.png)
Similaridade de várias imagens: uma abordagem para um problema recorrente




Motivação
As imagens estão por toda parte. Talvez você conheça a expressão “uma imagem vale mais que mil palavras”. A quantidade de informações que uma única olhada em uma imagem pode nos dar é enorme e podemos processá-la em apenas 13 milissegundos!
Como seres humanos, pensamos em termos de imagens e é por isso que somos cativados por filmes, televisão e sites. Nós nos tornamos uma sociedade visualmente orientada. As pessoas estão acostumadas a ver e responder às imagens e isso deu origem a centenas de aplicativos baseados em imagens. Restauração ou geração de imagens (como Dale.), detecção de defeitos, recomendação baseada em conteúdo e pesquisa de imagens on-line são alguns exemplos desse vasto universo de implementações.
Muitos desses aplicativos dependem de algoritmos de similaridade de imagem para realizar sua tarefa principal. Podemos pensar em um modelo semissupervisionado para construção de conjuntos de dados. Com esse modelo, novas imagens podem ser rotuladas automaticamente calculando sua semelhança com todas as outras imagens de um conjunto de dados rotulado.
Como o leitor verá ao longo do artigo, a comparação de imagens não é uma tarefa difícil, pelo menos não quando estamos comparando uma imagem com outra. O desafio que queremos abordar aqui é a comparação entre conjuntos de imagens. Um conjunto de imagens de um objeto certamente tem mais informações do que uma única imagem e é por isso que esse desafio é atraente.
É claro que essa extensão transforma o problema de quase trivial em bastante complexo. Tentaremos orientá-lo passo a passo sobre como estamos lidando com isso.
Declaração do problema
Nosso principal objetivo é alcançar uma métrica apropriada para comparar conjuntos de imagens. Isso foi estudado pela primeira vez no contexto do comércio eletrônico, com o objetivo de recomendar produtos similares nos quais várias imagens estão disponíveis.
Para comparar imagens e encontrar semelhanças, aproveitaremos como as redes neurais convolucionais (CNNs) funcionam e poderemos classificar imagens em diferentes categorias. Da discriminação usual de gato/cachorro ao rede de imagens conjunto de dados que tem 1.000 categorias diferentes.
Se você enviar uma imagem para uma CNN treinada, a imagem será convertida em um vetor (incorporação) que retém as principais características da imagem. Esse vetor é usado pela última camada da CNN para classificar a imagem em uma categoria. Por exemplo, para saber se a imagem era de um cachorro ou de um gato. É possível ver que todos os vetores de uma determinada categoria estão agrupados no espaço multidimensional.
Usaremos essa característica para encontrar semelhanças entre qualquer imagem. Vamos enviar duas imagens diferentes para uma CNN, extrair seus vetores correspondentes e, se esses dois vetores estiverem próximos um do outro, concluiremos que as duas imagens originais são semelhantes. Para medir a distância entre dois vetores, podemos calcular sua similaridade de cosseno e nos referiremos a (1 - semelhança de cosseno) como pontuação de similaridade.
Existem muitas CNNs tradicionais pré-treinadas que podemos usar para converter imagens em vetores (VGGs, Resnets, Efficient-NETs). Decidimos experimentar a implementação do Hugging Face do Modelo CLIP. O CLIP foi concebido principalmente para encontrar semelhanças entre imagem e texto, mas podemos usá-lo perfeitamente para nosso propósito de semelhança entre imagem e imagem. O CLIP também demonstrou desempenho de última geração em muitas tarefas de classificação com previsões zero sem nenhum treinamento específico de ajuste fino.
[caption id="attachment_1302" align="aligncenter” width="557"]
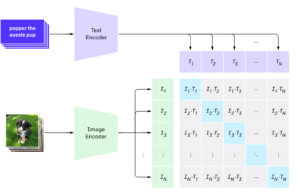
Esquema de processamento de imagem e texto do CLIP. [/legenda]
Caso mais simples: imagem única
Antes de mergulhar em águas mais profundas, tentaremos encontrar imagens semelhantes em um conjunto de dados de calçados, extraindo dados do Conjunto de dados 44K Fashion. Tem 315 sapatos diferentes com características diferentes. O pipeline é o seguinte:
- Redimensione, recorte e preencha imagens para uma resolução de 240x180 em cada uma das 315 imagens.
- Transforme imagens em 512 vetores dimensionais usando o codificador de imagem CLIP.
- Calcule uma matriz de distância (315x315) entre todos os vetores de imagem.
- Extraia as imagens mais próximas de qualquer sapato.
Nas imagens abaixo, podemos ver 4 exemplos. Para cada sapato, pedimos ao modelo que nos forneça as 3 imagens mais próximas dentro do conjunto de dados. Podemos confirmar visualmente que está fazendo um bom trabalho, separando os calçados esportivos dos formais e casuais. Ele também separa corretamente dois tipos diferentes de sapatos casuais (dois últimos conjuntos de imagens)
[caption id="attachment_1324" align="aligncenter” width="606"]

Recomendações para o artigo alvo com base na semelhança de imagens únicas. [/legenda]
Traçando nossos vetores de imagem
Conforme previsto, podemos ver como as diferentes categorias do conjunto de dados de calçados tendem a se agrupar. Uma ferramenta interessante para visualizar vetores é o t-SNE. Reduzimos os vetores para apenas duas dimensões para fins de visualização. Também podemos ver que sapatos casuais se cruzam com calçados formais e esportivos e isso faz todo o sentido. Lembre-se de que nossos vetores têm 512 dimensões, então é impressionante que, com apenas duas dimensões, possamos atingir esse nível de agrupamento.
[caption id="attachment_1338" align="aligncenter” width="615"]

Representação bidimensional de incorporações de imagens. [/legenda]
Um pouco de tempero: várias imagens solicitadas
Isso foi bem simples, mas lembre-se de que, na realidade, geralmente precisamos enfrentar cenários mais gerais e, como você deve ter notado, geralmente temos mais de uma imagem por artigo ao navegar em sites de comércio eletrônico. Isso abre uma nova gama de oportunidades, mas também alguns obstáculos.
A situação mais simples nesse universo de várias imagens seria aquela em que cada artigo tivesse a mesma quantidade de imagens, tiradas sob as mesmas regras (ângulo, plano de fundo, proporção de fundo do artigo etc.) e igualmente ordenadas.
Aqui temos um artigo alvo para o qual encontraremos o artigo mais semelhante de um subconjunto de três outros candidatos. Há quatro imagens para cada artigo, perfeitamente marcadas como direita, em cima, atrás e frente. Para cada tag, há também a pontuação de similaridade calculada para cada candidato relacionado ao artigo alvo.
[caption id="attachment_1330" align="aligncenter” width="601"]

Similaridade de imagens de artigos candidatos sob vários ângulos. [/legenda]
Bem, parece bastante simples. Poderíamos apenas calcular a média das semelhanças de cada candidato e do k artigos com maior similaridade devem ser os recomendados. Nesse caso, com k=1, o Candidato 1 seria o recomendado relacionado ao Artigo alvo.
O verdadeiro desafio: várias imagens genéricas
Até agora, tivemos um cenário bastante confortável em que um conjunto ordenado de n imagens de cada objeto estavam disponíveis (com o caso particular de n=1). Essa configuração nos permitiu comparar as imagens de cada conjunto em ordem e obter uma semelhança média. Mas o que acontece quando as imagens não são ordenadas? E se o tamanho de cada conjunto for diferente? Foi assim que lidamos com isso:
Correspondência recursiva
A ideia por trás dessa abordagem é obter a melhor correspondência em cada iteração, descartando as imagens que já foram correspondidas.
Vamos supor que queremos obter a semelhança de uma inicialização com 4 imagens em relação a outra inicialização com 5 imagens. Cada conjunto é independente e nem todas as fotos são tiradas do mesmo ângulo.
[caption id="attachment_1244" align="aligncenter” width="688"]

Conjuntos de imagens de dois artigos com números e ângulos diferentes. [/legenda]
O primeiro passo é comparar todas as imagens de um lado com as imagens do outro. Ao fazer isso, obtemos uma matriz 4x5 com a pontuação de similaridade de cada par de imagens:
cat_black_1cat_black_2cat_black_3cat_black_4cat_black_5cat_brown_1 0,837 (3) 0,835 0,747 0,703 0,698 cat brown_2 0,803 0,799 0,838 (2) 0,760 0,769 cat brown_3 0,772 0,752 0,794 0,761 (4) 0,796 cat brown_4 0,787 0,785 0,794 0,866 0,881 (1)
Agora, simplesmente pegamos a pontuação mais alta (0,881), dada pelo par (1). Tirando essas duas imagens dos pares disponíveis, a próxima pontuação mais alta é 0,838, dada por (2). Seguindo essa lógica, obtemos:

onde (5) não é usado.
Nesse caso, obtemos uma pontuação média de similaridade de 0,829, que seria a pontuação de similaridade entre essas botas.
Claramente, pode haver algumas incompatibilidades, principalmente devido à falta de correspondência real nos conjuntos de imagens. Poderíamos lidar com isso da seguinte forma:
- Definindo um limite de similaridade (s) para que as partidas sejam consideradas em média. Por exemplo: considere somente as correspondências com similaridade 0,8 ou superior.
- Considere apenas um número fixo (m) de correspondências para calcular a semelhança média.
Ambos s e m podem ser tratados como hiperparâmetros e ser otimizados.
- Use o aumento de dados (rotação, espelhamento etc.) para encontrar melhores correspondências e definir uma opção mais restritiva m ou s. Isso aumentaria o custo computacional, mas poderia aprimorar as métricas.
Você deve levar em conta que o uso de um m muito pequeno ou um s muito alto pode prejudicar o modelo. Se m=1 e a melhor combinação em cada par de conjuntos é a das solas dos sapatos, não receberíamos recomendações significativas.
Otimização linear
Outra alternativa para combinar conjuntos de imagens é usar a otimização linear. Essa ferramenta encontra a distância total mínima entre dois conjuntos de imagens.
Aqui podemos ver uma comparação de como cada algoritmo escolhe as correspondências marcadas em azul na mesma matriz de distância. A otimização linear encontra uma distância total menor e obtém uma “pior correspondência” bastante razoável, mas não escolhe a melhor correspondência absoluta.
[caption id="attachment_1339" align="aligncenter” width="491"]
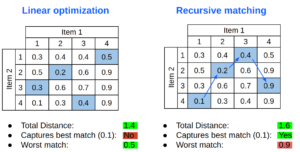
Comparação simples entre otimização linear e correspondência recursiva [/caption]
Caminhos alternativos
- Adição de texto
Também é comum ter alguns metadados dos artigos, ou seja, nome do produto, categoria, descrição curta, etc. Todo esse texto pode ser extremamente útil ao combinar itens. Um exemplo claro seria a descrição de calçados pesados. Alguns deles parecem muito esportivos, mas nenhum de nós compraria um para correr uma maratona.
Há algumas maneiras de fazer isso:
-
- Reduza o espaço de pesquisa para um conjunto restrito, agrupado por categoria ou uso. Isso pode ser um pouco complicado, já que muitos artigos podem se encaixar em mais de uma categoria.
- Compare as distâncias da imagem como antes e inclua também as distâncias do texto entre o artigo e os candidatos. O processo mais simples envolve a média de peso das semelhanças entre imagens e textos.
- Redes/algoritmos alternativos
Conforme afirmado no início, existem muitas outras arquiteturas que podem ser usadas para calcular as incorporações, como VGGs, Resnets, Efficient-Nets.
Existem também algumas bibliotecas (Similaridade do Tensorflow, FastDup) que poderiam ser explorados para estender a comparação de imagens a conjuntos de imagens.
- Entidade 3D
Outra abordagem muito interessante pode envolver o tratamento de um conjunto de imagens como um todo e não como blocos discretos de dados. Ser capaz de extrair características de cada imagem e gerar uma entidade 3D de cada artigo superaria o problema de conjuntos ordenados e de tamanhos diferentes.
Esse processo seria muito mais complexo. Também pode ser melhor aplicado a domínios específicos e não para fins gerais, pois as características extraídas podem depender deles.
- Transferir aprendizado
Se tivéssemos um conjunto de dados com uma quantidade considerável de imagens (e alguns poupe horas de trabalho para gastar), pode ser uma boa ideia rotular a semelhança entre conjuntos de imagens sob certos critérios. Poderíamos então fazer uso de uma rede pré-treinada e treinar algumas novas camadas com o objetivo de distinguir se dois conjuntos de imagens representam objetos semelhantes.
Conclusão
Como na maioria dos projetos de aprendizado de máquina, partimos de um problema bem simples e adicionamos alguma complexidade a cada iteração. A partir de uma única imagem bonita de cada artigo, acabamos tendo conjuntos não ordenados de imagens diferentes e estamos na metade do caminho. O cenário mais geral é aquele em que o fundo da imagem é irregular e, no caso de artigos de moda, eles podem estar sendo usados por uma pessoa.
Na Marvik, temos uma vasta experiência trabalhando com Image Similarity e adoramos esse tipo de desafio. Se você estiver trabalhando em um projeto com essas características ou quiser saber mais, entre em contato com [email protected] e nós podemos te ajudar!



.png)