.png)
Los personajes parlantes con IA de MoCha dan vida a tu guion




[ancho de vídeo="944" height="528" mp4=» https://blog.marvik.ai/wp-content/uploads/2025/04/2p_2clip_2talk_spaceship_woman_man_bruse.mp4"][/video]
Vídeo de Página del proyecto MoCHA
Conoce a los personajes parlantes con inteligencia artificial de MoCha, una tecnología innovadora que toma un guion (hecho con voz y texto) y, aunque puede que no sirva para toda la película, le da vida. No solo una cabeza de Zordon flotante, no solo Hotel Reverie, sino un personaje de cuerpo entero con movimientos y contexto naturales. Es el tipo de tecnología que parece sacada del episodio de Black Mirror, solo que es muy real. [caption id="attachment_4328" align="aligncenter» width="504"]
MoCha como caja negra [/caption] Los personajes parlantes desempeñan un papel fundamental a la hora de transmitir mensajes y atraer emocionalmente al público. En el cine, el diálogo es una herramienta fundamental para contar historias: frases icónicas como «Que la fuerza te acompañe» de La guerra de las galaxias muestran cómo una sola frase puede resonar mucho más allá de la pantalla (lo sé, también leo con voz de Jedi). Este poder comunicativo también impulsa una amplia gama de aplicaciones, desde asistentes virtuales y avatares digitales hasta contenido publicitario y educativo. Los personajes parlantes basados en inteligencia artificial de MoCha mejoran este poder comunicativo al permitir actuaciones digitales más matizadas y expresivas. En cuanto a la tecnología, los modelos básicos de vídeo, como SoRa, han logrado avances impresionantes a la hora de generar vídeos visualmente atractivos a partir de indicaciones de texto. Partiendo de esta base, Mocha presenta capacidades avanzadas de voz que permiten que los personajes hablen de forma más expresiva y realista. Este avance es particularmente evidente en los personajes parlantes basados en la IA de MoCha, donde las instrucciones detalladas pueden definir los rasgos, el estado emocional, los movimientos, la ambientación de la escena, la estructura narrativa e incluso la dirección del rostro del personaje. Por ejemplo:
[perfectpullquote align="full» bordertop="false» cite= "» link= "» color= "» class= "» size=" "] «Un primer plano de un hombre sentado en un sofá gris oscuro... Detrás del hombre hay tres lámparas cilíndricas blancas con luces amarillas en su interior... el hombre sigue hablando a la cámara mientras sostiene un cigarro encendido, el humo se enrolla suavemente en el aire...» [/perfectpullpullcita]
[ancho de vídeo="976" height="528" mp4=» https://blog.marvik.ai/wp-content/uploads/2025/04/1p_man_cigar_i_have_said_it_before.mp4"][/video]
Vídeo resultante de Página del proyecto MoCHA
Por otro lado, los métodos de generación de vídeo basados en la voz, como Emo y Halloween 3, se han orientado a los movimientos faciales durante el proceso del habla, pero se han limitado mucho a escenarios realistas. MoCa une lo mejor de ambos mundos al abordar la compleja tarea de modelar los movimientos corporales coordinados, las expresiones faciales y la alineación multimodal. Este enfoque integrado establece un nuevo estándar para la creación de vídeos con voz.
Descripción general de la arquitectura
[caption id="attachment_4332" align="aligncenter» width="750"]
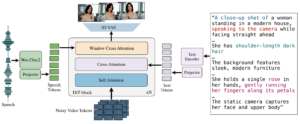
Arquitectura MoCa en papel. [/caption] La arquitectura principal del modelo se basa en un transformador de difusión basado en un decodificador autorregresivo que genera una secuencia unificada de señales de vídeo condicionadas por la entrada de audio/texto y las indicaciones de caracteres mediante la atención cruzada. Comienza con un vídeo RGB ruidoso y lo codifica en un espacio latente mediante un VAE 3D para reducir la resolución espacial y temporal del vídeo. A continuación, centra su atención en sí misma y en los elementos de estado de audio y texto para generar una paralelización de todos los fotogramas de vídeo: un identificador de vídeo corresponde a una ventana local de símbolos de audio para alinearlos. Para sincronizar eficazmente la voz con el vídeo, MoCHA introduce un mecanismo de atención de la ventana de voz y vídeo. Esta atención alinea selectivamente las funciones de audio con los fotogramas de vídeo relevantes desde el punto de vista temporal, garantizando que la animación refleje los matices prosódicos y el ritmo del habla. MoCha permite generar conversaciones entre varios personajes a través de plantillas de mensajes estructuradas que incluyen etiquetas de caracteres y controles de diálogo por turnos. La generación de clips es la misma que la de un solo clip, pero con un proceso simultáneo en el que se presta más atención a los distintos elementos para garantizar la coherencia de los personajes en los distintos clips. La señal de audio guía el momento de corte de la escena entre los clips. Para evitar el exceso de verbosidad y complejidad en el mensaje, MoCha utiliza una plantilla con los siguientes elementos: [perfectpullquote align="full» bordertop="false» cite= "» link= "» color= "» class= "» size=" "]
- Número de clips: Dos videoclips
- Personajes:
- Persona 1: Un hombre dentro de un traje blindado pesado con un brazo de motosierra está de pie.
- Persona 2: Una mujer cyborg enojada.
- Primer clip: Persona 1 de pie en una zona boscosa y cubierta de hierba, en una pose dramática, a mitad de la acción, lista para atacar a cualquier tiburón que se atreva a volar en su camino. La cámara amplía gradualmente el rostro de la Persona 1.
- Segundo clip: La persona 2 lanza tiburones voladores con su cañón de brazo biónico como un enorme tornado que atraviesa el horizonte de una ciudad detrás de ella.
[/cita perfecta]
Proceso formativo
MoCHA se basa en un modelo de transformador de difusión de 30B previamente entrenado. Para hacer frente a la disponibilidad limitada de conjuntos de datos de vídeo con anotaciones de voz a gran escala, el MoCHA adopta un enfoque de formación conjunto que integra datos etiquetados con voz y texto. Esta fusión multimodal mejora la capacidad del modelo para generalizar en diferentes estilos de personajes, patrones de movimiento y contextos de diálogo. Para aumentar aún más la diversidad y la solidez, el 20% de la formación se basa únicamente en datos de conversión de texto a vídeo sin el audio correspondiente. El corpus de formación combina conjuntos de datos privados y públicos con distintos niveles de calidad de anotación. El rendimiento de MoCha se evaluó mediante una combinación de métricas automáticas (que evaluaban la precisión de la sincronización labial y la calidad del movimiento) y estudios en humanos centrados en el realismo, la expresividad y las preferencias generales del usuario. Todos los modelos se entrenan utilizando una resolución espacial cercana a 720 × 720, con soporte para múltiples relaciones de aspecto. Cada modelo está optimizado para producir vídeos de 128 fotogramas a 24 fps, lo que da como resultado salidas de aproximadamente 5,3 segundos de duración. Los modelos requieren dos modelos de memoria NVIDIA A-100 de 80 GB para la inferencia, según la cantidad de parámetros (30 B), sin cuantificación (PF32) y con un Factor de gastos generales del 20%.
Marco de evaluación
Para la evaluación del modelo, crean un banco MoCHA para la tarea de generación de personajes parlantes y consisten en cinco puntajes de evaluación humana del 1 al 4.
- Calidad de sincronización de labios: mide la sincronización entre el audio hablado y los movimientos de los labios del personaje.
- Naturalidad de la expresión facial: evalúa las expresiones faciales en relación con el mensaje y el contenido del discurso dados.
- Acción: naturalidad: evalúa los movimientos corporales de acuerdo con los gestos, el habla y las indicaciones.
- Alineación del texto: verifique que el contexto y las acciones se alineen con la solicitud.
- Calidad visual: busca artefactos, discontinuidades o fallos.
Obras relacionadas
Si quieres obtener más información sobre los vídeos de personajes generados por IA, ya sea para avatares parlantes, narraciones animadas o síntesis de vídeo controlable, hay un creciente número de investigaciones que vale la pena explorar.
Magia infinita tiene como objetivo producir vídeos de conversación de alta fidelidad con varios tipos de personajes de cuerpo completo o individuales, pero con énfasis en las posturas faciales. También utiliza una estrategia de transformación de difusión con mecanismos de atención plena en 3D y una ventana corrediza para eliminar el ruido, e incorpora un esquema de aprendizaje curricular de dos pasos, que integra audio para sincronizar los labios, texto para la dinámica expresiva e imágenes de referencia para preservar la identidad. Utiliza una máscara específica para cada región para identificar con precisión a los hablantes en escenas con varios personajes. Puede generar un vídeo de 10 segundos a 540x540p en 10 segundos o 720x720p en 30 segundos en 8 GPU H100 sin pérdida de calidad.
[ancho de vídeo="400" height="400" mp4=» https://blog.marvik.ai/wp-content/uploads/2025/04/id-55_BfB3AezynUF8grvgMK5Wg_5fdd297fedf64843b55d4ac76d055eeb_ElevenLabs_2024-09-24T20_03_16_Allison-millennial_pvc_s41_sb95_t2_repeat-0_emaTrue_gaudio_1.0_gtext_1.0.mp4"][/video]
Vídeo resultante de Página del proyecto MagicInfinite
Cajero se centra en crear vídeos de cabezas parlantes de alta fidelidad al separar el movimiento de la apariencia mediante un marco de dos etapas: un modelo de audio a movimiento (AToM) para movimientos sincronizados de los labios y un modelo de movimiento a vídeo (MToV) para producir vídeos de cabeza detallados. Si bien ModiTalker se destaca por capturar expresiones faciales sutiles y garantizar la coherencia temporal, MoCHA va más allá de las cabezas parlantes y abarca la animación de personajes de cuerpo entero y las interacciones entre varios personajes, abordando una gama más amplia de elementos narrativos.
[ancho de vídeo="400" height="400" mp4=» https://blog.marvik.ai/wp-content/uploads/2025/04/Video-sin-titulo-‐-Hecho-con-Clipchamp.mp4"][/video]
Vídeo resultante de Página del proyecto Teller
Chatea con cualquier persona apunta a la generación en tiempo real de vídeos estilizados de retratos, que van desde cabezas parlantes hasta interacciones con la parte superior del cuerpo. Hace hincapié en las expresiones faciales expresivas y los movimientos corporales sincronizados, incluidos los gestos con las manos, para mejorar las videoconferencias interactivas. ChatAnyone utiliza modelos jerárquicos de difusión de movimiento que incorporan representaciones de movimiento explícitas e implícitas basadas en entradas de audio. Las señales explícitas de control manual están integradas en el generador para producir gestos detallados con las manos, lo que mejora el realismo y la expresividad generales de los vídeos de retratos.
Reflexiones finales
Con MoCHA, estamos presenciando un salto significativo para hacer que los personajes generados por IA sean más cinematográficos, expresivos y conscientes del contexto. Al cerrar la brecha entre los modelos de difusión de texto a vídeo y la animación basada en la voz, MoCHA introduce un nuevo paradigma para la narración de historias de cuerpo entero y con varios personajes. Su capacidad para sincronizar señales de audio complejas con expresiones faciales, movimientos corporales y narrativas a nivel de escena lo convierte en una herramienta versátil para creadores de todos los sectores. El potencial de los personajes parlantes basados en inteligencia artificial de MoCHA para revolucionar campos que van desde la cinematografía hasta los agentes virtuales es inmenso. A diferencia de los sistemas anteriores, que se centraban en el realismo facial o en los gestos corporales básicos, el transformador de difusión unificado de MoCHA reúne estas dimensiones para generar videoclips que no solo tienen una gran riqueza visual, sino que también tienen una gran resonancia emocional y están alineados contextualmente con el mensaje narrativo. A medida que el contenido de vídeo generado por IA se hace cada vez más frecuente, herramientas como MoCHA muestran que no estamos lejos de contar con actores digitales dinámicos y naturales que puedan leer un guion e interpretarlo de forma convincente. Sin embargo, actualmente está limitado a una duración de 5,3 segundos. Meta publicará pronto el código y los pesos de MoCha.
Referencias
Fórmula para calcular la memoria de la GPUMoCHA: Hacia una síntesis de personajes parlantes al nivel cinematográficoMagicInfinite: Cómo generar vídeos de conversación infinitos con tus palabras y tu vozChatAnyone: generación estilizada de videos de retratos en tiempo real con un modelo jerárquico de difusión de movimientoTeller: animación de retratos basada en audio en streaming en tiempo real con generación de movimiento autorregresivo



.png)