.png)
Introdução à inferência causal: entendendo as relações de causa e efeito




Introdução
Você já se perguntou como podemos determinar as relações de causa e efeito entre diferentes variáveis? A inferência causal é a resposta! É um campo fascinante que nos permite descobrir as conexões ocultas entre diferentes fatores e prever como eles interagirão no futuro. Das ciências sociais à medicina e muito mais, é uma ferramenta essencial para desbloquear ideias e tomar decisões informadas. Em um mundo onde o aprendizado de máquina é mais comum a cada dia, é importante reconhecer suas limitações. Os modelos de aprendizado de máquina só aprendem a prever resultados, mas não têm ideia de como alterar a realidade para produzir o resultado desejado. Neste post, vamos nos aprofundar no mundo da inferência causal, explorando seu poder e potencial. Vamos dar uma olhada em um exemplo do mundo real em que a inferência causal é útil. Vamos mencionar alguns modelos e ferramentas que tornam tudo isso possível. Seja você um aluno curioso ou um analista de dados especializado, não vai querer perder essa aventura emocionante no empolgante mundo da inferência causal!
O que é inferência causal? Por que isso é importante?
A inferência causal é uma estrutura estatística útil para entender a relação entre uma causa e seu efeito. O objetivo dessa estrutura é identificar os efeitos causais de uma ou mais variáveis em um resultado. Isso deve ser feito enquanto se controla outros fatores que podem influenciar o resultado.
A inferência causal pode nos ajudar a entender as verdadeiras causas dos fenômenos que observamos. Ao usar métodos rigorosos para identificar relações causais, podemos reduzir a incerteza, melhorar a eficiência e, por fim, causar um impacto positivo no mundo ao nosso redor. O grupo de grandes empresas que usaram a inferência causal inclui Uber e Netflix.
No restante deste blog, teremos em mente o seguinte problema: suponha que uma empresa tenha lançado recentemente uma nova campanha de marketing e queira saber se ela foi eficaz no aumento da receita de vendas. Nesse caso, a campanha de marketing será o tratamento e a receita de vendas o resultado.
Tipos de inferência causal: experimentação versus observação
Existem dois tipos principais de inferência causal: experimentação e observação. Compreender as diferenças entre esses tipos é essencial para interpretar os dados com precisão e tirar conclusões válidas.
Experimentação
A experimentação envolve a divisão ativa dos sujeitos em um grupo de tratamento e um grupo de controle. O objetivo é controlar todas as outras variáveis que possam estar influenciando o resultado, além do tratamento. Nesse cenário, as mudanças nos resultados são exclusivamente uma consequência do tratamento.
Em nosso exemplo, esse tipo de inferência causal poderia ser resolvido por um ensaio clínico randomizado (RCT). O RCT envolve a escolha aleatória de um grupo de clientes para participar da campanha, enquanto outro grupo selecionado aleatoriamente é deixado de fora. O objetivo de randomizar a seleção é que a diferença no resultado entre os grupos seja consequência da campanha e não de outros fatores. No entanto, isso pode não ser possível, pois os clientes podem não querer participar da campanha e essa escolha dificulta o processo de randomização.
Observação
Os estudos observacionais, por outro lado, envolvem observar a variação natural em uma variável e seu efeito em outra variável. Diferentemente dos experimentos, as variáveis não são manipuladas ativamente e não há controle sobre as influências externas. Estudos observacionais são comuns em áreas como epidemiologia e economia. Nesses campos, geralmente é impossível ou antiético manipular variáveis em um ambiente controlado.
Voltando ao nosso exemplo, esse tipo de análise pode ser realizado seguindo algumas etapas. Primeiro, precisaríamos coletar dados sobre a aplicação da campanha de marketing, a receita de vendas e outras variáveis relevantes que possam influenciar o resultado de interesse. Essas variáveis podem incluir: o tipo e o conteúdo da campanha de marketing, as condições do mercado durante o período do estudo, as características dos clientes, como dados demográficos, entre outras. Em seguida, precisaríamos formular um modelo que represente as relações causais entre as variáveis selecionadas.
Finalmente, precisaríamos estimar o efeito do tratamento e, ao mesmo tempo, considerar possíveis fatores de confusão. Esses fatores de confusão são as variáveis que influenciam tanto o resultado quanto o tratamento. Variáveis confusas afetam a quem a campanha de marketing foi destinada e a receita de vendas. Algumas variáveis de confusão nesse cenário podem incluir a condição econômica, idade e localização geográfica do cliente, entre outras.
Qual escolher?
Resumindo, embora a experimentação forneça fortes evidências de causalidade, os estudos observacionais também podem fornecer informações valiosas quando os experimentos não são viáveis. No entanto, devido ao potencial de confundir variáveis, os estudos observacionais são evidências mais fracas do que os estudos experimentais. Em última análise, a escolha entre experimentação e observação depende da questão da pesquisa, dos recursos disponíveis e de considerações éticas.
No restante deste blog, nos concentraremos na inferência causal com dados observacionais, pois geralmente ela está mais prontamente disponível do que dados experimentais e pode fornecer informações sobre como as variáveis interagem em ambientes do mundo real.
Inferência causal a partir de dados observacionais
Os modelos causais são uma ferramenta fundamental para entender e testar relações causais entre variáveis. Um modelo causal é uma representação formal de um sistema causal. Ele identifica as variáveis de interesse, sua relação causal e os mecanismos que as unem. A seleção de um modelo é a primeira etapa para a inferência causal.
Com o modelo escolhido, o seguinte é escolher um método. O método dependerá dos dados disponíveis, do objetivo da análise, da hipótese de trabalho sobre as variáveis observadas e da relação entre tratamento e resultado.
Uma ótima ferramenta para analisar relações causais é Gráficos acíclicos direcionados (DAGs). Esses tipos de gráfico são representações visuais de relações causais. Além disso, quando todas as variáveis de confusão são observadas, métodos como ML duplo, Aprendizado duplamente robusto e Meta-aprendizes pode ser usado para estimar o efeito causal. No entanto, quando essa condição não é atendida, outras abordagens, como variáveis instrumentais pode ser usado.
A etapa final da inferência causal é avaliar a estimativa do efeito causal. Usando testes estatísticos apropriados e análises de sensibilidade, podemos avaliar a robustez e a confiabilidade dos resultados. Abaixo, apresentamos um pipeline completo de inferência causal usando dados observacionais.
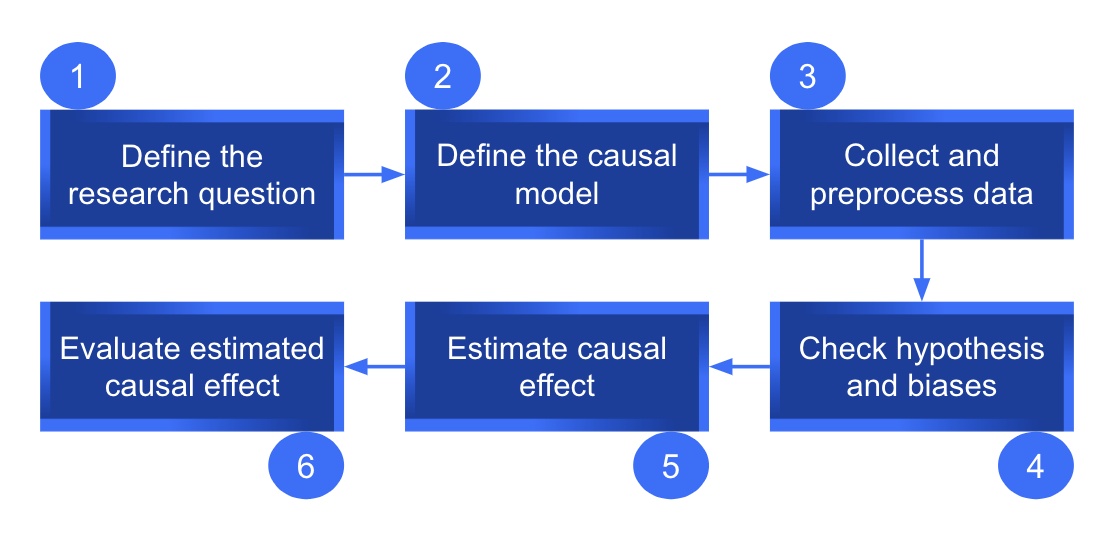
Pipeline de inferência causal usando dados observacionais.
De quantos dados eu preciso?
A quantidade de dados necessária para realizar uma inferência causal confiável depende de vários fatores. Alguns deles são: a complexidade das relações causais, o número de variáveis de confusão, o tipo de método de análise usado, o grau de heterogeneidade e variabilidade dos dados e o nível desejado de poder e precisão estatísticos.
Em geral, ter uma amostra maior é benéfico para a inferência causal. Conjuntos de dados maiores aumentam a precisão e reduzem o risco de viés no efeito causal estimado. No entanto, não existe uma regra estrita para o tamanho mínimo da amostra para problemas de inferência causal. A quantidade de dados necessários pode variar dependendo do contexto específico e da questão da pesquisa.
Ferramentas Python para inferência causal
Algumas ferramentas relevantes para inferência causal com Python são:
- Faça por quê: Biblioteca Python, da Microsoft Research, que visa estimular o pensamento e a análise causais. O DoWhy fornece uma ampla variedade de algoritmos para estimativa de efeitos, aprendizado de estruturas causais e diagnóstico de estruturas causais. Inclui análise de causa raiz, intervenções e contrafactuais.
- Econ ML: pacote Python, da Microsoft Research, que aplica o poder das técnicas de aprendizado de máquina para estimar respostas causais individualizadas a partir de dados observacionais ou experimentais. É compatível com DoWhy. Fornece métodos de última geração para estimativa na análise causal.
- ML causal: pacote Python criado pela Uber que fornece uma coleção de métodos de modelagem ascendente e inferência causal usando algoritmos de aprendizado de máquina.
- Inferência causal: Pacote de software que implementa vários métodos estatísticos e econométricos usados no campo, também conhecidos como inferência causal, avaliação de programas ou análise de efeitos de tratamento.
- Lib causal: pacote Python para análise causal desenvolvido pela IBM. O pacote fornece uma API de análise causal unificada com a API Scikit-Learn. Portanto, um modelo de aprendizado complexo pode usar o método de ajuste e previsão de alto nível.
- Impacto causal: Pacote Python para inferência causal usando modelos estruturais bayesianos de séries temporais.
Desafios na inferência causal
A inferência causal envolve fazer inferências sobre a relação causal entre variáveis com base em dados observacionais. Existem vários desafios na realização de inferência causal, incluindo viés de confusão, viés de seleção, erro de medição e dados limitados.
Por um lado, o viés de confusão pode surgir quando a exposição e o resultado compartilham uma causa comum não controlada. Isso aconteceria em nosso exemplo se não pudéssemos observar as informações demográficas que afetassem a submissão ou não dos clientes à campanha e a quantidade de compras que eles fazem.
Por outro lado, o viés de seleção ocorre quando a seleção das unidades do grupo de tratamento ou controle está relacionada à variável de resultado. Em nosso exemplo, esse seria o caso se a empresa mostrasse a campanha apenas para os clientes mais fiéis. Aqui, haveria uma diferença sistemática entre os clientes que recebem o tratamento e aqueles que não recebem.
O erro de medição ocorre quando os valores observados das variáveis não são um reflexo preciso de seus valores reais. Em nosso exemplo, isso pode acontecer se a empresa não conseguir identificar quais clientes foram expostos à campanha de marketing. Finalmente, dados limitados podem dificultar a estimativa do efeito causal com precisão. Isso é especialmente importante quando há muitos fatores de confusão ou o efeito do tratamento é pequeno.
Enfrentar esses desafios requer uma consideração cuidadosa da questão da pesquisa, dos dados disponíveis e das suposições subjacentes ao método escolhido para inferência causal. É importante reconhecer esses desafios para garantir que a inferência causal forneça resultados válidos e confiáveis.
Considerações finais
A inferência causal é uma ferramenta poderosa para entender as relações entre variáveis e prever como elas interagirão no futuro. Vimos que tanto a experimentação quanto a observação podem ser usadas para inferência causal. No entanto, os dados observacionais geralmente estão mais facilmente disponíveis e podem fornecer informações sobre como as variáveis interagem em ambientes do mundo real. Para identificar e quantificar com precisão as relações causais em dados observacionais, é essencial usar métodos estatísticos apropriados e considerar cuidadosamente as possíveis variáveis de confusão.
Felizmente, existem várias ferramentas Python disponíveis para ajudar na análise de inferência causal. Essas ferramentas oferecem uma ampla variedade de algoritmos para estimativa de efeitos, aprendizado de estrutura causal, diagnóstico de estruturas causais, análise de causa raiz, intervenções e contrafactuais.
Em conclusão, a inferência causal pode ser fundamental para tomar decisões informadas em muitas áreas. A variedade de aplicações inclui negócios, ciências sociais, medicina e muito mais. Ao usar métodos rigorosos para identificar relações causais, podemos reduzir a incerteza, melhorar a eficiência e, por fim, causar um impacto positivo no mundo ao nosso redor.



.png)