.png)
NVIDIA-Merlin: un marco para construir sistemas de recomendación




En los últimos años, los sistemas de recomendación han ganado una enorme popularidad en la comunidad de aprendizaje automático y ciencia de datos debido a su impacto en los ingresos de las plataformas digitales y de comercio electrónico al sugerir artículos específicos a los clientes que podrían ser interesantes para ellos. Sin embargo, a la hora de crear sistemas de recomendación se tropieza con una amplia gama de obstáculos. Para abordar esos desafíos, se está desarrollando una gran variedad de herramientas para minimizar los esfuerzos invertidos en la construcción de estos sistemas, como Se recomienda TensorFlowseñora, Antorcha REC, y NVIDIA-Merlín.
En este artículo profundizaremos en NVIDIA-Merlín, que es un marco de vanguardia para crear sistemas de recomendación a escala, ya que promete abordar los diferentes desafíos que surgen de los flujos de trabajo de los sistemas de recomendación. Resumiremos consejos importantes que serán útiles a la hora de evaluar su idoneidad para un proyecto o al empezar a trabajar con él.
El problema
Uno de los mayores problemas a los que se enfrentan las empresas digitales hoy en día es la participación de los usuarios en sus plataformas, lo que se traduce en un aumento de las ganancias. Preguntas como: ¿cómo obtenemos nuestro Usuarios de Youtube para hacer clic en '¿Qué sigue?'¿uno tras otro durante un largo período de tiempo? ¿O cómo damos un dato específico Netflix usuario a»Qué se recomienda para ti» ¿sugerencia que ayudará a retenerlos por un poco más de tiempo? Incluso si tienes una tienda de moda online: ¿cómo podemos ayudar a nuestros clientes a encontrar sus productos de una manera más fácil? »También te puede interesar...» o»Comprados juntos con frecuencia» ayudan a resolver este problema.
Todos los ejemplos mencionados anteriormente son posibles gracias a los sistemas de recomendación.
Sistemas de recomendación
Los sistemas de recomendación aumentan los ingresos empresariales al ayudar a los clientes a encontrar los artículos deseados y comprar los más adecuados para ellos con menos esfuerzo.
Algunos ejemplos ilustrativos de cómo los sistemas de recomendación están impactando en las plataformas digitales y el comercio electrónico son:
- UN McKinsey & Company informe atribuido 35% de De Amazon ventas a recomendaciones [1].
- Según el artículo 'Estudio de desarrollo de la personalización de 2019'mantenido por Monetar: El 78% de las empresas con una estrategia de personalización total o parcial experimentaron un crecimiento de ingresos (frente al 45,4% de crecimiento de ingresos registrado por las empresas sin una estrategia de personalización) [2].
- Una investigación de Epsilon muestra que el 80% de los consumidores tienen más probabilidades de realizar una compra cuando la tienda en línea ofrece experiencias personalizadas [3].
- De acuerdo con Segmento: casi el 60% de los consumidores aceptaron convertirse en compradores habituales tras una experiencia de compra personalizada [4].
Filtrado colaborativo frente a filtrado de contenido
Teniendo en cuenta que existen varios criterios para hacer recomendaciones específicas a los usuarios, también existen varios tipos de sistemas de recomendación. Una primera clasificación general distingue entre personalizado o no personalizado recomendadores. Un ejemplo ilustrativo de esto último son las recomendaciones basadas en la popularidad (por ejemplo, cuando Netflix te muestra las películas más populares de tu país).
Por otro lado, los sistemas de recomendación personalizados tienen como objetivo recomendar de forma «personalizada» encontrando principalmente tres tipos de filtrado: colaborativo, basado en contenido y híbridos, que aprovechan las ventajas de ambos sistemas.
- Filtrado colaborativo se basa en el hecho de la «similitud de preferencias» entre los usuarios para recomendar nuevos artículos. Dadas las interacciones anteriores entre los usuarios y los elementos, los algoritmos de recomendación aprenden a predecir las interacciones futuras. La idea es que si algunas personas han tomado decisiones y han hecho compras similares en el pasado, como la elección de una película, existe una alta probabilidad de que se pongan de acuerdo sobre otras selecciones futuras.
Por ejemplo, en la figura 1 se puede ver que si a un usuario A y a un usuario B les gustan las mismas dos películas, el sistema recomendará al usuario B una tercera película que le guste al usuario A.
[caption id="attachment_1548" align="aligncenter» width="500"]
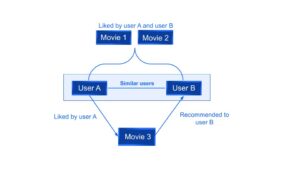
Figura 1: Ejemplo de filtrado colaborativo[/subtítulo]
- Filtrado de contenido, por el contrario, usa los atributos o características de un elemento -esta es la parte del contenido- para recomendar otros elementos similares a las preferencias del usuario. Este enfoque se basa en la similitud entre las características del elemento y del usuario, teniendo en cuenta la información sobre un usuario y los elementos con los que ha interactuado (por ejemplo, el sexo del usuario, la edad, el promedio de reseñas de una película) modelan la probabilidad de una nueva interacción.
Por ejemplo, si a un usuario le gustó una película A, se le recomendará una película B con características similares a las de la película A.
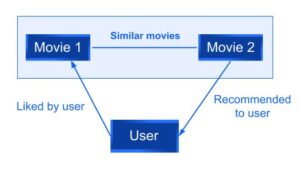
Figura 2: Ejemplos de filtrado basado en contenido
- Un sistema de recomendación híbrido tiene como objetivo superar algunas de las limitaciones de los métodos de filtrado colaborativos y basados en el contenido. Hay varias formas de implementar este tipo de sistemas: hacer predicciones basadas en el contenido y las basadas en la colaboración por separado y, a continuación, combinarlas, añadiendo capacidades basadas en la colaboración a un enfoque basado en el contenido o viceversa.
Por ejemplo, Netflix utiliza este enfoque comparando primero lo que ven usuarios similares (filtrado basado en la colaboración) y, en segundo lugar, recomendando películas con funciones similares a las mejor valoradas por el usuario (filtrado basado en el contenido).
Los desafíos
El proceso de inferencia del sistema de recomendación implica seleccionar y clasificar los elementos candidatos de acuerdo con la probabilidad prevista de que el usuario interactúe con ellos (se presentan al usuario aquellos con la mayor probabilidad pronosticada).
En esta sección analizaremos cómo hacer frente a los obstáculos encontrados en cada paso del flujo de trabajo al crear un sistema de recomendación desde el principio hasta que esté listo para los clientes en producción.
1. Obtener los datos y prepararlos para la capacitación
Los datos de las interacciones entre los usuarios y los elementos provienen de reseñas, me gusta o incluso clics en un sitio web y, por lo general, se almacenan en almacenes de datos o lagos de datos. Estos datos se utilizan luego para entrenar los sistemas de recomendación. El objetivo principal del proceso ETL (Extraer, Transformar y Cargar) es preparar el conjunto de datos para la parte de entrenamiento, que normalmente viene en un formato tabular que puede llegar incluso a Terabyte escala, lo que significa que hay muchos datos que procesar en la ingeniería de características (es decir, crear nuevas funciones a partir de las existentes) y preprocesar las piezas.
Por ejemplo, si tu tienda de moda online quiere utilizar una lista de correo para enviar recomendaciones personalizadas una vez al mes, primero tendrás que recopilar todas las interacciones de los usuarios dentro de tu sitio web (por ejemplo, qué artículos le han gustado al usuario, reseñas anteriores realizadas), limpiar los datos (por ejemplo, reseñas poco significativas) y seleccionar las funciones que se utilizarán y, al mismo tiempo, crear otras nuevas (por ejemplo, una tasa media de usuarios puede resultar útil).
Este paso plantea muchos desafíos:
- La falta de datos de alta calidad: la ausencia de datos de alta calidad puede hacer que tengas dificultades para crear un motor de recomendaciones preciso.
- Escasez de datos: se encuentra principalmente en los sistemas de recomendación colaborativos, este problema aparece cuando un artículo es valorado por pocas personas, pero con reseñas de valoraciones altas que no aparecen en la lista de recomendaciones. Esto podría proporcionar recomendaciones inexactas a los usuarios con gustos «poco comunes» en comparación con otros usuarios.
- Sistemas que pueden adaptarse a la cambio en los intereses del usuario: se debe tener en cuenta la dinámica de los usuarios y los artículos a la hora de recomendar (por ejemplo, los intereses de los usuarios recientes no pueden tener el mismo impacto en las recomendaciones que los antiguos)
- Pasos como la ingeniería de funciones, la codificación categórica y la normalización de variables continuas normalmente pueden llevar mucho tiempo, especialmente para los recomendadores comerciales que utilizan enormes conjuntos de datos (terabytes o incluso más grandes) .l
2. Entrenamiento
La etapa de entrenamiento generalmente se realiza eligiendo uno de los marcos disponibles (como Pytorch, Tensorflow o Huge CTR, que es una biblioteca de NVIDIA Merlin que se analizará más adelante), evaluado y listo para pasar a la producción. Algunos de los desafíos que se plantean en este paso son:
- «Arranque en frío» problema (que se encuentra principalmente en el filtrado colaborativo): este problema surge cuando se acaba de añadir un nuevo usuario o un nuevo elemento al sistema de recomendación cuando no existe información previa sobre el usuario, por lo que el sistema no puede predecir con precisión las próximas elecciones del usuario.
- Problema de cuello de botella: puede ocurrir que tu tienda online experimente un crecimiento sostenido que lleve a una ampliación del catálogo. Así que ahora, una enorme cantidad de datos que no se tuvieron en cuenta en un principio. Esto podría provocar un «problema de cuello de botella» en el que su tablas de incrustación potencialmente enormes deja de caber en la memoria de la GPU y se debe tomar una medida correctiva.
3. Despliegue y refinamiento del sistema de recomendación
- Necesidad continua de readiestramiento debido a la entrada de nuevos registros de usuarios/artículos: incluso si tu modelo trabaja en producción y hace recomendaciones a tus usuarios, es posible que necesites añadir constantemente nuevos productos a tu tienda online, lo que generará nuevas interacciones con tus usuarios. Además, también tendrás nuevos usuarios registrándose. Ambos casos llevan a la necesidad de volver a entrenar sus modelos para seguir satisfaciendo las necesidades de los usuarios. Esto también lleva a la necesidad de cargar y descargar los modelos de forma sencilla.
- Gestionar muchos usuarios al mismo tiempo
- En algunos escenarios tiempo real inferencia es necesario: por ejemplo, cuando un cliente esté al lado de «pagar» un producto deportivo específico «añadido al carrito», como unos pantalones cortos para correr, también querrás sugerirle al usuario que compre otra ropa para correr. En este caso, es necesario que la inferencia se realice en el momento, es decir, en tiempo real. Al abordar este tipo de problemas, el tiempo de inferencia y la cantidad de usuarios a tratar son aspectos clave a tener en cuenta.
Por el contrario, si quieres que tu tienda online utilice una lista de correo para recomendar productos personalizados para cada usuario una vez al mes, solo tendrás que realizar el paso de inferencia antes de enviar los correos electrónicos. Consiste en un no en tiempo real escenario.
Cuando los sistemas de recomendación entran en escena, aparecen una amplia variedad de barreras. Por lo tanto, para simplificar la vida de los científicos de datos y los desarrolladores de aprendizaje automático (o al menos intentarlo), se están desarrollando nuevas herramientas y marcos para respaldar este motor de recomendaciones: Se recomienda TensorFlowrs (una biblioteca desarrollada por investigadores de Google), Antorcha REC (una biblioteca de dominios de PyTorch) y Nvidia-Merlín (un framework desarrollado por NVIDIA) son algunos de ellos.
A partir de ahora, este primer artículo se centrará en NVIDIA-Merlin, que se lanzó en 2020, y promete abordar algunos de los desafíos mencionados anteriormente.
NVIDIA-Merlín
La documentación oficial de NVIDIA Merlin se define a sí misma como «marco de código abierto para crear sistemas de recomendación de alto rendimiento a escala». Este marco se diseñó para acelerar todo el sistema de recomendaciones en todo el flujo de trabajo de recomendación siguiendo los siguientes pasos:
- Preprocesamiento
- Ingeniería de funciones
- Entrenamiento
- Inferencia
- Implemente en producción
El siguiente diagrama en Figura 3 muestra las principales características para las que NVIDIA Merlín se desarrolló y cómo organiza todo el sistema de recomendaciones. Teniendo esta visión global del proceso, podemos ir a cada una de las bibliotecas diseñadas para este propósito.
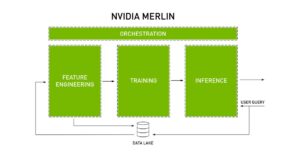
Figura 4: Orquestación de NVIDIA Merlin de las principales características de un sistema de recomendación [6]
NVIDIA Merlin proporciona varios componentes para que se pueda usar una sola biblioteca o varias de ellas para acelerar todo el proceso de recomendación: desde la ingesta, el entrenamiento y la inferencia hasta la implementación y la producción.
Según el problema que intentes resolver, los componentes de NVIDIA Merlin que utilices pueden variar.
Las tres bibliotecas principales que están diseñadas para funcionar juntas son:
- NVTabular: diseñado para manipular conjuntos de datos del sistema de recomendación que vienen en formato tabular. Esta biblioteca realiza las partes de preprocesamiento e ingeniería de funciones.
- Modelos Merlin: proporciona modelos estándar (como la factorización matricial o Two Tower) para sistemas de recomendación. Esta biblioteca incluye algunos componentes básicos que permiten definir nuevas arquitecturas.
- Sistemas Merlin: diseñado para implementar la canalización de recomendaciones en la producción. Esto se hace creando el conjunto que servirá para el Servidor de inferencia Triton (descrito más adelante) que realizará el paso de inferencia.
También hay otras bibliotecas de Merlin diseñadas para abordar algunos desafíos específicos:
- Enorme CTR: especialmente útil para casos que involucran grandes conjuntos de datos y enormes tablas de incrustación que permiten realizar el paso de entrenamiento de manera eficiente distribuyendo el entrenamiento entre múltiples GPU y nodos.
- Transformers 4Rec: diseñada para recomendaciones secuenciales y basadas en sesiones, esta función de biblioteca la diferencia del resto. Los recomendadores secuenciales capturan patrones secuenciales en los usuarios para anticipar las próximas intenciones de los usuarios y proporcionarles recomendaciones más precisas. Por otro lado, los recomendadores basados en sesiones (subclase de los secuenciales) se utilizan cuando solo tienes acceso a una breve secuencia de interacciones dentro de la sesión actual con el objetivo de ofrecer recomendaciones personalizadas, incluso cuando el historial de usuario anterior no esté disponible o cuando los gustos de los usuarios cambien con el tiempo.
Además de Figura 3 donde se resumen las características clave de un sistema de recomendación, el Figura 4 muestra cómo cada biblioteca realiza una tarea específica dentro del flujo de trabajo del sistema de recomendación.
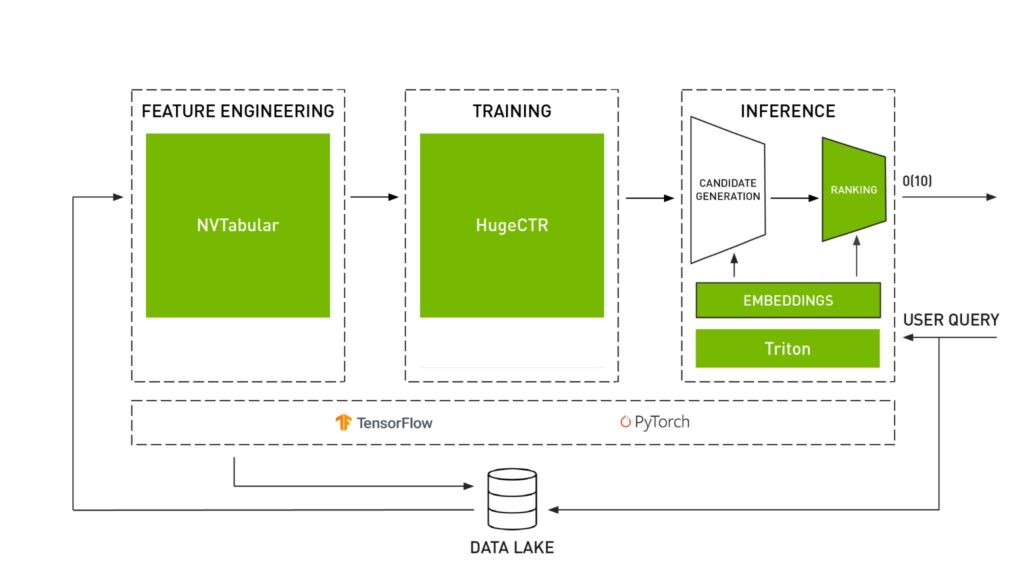
Figura 4: Bibliotecas NVIDIA Merlin [6]
Un consejo antes de seguir: la figura 4 muestra cómo Merlin se basa en Tensorflow y Pytorch. Sin embargo, antes de continuar, debes tener en cuenta que, para la mayoría de los componentes, la API de Pytorch estaba iniciada pero estaba incompleta en el momento de publicar este artículo. Así, por ejemplo, si en tu proyecto actual necesitas usar Merlin Models, todavía no podrás compilarlo en Pytorch.
Además de estas bibliotecas, NVIDIA Merlin aprovecha el software ya desarrollado por NVIDIA AI disponible en su plataforma. Cabe mencionar el servidor de inferencia Triton de NVIDIA, cuyo objetivo es lograr una inferencia de alto rendimiento a escala durante la producción. Esto se consigue 'al ejecutar la inferencia de manera eficiente en las GPU al maximizar el rendimiento con la combinación correcta de latencia y utilización de la GPU', tal y como se describe en la documentación oficial de NVIDIA.
Recomendador basado en sesiones: una aplicación integral que utiliza NVIDIA-Merlin
Se presenta un escenario especial cuando quieres predecir los intereses del próximo usuario pero no tienes información previa sobre ellos. Esto es útil teniendo en cuenta que los intereses de los usuarios pueden cambiar con el tiempo o incluso cuando los usuarios deciden navegar en modo privado. Por lo tanto, solo recopilar la información de la sesión actual puede ayudar a resolver estos problemas.
Un ejemplo de esto se presenta en la documentación oficial proporcionada por NVIDIA con el objetivo de recomendar los siguientes elementos de usuario de las interacciones de la sesión actual.
En esta sección se describen los principales pasos y bibliotecas que se utilizan para lograr este objetivo (puede seguir el código para obtener más información en [5], [6]).
1er NVTabular: se usa para definir el flujo de trabajo para preprocesar los datos agrupando las interacciones de la misma sesión y clasificándolas por tiempo.
Segundo Transformers 4Rec: esta biblioteca le permite utilizar la arquitectura de transformadores que se importa de la biblioteca de PNL de Hugging Face Transformers para realizar la capacitación. Esta biblioteca también incluye métricas de Recsys que le permiten medir el rendimiento de su modelo.
Tercer servidor Triton Inference: esta biblioteca permite implementar y servir el modelo para la inferencia. Se logra el despliegue a partir de ambos: el flujo de trabajo de ETL (ya que en la inferencia tendrás que transformar los datos de entrada tal y como se hizo durante el entrenamiento) y el modelo entrenado. Como resultado, ahora sus usuarios pueden consultar el servidor para obtener las predicciones del siguiente elemento.
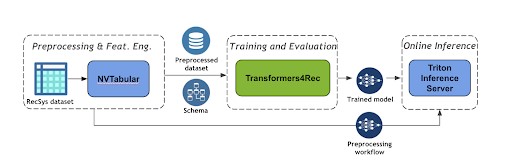
Figura 5: Un flujo de trabajo de recomendación basado en sesiones [6]
Acerca de la solución
Tras leer la documentación oficial de NVIDIA, decidimos ponernos manos a la obra y probar algunas bibliotecas nosotros mismos. NVTabular y Modelos Merlin fueron los componentes principales abordados para descubrir algunos aspectos clave a tener en cuenta antes de decidir seguir adelante con esta herramienta.
- Solución de extremo a extremo
Modelos Merlin, NVTabular y Sistemas Merlin son componentes de Merlin que están diseñados para funcionar juntos. NVTabular generará (además de los archivos de parquet preprocesados) un archivo de esquema que describe las estructuras del conjunto de datos que se necesitan para alimentar a Merlin Models. Luego, se debe crear el conjunto con los modelos de Merlin para obtener el proceso de inferencia del modelo. El último paso consistiría en implementar los flujos de trabajo y modelos de NV-Tabular en el servidor Triton Inference.
Esta integración diseñada entre bibliotecas facilita la creación de canalizaciones RecSys de extremo a extremo, pero en términos de flexibilidad, si se decide pasar a otra tecnología puede resultar difícil.
- Un consejo sobre los contenedores Docker
La forma más sencilla de usar Merlin es ejecutar un contenedor docker que se encuentra en https://catalog.ngc.nvidia.com/containers, para evitar problemas entre bibliotecas y dependencias. Decidimos ejecutarlo en una instancia de AWS g4dn.xlarge que proporciona una sola GPU, 4 vCPU y un tamaño de memoria de 16 GiB. El uso de este tipo de instancia cuesta 243 USD al mes (calculado mediante Calculadora de AWS). El proyecto en el que se embarque establecerá sus propios costos de infraestructura, que serán diferentes a los de este, pero seguro que deben tenerse en cuenta antes de continuar.
Como ya se mencionó anteriormente, descubrimos en la documentación oficial de NVIDIA los siguientes consejos: «En nuestras versiones iniciales, Merlin Models incluye una API de Tensorflow. La API de PyTorch está iniciada, pero incompleta».
Entonces, lo primero que hay que tener en cuenta: a pesar de algunos componentes específicos (como Transformadores 4REC) Nvidia-Merlin está diseñado para integrarse con Tensorflow.
Reflexiones finales
En este artículo analizamos primero el impacto de los sistemas de recomendación en las plataformas digitales actuales y los diferentes tipos de filtros. Luego pasamos a entender los principales desafíos que plantean los recomendadores y la necesidad de herramientas que respalden cada paso del proceso de flujo de trabajo. Finalmente, presentamos y discutimos NVIDIA Merlín, un marco prometedor para crear sistemas de recomendación de extremo a extremo que puede ser útil para acelerar el preprocesamiento y la ingeniería de funciones con NV Tabular, pero que no es tan flexible (hasta ahora) para usarse en un sistema de recomendación completo basado en Pytorch. También hablamos de los recomendadores basados en sesiones, que son particularmente útiles cuando no se encuentran interacciones previas con el usuario.
En Marvik siempre estamos buscando tecnologías de vanguardia para resolver problemas complejos. No dude en ponerse en contacto con nosotros en hola @marvik .ai si tiene alguna pregunta o quiere compartir algunas ideas.
Referencias
[1] I. MacKenzie, C. Meyer, S. Noble (1 de octubre de 2013). «Cómo los minoristas pueden mantenerse al día con los consumidores». https://www.mckinsey.com/industries/retail/our-insights/how-retailers-can-keep-up-with-consumers
[2] Monetate (2019). «Estudio de desarrollo de la personalización de 2019». https://info.monetate.com/rs/092-TQN-434/images/2019_Personalization_Development_Study_US.pdf
[3] Epsilon (2018, 9 de enero). «Una nueva investigación de Epsilon indica que el 80% de los consumidores tienen más probabilidades de realizar una compra cuando las marcas ofrecen experiencias personalizadas». https://www.epsilon.com/us/about-us/pressroom/new-epsilon-research-indicates-80-of-consumers-are-more-likely-to-make-a-purchase-when-brands-offer-personalized-experiences
[4] Keating (2021, 1 de junio). «Anunciando el estado de la personalización en 2021». https://segment.com/blog/announcing-the-state-of-personalization-2021/
[5] NVIDIA. https://nvidia-merlin.github.io/Transformers4Rec/main/examples/tutorial/03-Session-based-recsys.html (consultado el 12 de diciembre de 2022)
[6] R. AK, G. Moreira (2022, 28 de junio). «Transformers4rec: creación de recomendaciones basadas en sesiones con una biblioteca nvidia merlin». https://developer.nvidia.com/blog/transformers4rec-building-session-based-recommendations-with-an-nvidia-merlin-library/
[7] NVIDIA. https://github.com/NVIDIA-Merlin/Merlin (consultado el 12 de diciembre de 2022)



.png)