.png)
Primeros pasos para implementar una arquitectura de múltiples cabezales




Introducción
En la vida, nos enfrentamos constantemente a varias situaciones al mismo tiempo. Esto es algo natural para nosotros, y la mayoría de las veces ni siquiera somos conscientes del hecho de que lo estamos haciendo. Por ejemplo, mientras conducimos un automóvil, debemos ser conscientes de diferentes cosas y tomar decisiones en tiempo real en consecuencia: detectar a los peatones que cruzan la calle, hacer un seguimiento de las maniobras de otros automóviles, detectar las marcas de los carriles, leer las señales de tráfico, entre otras cosas.
Ahora, ¿cómo podemos traducir esto en una solución de aprendizaje profundo? ¿Necesitamos desarrollar modelos separados para abordar cada tarea? ¿O podemos beneficiarnos del hecho de que haya un punto de partida común? Este es uno de los principales temas a los que se hizo referencia durante Día de la IA de Tesla 2021 charla, lo que alentó nuestra investigación. En esta conferencia magistral, Tesla presentó por primera vez el concepto de utilizar una arquitectura multicabezal (denominada Hydra Net) aplicada a la conducción autónoma. A lo largo de nuestra investigación, nos dimos cuenta de que este novedoso enfoque de aprendizaje profundo multitarea aún no se ha aprovechado al máximo y que no se ha hecho mucho trabajo en este aspecto. De hecho, la mayoría de las implementaciones se centran en tareas individuales específicas en lugar de abordar el problema en su conjunto.
El objetivo de esta publicación es presentar un enfoque para recrear completamente el concepto de redes multicabezal introducido por Tesla y apreciar sus beneficios. Nos centraremos en resolver dos tareas específicas: segmentación de carriles y detección de objetos en escenarios de conducción. Consideramos que ambas funciones son clave para implementar con éxito una solución de conducción autónoma. Segmentación de carriles implica detectar todas las áreas posibles para conducir. Requiere que el modelo pueda detectar los carriles libres, las vías de conducción opuestas, las aceras, las entradas a los estacionamientos, entre otros.

Imágenes obtenidas mediante el modelo de segmentación de UNet
Por otro lado, detección de objetos implica poder detectar todos los objetos visibles y clasificarlos en consecuencia. En términos de conducción, esto generalmente incluye la detección de otros automóviles, señales de tráfico, semáforos, peatones, entre otros. El hecho de que los objetos puedan tener diferentes tamaños y formas, y la posibilidad de una oclusión parcial constituyen algunos de los desafíos de esta tarea específica.

Imagen obtenida con el modelo YoloV7
Ambos conceptos, la segmentación de carriles y la detección de objetos, se han estudiado en profundidad por separado durante los últimos años. Las soluciones más comunes implican el uso de Máscara R-CNN arquitectura para la segmentación de imágenes y YOLO (en sus diferentes sabores) para la detección de objetos. Sin embargo, estas tareas no suelen abordarse de forma conjunta. En cuanto a las soluciones de conducción autónoma, las capacidades informáticas suelen ser limitadas, ya que se requiere que el modelo funcione dentro del vehículo. Esta deficiencia hace que la idea de utilizar el modelo en su conjunto sea aún más tentadora.
Arquitectura multicabezal
UN red multicabezal suele constar de los siguientes módulos:
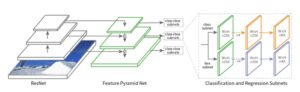
- Columna vertebral: Es una red de extracción de características común que, como su nombre lo indica, se utiliza para extraer información relevante de los datos de entrada y generar su mapa de características correspondiente.
- Cuello: Ubicado entre la columna vertebral y las cabezas, este módulo se usa generalmente para extraer más información y características más elaboradas mediante técnicas piramidales.
- Cabeza: Este tipo de módulo se implementa para resolver tareas más específicas utilizando los mapas de características generados por los módulos de columna vertebral y cuello.
El siguiente diagrama le brinda una mejor comprensión de la estructura general de una arquitectura típica de red de múltiples cabezales.
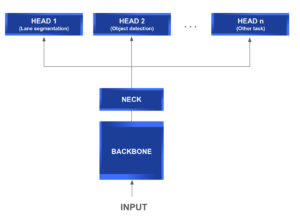
Lo que hace que este tipo de arquitectura sea tan atractiva es su capacidad de uso compartido de funciones entre las diferentes cabezas. Esto implica una reducción directa de las tareas repetitivas, los cálculos de convolución, la memoria y la cantidad de parámetros utilizados. Es especialmente eficiente a la hora de realizar pruebas.
En términos de conducción autónoma, los cabezales están diseñados para diferentes propósitos, como la segmentación de carriles, la detección y el seguimiento de señales de tráfico, entre muchos otros. Pero, por si sirve de algo, este concepto puede abstraerse y aplicarse a cualquier otro escenario que necesite abordar diferentes tareas simultáneamente y pueda beneficiarse de compartir una estructura básica común.
El resto de este post está organizado de la siguiente manera. En primer lugar, presentaremos la arquitectura de nuestro modelo, profundizando en cada uno de sus componentes, con un enfoque especial en la interconexión de cada bloque. A continuación, presentaremos algunos de los resultados obtenidos en esta prueba de concepto, que resultó ser muy prometedora. Por último, analizaremos los posibles próximos pasos y mejoras.

Imagen obtenida con nuestro modelo de cabezales múltiples
Nuestro modelo
Como mencionamos anteriormente, nuestro objetivo principal era desarrollar un modelo de cabezales múltiples capaz de realizar dos tareas: la detección de objetos y la segmentación de carriles.
En lugar de lanzarnos directamente a los modelos actuales de última generación para cada tema y descubrir cómo unir su compleja arquitectura, optamos por dar unos pasos atrás. Nuestro enfoque se centra en mantener las cosas lo más simples posible al principio, para obtener una comprensión completa de las interconexiones de la arquitectura.
Nuestra columna vertebral consiste en un ResNet 34 red que luego se conecta a un clásico Característica: Pyramid Network bloque (FPN). Las diferentes salidas de la pirámide se conectan luego a los cabezales de segmentación y detección de objetos, que se basan en el UNet y RetinaNet modelos respectivamente. Ahora, revisemos cómo se construyeron estos componentes, ¿de acuerdo?
Columna vertebral
El módulo troncal consiste en una red de extracción de características. Con este fin, ResNet parecía ser un buen punto de partida y se podía conectar fácilmente a una vainilla FPN red, sin añadir más complejidades al modelo.
ResNet
Las ResNet son un tipo de red neuronal convolucional capaz de aumentar la profundidad y, al mismo tiempo, abordar muy bien el problema de la desaparición del gradiente. La idea central detrás de esto es aplicar conexiones de acceso directo que omitan una o más capas.
Las ResNet se componen de una serie de bloques residuales, también denominados ResBlocks. Cada uno ResBlock consta de dos capas convolucionales de 3x3, cada una seguida de una capa de normalización por lotes y una función de activación de ReLU. A continuación, se utiliza una conexión de omisión para añadir la entrada a la salida del bloque. Se utilizan dos tipos de bloques, dependiendo de si las dimensiones de entrada y salida son las mismas o no:
- Bloque de identidad: Cuando las dimensiones de entrada y salida son las mismas, la conexión de omisión une la entrada directamente a la salida del ResBlock, y los suma. No se necesitan más modificaciones.
- Bloque convolucional: Cuando las dimensiones de entrada y salida no coinciden, se aplica una capa convolucional de 1x1 seguida de una capa de normalización por lotes en la ruta de conexión de omisión.
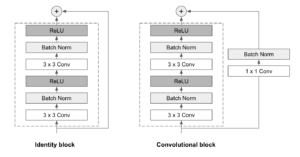
Las ResNets pueden tener tamaños y capas variables. En nuestra implementación, hemos optado por utilizar un ResNet 34 arquitectura (34 capas), que parecía ser la opción más acertada para mantener las cosas lo más simples posible.
FPN
Las redes de pirámides de características (FPN) están diseñadas para ayudar a detectar objetos en diferentes escalas, generando múltiples capas de mapas de características. Se compone de dos vías: de abajo hacia arriba y de arriba hacia abajo.
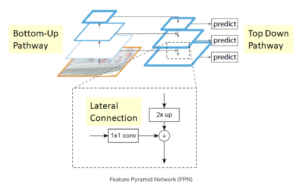
El ruta de abajo hacia arriba es la red convolucional habitual para la extracción de características. A medida que aumentamos, la resolución espacial disminuye pero el valor semántico aumenta. En el artículo original, esto se construyó usando una ResNet.
El camino de arriba hacia abajo construye capas de mayor resolución a partir de una capa rica en semántica. Se añaden conexiones laterales entre las capas reconstruidas y los mapas de características correspondientes para ayudar al detector a predecir mejor la ubicación. También actúa como una conexión de salto para facilitar el entrenamiento.
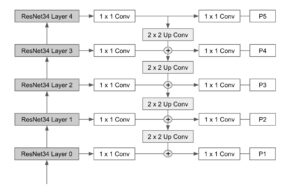
El siguiente diagrama muestra la arquitectura troncal final que combina los niveles de ResNet y FPN.
Jefe de segmentación
Alineados con el desarrollo de un enfoque simple, decidimos basar el cabezal de segmentación en un enfoque clásico UNet modelo que ha demostrado ser útil para este tipo de problemas.
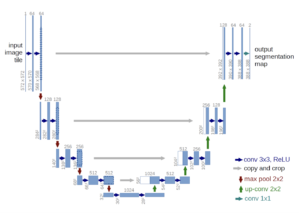
La arquitectura de UNet es totalmente convolucional y consiste básicamente en tres partes:
- Ruta de contratación (codificador): Consta de 4 bloques. Cada uno aplica dos veces una combinación de convolución 3x3 más ReLU («doble convolución»), seguida de una combinación MaxPool de 2x2 con stride 2 para reducir la resolución. En cada paso de reducción de resolución, duplicamos el número de canales de funciones.
- Cuello de botella: Es una combinación de 3x3 convolution + ReLU repetida dos veces. Actúa como un puente entre las rutas del codificador y del decodificador.
- Ruta expansiva (decodificador): Consta de 4 bloques. Cada uno aplica un muestreo ascendente del mapa de características seguido de una convolución de 2x2 («convolución hacia arriba»), seguida de una concatenación con el mapa de características recortado correspondientemente de la ruta de contracción, y dos combinaciones de convolución más ReLU de 3x3 («doble convolución»). El paso de concatenación ayuda a evitar la pérdida de información espacial debido a la reducción del muestreo. En la capa final, se usa una convolución de 1x1 para asignar cada vector de características de 64 componentes al número deseado de clases.
Cabezal de detección
En cuanto a los detectores de objetos de una etapa, el modelo RetinaNet ha demostrado funcionar muy bien en objetos pequeños. Además, en esencia, su columna vertebral consiste en una FPN construida sobre una ResNet que se alinea perfectamente con la nuestra. Por lo tanto, parecía la mejor opción para construir nuestro cabezal de detección.
RetinaNet fue presentada por el equipo de investigación de inteligencia artificial de Facebook en 2017. Su diseño tenía como objetivo abordar los problemas de detección de objetos pequeños y densos mediante la introducción de dos mejoras en los modelos clásicos de detección de objetos:
- Incorporar Feature Pyramid Networks (FPN) en la red troncal.
- Uso de la función de pérdida focal para la pérdida de subred de clasificación.
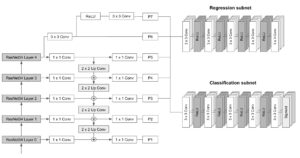
La arquitectura de RetinaNet consiste en lo siguiente:
- Columna vertebral: Una red troncal totalmente convolucional responsable de calcular el mapa de características en toda la imagen a diferentes escalas. En el caso de RetinaNet, la FPN se basa en la arquitectura ResNet. La pirámide tiene 5 niveles, del P3 al P7, que abarcan las siguientes resoluciones: [23, 24, 25, 26, 27].
- Subred de clasificación: Una red totalmente convolucional conectada a cada nivel de pirámide que tiene como objetivo predecir la probabilidad de que un objeto esté presente en cada ubicación espacial para cada caja de anclaje y clase de objeto. Consiste en aplicar cuatro capas convolucionales de 3 x 3 con M filtros, seguidas de activaciones de ReLU, donde M es el número de canales en cada nivel de pirámide. Por último, aplica otra capa convolucional de 3x3 con filtros CxA, donde C es el número de clases objetivo y A el número de cajas de anclaje (9 por defecto), seguidas de las activaciones sigmoideas que se utilizan para obtener la puntuación final de la clasificación.
- Subred de regresión: Una red totalmente convolucional conectada a cada nivel de pirámide que se ejecuta en paralelo a la subred de clasificación. Su propósito es hacer retroceder el desfase de cada caja de anclaje a un objeto cercano (si existe). El diseño de la subred de regresión de cajas es prácticamente idéntico al de la red de clasificación. La única diferencia es que la última convolucional de 3 x 3 tiene 4 filtros A, siendo A el número de cajas de anclaje (9 por defecto). En otras palabras, para cada una de las cajas de anclaje A por ubicación espacial, se predicen 4 salidas, lo que representa el desfase relativo entre el ancla y la caja de referencia terrestre).
El siguiente esquema ilustra la arquitectura de RetinaNet y las interconexiones entre sus diferentes módulos:
Cajas de anclaje
RetinaNet utiliza cajas de anclaje con tamaños fijos antes de predecir la caja delimitadora real de cada objeto. Los anclajes tienen áreas que van desde 32x32 a 512x512 en todos los niveles de la pirámide (P3 a P7). Además, para mejorar la cobertura, se han incorporado al diseño tres proporciones de aspecto [1:2, 1:1, 2:1] y escalas [20, 21/3, 22/3], lo que da como resultado un total de 9 anclajes por nivel y ubicación espacial. Con esta configuración, los anclajes logran cubrir el rango de escala de 32 a 813 píxeles en relación con la imagen de entrada.
Para cada ancla, se calcula una puntuación de intersección sobre unión (IoU). Si la puntuación del pagaré es mayor o igual a 0,5, el ancla se asigna a un objeto de verdad fundamental y se tiene en cuenta en la función de pérdida. Si el pagaré está entre 0 y 0,4, se considera como fondo. Por último, si la puntuación se encuentra entre 0,4 y 0,5, se ignora.
En cada capa piramidal se generan miles de cajas de anclaje (9 por cada ubicación espacial de la imagen), pero solo unas pocas contendrán objetos. Por lo tanto, esta gran cantidad de negativos fáciles puede desbordar el modelo Pérdida focal se introdujo para evitar esto. Básicamente, Pérdida focal reconfigura la pérdida de entropía cruzada (CE) clásica al incorporar un factor de escalado dinámico que decae a cero a medida que aumenta la confianza en la clase correcta. En otras palabras, este factor de escalado minimiza automáticamente la contribución de los ejemplos fáciles, como los negativos fáciles, y se centra rápidamente en mejorar los negativos difíciles.
Algunas cosas a tener en cuenta...
Usos de RetinaNet fija tamaños de anclaje que pueden necesitar ajustarse en consecuencia. Los valores de tamaño predeterminados son [32, 54, 128, 256, 512], es decir, el modelo no detectará objetos de menos de 32 por 32 píxeles. Teniendo en cuenta este factor, para lograr un diseño adecuado de las cajas de anclaje, es una buena práctica revisar los siguientes puntos:
- Identifique los objetos más pequeños y más grandes que se van a detectar.
- Identifica las diferentes formas que puede adoptar una caja, es decir, las posibles proporciones entre la altura y el ancho de una caja.
Juntando todo
Ahora que hemos revisado cada componente por separado, en esta sección te guiaremos a través del proceso de conectar todas las piezas. Como hemos presentado anteriormente, nuestra columna vertebral es la misma que la de RetinaNet, por lo que solo tendremos que centrarnos en cómo conectar el cabezal de segmentación con nuestra red troncal.
Al observar de cerca la arquitectura de UNet, uno puede darse cuenta de que la ruta del codificador puede sustituirse fácilmente por nuestra red troncal ResNet + FPN. Para ello, las capas P1 a P5 de la red piramidal se concatenan con las entradas de los bloques descodificadores de Unet.
El siguiente diagrama pretende describir la arquitectura final del modelo.
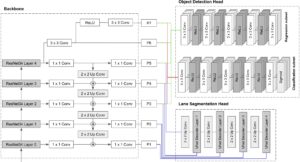
Para entrenar el modelo final, se debe definir una función de pérdida adecuada. Hemos abordado este requisito realizando una suma ponderada que combina las pérdidas de cada cabezal: entropía cruzada para el cabezal de segmentación y pérdida focal para el cabezal de detección de objetos.
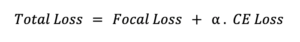
Nuestros resultados
Hemos entrenado nuestro modelo utilizando el Conjunto de datos de Berkeley Deep Drive (BDD100k) y pudimos obtener resultados muy alentadores a pesar de haber utilizado solo 5 épocas para el entrenamiento. Algunos de los resultados obtenidos en el set de prueba se muestran en las imágenes de abajo.
Como puede ver, el modelo no solo logra la segmentación de los carriles transitables, sino que también logra detectar diferentes objetos de diferentes tamaños y clases presentes en las imágenes.




Para validar aún más el rendimiento del modelo, también lo hemos utilizado en algunas imágenes de las calles de la ciudad de Montevideo, obteniendo resultados asombrosos. Como estas imágenes están fuera del conjunto de datos BDD100k, hemos demostrado que nuestro modelo también es capaz de generalizar muy bien.



Conclusiones y próximos pasos
¡Lo logramos! Pudimos implementar con éxito un modelo simple pero potente de dos cabezas para la detección de objetos y la segmentación de imágenes. Los resultados obtenidos con este enfoque han demostrado ser bastante prometedores, lo que reafirma las ventajas de implementar el enfoque multicabezal. Sin embargo, la simplicidad utilizada en la arquitectura nos ha permitido comprender mejor la solución en su conjunto.
En cuanto a los posibles pasos a seguir, algunos de los siguientes podrían ser buenos puntos de partida:
- Mejorar la selección de anclajes en RetinaNet mediante la implementación de un algoritmo de agrupamiento, por ejemplo, k-means, para determinar los tamaños de anclaje apropiados en función de los datos de entrenamiento.
- Sumérjase en el ajuste preciso de la ponderación de las pérdidas.
- Sustituir nuestra versión estándar de FPN por una FPN extendida. De esta forma, podemos incorporar el mapa de características del nivel P2 de la pirámide sin poner en peligro el rendimiento en tiempo real.
- Sustituya ResNet34 por versiones más profundas, como ResNet101 o ResNet 50, para lograr una mayor precisión.
Esperamos que hayas disfrutado de este post. ¡Estén atentos para más información!
Referencias:
- Aprendizaje residual profundo para el reconocimiento de imágenes
- Cuenta con redes piramidales para la detección de objetos
- U-Net: redes convolucionales para la segmentación de imágenes biomédicas
- Anchor Boxes: la clave para una detección de objetos de calidad
- Pérdida focal para la detección de objetos densos
- Conjunto de datos de Berkeley Deep Drive (BDD100k)



.png)