.png)
Primeiros passos na implementação de uma arquitetura com várias cabeças




Intro
Na vida, estamos constantemente lidando com várias situações ao mesmo tempo. Isso é natural para nós e, na maioria das vezes, nem temos consciência do fato de que estamos fazendo isso. Por exemplo, ao dirigir um carro, certamente devemos estar cientes de coisas diferentes e tomar decisões em tempo real: detectar pedestres atravessando a rua, acompanhar as manobras de outros carros, detectar marcações de faixas, ler sinais de trânsito, entre outras coisas.
Agora, como podemos traduzir isso em uma solução de aprendizado profundo? Precisamos desenvolver modelos separados para lidar com cada tarefa? Ou podemos nos beneficiar do fato de haver um ponto de partida comum? Este é um dos principais tópicos mencionados durante Dia da IA da Tesla em 2021 conversa, o que incentivou nossa pesquisa. Nesta palestra, a Tesla apresentou pela primeira vez o conceito de usar uma arquitetura de várias cabeças (chamada Hydra Net) aplicada à direção autônoma. Ao longo de nossa investigação, percebemos que essa nova abordagem de aprendizado profundo multitarefa ainda não foi amplamente explorada e que não há muito trabalho feito nesse aspecto. Na verdade, a maioria das implementações se concentra em tarefas únicas específicas, em vez de abordar o problema como um todo.
O objetivo desta postagem é apresentar uma abordagem para recriar totalmente o conceito de redes com várias cabeças introduzido pela Tesla e apreciar seus benefícios. Vamos nos concentrar em resolver duas tarefas específicas: segmentação de faixa e detecção de objetos em cenários de condução. Consideramos que ambas as funções são fundamentais para a implantação bem-sucedida de uma solução de direção autônoma. Segmentação de faixa implica detectar todas as áreas possíveis de dirigir. Exige que o modelo seja capaz de detectar faixas livres, vias de condução opostas, calçadas, entradas de estacionamento, entre outras.

Imagens obtidas usando o modelo de segmentação UNet
Por outro lado, detecção de objetos envolve a capacidade de detectar todos os objetos visíveis e classificá-los adequadamente. Em termos de direção, isso geralmente inclui a detecção de outros carros, sinais de trânsito, semáforos, pedestres, entre outros. O fato de os objetos poderem ter tamanhos e formas variados e a possibilidade de oclusão parcial compõem alguns dos desafios dessa tarefa específica.

Imagem obtida usando o modelo YOLOv7
Ambos os conceitos, segmentação de faixa e detecção de objetos, foram profundamente estudados separadamente nos últimos anos. As soluções mais comuns envolvem o uso de um Máscara R-CNN arquitetura para segmentação de imagens e YOLO (em seus diferentes sabores) para detecção de objetos. No entanto, essas tarefas geralmente não são tratadas em conjunto. Em termos de soluções de direção autônoma, as capacidades de computação geralmente são limitadas, pois o modelo é necessário para funcionar dentro do veículo. Essa lacuna torna a ideia de executar o modelo como um todo ainda mais tentadora.
Arquitetura com várias cabeças
UM rede com várias cabeças geralmente consiste nos seguintes módulos:
- Espinha dorsal: É uma rede comum de extração de recursos que, como o próprio nome indica, é usada para extrair informações relevantes dos dados de entrada e gerar seu mapa de recursos correspondente.
- Pescoço: Localizado entre a espinha dorsal e as cabeças, esse módulo geralmente é usado para extrair mais informações e características mais elaboradas usando técnicas piramidais.
- Cabeça: Esse tipo de módulo é implantado para resolver tarefas mais específicas usando os mapas de recursos gerados pelos módulos de backbone e neck.
O diagrama a seguir fornece uma compreensão mais aprofundada da estrutura geral de uma arquitetura típica de rede com várias cabeças.
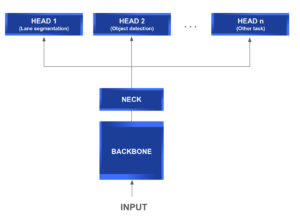
O que torna esse tipo de arquitetura tão atraente é sua capacidade de compartilhamento de recursos entre as diferentes cabeças. Isso implica uma redução direta nas tarefas repetitivas, nos cálculos de convolução, na memória e no número de parâmetros usados. É especialmente eficiente na hora do teste.
Em termos de direção autônoma, os cabeçotes são projetados para diferentes propósitos, como segmentação de faixa, detecção e rastreamento de sinais de trânsito, entre muitos outros. Mas, se vale de alguma coisa, esse conceito pode ser abstraído e aplicado a qualquer outro cenário que precise lidar com diferentes tarefas simultaneamente e possa se beneficiar do compartilhamento de uma espinha dorsal comum.
O restante desta postagem está organizado da seguinte forma. Primeiro, apresentaremos a arquitetura do nosso modelo, mergulhando profundamente em cada um de seus componentes, com foco especial na interconexão de cada bloco. A seguir, apresentaremos alguns dos resultados obtidos nessa prova de conceito, que se mostrou muito promissora. Por fim, discutiremos as possíveis próximas etapas e melhorias.

Imagem obtida usando nosso modelo Multi-Head
Nosso modelo
Como mencionamos anteriormente, nosso principal objetivo era desenvolver um modelo com várias cabeças capaz de realizar duas tarefas: detecção de objetos e segmentação de faixa.
Em vez de mergulhar diretamente nos modelos atuais de última geração para cada assunto e descobrir como unir sua arquitetura complexa, optamos por dar alguns passos atrás. Nossa abordagem se concentra em manter as coisas o mais simples possível no início, para obter uma compreensão completa das interconexões da arquitetura.
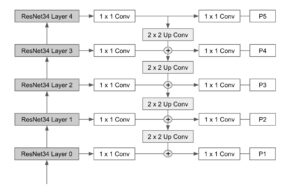
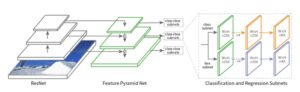
Nossa espinha dorsal consiste em um ResNet 34 rede que é então conectada a uma rede clássica Características: Pyramid Network Bloco (FPN). As diferentes saídas da pirâmide são então conectadas às cabeças de segmentação e detecção de objetos, que são baseadas no UNet e Retina Net modelos, respectivamente. Agora, vamos revisar como esses componentes foram construídos, certo?
Espinha dorsal
O módulo de backbone consiste em uma rede de extração de recursos. Para este fim, ResNet parecia ser um bom ponto de partida e poderia ser facilmente conectado a uma baunilha FPN rede, sem adicionar mais complexidades ao modelo.
ResNet
As ResNets são um tipo de rede neural convolucional capaz de aumentar a profundidade e, ao mesmo tempo, lidar muito bem com o problema do gradiente que desaparece. A ideia central por trás disso é aplicar conexões de atalho que pulem uma ou mais camadas.
As ResNets são compostas por uma série de blocos residuais, também chamados de ResBlocks. Cada Bloco de Res consiste em duas camadas convolucionais 3x3, cada uma seguida por uma camada de normalização em lote e uma função de ativação ReLU. Uma conexão de salto é então usada para adicionar a entrada à saída do bloco. Dois tipos de bloco são usados, dependendo se as dimensões de entrada e saída são iguais ou não:
- Bloco de identidade: Quando as dimensões de entrada e saída são iguais, a conexão de salto une a entrada diretamente à saída do Bloco de Res, e os soma. Nenhuma modificação adicional é necessária.
- Bloco convolucional: Quando as dimensões de entrada e saída não coincidem, uma camada convolucional 1x1 seguida por uma camada de normalização em lote é aplicada no caminho de conexão de salto.
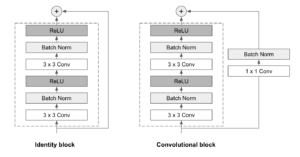
As ResNets podem ter tamanhos e camadas variáveis. Em nossa implementação, optamos por usar um ResNet 34 Arquitetura (34 camadas), que parecia ser a escolha mais sábia para manter as coisas o mais simples possível.
FPN
As Feature Pyramid Networks (FPN) têm como objetivo ajudar a detectar objetos em diferentes escalas, gerando várias camadas de mapas de feições. É composto por duas vias: de baixo para cima e de cima para baixo.
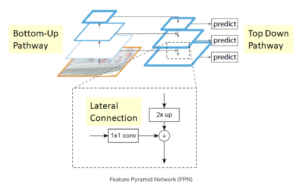
O caminho de baixo para cima é a rede convolucional usual para extração de características. À medida que subimos, a resolução espacial diminui, mas o valor semântico aumenta. No artigo original, isso foi construído usando um ResNet.
O caminho de cima para baixo constrói camadas de alta resolução a partir de uma camada rica em semântica. Conexões laterais são adicionadas entre as camadas reconstruídas e os mapas de características correspondentes para ajudar o detector a prever melhor a localização. Ele também atua como uma conexão de salto para facilitar o treinamento.
O diagrama a seguir mostra a arquitetura final do backbone combinando os níveis ResNet e FPN.
Cabeça de segmentação
Alinhados com o desenvolvimento de uma abordagem simples, decidimos basear a cabeça de segmentação em uma abordagem clássica UNet modelo que tem se mostrado útil para esse tipo de problema.
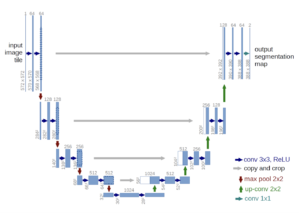
A arquitetura da UNet é totalmente convolucional e consiste basicamente em três partes:
- Caminho de contratação (codificador): É composto por 4 blocos. Cada um aplica uma combinação de convolução 3x3+ReLU duas vezes (“Convolução dupla”), seguida por um MaxPool 2x2 com passo 2 para reduzir a resolução. Em cada etapa de redução da resolução, dobramos o número de canais especiais.
- Gargalo: É uma combinação de convolução 3x3+ReLU repetida duas vezes. Ele atua como uma ponte entre as vias do codificador e do decodificador.
- Caminho expansivo (decodificador): É composto por 4 blocos. Cada um aplica uma ampliação da amostra do mapa de características seguida por uma convolução 2x2 (“Convolução ascendente”), seguida por uma concatenação com o mapa de características correspondente recortado do caminho de contração e duas combinações 3x3 de convolução + ReLU (“Convolução dupla”). A etapa de concatenação ajuda a evitar a perda de informações espaciais devido à redução da resolução. Na camada final, uma convolução 1x1 é usada para mapear cada vetor de feição de 64 componentes para o número desejado de classes.
Cabeça de detecção
Em termos de detectores de objetos de um estágio, o modelo RetinaNet provou funcionar muito bem em objetos pequenos. Além disso, em essência, seu backbone consiste em uma FPN construída sobre uma ResNet que se alinha perfeitamente com a nossa. Assim, parecia a melhor maneira de construir nossa cabeça de detecção.
O RetinaNet foi apresentado pela equipe de pesquisa de IA do Facebook em 2017. Seu design visava resolver problemas de detecção de objetos pequenos e densos, introduzindo duas melhorias nos modelos clássicos de detecção de objetos:
- Incorporando Feature Pyramid Networks (FPN) ao backbone.
- Usando a função Focal Loss para a classificação da perda de sub-rede.
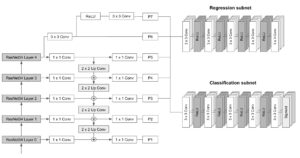
A arquitetura da RetinaNet consiste no seguinte:
- Espinha dorsal: Um backbone totalmente convolucional responsável por computar o mapa de características de toda a imagem em diferentes escalas. Para o RetinaNet, o FPN é construído com base na arquitetura ResNet. A pirâmide tem 5 níveis, P3 a P7, cobrindo as seguintes resoluções: [23, 24, 25, 26, 27].
- Sub-rede de classificação: Uma rede totalmente convolucional conectada a cada nível da pirâmide que visa prever a probabilidade de um objeto estar presente em cada localização espacial para cada caixa âncora e classe de objeto. Consiste na aplicação de quatro camadas convolucionais 3x3 com filtros M seguidas de ativações ReLU, sendo M o número de canais em cada nível da pirâmide. Finalmente, ele aplica outra camada convolucional 3x3 com filtros CxA, com C sendo o número de classes alvo e A o número de caixas de ancoragem (9 por padrão), seguido por ativações sigmóides que são usadas para obter a pontuação final da classificação.
- Sub-rede de regressão: Uma rede totalmente convolucional conectada a cada nível da pirâmide que funciona em paralelo à sub-rede de classificação. Seu objetivo é regredir o deslocamento de cada caixa âncora para um objeto próximo (se houver). O design da sub-rede de regressão de caixa é praticamente idêntico ao da rede de classificação, a única diferença é que o último convolucional 3x3 tem filtros 4*A, com A sendo o número de caixas âncora (9 por padrão). Em outras palavras, para cada uma das caixas de ancoragem A por localização espacial, 4 saídas são previstas, que representam o deslocamento relativo entre a âncora e a caixa de verdade terrestre).
O esquema a seguir ilustra a arquitetura da RetinaNet e as interconexões entre seus diferentes módulos:
Caixas de ancoragem
O RetinaNet usa caixas de ancoragem com tamanhos fixos antes de prever a caixa delimitadora real de cada objeto. As âncoras têm áreas que variam de 32x32 a 512x512 em todos os níveis da pirâmide (P3 a P7). Além disso, para melhorar a cobertura, três proporções [1:2, 1:1, 2:1] e escalas [20, 21/3, 22/3] são incorporadas ao design, resultando em um total de 9 âncoras por nível por localização espacial. Com essa configuração, as âncoras conseguem cobrir a faixa de escala de 32 a 813 pixels em relação à imagem de entrada.
Para cada âncora, uma pontuação de interseção sobre união (IoU) é calculada. Se a pontuação de IoU for maior ou igual a 0,5, a âncora será atribuída a um objeto fundamental e considerada na função de perda. Se o IoU estiver entre 0 e 0,4, ele será considerado como plano de fundo. Finalmente, se a pontuação estiver entre 0,4 e 0,5, ela será ignorada.
Em cada camada da pirâmide, milhares de caixas de ancoragem são geradas (9 por cada localização espacial na imagem), mas apenas algumas realmente conterão objetos. Esse grande número de negativos fáceis pode sobrecarregar o modelo, portanto Perda focal foi introduzido para evitar isso. Basicamente, Perda focal remodela a clássica perda de entropia cruzada (CE) incorporando um fator de escala dinâmico que decai para zero à medida que a confiança na classe correta aumenta. Em outras palavras, esse fator de escala reduz automaticamente a contribuição dos exemplos fáceis, como negativos fáceis, e se concentra rapidamente em melhorar os difíceis.
Algumas coisas para ter em mente...
Usos do RetinaNet fixo tamanhos de âncora que podem precisar ser ajustados adequadamente. Os valores de tamanho padrão são [32, 54, 128, 256, 512], ou seja, objetos menores que 32 por 32 pixels não serão detectados pelo modelo. Levando esse fator em consideração, para realizar um projeto adequado das caixas de ancoragem, é uma boa prática revisar os seguintes pontos:
- Identifique os menores e maiores objetos que devem ser detectados.
- Identifique as diferentes formas que uma caixa pode assumir, ou seja, as possíveis proporções entre a altura e a largura de uma caixa.
Juntando tudo
Agora que analisamos cada componente separadamente, nesta seção, orientaremos você no processo de conexão de todas as peças. Como apresentamos anteriormente, nosso backbone é igual ao da RetinaNet, então só precisaremos nos concentrar em como conectar o cabeçote de segmentação ao nosso backbone.
Examinando de perto a arquitetura da UNet, pode-se perceber que o caminho do codificador pode ser facilmente substituído pelo nosso backbone ResNet + FPN. Para isso, as camadas P1 a P5 da rede piramidal são concatenadas às entradas dos blocos decodificadores da Unet.
O diagrama a seguir pretende descrever a arquitetura final do modelo.
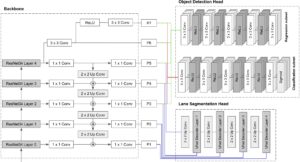
Para treinar o modelo final, uma função de perda adequada deve ser definida. Abordamos esse requisito realizando uma soma ponderada que combina as perdas de cada cabeça: entropia cruzada para a cabeça de segmentação e perda focal para a cabeça de detecção de objetos.
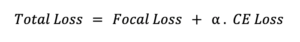
Nossos resultados
Treinamos nosso modelo usando o Conjunto de dados do Berkeley Deep Drive (BDD100k) e conseguimos obter resultados muito encorajadores, independentemente de termos usado apenas 5 épocas para treinamento. Alguns dos resultados obtidos no conjunto de testes são mostrados nas imagens abaixo.
Como você pode ver, o modelo não apenas realiza a segmentação das faixas dirigíveis, mas também consegue detectar diferentes objetos de tamanhos e classes variados presentes nas imagens.




Para validar ainda mais o desempenho do modelo, também o testamos em algumas imagens das ruas da cidade de Montevidéu, obtendo resultados incríveis. Como essas imagens estão fora do conjunto de dados BDD100k, demonstramos que nosso modelo também é capaz de generalizar muito bem.



Conclusões e próximas etapas
Nós fizemos isso! Conseguimos implementar com sucesso um modelo simples, mas poderoso, de duas cabeças para detecção de objetos e segmentação de imagens. Os resultados alcançados com essa abordagem têm se mostrado bastante promissores, reafirmando as vantagens da implementação da abordagem com várias cabeças. No entanto, a simplicidade usada na arquitetura nos deu uma compreensão mais profunda da solução como um todo.
Quanto às possíveis próximas etapas, algumas das seguintes podem ser bons pontos de partida:
- Melhorar a seleção de âncoras no RetinaNet implementando um algoritmo de agrupamento, por exemplo, k-means, para determinar os tamanhos de âncora apropriados com base nos dados de treinamento.
- Mergulhe mais fundo no ajuste fino da ponderação de perdas.
- Substituindo nossa versão básica do FPN por um FPN estendido. Dessa forma, podemos incorporar o mapa de recursos do nível P2 da pirâmide sem comprometer o desempenho em tempo real.
- Substitua o ResNet34 por versões mais profundas, como ResNet101 ou ResNet 50, para obter maior precisão.
Esperamos que você tenha gostado desta postagem. Fique ligado para saber mais!
Referências:
- Aprendizado residual profundo para reconhecimento de imagens
- Possui redes em pirâmide para detecção de objetos
- U-Net: Redes convolucionais para segmentação de imagens biomédicas
- Anchor Boxes — A chave para a detecção de objetos de qualidade
- Perda focal para detecção de objetos densos
- Conjunto de dados do Berkeley Deep Drive (BDD100k)



.png)