.png)
ChatGPT y LLM: cómo ponerlos a trabajar para tu negocio




Comprender cómo usar ChatGPT y LLMS
ChatGPT está provocando una revolución en muchos sectores. Muchos más están en proceso de ser interrumpidos y aún no se han dado cuenta de ello. Al mismo tiempo, es difícil saber qué hacer al respecto. Es difícil crear una hoja de ruta clara para utilizar esta tecnología, dada la evolución extremadamente rápida del campo. Una decisión inteligente de hoy puede quedar anticuada mañana. Esta publicación busca compartir algunos datos y consejos basados en nuestra experiencia en Marvik para que puedas evitar sentirte abrumado por tu cuenta de Twitter.

Conceptos clave
Algunos conceptos importantes que debe conocer para comprender lo que está sucediendo. En primer lugar, Chat.GPT es propiedad de OpenAI.. OpenAI es una empresa privada en la que Microsoft tiene una enorme inversión, puedes leer más sobre eso aquí. No se han revelado los detalles del modelo utilizado por ellos y no tenemos mucha visibilidad sobre su hoja de ruta comercial o de productos. Modelos lingüísticos de gran tamaño o LLMs forman parte del campo Procesamiento del lenguaje natural (PNL). Se trata de modelos enormes (medidos por los miles de millones de parámetros que tienen) centrados en la resolución de problemas lingüísticos. No hay que preocuparse por los miles de millones de parámetros, solo hay que recordar que, cuanto más tienen, mejores suelen ser los modelos y más caros son su formación y su uso en producción debido al hardware que necesitan. IA generativa es otro campo que ha evolucionado rápidamente en los últimos meses y que se centra en la generación de cosas según los modelos de IA. Esos cosas pueden ser texto (por ejemplo, ChatGPT), imágenes (por ejemplo, Midjourney), vídeos, audio, etc. ChatGPT reside en la intersección de los LLM y la IA generativa, pero hay modelos generativos que no generan texto y LLM que se centran en otras tareas que no son la generación de texto. Ninguno de estos campos es nuevo y hay empresas (como nosotros:)) que llevan años trabajando en ellos, pero últimamente han recibido más atención. Podemos dar las gracias a OpenAI y ChatGPT porque sin su increíble progreso esto no habría sido posible, y está habilitando muchas aplicaciones y acelerando su adopción.
Preocupaciones y bloqueadores
Si quieres usar ChatGPT para tu negocio, lo más probable es que tengas dificultades para resolver dos problemas importantes:
- Privacidad: OpenAI necesita recibir sus datos como entrada para poder producir las salidas que generan. No hay forma de evitar enviarles información, aunque exploramos soluciones para ello.
- Precisión: ChatGPT no conoce los detalles de su negocio y, en términos más generales, los modelos generativos están entrenados para generar cosas coherentes que no siempre son precisas. Puede malinterpretar datos importantes, lo que puede tener un enorme impacto en sus clientes o en los procesos internos.
Si quieres ser más técnico, cuando entrenas a estos modelos hay una equilibrio entre generalización y memorización. Supongamos que entrenas a un modelo para que responda preguntas sobre los productos de tu tienda. Los entrenas con los datos de los que dispones en este momento y te gustaría que pudieran responder a preguntas sobre productos que aún no se han añadido a tu catálogo o stock. Si dejas que los modelos se generalicen y hablen sobre cosas que aún no tienes en tu catálogo durante el entrenamiento, entonces tienen que inventarse cosas. Si le enseñas al modelo a ser preciso, solo podrá hacerlo si memoriza todo tu catálogo. Necesita un poco de ambos, debe evitar consumir demasiado de ninguno de los dos. El punto exacto en el que se encuentra con respecto a este equilibrio es parte del trabajo de ingeniería que debe realizar al desarrollar estos sistemas.
Uso de ChatGPT y LLMS
Las alternativas son:
- Para usar ChatGPT con información enmascarada: es posible que su empresa no tenga restricciones estrictas en cuanto a la privacidad de la información o la precisión de las instrucciones que se devuelven a los usuarios. ¡Eres uno de los afortunados
- Para usar tu propio modelo generativo o LLM: es posible que hayas oído hablar Llama del equipo de IA de Meta, Vicuña que se puede encontrar en HuggingFace y en muchos otros modelos con nombres de camélidos por alguna razón. Estos modelos han sido de código abierto para que la comunidad entrene alternativas a ChatGPT. Estos modelos forman parte de lo que se denomina LLM y se pueden entrenar para múltiples tareas. La ventaja es que puedes ser el propietario del modelo, lo que elimina cualquier problema de privacidad y también enseña a los modelos sobre tu dominio o empresa específicos, lo que, si se hace correctamente, puede mejorar la precisión. Los conjuntos de datos de código abierto facilitan esta tarea, lo que reduce las restricciones de necesitar grandes volúmenes de información para capacitarse. Estos datos de código abierto generalmente se combinan con sus propios datos para que también puedan obtener información específica del dominio.
- Para usar las dos opciones anteriores y combinar el resultado: donde utilizas lo mejor de ChatGPT y sus avances y lo combinas con tus propios modelos o un canal más sofisticado. Las canalizaciones complejas pueden requerir diferentes etapas generativas, en las que ChatGPT puede complementarse con un modelo que te capacites para especializarte en un tema específico.
Un descargo de responsabilidad importante es que la formación de ChatGPT ha costado millones de dólares, se basó en enormes volúmenes de información y es que el modelo, que es notoriamente mejor que casi cualquier otro que existe en este momento, no es de código abierto. La comunidad busca replicar lo que está haciendo el equipo de OpenAI, pero todavía tienen una ventaja tecnológica en el ámbito general. Esto significa que ChatGPT puede ser mejor para resolver muchos problemas, pero no necesariamente mejor para resolver su problema. Puede proporcionarlo con un contexto limitado, que puede o no ser suficiente para su aplicación.
Entrando en los detalles técnicos
Sistemas como estos deben diseñarse caso por caso, pero a continuación veremos cómo puede ser una canalización lista para la producción.
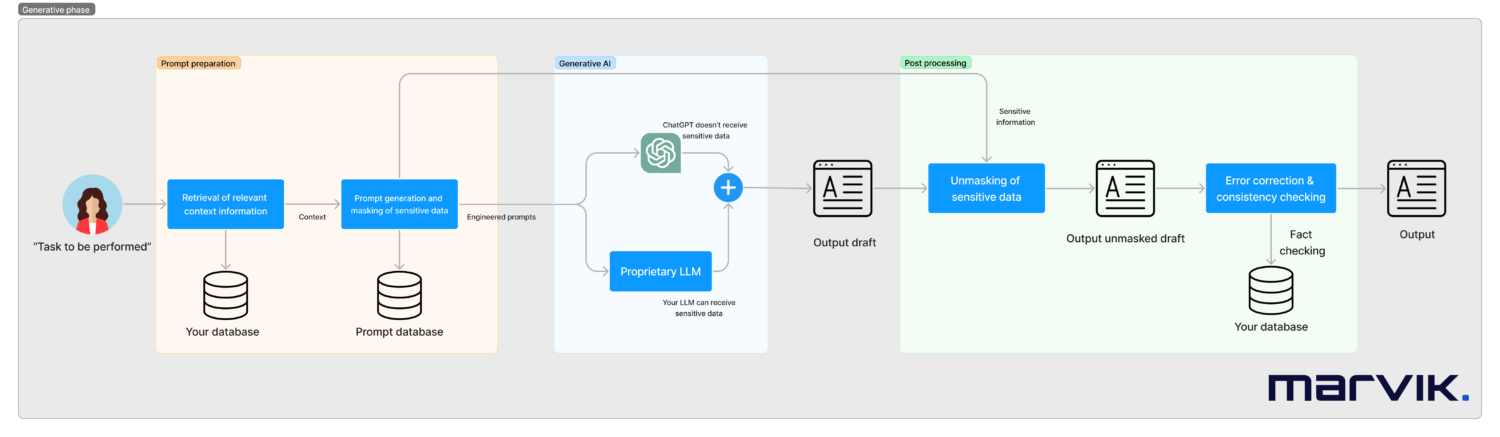
En este flujo de trabajo, haremos lo siguiente:
- Comience con una tarea a realizar (puede ser activada por una persona o automáticamente, como un correo electrónico entrante). Vamos a trabajar con un ejemplo de un caso de atención al cliente de una institución financiera
- Recuperaremos toda la información de contexto relevante necesaria para responder a la tarea. En el ejemplo, este puede ser el saldo de la tarjeta de crédito
- Pasaremos a la fase de preparación de las indicaciones para los modelos generativos. Este será el resultado de un rápido trabajo de ingeniería realizado una vez durante la implementación del sistema.
- También podemos ocultar cualquier dato confidencial si es necesario en este momento, por ejemplo, el nombre del cliente o el saldo de la cuenta. Al simplificar demasiado el enmascaramiento, esto puede reemplazar a saldo de $100 por balance de X. Esto es más complejo que eso, ya que hay relaciones que deben preservarse (si estás intentando comprar un artículo por 200 dólares, no es lo mismo si tu saldo es de 100 o 300 dólares).
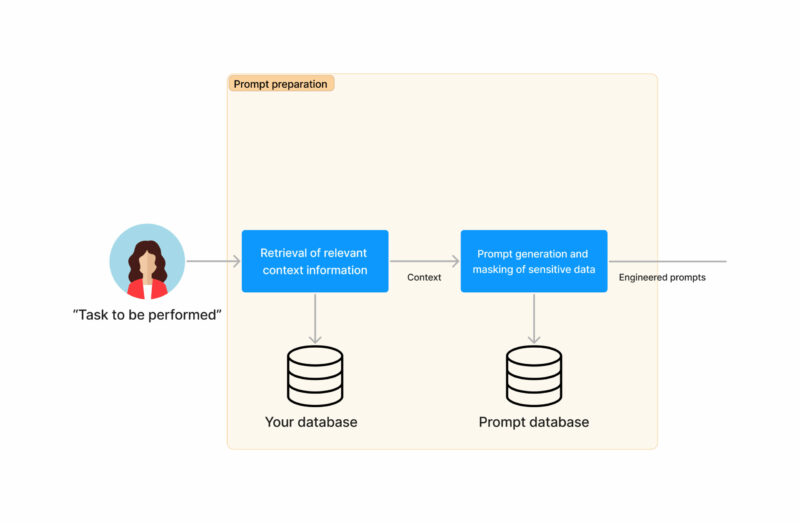
- Las instrucciones se enviarán automáticamente a los modelos generativos. Las alternativas son:
- Para usar ChatGPT con información enmascarada
- Para usar su propio modelo generativo o LLM
- Para usar las dos opciones anteriores y combinar el resultado
- En este momento necesitamos desenmascarar la información sensible que habíamos ocultado anteriormente. Es decir, revertir el balance de X para un saldo de $100.
- Haz lo real generación de texto mediante IA. Puedes hacerlo usando ChatGPT o tu propio modelo LLM.
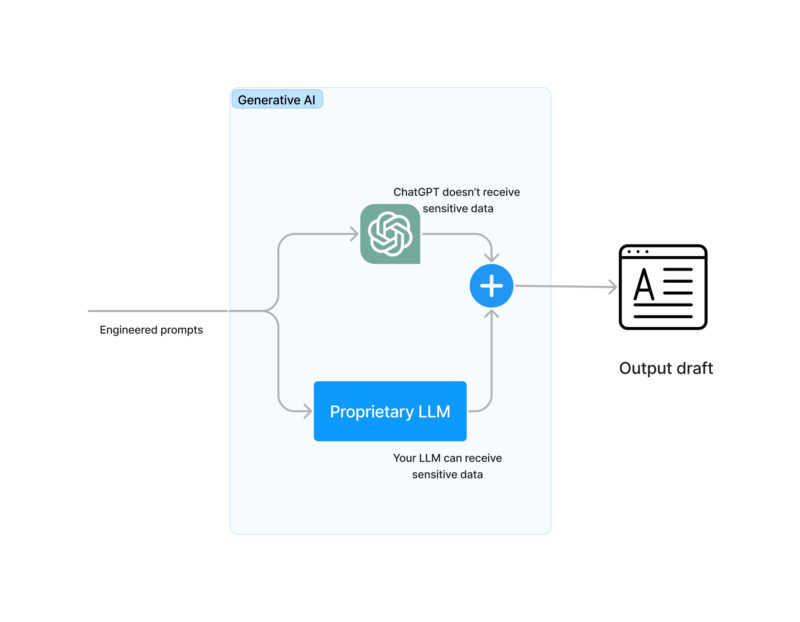
- Ahora que tiene una respuesta viable, debe comprobar que no está diciendo ninguna incoherencia. En este momento lo pones estrategias de corrección de errores y contingencia para tus datos. Por ejemplo, parte de la respuesta podría ser»Si tienes cualquier duda, llámanos al 555-1234 de 8:00 a 17:00». Más vale que ese número de teléfono y horario de atención sean reales. Esto puede resultar muy problemático en algunos dominios, como el comercio electrónico, en el que no puedes vender un iPhone de 350 GB, tiene 256 GB o 512 GB y un modelo generativo puede equivocarse fácilmente.
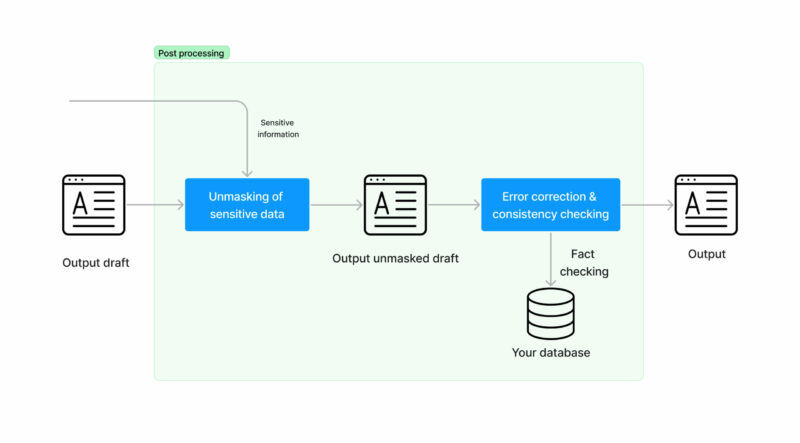
- ¡Hemos terminado! Ahora tienes una respuesta generada automáticamente para una tarea entrante que puedes compartir con tus usuarios. Los hechos se comprueban para que no haya inconsistencias y no se compartan datos confidenciales con terceros.
- ¿Hemos terminado? En ámbitos específicos, es habitual que los humanos vuelvan a avisar. Esto lo podría hacer un agente de atención al cliente que trabaje como un humano al día. Si es necesario, se pueden dar instrucciones a nuestros modelos para que repitan las respuestas.

Algunos comentarios importantes si está pensando en usar esto realmente:
- ChatGPT es genial y puedes aprovechar cualquier modelo nuevo y mejorado que publiquen si usas su API. Ten en cuenta que necesitarás definir indicaciones para interactuar con ChatGPT, los optimizarás para obtener los mejores resultados. Si ChatGPT publica un modelo mejorado, es probable que necesita mantenimiento.
- Comprenda los límites de Políticas de uso de datos de ChatGPT. La versión más reciente en este momento se puede encontrar en https://openai.com/policies/api-data-usage-policies. Básicamente dice: retienen tus datos durante 30 días y, si lo deseas, no los usan para volver a entrenar sus modelos. Esto solo se aplica a la API, no a la interfaz web. Por el momento, todos los datos se procesan y almacenan únicamente en EE. UU.
- La calidad de ChatGPT frente a la de tu propio LLM: Puede esperar que la calidad de ChatGPT sea mejor, pero no tan específica. Se necesita una gran inversión para ser el mejor que existe y lo han hecho, pero es posible que te impresione la calidad de los LLM que puedes formar (muchísimas gracias a la comunidad de código abierto de IA por ello). ChatGPT utiliza, por ejemplo, el aprendizaje por refuerzo, algo que la mayoría de los modelos no utilizan (todavía estamos intentando aplicar ingeniería inversa a la forma exacta en que lo utilizan)
- Tras haber trabajado con modelos generativos en múltiples dominios a gran escala desde hace algunos años, recomendamos encarecidamente no subestimar la importancia de la corrección de errores y contingencias necesario para comprobar la calidad de la generación.
Conseguir el momento adecuado
Es posible que tengas miedo de involucrarte en un costoso proyecto de desarrollo capacitando a tus propios LLM cuando OpenAI o alguna otra empresa lance un nuevo modelo mejorado en el futuro, o cambie sus políticas de privacidad y tu solución quede obsoleta rápidamente. Este es un punto completamente válido, pero solo algunas reflexiones al respecto:
- La realidad puede cambiar, pero también puede que no, y si no lo hace, está desperdiciando un tiempo valioso que sus competidores tal vez no estén perdiendo
- Es más probable que la comunidad publique un LLM mejorado o que abra código abierto un nuevo conjunto de datos que haga que sea más inteligente entrenar un nuevo modelo y simplemente reemplazar ese bloque en nuestro diagrama que OpenAI cambie sus políticas de privacidad y esto se convierta en una inversión innecesaria. La razón detrás de esto es que:
- Este es un campo que avanza rápidamente y la comunidad se está poniendo al día muy rápido con el estado del arte.
- No parece la decisión más inteligente de OpenAI lanzar sus modelos en los que se les pueda aplicar ingeniería inversa mientras tengan una ventaja tecnológica.
- Si se lanzan nuevos modelos, lo más probable es que pueda reutilizar cualquier preparación de capacitación que ya haya realizado, y el costo y el tiempo de actualización se reducirán significativamente.
- Incluso si la parte generativa del sistema necesita una actualización en el futuro (ChatGPT o tu propio LLM), es muy probable que el resto del sistema sea necesario para cualquier tarea que quieras resolver a escala.
Reflexiones finales
Hemos visto un gran avance en el juego. Esto se debe a volúmenes de información aún mayores con los que ahora podemos entrenarnos, a modelos más grandes y sofisticados y a una enorme potencia informática para la formación. Si bien todo lo anterior es crucial, también parte de esta evolución se debe al cambio de enfoque del entrenamiento de estos modelos que ahora intentan resolver tareas más complejas. En pocas palabras, en el pasado solíamos entrenar a los chatbots para que clasificaran la intención de un usuario y creábamos la respuesta con una regla bastante fija. Entrenamos los modelos para que fueran precisos en la clasificación. Ahora los entrenamos con el objetivo de mantener una conversación realista parecida a la de un humano. Parecen más inteligentes a la hora de hacer el balance de no entender bien los hechos. Conseguir que la conversación y los hechos sean correctos al mismo tiempo todavía está al borde del estado del arte. Muchas empresas se verán afectadas. Todavía estamos en medio de la revolución, por lo que es difícil predecir cómo acabará siendo el panorama. Por ejemplo, espero con ansias los avances que conseguiremos en el campo de la robótica muy pronto. A pesar de esto, hay no hay mejor momento para trabajar en esto que ahora, mañana puede ser tarde. Como dijo Bill Gates: la era de la IA ha comenzado. Lea más sobre esto en nuestra web: https://www.marvik.ai/areas/large-language-models



.png)