser útil remover palavras que não agregam valor à intenção semântica da consulta. Mais uma vez, o SpaCy pode ajudar nessa tarefa.
- Padronização de unidades de medida: no comércio eletrônico em particular, é bastante comum ter diversas unidades de medida e possíveis conversões. Isso também pode ser prejudicial às capacidades de aprendizado dos modelos, daí a necessidade de um bom pré-processamento por meio da padronização deles. Bibliotecas como Cervejas e Quantulum 3 é útil para esta etapa.
Aprendendo a ranquear
Lembrando que, para pesquisa de produtos, nossos documentos (d) representar produtos e as consultas (q) são a consulta de pesquisa escrita pelo usuário, as abordagens mais comuns para treinar um modelo LTR são:
- Métodos pontuais: onde o problema de aprendizado supervisionado é visto como um problema de regressão, onde para cada par consulta-documento, há um rótulo do tipo flutuante representando a semelhança entre a consulta e o documento, e o modelo tenta aprender esses padrões nos dados. Existem também versões discretas dos métodos Pointwise em que a semelhança é discretizada entre um determinado intervalo, por exemplo: de 1 a 10.
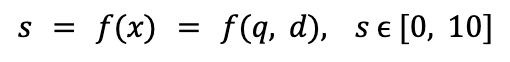
- Métodos pareados: embora a tarefa de regressão possa ser vista como a mais intuitiva, é pouco provável que tenha dados rotulados para essa forma de treinamento. Portanto, outra abordagem é, considerando dois produtos (d1 e d2), determinar qual produto é mais semelhante à consulta.
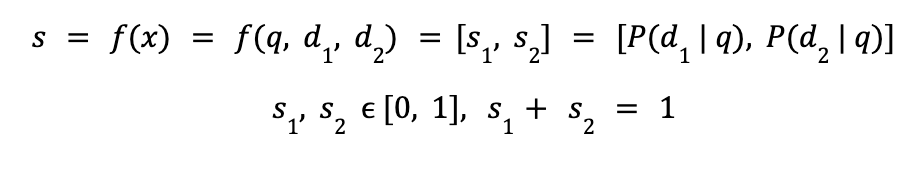
- Métodos Listwise: nesses métodos, em vez de transformar o problema de classificação em uma tarefa de regressão ou classificação, os métodos Listwise resolvem o problema de forma mais direta, maximizando a métrica de avaliação.
Modelos de espaço vetorial
Essas abordagens são métodos estatísticos tradicionais, como o TF-IDF, ou dependem do treinamento de um modelo de aprendizado de máquina em uma tarefa auxiliar para aprender uma representação desejável de consultas e documentos em um espaço vetorial. Normalmente, essa tarefa auxiliar é uma tarefa de classificação, mas removendo a última camada de classificação (ou até mais algumas), o modelo pode converter as entradas nessas representações úteis de dados, chamadas de incorporações.
Word2Vec
A eficácia do Word2Vec vem de sua capacidade de agrupar vetores de palavras semelhantes. Isso se baseia na hipótese de que cada palavra em uma frase é condicionada pelas palavras em seu entorno (contexto). Existem duas maneiras principais de treinar o Word2Vec, mas vamos dar uma olhada na mais intuitiva: Continuous Bag of Words (CBOW).

Arquitetura CBOW, retirada do artigo Word2Vec
Na figura acima, a entrada é uma frase com cinco palavras, em que a palavra do meio não é dada ao modelo, e o objetivo do modelo é prever qual palavra deve estar no meio dessa frase. Isso, inerentemente, faz com que os parâmetros aprendam as frequências e correlações entre palavras que são comumente usadas juntas em frases, e o vetor que representa cada palavra tenha algumas propriedades semânticas e sintáticas desejáveis, conforme mostrado abaixo:
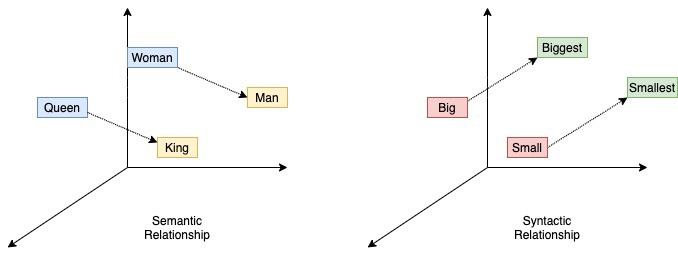
Incorporações de palavras, relações semânticas e sintáticas
Então, com essas representações, podemos criar incorporações para cada palavra e usar algumas heurísticas para definir uma incorporação para toda a consulta ou produto. Em seguida, compare essas incorporações para determinar a classificação a ser mostrada.
Codificadores
Nós mencionamos BERT pois é uma das arquiteturas de transformadores de codificadores mais usadas, mas qualquer codificador poderia servir ao mesmo propósito. A ideia por trás disso é usar o BERT como a espinha dorsal da arquitetura e, em seguida, adicionar uma cabeça de classificação ou regressão para treinar o modelo, conforme referido nos métodos PointWise e Pairwise. Vejamos um exemplo da arquitetura:
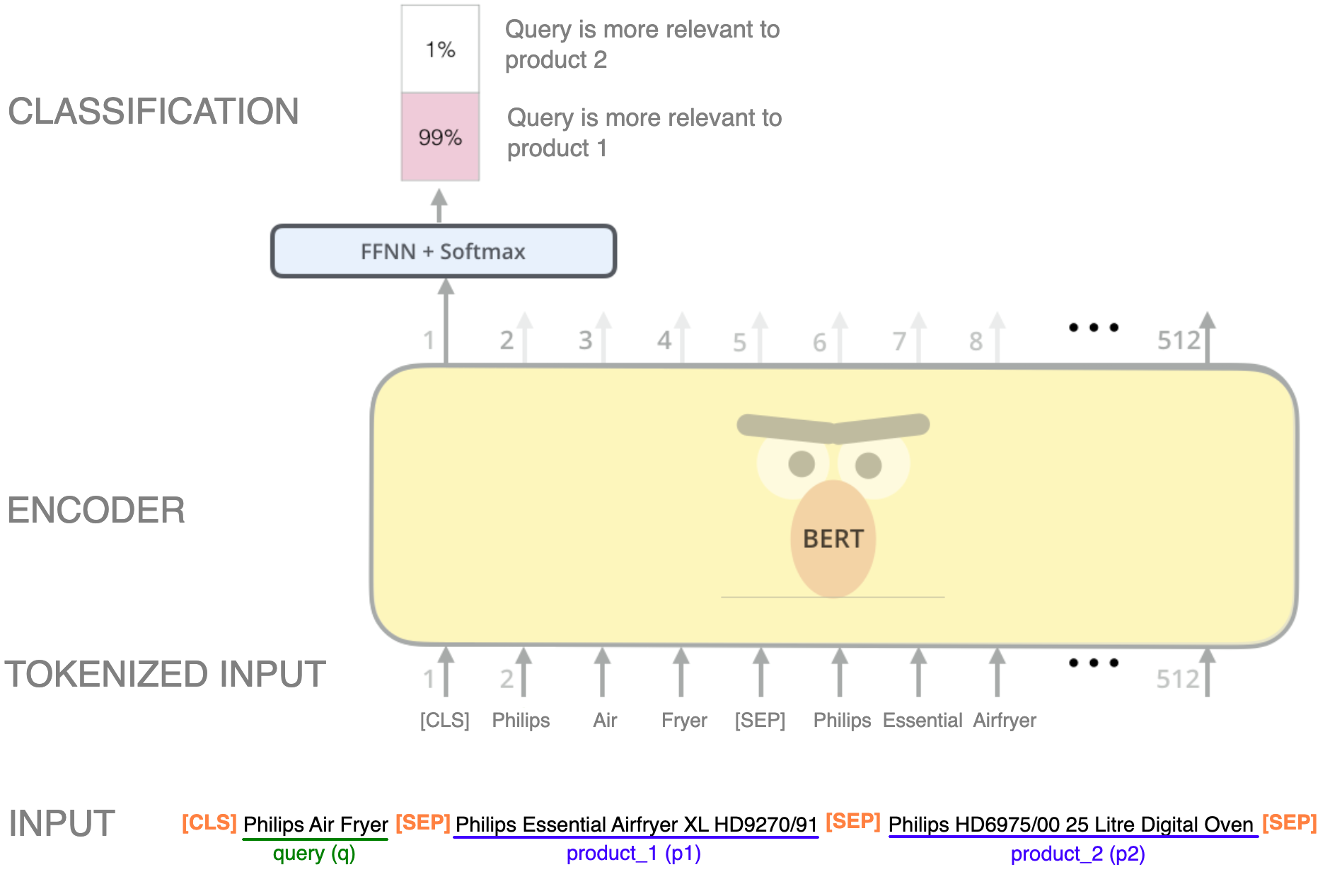
Imagem modificada do Jay's Alammar blog no BERT.
Neste exemplo, usamos uma abordagem de pares para classificar se a consulta é mais relevante para o produto 1 ou para o produto 2. Para isso, é possível treinar o modelo usando uma estrutura semelhante à Next Sentence Prediction (NSP), que é uma das maneiras pelas quais o BERT é pré-treinado, mas com três frases: a consulta, o produto 1 e o produto 2, cada um separado pelo token de separação especial [SEP]. Os transformadores geralmente são evitados por serem modelos pesados com milhões de parâmetros. Mas, em alguns casos, com apenas a redução do número de camadas do codificador em sua arquitetura, bons resultados podem ser alcançados e a sequencialidade, que consome mais tempo e recursos, é reduzida. O artigo que apresentou a arquitetura dos transformadores,”Atenção é tudo que você precisa“, usa 6 camadas codificadoras empilhadas para o bloco codificador, mas com 1 ou 2 camadas pode ser suficiente para essa finalidade. Um exemplo disso pode ser visto no artigo intitulado”Transformador de sequência de comportamento para recomendação de comércio eletrônico no Alibaba“pelo Alibaba Search & Recommendation Group do Alibaba. Embora este artigo se refira a um Sistema de Recomendação, os mesmos conceitos podem ser aplicados aos mecanismos de pesquisa. No entanto, como no exemplo, os produtos devem ser fornecidos como entrada em pares, no momento de usar a inferência do modelo, esses dois produtos também devem ser fornecidos. Outras opções são usar esse treinamento como pré-treinamento e ajustar o codificador em outra tarefa posterior, ou apenas usar o codificador sem o cabeçalho de classificação, como fizemos com o Word2Vec. Ao usar esse tipo de entrada, o número de comparações pode crescer exponencialmente, portanto, esse modelo só pode ser usado quando os produtos mais relevantes são recuperados primeiro, digamos algumas centenas de produtos para uma comparação detalhada. Da mesma forma que o Word2Vec, a última camada de classificação com a função de ativação Softmax pode ser removida para obter consultas e incorporações de documentos.
Literatura relevante
A seguir está uma lista selecionada de artigos que foram considerados interessantes para pesquisar soluções viáveis de pesquisa de produtos que poderiam ser escaláveis em milhões e até bilhões de produtos de catálogo e ainda ter um ótimo desempenho.
Pesquisa semântica de produtos
Neste artigo, a relevância dos produtos em uma consulta de pesquisa foi modelada como um problema de regressão usando uma rede siamesa:
- Os autores usam Saco de palavras (BoW) compartilhado junto com as consultas e os produtos, para então criar um espaço de incorporação compartilhado com agrupamento médio. Essa é a base para treinar a Rede Siamesa com semelhança entre cossenos.
- Uma peça de 3 partes Perda de dobradiça é usado para distinguir entre produtos comprados, produtos clicados não comprados e produtos não clicados. Em uma primeira instância, eles testaram uma perda de dobradiça em duas partes com produtos clicados e não clicados, mas as informações de compra forneceram uma visão extremamente útil para o modelo girar.
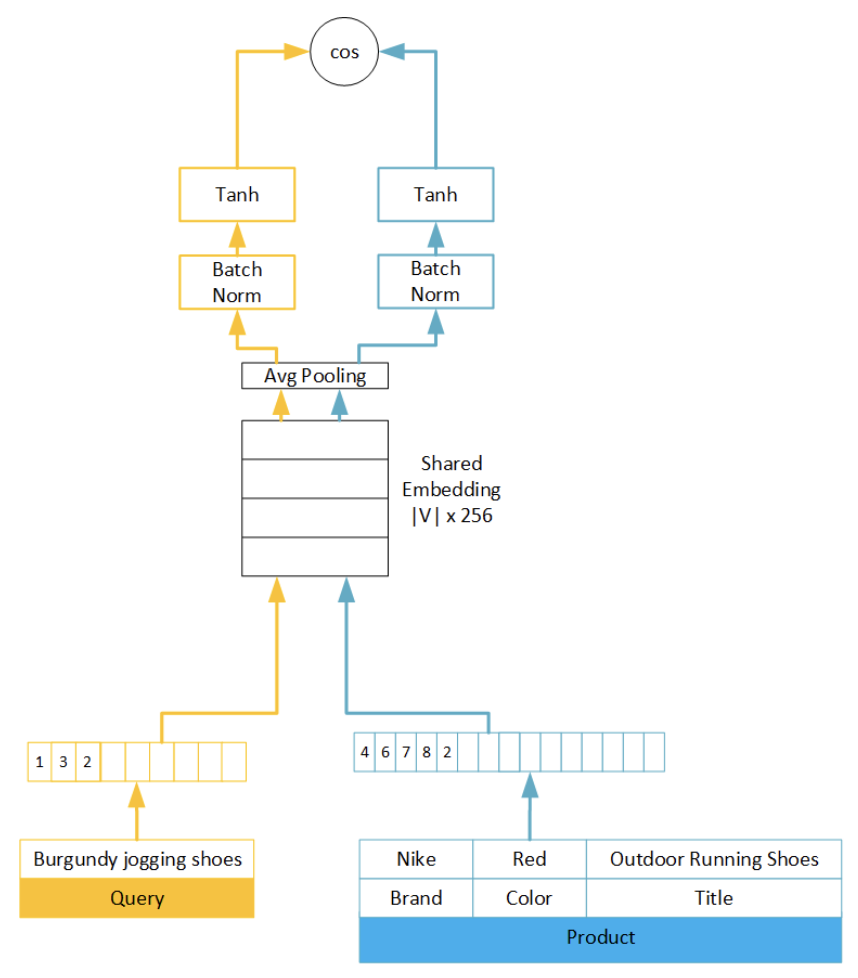
Imagem retirada do artigo Semantic Product Search
Relevância sazonal na pesquisa de comércio eletrônico
Este artigo se concentra na ideia de que muitos produtos têm inerentemente um componente sazonal em suas vendas. Isso leva a consultas que possivelmente estão alinhadas com essas tendências temporais, portanto, é mais provável que um usuário pesquise um suéter de inverno no início do inverno do que no verão.
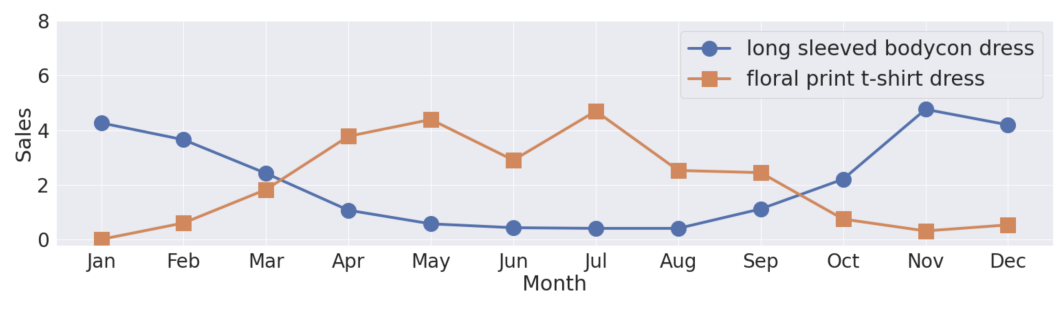
Imagem retirada do artigo Seasonal Relevance in E-Commerce Search
Destaques:
- Os autores mostram que 39% das consultas feitas pelos usuários estão alinhadas com esses componentes de sazonalidade dos produtos.
- Daí a ideia de propor características de sazonalidade para serem usadas nos algoritmos de busca.
- Eles propõem uma rede simples de classificação multiclasse Feed-Forward com mecanismos de atenção agrupados, que usa apenas a consulta de entrada como entrada para a rede, criando incorporações com Fasttext e adicionando um termo de sazonalidade à perda categórica de entropia cruzada.
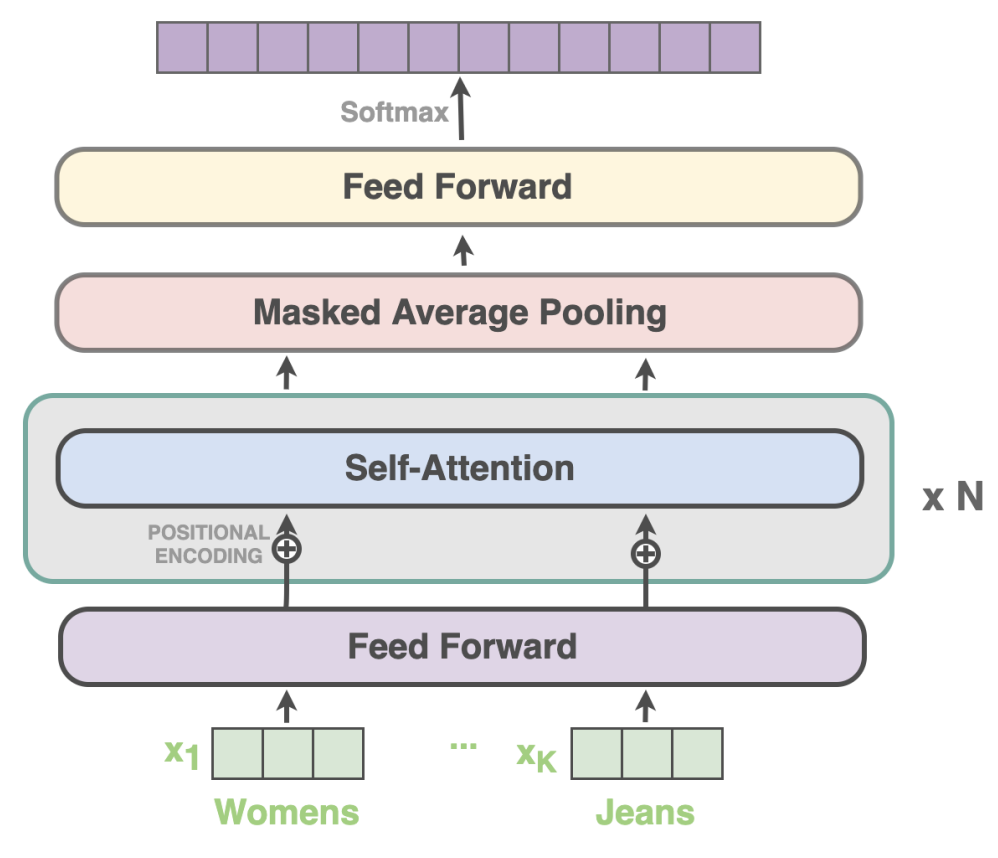
Imagem retirada do artigo de pesquisa de correção ortográfica usando fonética em comércio eletrônico
ROSE: Caches robustos para pesquisa de produtos na Amazon
Este artigo é um pouco diferente dos demais, pois não está centrado no design do modelo, mas em como melhorar a experiência do usuário com o uso de caches inteligentes resistentes a erros de digitação, erros ortográficos e fenômenos similares (consultas de baixa qualidade) para reduzir a latência quando os usuários pesquisam. Destaques:
- Esse sistema de cache está atualmente em produção para a Amazon.
- Os autores propõem mapear consultas de baixa qualidade para consultas de alta qualidade, mantendo somente consultas de alta qualidade em cache. Para indexar e legendar a semelhança semântica dessas consultas, um Hash sensível à localidade (LSH) está sendo realizado, conforme proposto pela abordagem de vizinhos mais próximos aproximados (ANN).
- Algumas palavras, como atributos do produto, têm maior peso do que outras palavras para manter essa semelhança semântica, usando Reconhecimento de entidade nomeada (NER) técnicas.
Correção ortográfica usando fonética na pesquisa de comércio eletrônico
Neste artigo, os autores falam sobre a realidade de que a maioria das soluções que envolvem mecanismos de pesquisa está centrada nas consultas de texto ruidosas que os usuários digitam, mas não levam em conta os erros fonéticos. Por exemplo, quando um casal de idosos tenta descobrir os fones de ouvido com “blutut” que sua neta queria no Natal. Destaques:
- Problemas com texto podem ser resolvidos com distância de edição, n-gramas ou até mesmo incorporações de palavras, mas os erros fonéticos são muito mais difíceis de resolver.
- Similarmente à distância de Levenshtein para semelhança textual de palavras, os autores propõem o uso da distância sonora de palavras, como Soundex.
- Eles propõem o uso de um modelo baseado em árvore, como o XGBoost, para corrigir a consulta digitada levando em consideração as duas distâncias (textual e sonora) com um algoritmo eficiente de busca de candidatos.
Por exemplo:
Sem semelhança fonética: a consulta “blutut sant systam” obteve 82 resultados, corrigindo-a para “blututh sent system”
Adicionando semelhança fonética: a consulta “blutut sant systam” obteve mais de 9000 resultados, corrigindo-a para “sistema de som bluetooth”
Considerações finais
Essa foi uma grande quantidade de informações para absorver! Mas esperamos que, com este blog, você tenha entendido em um nível mais alto os conceitos-chave em torno da pesquisa de produtos, as diferenças entre os mecanismos de pesquisa e os sistemas de recomendação e os principais aspectos e desafios a serem considerados ao criar um mecanismo de pesquisa de produtos. Se você estiver interessado o suficiente para continuar com os detalhes mais técnicos sobre o estado da arte na pesquisa de produtos, esperamos que este blog tenha lhe dado algumas dicas sobre quais decisões precisam ser tomadas para criar um mecanismo de pesquisa escalável e eficiente, além de algumas ideias de por onde podemos começar a tentar modelar essas soluções. Fique ligado para mais conteúdo!
Referências
- Alexander Reelsen, “Uma pesquisa moderna de comércio eletrônico” (junho de 2020). https://spinscale.de/posts/2020-06-22-implementing-a-modern-ecommerce-search.html
- Instituto Baymard, “Desconstruindo a UX de pesquisa de comércio eletrônico: os 8 tipos de consulta de pesquisa mais comuns (42% dos sites têm problemas)” (julho de 2022). https://baymard.com/blog/ecommerce-search-query-types
- Francesco Casalegno, “Aprendendo a classificar: um guia completo para classificação usando aprendizado de máquina” (fevereiro de 2022). https://towardsdatascience.com/learning-to-rank-a-complete-guide-to-ranking-using-machine-learning-4c9688d370d4
- Central de Pesquisa do Google,”Guia detalhado sobre como a Pesquisa do Google funciona” (Outubro de 2022). https://developers.google.com/search/docs/fundamentals/how-search-works
- Loop 54, “A diferença entre mecanismos de busca de produtos e mecanismos de recomendações de produtos” (outubro de 2016). https://www.loop54.com/knowledge-base/product-search-engines-product-recommendation-engines-differences
- Mangool, “Search Engines” (janeiro de 2021). https://mangools.com/blog/search-engines
- Pinterest,”Tudo sobre o Pinterest” (Julho de 2022). https://help.pinterest.com/en/guide/all-about-pinterest #
- Diário do mecanismo de pesquisa,”Conheça os 7 mecanismos de busca mais populares do mundo” (Março de 2021). https://www.searchenginejournal.com/seo-guide/meet-search-engines
- Telus,”O que são mecanismos de busca no aprendizado de máquina?” (Fevereiro de 2021). https://www.telusinternational.com/articles/what-are-search-recommendation-systems-in-machine-learning #
- Interpretação na Web,”Entenda o mecanismo de busca da Amazon para gerar mais vendas” (Agosto de 2022). https://www.webinterpret.com/us/blog/ecommerce-product-searches-amazon-google/



.png)