.png)
Similitud entre imágenes múltiples: un enfoque para un problema recurrente




Motivación
Las imágenes están en todas partes. Puede que conozcas la expresión «una imagen vale más que mil palabras». La cantidad de información que puede proporcionarnos una sola mirada a una imagen es enorme, ¡y podemos procesarla en tan solo 13 milisegundos!
Como seres humanos, pensamos en términos de imágenes y por eso nos cautivan las películas, la televisión y los sitios web. Nos hemos convertido en una sociedad orientada a lo visual. La gente está acostumbrada a ver imágenes y responder a ellas, y esto ha dado lugar a cientos de aplicaciones basadas en imágenes. Restauración o generación de imágenes (como Dallar.), la detección de defectos, la recomendación basada en el contenido y la búsqueda de imágenes en línea son algunos ejemplos de este vasto universo de implementaciones.
Muchas de estas aplicaciones se basan en algoritmos de similitud de imágenes para realizar su tarea principal. Podemos pensar en un modelo semisupervisado para la construcción de conjuntos de datos. Con este modelo, las imágenes nuevas se pueden etiquetar automáticamente calculando su similitud con cualquier otra imagen de un conjunto de datos etiquetado.
Como el lector verá a lo largo del artículo, la comparación de imágenes no es una tarea difícil, al menos, no cuando estamos comparando una imagen con otra. El desafío que queremos abordar aquí es la comparación entre conjuntos de imágenes. Un conjunto de imágenes de un objeto contiene sin duda más información que una sola imagen y por eso este desafío es atractivo.
Está claro que esta extensión hace que el problema pase de ser casi trivial a uno bastante complejo. Intentaremos guiarlo paso a paso sobre cómo lo estamos abordando.
Planteamiento del problema
Nuestro objetivo principal es alcanzar una métrica adecuada para comparar conjuntos de imágenes. Esto se estudió por primera vez en el contexto del comercio electrónico, con el objetivo de recomendar productos similares de los que hubiera varias imágenes disponibles.
Para comparar imágenes y encontrar similitudes, aprovecharemos el funcionamiento de las redes neuronales convolucionales (CNN) y podremos clasificar las imágenes en diferentes categorías. Desde la habitual discriminación entre perros y gatos hasta la red de imágenes conjunto de datos que tiene 1.000 categorías diferentes.
Si le das una imagen a una CNN entrenada, la imagen se convertirá en un vector (incrustación) que conservará las características principales de la imagen. La última capa de la CNN utiliza este vector para clasificar la imagen en una categoría. Por ejemplo, para saber si la imagen era de un perro o un gato. Es posible ver que todos los vectores de una categoría determinada están agrupados en el espacio multidimensional.
Usaremos esta característica para encontrar similitudes entre cualquier imagen. Enviaremos dos imágenes diferentes a una CNN, extraeremos sus vectores correspondientes y, si estos dos vectores están cerca uno del otro, llegaremos a la conclusión de que las dos imágenes originales son similares. Para medir la distancia entre dos vectores podemos calcular su similitud de coseno, y nos referiremos a (1 - similitud de coseno) como puntuación de similitud.
Hay muchas CNN tradicionales previamente entrenadas que podríamos usar para convertir imágenes en vectores (VGG, Resnets, Efficient-nets). Decidimos probar la implementación de Hugging Face del Modelo CLIP. CLIP se concibió principalmente para encontrar similitudes entre imágenes y texto, pero podemos usarlo perfectamente para nuestro propósito de similitud entre imágenes y imágenes. CLIP también ha demostrado un rendimiento de vanguardia en muchas tareas de clasificación, con predicciones sin ningún tipo de entrenamiento específico.
[caption id="attachment_1302" align="aligncenter» width="557"]
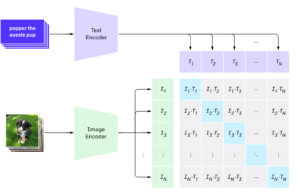
Esquema de procesamiento de imágenes y textos de CLIP. [/caption]
Caso más simple: imagen única
Antes de sumergirnos en aguas más profundas, trataremos de encontrar imágenes similares en un conjunto de datos de calzado, extrayendo datos del Conjunto de datos de moda de 44K. Cuenta con 315 zapatos diferentes con diferentes características. El oleoducto es el siguiente:
- Cambie el tamaño, recorte y rellene las imágenes a una resolución de 240 x 180 cada una de las 315 imágenes.
- Transforma imágenes en vectores de 512 dimensiones con el codificador de imágenes de CLIP.
- Calcule una matriz de distancia (315x315) entre todos los vectores de imagen.
- Extrae las imágenes más cercanas de un zapato determinado.
En las imágenes de abajo podemos ver 4 ejemplos. Para cada zapato, le pedimos al modelo que nos dé las 3 imágenes más cercanas dentro del conjunto de datos. Podemos confirmar visualmente que está haciendo un buen trabajo, separando las zapatillas deportivas de las formales y casuales. También separa correctamente dos tipos diferentes de calzado casual (dos últimos conjuntos de imágenes)
[caption id="attachment_1324" align="aligncenter» width="606"]

Recomendaciones para el artículo objetivo basadas en la similitud de imágenes individuales. [/caption]
Trazando nuestros vectores de imágenes
Como se anticipó, podemos ver cómo las diferentes categorías del conjunto de datos de calzado tienden a agruparse. Una herramienta interesante para la visualización de vectores es t-SNE. Hemos reducido los vectores a solo dos dimensiones con fines de visualización. También podemos ver que los zapatos casuales se cruzan con los zapatos formales y deportivos, y eso tiene mucho sentido. Recuerda que nuestros vectores tienen 512 dimensiones, por lo que es impresionante que con solo dos dimensiones podamos lograr este nivel de agrupamiento.
[caption id="attachment_1338" align="aligncenter» width="615"]

Representación bidimensional de incrustaciones de imágenes. [/caption]
Un poco de sabor: pedí varias imágenes
Era bastante simple, pero recuerda que, en realidad, normalmente tenemos que enfrentarnos a escenarios más generales y, como habrás notado, generalmente tenemos más de una imagen por artículo cuando navegamos por sitios web de comercio electrónico. Esto abre una gama completamente nueva de oportunidades, pero también algunos obstáculos.
La situación más simple en este universo de imágenes múltiples sería aquella en la que cada artículo tuviera la misma cantidad de imágenes, tomadas bajo las mismas reglas (ángulo, fondo, relación artículo-fondo, etc.) y ordenadas por igual.
Aquí tenemos un artículo objetivo para el que encontraremos el artículo más similar de un subconjunto de otros tres candidatas. Hay cuatro imágenes para cada artículo, perfectamente etiquetadas como derecha, arriba, atrás y parte delantera. Para cada etiqueta, también se calcula la puntuación de similitud para cada candidato en relación con el artículo objetivo.
[caption id="attachment_1330" align="aligncenter» width="601"]

Similitud de imágenes de los artículos candidatos desde varios ángulos. [/caption]
Bueno, parece bastante simple. Podríamos simplemente promediar las similitudes de cada candidato y el k los artículos con la mayor similitud deben ser los recomendados. En este caso, con k=1, el Candidato 1 sería el recomendado relacionado con el Artículo objetivo.
El verdadero desafío: imágenes múltiples genéricas
Hasta ahora teníamos un escenario bastante cómodo en el que un conjunto ordenado de n las imágenes de cada objeto estaban disponibles (con el caso particular de n=1). Esta configuración nos permitió comparar las imágenes de cada conjunto en orden y obtener una similitud promedio. Pero, ¿qué ocurre cuando las imágenes no están ordenadas en absoluto? ¿Qué pasa si el tamaño de cada conjunto es diferente? Así es como lo manejamos:
Coincidencia recursiva
La idea detrás de este enfoque es obtener la mejor coincidencia en cada iteración, descartando las imágenes que ya coincidían.
Supongamos que queremos obtener la similitud de un arranque con 4 imágenes en relación con otro arranque con 5 imágenes. Cada conjunto es independiente y no todas las fotografías se toman desde el mismo ángulo.
[caption id="attachment_1244" align="aligncenter» width="688"]

Conjuntos de imágenes de dos artículos con números y ángulos diferentes. [/caption]
El primer paso es comparar todas las imágenes de una cara con las imágenes de la otra. Al hacer esto, obtenemos una matriz de 4x5 con la puntuación de similitud de cada par de imágenes:
cat_black_1cat_black_2cat_black_3cat_black_4cat_black_5cat_brown_1 0,837 (3) 0,835 0,747 0,7703 0,698 cat_brown_2 0,803 0,799 0,838 (2) 0,769 0,769 cat_brown_3 0,772 0,752 0,794 0,761 (4) 0,796 cat_brown_4 0,787 0,785 0,794 0,866 0,881 (1)
Ahora, simplemente tomamos la puntuación más alta (0.881), dada por el par (1). Si sacamos esas dos imágenes de los pares disponibles, la siguiente puntuación más alta es 0.838, dada por (2). Siguiendo esta lógica, obtenemos:

donde (5) no se utiliza.
En este caso, obtenemos una puntuación media de similitud de 0,829, y esa sería la puntuación de similitud entre esas botas.
Es evidente que podría haber algunos desajustes, principalmente debido a la falta de coincidencia real en los conjuntos de imágenes. Podríamos manejar esto de la siguiente manera:
- Establecer un umbral de similitud (s) para que los partidos se consideren en promedio. Por ejemplo: considere solo las coincidencias con una similitud de 0.8 o superior.
- Considera solo un número fijo (m) de coincidencias para calcular la similitud promedio.
Ambos s y m pueden tratarse como hiperparámetros y optimizarse.
- Utilice el aumento de datos (rotación, duplicación, etc.) para encontrar mejores coincidencias y establecer una más restrictiva m o s. Esto aumentaría el costo computacional, pero podría mejorar las métricas.
Debes tener en cuenta que el uso de un m demasiado pequeño para un s demasiado alto podría dañar al modelo. Si m=1 y la mejor combinación en cada par de conjuntos es la de las suelas de los zapatos, no queremos recibir recomendaciones significativas.
Optimización lineal
Otra alternativa para hacer coincidir conjuntos de imágenes es utilizar la optimización lineal. Esta herramienta encuentra la distancia total mínima entre dos conjuntos de imágenes.
Aquí podemos ver una comparación de cómo cada algoritmo selecciona las coincidencias marcadas en azul en la misma matriz de distancias. La optimización lineal encuentra una distancia total más baja y obtiene una «peor coincidencia» muy razonable, pero no elige la mejor coincidencia absoluta.
[caption id="attachment_1339" align="aligncenter» width="491"]
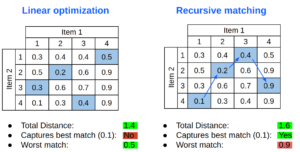
Comparación sencilla entre la optimización lineal y la coincidencia recursiva [/caption]
Rutas alternativas
- Adición de texto
También es habitual tener algunos metadatos de los artículos, es decir, el nombre del producto, la categoría, una breve descripción, etc. Todo este texto puede ser tremendamente útil a la hora de hacer coincidir los artículos. Un ejemplo claro serían las descripciones de zapatos pesados. Algunos tienen un aspecto muy deportivo, pero ninguno de nosotros compraría uno para correr una maratón.
Hay varias maneras de hacerlo:
-
- Reduce el espacio de búsqueda a un conjunto restringido, agrupado por categoría o uso. Esto puede resultar algo complicado dado que muchos artículos pueden pertenecer a más de una categoría.
- Compara las distancias de las imágenes como antes e incluye también las distancias de texto entre el artículo y los candidatos. El proceso más sencillo consiste en promediar el peso de las similitudes entre imágenes y textos.
- Redes/algoritmos alternativos
Como se indicó al principio, hay muchas otras arquitecturas que podrían usarse para calcular las incrustaciones, como VGG, Resnets y Efficient-Nets.
También hay algunas bibliotecas (Similitud de Tensorflow, DUP rápido) que podría explorarse para extender la comparación de imágenes a conjuntos de imágenes.
- Entidad 3D
Otro enfoque muy interesante podría implicar tratar un conjunto de imágenes como un todo y no como fragmentos discretos de datos. Poder extraer características de cada imagen y generar una entidad 3D de cada artículo resolvería el problema de los conjuntos ordenados y de diferentes tamaños.
Este proceso sería mucho más complejo. También podría aplicarse mejor a dominios específicos y no a un propósito general, ya que las características extraídas podrían depender de ellos.
- Transferir el aprendizaje
Si tuviéramos un conjunto de datos con una cantidad considerable de imágenes (y algunos horas de trabajo libres), puede ser una buena idea etiquetar la similitud entre los conjuntos de imágenes según ciertos criterios. Entonces, podríamos utilizar una red previamente entrenada y entrenar algunas capas nuevas con el objetivo de distinguir si dos conjuntos de imágenes representan objetos similares.
Conclusión
Como en la mayoría de los proyectos de aprendizaje automático, partimos de un problema bastante simple y agregamos algo de complejidad en cada iteración. Partiendo de una única y hermosa imagen de cada artículo, terminamos teniendo conjuntos desordenados de diferentes imágenes, y ya estamos a mitad de camino. El escenario más general es aquel en el que el fondo de la imagen es irregular y, en el caso de los artículos de moda, podría estar siendo usado por una persona.
En Marvik tenemos una amplia experiencia trabajando con Image Similarity y nos encantan este tipo de desafíos. Si estás trabajando en un proyecto de estas características o quieres obtener más información, comunícate con [email protected] ¡y podemos ayudarte!



.png)