.png)
Os personagens falantes de IA do MoCha dão vida ao seu roteiro




[largura do vídeo="944" height="528" mp4=” https://blog.marvik.ai/wp-content/uploads/2025/04/2p_2clip_2talk_spaceship_woman_man_bruse.mp4"][/video]
Vídeo de Página do projeto MoCha
Conheça os personagens falantes com inteligência artificial do MoCHa, uma tecnologia inovadora que pega um roteiro (feito com fala e texto) e, embora possa não fazer parte do filme completo, dá vida a ele. Não apenas uma cabeça flutuante de Zordon, não apenas Hotel Reverie, mas um personagem de corpo inteiro com movimentos e contexto naturais. É o tipo de tecnologia que parece ter saído diretamente do episódio de Black Mirror, mas é muito real. [caption id="attachment_4328" align="aligncenter” width="504"]
MoCHa como caixa preta [/caption] Personagens falantes desempenham um papel fundamental na transmissão de mensagens e no envolvimento emocional do público. No cinema, o diálogo é uma ferramenta fundamental para contar histórias — frases icônicas como “Que a Força esteja com você” de Star Wars mostram como uma única frase pode ressoar muito além da tela (eu sei, também leio com uma voz de Jedi). Esse poder comunicativo também impulsiona uma ampla variedade de aplicativos, desde assistentes virtuais e avatares digitais até conteúdo publicitário e educacional. Os personagens falantes com inteligência artificial do MoCHa aprimoram esse poder comunicativo ao permitir performances digitais mais diferenciadas e expressivas. No que diz respeito à tecnologia, modelos de base de vídeo, como o SoRa, fizeram avanços impressionantes na geração de vídeos visualmente atraentes a partir de instruções de texto. Com base nisso, o Mocha apresenta recursos avançados de fala que permitem personagens falantes mais expressivos e realistas. Esse avanço é particularmente evidente nos personagens falantes de IA do MoCHa, onde instruções detalhadas podem definir as características, o estado emocional, os movimentos, o cenário, a estrutura narrativa e até mesmo a direção do personagem. Por exemplo:
[perfectpullquote align="full” bordertop="false” cite= "” link= "” color= "” class= "” size=" "] “Uma foto em close-up de um homem sentado em um sofá cinza escuro... Atrás do homem estão três luminárias cilíndricas brancas com luzes amarelas dentro delas... o homem continua falando com a câmera enquanto segura um charuto aceso, a fumaça diminui mergulhando suavemente no ar...” [/perfectpullquote]
[largura do vídeo="976" height="528" mp4=” https://blog.marvik.ai/wp-content/uploads/2025/04/1p_man_cigar_i_have_said_it_before.mp4"][/video]
Resultado do vídeo de Página do projeto MoCha
Por outro lado, métodos de geração de vídeo baseados em fala, como Emo e Hallo3, foram orientados para movimentos faciais durante o processo de fala, mas foram muito limitados a cenários realistas. MoCHa une o melhor dos dois mundos ao enfrentar a complexa tarefa de modelar movimentos corporais coordenados, expressões faciais e alinhamento multimodal. Essa abordagem integrada define um novo padrão para a criação de vídeos baseados em voz.
Uma visão geral da arquitetura
[caption id="attachment_4332" align="aligncenter” width="750"]
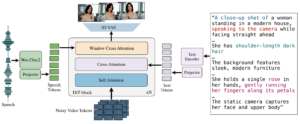
Arquitetura MoCHa a partir do papel. [/caption] A arquitetura do modelo principal é construída em torno de um transformador de difusão baseado em um decodificador autorregressivo que gera uma sequência unificada de tokens de vídeo condicionados por entrada de áudio/texto e solicitações de caracteres por meio de atenção cruzada. Ele começa com um vídeo RGB ruidoso e o codifica em um espaço latente usando um VAE 3D para reduzir a resolução do vídeo espacial e temporalmente. Em seguida, ele usa autoatenção e atenção cruzada com os tokens de condição de texto e áudio para gerar uma paralelização de todos os quadros de vídeo: um token de vídeo corresponde a uma janela local de tokens de áudio para alinhá-los. Para sincronizar efetivamente a fala com o vídeo, o MoCHa introduz um mecanismo de atenção na janela de fala e vídeo. Essa atenção alinha seletivamente os recursos de áudio com quadros de vídeo temporalmente relevantes, garantindo que a animação reflita nuances prosódicas e o ritmo da fala. O MoCHA permite a geração de conversas entre vários personagens por meio de modelos de prompt estruturados que incluem etiquetas de caracteres e controle de diálogo por turnos. A geração do clipe é igual à do clipe único, mas com um processo simultâneo com atenção extra em todos os tokens para garantir a consistência dos caracteres nos vários clipes. O sinal de áudio guia o momento de corte da cena entre os clipes. Para evitar o excesso de verbosidade e complexidade no prompt, o MoCHa usa um modelo com esses elementos: [perfectpullquote align="full” bordertop="false” cite= "” link= "” color= "” class= "” size=" "]
- Número de clipes: Dois videoclipes
- Personagens:
- Pessoa 1: Um homem dentro de um macacão blindado pesado com uma serra elétrica se apoia.
- Pessoa 2: Uma mulher ciborgue com raiva.
- Primeiro clipe: Pessoa 1 em pé em uma área gramada e arborizada, fazendo uma pose dramática, em ação, pronta para atacar qualquer tubarão que se atreva a voar em sua direção. A câmera gradualmente amplia o rosto da Pessoa 1.
- Segundo clipe: A pessoa 2 explode tubarões voadores com seu canhão biônico como um enorme tornado no horizonte de uma cidade atrás dela.
[/perfect pullquote]
Processo de treinamento
O MoCHa é construído em um modelo pré-treinado de transformador de difusão 30B. Para lidar com a disponibilidade limitada de conjuntos de dados de vídeo com anotações de fala em grande escala, o MoCHa adota uma abordagem de treinamento conjunto que integra dados rotulados por voz e texto. Essa fusão multimodal aprimora a capacidade do modelo de generalizar em diferentes estilos de personagens, padrões de movimento e contextos de diálogo. Para aumentar ainda mais a diversidade e a robustez, 20% do treinamento depende exclusivamente de dados de texto para vídeo, sem áudio adicional. O corpus de treinamento combina conjuntos de dados proprietários e públicos com níveis variados de qualidade de anotação. O desempenho do MoCHa foi avaliado usando uma combinação de métricas automáticas - avaliando a precisão da sincronização labial e a qualidade do movimento - e estudos em humanos com foco no realismo, expressividade e preferência geral do usuário. Todos os modelos são treinados usando uma resolução espacial próxima a 720 × 720, com suporte para várias proporções. Cada modelo é otimizado para produzir vídeos de 128 quadros a 24 fps, resultando em saídas de aproximadamente 5,3 segundos de duração. Os modelos requerem dois modelos de memória NVIDIA A-100 de 80 GB para inferência, dependendo do número de parâmetros (30B), sem quantização (PF32) e com um Fator de sobrecarga de 20%.
Estrutura de avaliação
Para a avaliação do modelo, eles criam uma bancada MoCHa para a tarefa de geração de personagens falantes e consistem em cinco pontuações de avaliação humana de 1 a 4.
- Qualidade de sincronização labial: mede a sincronização entre o áudio falado e os movimentos labiais do personagem.
- Naturalidade da expressão facial: avalia as expressões faciais em relação ao conteúdo do prompt e da fala fornecidos.
- Naturalidade da ação: avalia os movimentos corporais de acordo com gestos, fala e sugestões.
- Alinhamento do texto: verifique se o contexto e as ações estão alinhados com o prompt.
- Qualidade visual: pesquise artefatos, descontinuidades ou falhas.
Trabalhos relacionados
Se você quiser saber mais sobre vídeos de personagens gerados por IA, seja para avatares falantes, narrativas animadas ou sínteses de vídeo controláveis, há um crescente corpo de pesquisas que vale a pena explorar.
Magic Infinite visa produzir vídeos falados de alta fidelidade com vários tipos de personagens únicos ou múltiplos de corpo inteiro, mas com ênfase em poses faciais. Ele também usa uma transformação de difusão com mecanismos 3D de atenção total e uma estratégia de eliminação de ruído por janela deslizante e incorpora um esquema de aprendizado curricular em duas etapas, integrando áudio para sincronização labial, texto para dinâmica expressiva e imagens de referência para preservação de identidade. Usa uma máscara específica da região para identificar com precisão o locutor em cenas com vários personagens. Ele pode gerar um vídeo 540x540p de 10 segundos em 10 segundos ou 720x720p em 30 segundos em 8 GPUs H100 sem perda de qualidade.
[largura do vídeo="400" height="400" mp4=” https://blog.marvik.ai/wp-content/uploads/2025/04/id-55_BfB3AezynUF8grvgMK5Wg_5fdd297fedf64843b55d4ac76d055eeb_ElevenLabs_2024-09-24T20_03_16_Allison-millennial_pvc_s41_sb95_t2_repeat-0_emaTrue_gaudio_1.0_gtext_1.0.mp4"][/video]
Resultado do vídeo de Página do projeto MagicInfinite
Caixa concentra-se na criação de vídeos de alta fidelidade com cabeças falantes, separando o movimento da aparência por meio de uma estrutura de dois estágios: um modelo Audio-To-Motion (AtoM) para movimentos labiais sincronizados e um modelo Motion-To-Video (MToV) para produzir vídeos detalhados da cabeça. Enquanto o ModiTalker se destaca em capturar expressões faciais sutis e garantir consistência temporal, o MoCHa vai além de falantes, passando por animações de corpo inteiro e interações com vários personagens, abordando uma gama mais ampla de elementos de narrativa.
[largura do vídeo="400" height="400" mp4=” https://blog.marvik.ai/wp-content/uploads/2025/04/Video-sin-titulo-‐-Hecho-con-Clipchamp.mp4"][/video]
Resultado do vídeo de Página do projeto Teller
Converse com qualquer pessoa visa a geração em tempo real de vídeos de retratos estilizados, desde cabeças falantes até interações na parte superior do corpo. Ele enfatiza expressões faciais expressivas e movimentos corporais sincronizados, incluindo gestos com as mãos, para aprimorar os bate-papos por vídeo interativos. O ChatAnyone usa modelos hierárquicos de difusão de movimento que incorporam representações de movimento explícitas e implícitas com base em entradas de áudio. Sinais explícitos de controle manual são integrados ao gerador para produzir gestos detalhados com as mãos, aprimorando o realismo geral e a expressividade dos vídeos de retratos.
Considerações finais
Com o MoCHa, estamos testemunhando um salto significativo para tornar os personagens gerados por IA mais cinematográficos, expressivos e sensíveis ao contexto. Preenchendo a lacuna entre os modelos de difusão de texto para vídeo e a animação por voz, o MoCHa introduz um novo paradigma para contar histórias de corpo inteiro com vários personagens. Sua capacidade de sincronizar sinais de áudio complexos com expressões faciais, movimentos corporais e narrativas em nível de cena o torna uma ferramenta versátil para criadores de todos os setores. O potencial dos personagens falantes com inteligência artificial do MoCHa para revolucionar campos, do cinema aos agentes virtuais, é imenso. Ao contrário dos sistemas anteriores que se concentram no realismo facial ou nos gestos corporais básicos, o transformador de difusão unificado do MoCHa reúne essas dimensões para gerar videoclipes que não são apenas visualmente ricos, mas também emocionalmente ressonantes e contextualmente alinhados com o aviso narrativo. À medida que o conteúdo de vídeo gerado por IA se torna mais predominante, ferramentas como o MoCHa mostram que não estamos longe de ter atores digitais naturais e dinâmicos que podem ler um roteiro e executá-lo de forma convincente. No entanto, atualmente está limitado a uma duração de 5,3 segundos. O código e os pesos do MoCHA serão lançados pela Meta em breve.
Referências
Calculando a fórmula de memória da GPUMoCHa: Rumo à síntese de personagens falantes em nível cinematográficoMagicInfinite: Gerando vídeos falantes infinitos com suas palavras e vozChatAnyone: geração de vídeo de retrato estilizado em tempo real com modelo hierárquico de difusão de movimentoTeller: Animação de retrato baseada em áudio em tempo real com geração de movimento autorregressivo



.png)