.png)
Introducción a la inferencia causal: comprensión de las relaciones de causa y efecto




Introducción
¿Alguna vez se ha preguntado cómo podemos determinar las relaciones de causa y efecto entre las diferentes variables? ¡La inferencia causal es la respuesta! Es un campo fascinante que nos permite descubrir las conexiones ocultas entre los diferentes factores y predecir cómo interactuarán en el futuro. Desde las ciencias sociales hasta la medicina y más allá, es una herramienta fundamental para obtener información y tomar decisiones informadas. En un mundo en el que el aprendizaje automático es cada día más común, es importante reconocer sus limitaciones. Los modelos de aprendizaje automático solo aprenden a predecir los resultados, pero no tienen ni idea de cómo alterar la realidad para producir el resultado deseado. En esta publicación, profundizaremos en el mundo de la inferencia causal y exploraremos su poder y potencial. Analizaremos un ejemplo del mundo real en el que la inferencia causal es útil. Vamos a mencionar algunos modelos y herramientas que lo hacen posible. Tanto si eres un estudiante curioso como un analista de datos experto, ¡no querrás perderte esta emocionante aventura en el apasionante mundo de la inferencia causal!
¿Qué es la inferencia causal? ¿Por qué es importante?
La inferencia causal es un marco estadístico útil para entender la relación entre una causa y su efecto. El objetivo de este marco es identificar los efectos causales de una o más variables en un resultado. Esto debe hacerse controlando otros factores que puedan influir en el resultado.
La inferencia causal puede ayudarnos a entender las verdaderas causas de los fenómenos que observamos. Al utilizar métodos rigurosos para identificar las relaciones causales, podemos reducir la incertidumbre, mejorar la eficiencia y, en última instancia, tener un impacto positivo en el mundo que nos rodea. El grupo de grandes empresas que han utilizado la inferencia causal incluye Uber y Netflix.
Durante el resto de este blog, tendremos en cuenta el siguiente problema: supongamos que una empresa ha lanzado recientemente una nueva campaña de marketing y quiere saber si ha sido eficaz para aumentar los ingresos por ventas. En este caso, la campaña de marketing será el tratamiento y los ingresos por ventas el resultado.
Tipos de inferencia causal: experimentación versus observación
Hay dos tipos principales de inferencia causal: la experimentación y la observación. Comprender las diferencias entre estos tipos es esencial para interpretar con precisión los datos y sacar conclusiones válidas.
Experimentación
La experimentación implica dividir activamente a los sujetos en un grupo de tratamiento y uno de control. El objetivo es controlar todas las demás variables que puedan estar influyendo en el resultado además del tratamiento. En este contexto, los cambios en los resultados son exclusivamente una consecuencia del tratamiento.
En nuestro ejemplo, este tipo de inferencia causal podría resolverse mediante un ensayo controlado aleatorio (ECA). La RCT consiste en seleccionar un grupo de clientes seleccionados al azar para que participen en la campaña, mientras que otro grupo seleccionado al azar queda fuera de ella. El objetivo de la selección aleatoria es que la diferencia en el resultado entre los grupos sea una consecuencia de la campaña y no de otros factores. Sin embargo, es posible que esto no sea posible, ya que es posible que los clientes no quieran participar en la campaña y esa elección dificulte el proceso de asignación aleatoria.
Observación
Los estudios observacionales, por otro lado, implican observar la variación natural de una variable y su efecto en otra variable. A diferencia de lo que ocurre en los experimentos, las variables no se manipulan activamente y no hay control sobre las influencias externas. Los estudios observacionales son comunes en campos como la epidemiología y la economía. En esos campos, por lo general es imposible o poco ético manipular las variables en un entorno controlado.
Volviendo a nuestro ejemplo, este tipo de análisis podría llevarse a cabo siguiendo unos pocos pasos. En primer lugar, necesitaríamos recopilar datos sobre la aplicación de la campaña de marketing, los ingresos por ventas y otras variables relevantes que pueden influir en el resultado de los intereses. Estas variables podrían incluir: el tipo y el contenido de la campaña de marketing, las condiciones del mercado durante el período de estudio, las características de los clientes, como la demografía, entre otras. Luego, necesitaríamos formular un modelo que represente las relaciones causales entre las variables seleccionadas.
Por último, tendríamos que estimar el efecto del tratamiento teniendo en cuenta los posibles factores de confusión. Estos factores de confusión son las variables que influyen tanto en el resultado como en el tratamiento. Las variables de confusión influyen en el destinatario de la campaña de marketing y en los ingresos por ventas. Algunas variables de confusión en este escenario pueden incluir la situación económica, la edad y la ubicación geográfica del cliente, entre otras.
¿Cuál elegir?
En resumen, si bien la experimentación proporciona pruebas sólidas de la causalidad, los estudios observacionales también pueden proporcionar información valiosa cuando los experimentos no son factibles. Sin embargo, debido al potencial de confundir las variables, los estudios observacionales son pruebas más débiles que los estudios experimentales. En última instancia, la elección entre la experimentación y la observación depende de la pregunta de investigación, los recursos disponibles y las consideraciones éticas.
Durante el resto de este blog, nos centraremos en la inferencia causal con datos de observación, ya que a menudo está más disponible que los datos experimentales y puede proporcionar información sobre cómo interactúan las variables en entornos del mundo real.
Inferencia causal a partir de datos observacionales
Los modelos causales son una herramienta clave para comprender y probar las relaciones causales entre las variables. Un modelo causal es una representación formal de un sistema causal. Identifica las variables de interés, su relación causal y los mecanismos que las vinculan. La selección de un modelo es el primer paso para la inferencia causal.
Con el modelo elegido, lo siguiente es elegir un método. El método dependerá de los datos disponibles, del objetivo del análisis, de la hipótesis de trabajo sobre las variables observadas y de la relación entre el tratamiento y el resultado.
Una gran herramienta para analizar las relaciones causales es Gráficos acíclicos dirigidos (DAG). Este tipo de gráficos son representaciones visuales de relaciones causales. Además, cuando se observan todas las variables de confusión, se utilizan métodos como Doble ML, Aprendizaje doblemente sólido y Meta alumnos se puede utilizar para estimar el efecto causal. Sin embargo, cuando no se cumple esta condición, otros enfoques, como variables instrumentales se puede utilizar.
El último paso para la inferencia causal es evaluar la estimación del efecto causal. Mediante pruebas estadísticas y análisis de sensibilidad apropiados, podemos evaluar la solidez y confiabilidad de los resultados. A continuación presentamos un proceso completo de inferencia causal utilizando datos observacionales.
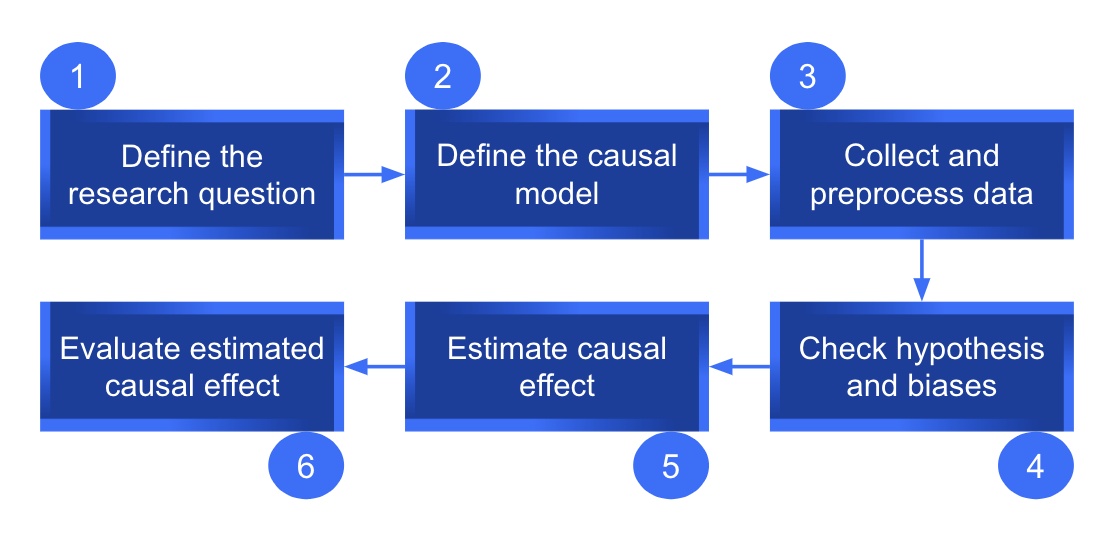
Canalización de inferencia causal utilizando datos observacionales.
¿Cuántos datos necesito?
La cantidad de datos requerida para realizar una inferencia causal confiable depende de varios factores. Algunos de ellos son: la complejidad de las relaciones causales, el número de variables de confusión, el tipo de método de análisis utilizado, el grado de heterogeneidad y variabilidad de los datos y el nivel deseado de potencia y precisión estadísticas.
En general, tener un tamaño de muestra más grande es beneficioso para la inferencia causal. Los conjuntos de datos más grandes aumentan la precisión y reducen el riesgo de sesgo en el efecto causal estimado. Sin embargo, no existe una regla estricta sobre el tamaño mínimo de la muestra para los problemas de inferencia causal. La cantidad de datos requerida puede variar según el contexto específico y la pregunta de investigación.
Herramientas de Python para la inferencia causal
Algunas herramientas relevantes para la inferencia causal con Python son:
- Haz por qué: biblioteca de Python, de Microsoft Research, que tiene como objetivo fomentar el pensamiento y el análisis causales. DoWhy proporciona una amplia variedad de algoritmos para la estimación de efectos, el aprendizaje de estructuras causales y el diagnóstico de estructuras causales. Incluye el análisis de las causas fundamentales, las intervenciones y los datos contrafácticos.
- Econ ML: paquete Python, de Microsoft Research, que aplica el poder de las técnicas de aprendizaje automático para estimar respuestas causales individualizadas a partir de datos observacionales o experimentales. Es compatible con DoWhy. Proporciona métodos de última generación para la estimación en el análisis causal.
- ML causal: paquete de Python creado por Uber que proporciona una colección de métodos de modelado de elevación e inferencia causal mediante algoritmos de aprendizaje automático.
- Inferencia causal: paquete de software que implementa varios métodos estadísticos y econométricos utilizados en el campo, conocidos como inferencia causal, evaluación de programas o análisis del efecto del tratamiento.
- Causalib: Paquete Python para el análisis causal desarrollado por IBM. El paquete proporciona una API de análisis causal unificada con la API Scikit-Learn. Por lo tanto, un modelo de aprendizaje complejo puede utilizar el método de ajuste y predicción de alto nivel.
- Impacto causal: Paquete de Python para la inferencia causal utilizando modelos de series temporales estructurales bayesianas.
Desafíos en la inferencia causal
La inferencia causal implica hacer inferencias sobre la relación causal entre las variables basándose en datos de observación. La realización de la inferencia causal plantea varios desafíos, como el sesgo de confusión, el sesgo de selección, el error de medición y la escasez de datos.
Por un lado, puede surgir un sesgo de confusión cuando la exposición y el resultado comparten una causa común no controlada. Esto sucedería en nuestro ejemplo si no pudiéramos observar la información demográfica que influye en la participación de los clientes en la campaña y en el importe de las compras que realizan.
Por otro lado, el sesgo de selección se produce cuando la selección de unidades en el grupo de tratamiento o control está relacionada con la variable de resultado. En nuestro ejemplo, este sería el caso si la empresa mostrara la campaña solo a los clientes más leales. En este caso, habría una diferencia sistemática entre los clientes que reciben el tratamiento y los que no.
El error de medición se produce cuando los valores observados de las variables no son un reflejo preciso de sus valores reales. En nuestro ejemplo, esto podría suceder si la empresa no puede identificar qué clientes estuvieron expuestos a la campaña de marketing. Por último, la escasez de datos puede dificultar la estimación precisa del efecto causal. Esto es especialmente importante cuando hay muchos factores de confusión o el efecto del tratamiento es pequeño.
Abordar estos desafíos requiere una consideración cuidadosa de la pregunta de investigación, los datos disponibles y las suposiciones en las que se basa el método elegido para la inferencia causal. Es importante reconocer estos desafíos para garantizar que la inferencia causal proporcione resultados válidos y confiables.
Reflexiones finales
La inferencia causal es una herramienta poderosa para comprender las relaciones entre las variables y predecir cómo interactuarán en el futuro. Hemos visto que tanto la experimentación como la observación se pueden utilizar para la inferencia causal. Sin embargo, los datos de observación suelen estar más fácilmente disponibles y pueden proporcionar información sobre cómo interactúan las variables en entornos del mundo real. Para identificar y cuantificar con precisión las relaciones causales en los datos de observación, es esencial utilizar métodos estadísticos apropiados y considerar cuidadosamente las posibles variables de confusión.
Afortunadamente, hay varias herramientas de Python disponibles para ayudar con el análisis de inferencia causal. Estas herramientas ofrecen una amplia variedad de algoritmos para la estimación de los efectos, el aprendizaje de las estructuras causales, el diagnóstico de las estructuras causales, el análisis de las causas fundamentales, las intervenciones y los métodos contrafácticos.
En conclusión, la inferencia causal puede ser fundamental para tomar decisiones informadas en muchas áreas. La gama de aplicaciones incluye negocios, ciencias sociales, medicina y más. Al utilizar métodos rigurosos para identificar las relaciones causales, podemos reducir la incertidumbre, mejorar la eficiencia y, en última instancia, tener un impacto positivo en el mundo que nos rodea.



.png)