.png)
NVIDIA-Merlin: uma estrutura para criar sistemas de recomendação




Nos últimos anos, os sistemas de recomendação ganharam enorme popularidade na comunidade de aprendizado de máquina e ciência de dados devido ao seu impacto nas receitas das plataformas digitais e de comércio eletrônico, sugerindo itens específicos aos clientes que seriam interessantes para eles. No entanto, ao construir sistemas de recomendação, uma grande variedade de obstáculos é encontrada. Para enfrentar esses desafios, uma grande variedade de ferramentas está sendo desenvolvida para minimizar os esforços investidos na construção desses sistemas, como TensorFlow recomendadosenhoras, Tocha Rec, e NVIDIA-Merlin.
Neste artigo, faremos um mergulho profundo em NVIDIA-Merlin, que é uma estrutura de última geração para criar sistemas de recomendação em grande escala, pois promete enfrentar os diferentes desafios decorrentes dos fluxos de trabalho de sistemas de recomendação. Resumiremos dicas importantes que serão úteis ao avaliar sua adequação a um projeto ou ao começar a trabalhar com ele.
O problema
Um dos maiores problemas que as empresas digitais enfrentam atualmente é o engajamento dos usuários em suas plataformas, o que se traduz em aumento de lucros. Perguntas como: como obtemos nosso Usuários do Youtube para clicar em 'O que vem a seguir'um após o outro por um longo período de tempo? Ou como podemos dar um específico Netflix usuário a”O que é recomendado para você” sugestão que ajudará a retê-los por um pouco mais de tempo? Mesmo se você tiver uma loja de moda on-line: como podemos ajudar nossos clientes a encontrar seus produtos de maneira mais fácil? ”Você também pode gostar de...” ou”Frequentemente comprados juntos” ajude a resolver esse problema.
Todos os exemplos mencionados acima são possíveis graças aos sistemas de recomendação.
Sistemas de recomendação
Os sistemas de recomendação aumentam a receita comercial ajudando os clientes a encontrar os itens desejados e comprar os mais adequados para eles com menos esforço.
Alguns exemplos ilustrativos de como os sistemas de recomendação estão impactando as plataformas digitais e o comércio eletrônico são:
- UM McKinsey & Company relatório atribuído 35% do Da Amazon vendas para recomendações [1].
- De acordo com o artigo 'Estudo de desenvolvimento de personalização de 2019'mantido por Monetar: 78% das empresas com uma estratégia de personalização total ou parcial tiveram crescimento de receita (contra um crescimento de receita de 45,4% experimentado por empresas sem estratégia de personalização) [2].
- Uma pesquisa da Epsilon mostra que 80% dos consumidores têm maior probabilidade de fazer uma compra quando a loja on-line oferece experiências personalizadas [3].
- De acordo com Segmento: quase 60% dos consumidores concordaram em se tornar compradores recorrentes após uma experiência de compra personalizada [4].
Filtragem colaborativa versus filtragem de conteúdo
Considerando que existem vários critérios para fazer recomendações específicas aos usuários, também existem vários tipos de sistemas de recomendação. Uma primeira classificação geral distingue entre personalizado ou não personalizado recomendadores. Um exemplo ilustrativo do último consiste em recomendações baseadas em popularidade (por exemplo, quando Netflix mostra os filmes mais populares do seu país).
Por outro lado, os sistemas de recomendação personalizados visam recomendar de forma “personalizada”, encontrando principalmente três tipos de filtragem: colaborativa, baseado em conteúdo e híbridos, que aproveitam as vantagens de ambos os sistemas.
- Filtragem colaborativa se baseia no fato da “semelhança nas preferências” entre os usuários para recomendar novos itens. Dadas as interações anteriores entre usuários e itens, os algoritmos de recomendação aprendem a prever interações futuras. A ideia é que, se algumas pessoas tomaram decisões e compras semelhantes no passado, como a escolha de um filme, há uma grande probabilidade de concordarem com outras seleções futuras.
Por exemplo, na Fig. 1, pode-se observar que se um usuário A e um usuário B gostarem dos mesmos dois filmes, o sistema recomendará ao usuário B um terceiro filme curtido pelo usuário A.
[caption id="attachment_1548" align="aligncenter” width="500"]
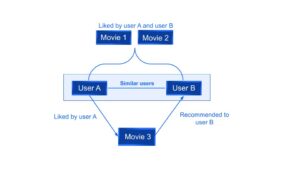
Fig. 1: Exemplo de filtragem colaborativa[/legenda]
- Filtragem de conteúdo, por outro lado, usa os atributos ou recursos de um item - essa é a parte do conteúdo - para recomendar outros itens semelhantes às preferências do usuário. Essa abordagem é baseada na semelhança entre o item e as características do usuário, uma vez que as informações sobre um usuário e os itens com os quais ele interagiu (por exemplo, sexo, idade, avaliação média de um filme) modelam a probabilidade de uma nova interação.
Por exemplo, se um usuário gostou de um filme A, um filme B com recursos semelhantes ao filme A será recomendado ao usuário.
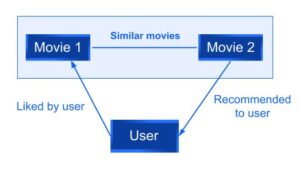
Fig. 2: Exemplos de filtragem baseada em conteúdo
- Um sistema de recomendação híbrido visa superar algumas das limitações dos métodos de filtragem colaborativos e baseados em conteúdo. Há várias maneiras de implementar esse tipo de sistema: fazer previsões baseadas em conteúdo e colaborativas separadamente e depois combiná-las, adicionando recursos baseados em colaboração a uma abordagem baseada em conteúdo ou vice-versa.
Por exemplo, a Netflix faz uso dessa abordagem comparando primeiro o que é assistido por usuários semelhantes (filtragem baseada em colaboração) e, em segundo lugar, recomendando filmes com recursos semelhantes aos mais bem avaliados pelo usuário (filtragem baseada em conteúdo).
Os desafios
O processo de inferência do sistema de recomendação envolve selecionar e classificar os itens candidatos de acordo com a probabilidade prevista de o usuário interagir com eles (aqueles com a maior probabilidade prevista são apresentados ao usuário).
Nesta seção, discutiremos como lidar com os obstáculos encontrados em cada etapa do fluxo de trabalho ao criar um sistema de recomendação desde o início até que esteja pronto para os clientes em produção.
1. Obtendo os dados e preparando-os para o treinamento
Os dados das interações de usuários e itens vêm de avaliações, curtidas ou até mesmo cliques em um site e geralmente são armazenados em datawarehouses ou datalakes. Esses dados são então usados para treinar os sistemas de recomendação. O objetivo principal do processo ETL (Extrair, Transformar e Carregar) é preparar o conjunto de dados para a parte de treinamento, que geralmente vem em um formato tabular que pode até atingir um Terabyte escala, o que significa que há muitos dados para processar na engenharia de recursos (ou seja, na criação de novos recursos a partir dos existentes) e no pré-processamento de peças.
Por exemplo, se sua loja de moda on-line quiser usar uma lista de e-mails para enviar recomendações personalizadas uma vez por mês, primeiro você precisará coletar todas as interações do usuário em seu site (por exemplo, de quais itens o usuário gostou, avaliações anteriores feitas), limpar os dados (por exemplo, avaliações sem significado) e selecionar os recursos que serão usados e, ao mesmo tempo, criar novos (por exemplo, uma taxa média de usuário pode ser útil).
Muitos desafios surgem dessa etapa:
- A falta de dados de alta qualidade: a ausência de dados de alta qualidade pode fazer com que você tenha dificuldades para criar um mecanismo de recomendação preciso.
- Dispersão de dados: encontrado principalmente em sistemas de recomendação colaborativa, esse problema aparece quando um item é avaliado por poucas pessoas, mas com avaliações de alta classificação que não apareceriam na lista de recomendações. Isso pode fornecer recomendações imprecisas para usuários com gostos “incomuns” em comparação com outros usuários.
- Sistemas que podem se adaptar ao mudança nos interesses do usuário: a dinâmica do usuário e do item deve ser considerada ao recomendar (por exemplo, os interesses recentes do usuário não podem ter o mesmo impacto nas recomendações que os mais antigos)
- Etapas como engenharia de recursos, codificação categórica e normalização de variáveis contínuas normalmente podem levar muito tempo, especialmente para recomendadores comerciais que envolvem grandes conjuntos de dados (terabytes ou até maiores) .l
2. Treinamento
A etapa de treinamento geralmente é executada escolhendo uma das estruturas disponíveis (como Pytorch, Tensorflow ou Huge CTR, que é uma biblioteca NVIDIA Merlin que será discutida posteriormente), avaliada e pronta para entrar em produção. Alguns dos desafios que surgem nesta etapa são:
- 'Arranque a frio' problema (encontrado principalmente na filtragem colaborativa): esse problema surge quando um novo usuário ou um novo item acaba de ser adicionado ao sistema de recomendação, onde não existem informações anteriores sobre o usuário, motivo pelo qual o sistema não consegue prever com precisão as próximas escolhas do usuário.
- Problema de gargalo: pode acontecer que sua loja on-line tenha um crescimento sustentado que leve à ampliação do catálogo. Então, agora, uma grande quantidade de dados que não foi considerada inicialmente. Isso pode levar a um “problema de gargalo” no qual seu tabelas de incorporação potencialmente enormes pare de caber na memória da GPU e uma ação corretiva deve ser tomada.
3. Implantação e refinamento do sistema de recomendação
- Necessidade contínua de reciclagem devido à entrada de novos usuários/registros de itens: mesmo que seu modelo esteja funcionando na produção e fazendo recomendações para seus usuários, talvez seja necessário adicionar constantemente novos produtos à sua loja virtual, o que levará a novas interações com seus usuários. Além disso, você também terá novos usuários se cadastrando. Ambos os casos levam à necessidade de retreinar seus modelos para continuar satisfazendo as necessidades do usuário. Isso também leva à necessidade de carregar e descarregar modelos de maneira fácil.
- Lidando com muitos usuários ao mesmo tempo
- Em alguns cenários em tempo real inferência é necessário: por exemplo, quando um cliente está ao lado de “finalizar a compra” de um produto esportivo específico “adicionado ao carrinho”, como alguns shorts de corrida, você também pode sugerir que seu usuário compre outras roupas de corrida. Nesse caso, é necessário que a inferência seja realizada no momento, ou seja, em tempo real. Ao abordar esses tipos de problemas, o tempo de inferência e a quantidade de usuários a serem tratados são os principais aspectos a serem considerados.
Por outro lado, se você quiser que sua loja virtual use uma lista de e-mails para recomendar produtos personalizados para cada usuário uma vez por mês, basta realizar a etapa de inferência antes de enviar os e-mails. Isso consiste em um não em tempo real cenário.
Uma grande variedade de barreiras aparece quando os sistemas de recomendação estão em cena. Então, para tornar a vida dos cientistas de dados e desenvolvedores de aprendizado de máquina mais simples (ou pelo menos tentar), novas ferramentas e estruturas começam a ser desenvolvidas para dar suporte a esse mecanismo de recomendação: TensorFlow recomendadors (uma biblioteca desenvolvida por pesquisadores do Google), Lanterna REC (uma biblioteca de domínio PyTorch) e Nvidia-Merlin (uma estrutura desenvolvida pela NVIDIA) são algumas delas.
A partir de agora, este primeiro artigo se concentrará na NVIDIA-Merlin, lançada em 2020, e promete abordar alguns dos desafios mencionados acima.
NVIDIA-Merlin
A documentação oficial da NVIDIA Merlin se define como uma 'estrutura de código aberto para criar sistemas de recomendação de alto desempenho em escala'. Essa estrutura foi projetada para acelerar todo o sistema de recomendação em todo o fluxo de trabalho de recomendação nas seguintes etapas:
- Pré-processamento
- Engenharia de recursos
- Treinamento
- Inferência
- Implantar na produção
O diagrama a seguir em Figura 3 mostra as principais características das quais NVIDIA Merlin foi desenvolvido e como ele orquestra todo o sistema de recomendação. Tendo essa visão geral do processo, podemos então acessar cada uma das bibliotecas projetadas para essa finalidade.
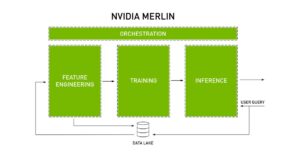
Fig. 4: Orquestração das principais características de um sistema de recomendação pela NVIDIA Merlin [6]
O NVIDIA Merlin fornece vários componentes para que uma única biblioteca ou várias delas possam ser usadas para acelerar todo o pipeline de recomendações: desde a ingestão, o treinamento, a inferência até a implantação e a produção.
Dependendo do problema que você está tentando resolver, os componentes do NVIDIA Merlin usados podem variar.
As três principais bibliotecas projetadas para trabalhar juntas são:
- Tabela NV: projetado para manipular conjuntos de dados do sistema de recomendação que vêm em formato tabular. As partes de pré-processamento e engenharia de recursos são executadas por essa biblioteca.
- Modelos Merlin: fornece modelos padrão (como fatoração matricial ou duas torres) para sistemas de recomendação. Essa biblioteca inclui alguns blocos de construção que permitem definir novas arquiteturas.
- Sistemas Merlin: projetado para implantar o pipeline de recomendação na produção. Isso é feito criando o conjunto que servirá para o Servidor de inferência Triton (descrito posteriormente) que executará a etapa de inferência.
Há também algumas outras bibliotecas Merlin projetadas para enfrentar alguns desafios específicos:
- Ecrã enorme: especialmente útil para casos que envolvem grandes conjuntos de dados e grandes tabelas de incorporação que permitem realizar a etapa de treinamento de forma eficiente, distribuindo o treinamento em várias GPUs e nós.
- Transformadores 4 Rec: projetada para recomendações sequenciais e baseadas em sessões, essa função de biblioteca a torna diferente das demais. Os recomendadores baseados em seqüência capturam padrões sequenciais nos usuários que podem antecipar as intenções do próximo usuário e fornecer recomendações mais precisas. Por outro lado, os recomendadores baseados em sessão (subclasse de sequencial) são usados quando você só tem acesso a uma curta sequência de interações na sessão atual com o objetivo de fornecer recomendações personalizadas mesmo quando o histórico anterior do usuário não está disponível ou quando o gosto dos usuários muda com o tempo.
Além de Figura 3 onde os principais recursos de um sistema de recomendação são resumidos, o Figura 4 mostra como cada biblioteca executa uma tarefa específica dentro do fluxo de trabalho do sistema de recomendação.
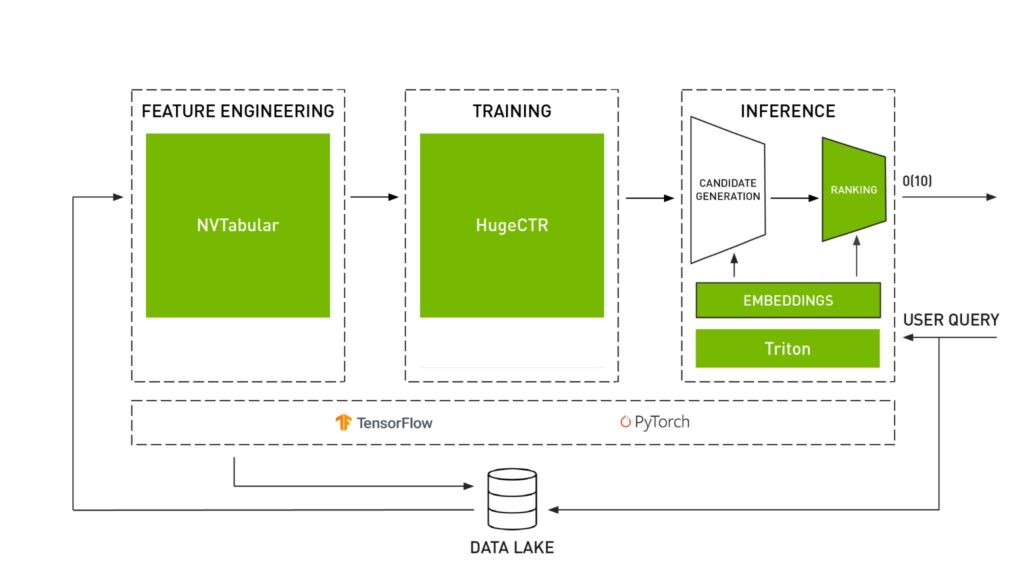
Fig. 4: Bibliotecas NVIDIA Merlin [6]
Um conselho antes de seguir: a Fig. 4 mostra como o Merlin é construído no Tensorflow e no Pytorch. No entanto, antes de seguir, você deve estar ciente de que, para a maioria dos componentes, a API Pytorch foi iniciada, mas incompleta no momento da publicação deste artigo. Portanto, por exemplo, se em seu projeto atual você precisar usar modelos Merlin, ainda não poderá construí-los no Pytorch.
Além dessas bibliotecas, a NVIDIA Merlin aproveita o software já desenvolvido pela NVIDIA AI disponível em sua plataforma. É relevante mencionar o NVIDIA Triton Inference Server, que visa alcançar uma inferência de alto desempenho em escala na produção. Isso é alcançado “executando a inferência de forma eficiente em GPUs, maximizando a taxa de transferência com a combinação certa de latência e utilização da GPU', conforme descrito na documentação oficial da NVIDIA.
Recomendador baseado em sessão: um aplicativo de ponta a ponta usando a NVIDIA-Merlin
Um cenário especial ocorre quando você deseja prever os interesses do próximo usuário, mas não tem informações prévias sobre eles. Isso é útil, pois os interesses do usuário podem mudar com o tempo ou até mesmo quando os usuários decidem navegar no modo privado. Portanto, apenas reunir as informações da sessão atual pode ajudar a resolver esses problemas.
Um exemplo disso é apresentado na documentação oficial fornecida pela NVIDIA com o objetivo de recomendar os próximos itens do usuário a partir das interações da sessão atual.
Nesta seção, as principais etapas e bibliotecas usadas para atingir esse objetivo são descritas (você pode acompanhar o código para ler mais em [5], [6]).
1ª tabela NV: usado para definir o fluxo de trabalho para pré-processar os dados agrupando as interações da mesma sessão, classificando-as por horário.
2º Transformers 4 Rec: esta biblioteca permite que você use a arquitetura de transformador que é importada da biblioteca de PNL Hugging Face Transformers para fazer o treinamento. Essa biblioteca também inclui métricas do Recsys que permitem medir o desempenho do seu modelo.
3º servidor Triton Inference: essa biblioteca permite implantar e servir o modelo para inferência. A implantação de ambos é alcançada: o fluxo de trabalho ETL (já que na inferência você precisará transformar os dados de entrada conforme feito durante o treinamento) e o modelo treinado. Como resultado, agora seus usuários podem consultar o servidor obtendo as previsões do próximo item.
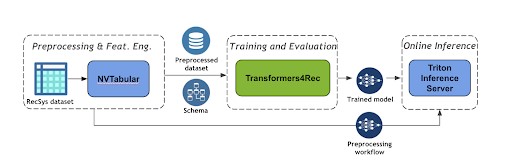
Figura 5: Um fluxo de trabalho de recomendação baseado em sessões [6]
Sobre a solução
Depois de ler a documentação oficial da NVIDIA, decidimos colocar a mão na massa e testar algumas bibliotecas sozinhos. Tabela NV e Modelos Merlin foram os principais componentes abordados, descobrindo alguns aspectos importantes a ter em mente antes de decidir seguir em frente com essa ferramenta.
- Solução de ponta a ponta
Modelos Merlin, NVTabular e Sistemas Merlin são componentes do Merlin projetados para funcionar juntos. Tabela NV produzirá (além dos arquivos de parquet pré-processados), um arquivo de esquema descrevendo as estruturas do conjunto de dados necessárias para alimentar os modelos Merlin. Em seguida, o conjunto com os modelos Merlin deve ser feito para obter o pipeline de inferência do modelo. A etapa final seria implantar os fluxos de trabalho e modelos NV-Tabulares no servidor Triton Inference.
Essa integração projetada entre bibliotecas facilita a criação de pipelines RecSys de ponta a ponta, mas em termos de flexibilidade, a decisão de migrar para outra tecnologia pode ser difícil.
- Um conselho sobre contêineres Docker
A maneira mais simples de usar o Merlin é executando um contêiner docker que pode ser encontrado em https://catalog.ngc.nvidia.com/containers, para evitar problemas de dependência de bibliotecas. Decidimos executá-lo em uma instância da AWS g4dn.xlarge que fornece uma única GPU, 4 vCPUs e um tamanho de memória de 16 GiB. O uso desse tipo de instância custa USD 243 por mês (calculado usando Calculadora AWS). O projeto em que você embarcará definirá seus próprios custos de infraestrutura, que serão diferentes deste, mas com certeza precisarão ser considerados antes de prosseguir.
Como já foi mencionado anteriormente, descobrimos na documentação oficial da NVIDIA o seguinte conselho: “Em nossos lançamentos iniciais, o Merlin Models apresenta uma API Tensorflow. A API PyTorch está iniciada, mas incompleta”.
Então, a primeira coisa a ter em conta: apesar de alguns componentes específicos (como para Transformadores 4REC) O NVIDIA-Merlin foi projetado para ser integrado ao Tensorflow.
Considerações finais
Neste artigo, discutimos primeiro o impacto dos sistemas de recomendação nas plataformas digitais atuais e os diferentes tipos de filtragem. Em seguida, passamos a entender os principais desafios que surgem dos recomendadores e a necessidade de ferramentas que suportem cada etapa do processo de fluxo de trabalho. Finalmente, apresentamos e discutimos NVIDIA Merlin, uma estrutura promissora para construir sistemas de recomendação de ponta a ponta que pode ser útil para acelerar o pré-processamento e a engenharia de recursos usando o NV Tabular, mas não é tão flexível (até agora) para ser usada em um sistema de recomendação completo construído em Pytorch. Também discutimos recomendações baseadas em sessões, que são particularmente úteis quando nenhuma interação anterior do usuário é encontrada.
Na Marvik, estamos sempre buscando tecnologias de ponta para resolver problemas complexos. Sinta-se à vontade para nos contatar em olá @marvik .ai se você tiver alguma dúvida ou quiser compartilhar algumas ideias.
Referências
[1] I. MacKenzie, C. Meyer, S. Noble (2013, 1º de outubro). “Como os varejistas podem acompanhar os consumidores”. https://www.mckinsey.com/industries/retail/our-insights/how-retailers-can-keep-up-with-consumers
[2] Monetate (2019). “Estudo de desenvolvimento de personalização de 2019". https://info.monetate.com/rs/092-TQN-434/images/2019_Personalization_Development_Study_US.pdf
[3] Epsilon (2018, 9 de janeiro). “Uma nova pesquisa da Epsilon indica que 80% dos consumidores têm maior probabilidade de fazer uma compra quando as marcas oferecem experiências personalizadas”. https://www.epsilon.com/us/about-us/pressroom/new-epsilon-research-indicates-80-of-consumers-are-more-likely-to-make-a-purchase-when-brands-offer-personalized-experiences
[4] Keating (2021, 1º de junho). “Anunciando o estado da personalização em 2021”. https://segment.com/blog/announcing-the-state-of-personalization-2021/
[5] NVIDIA. https://nvidia-merlin.github.io/Transformers4Rec/main/examples/tutorial/03-Session-based-recsys.html (acessado em 12/12/2022)
[6] R. AK, G. Moreira (2022, 28 de junho). “Transformers4rec - Construindo recomendações baseadas em sessões com uma biblioteca nvidia merlin”. https://developer.nvidia.com/blog/transformers4rec-building-session-based-recommendations-with-an-nvidia-merlin-library/
[7] NVIDIA. https://github.com/NVIDIA-Merlin/Merlin (acessado em 12/12/2022)



.png)