.png)
ChatGPT e LLMs: como colocá-los em prática para sua empresa




Entendendo como usar o ChatGPT e o LLMs
O ChatGPT está causando uma revolução em muitos setores. Muitos outros estão em processo de interrupção e ainda não perceberam isso. Ao mesmo tempo, é difícil saber o que fazer a respeito. É difícil criar um roteiro claro para usar essa tecnologia, dada a evolução extremamente rápida do campo. Uma decisão inteligente hoje pode estar desatualizada amanhã. Esta postagem tem como objetivo compartilhar alguns fatos e conselhos com base em nossa experiência na Marvik, para que você evite ficar sobrecarregado com o feed do Twitter.

Conceitos-chave
Alguns conceitos importantes que você precisa conhecer para entender o que está acontecendo. Em primeiro lugar, O ChatGPT é de propriedade da OpenAI. A OpenAI é uma empresa privada na qual a Microsoft tem um grande investimento, você pode ler mais sobre isso aqui. As especificidades do modelo usado por eles não foram reveladas e não temos muita visibilidade sobre seu produto ou roteiro comercial. Grandes modelos de linguagem ou LLMs fazem parte do campo de Processamento de Linguagem Natural (PNL). Esses são modelos enormes (medidos pelos bilhões de parâmetros que eles têm) focados na solução de problemas de linguagem. Você não deve se preocupar com os bilhões de parâmetros, mas lembre-se apenas de que, quanto mais eles tiverem, melhores serão os modelos e mais caros serão treinados e usados na produção devido ao hardware de que precisam. IA generativa é outro campo que evoluiu rapidamente nos últimos meses, que se concentra na geração de coisas pelos modelos de IA. Aqueles coisas pode ser texto (por exemplo, ChatGPT), imagens (por exemplo, Midjourney), vídeos, áudio etc. O ChatGPT reside na interseção de LLMs e IA generativa, mas existem modelos generativos que não geram texto e LLMs que se concentram em outras tarefas que não são geração de texto. Nenhum desses campos é novo e existem empresas (como nós:)) que trabalham neles há anos, mas só receberam mais atenção ultimamente. Podemos agradecer à OpenAI e ao ChatGPT porque, sem seu incrível progresso, isso não teria sido possível, e está habilitando muitos aplicativos e acelerando a adoção.
Preocupações e bloqueadores
Se você quiser usar o ChatGPT para sua empresa, provavelmente está tendo dificuldades para resolver dois grandes problemas:
- Privacidade: O OpenAI precisa receber dados de você como entrada para que possa produzir as saídas que eles geram. Não há como evitar o envio de informações a eles, embora exploremos soluções alternativas para isso.
- Precisão: O ChatGPT não conhece as especificidades do seu negócio e, de forma mais ampla, os modelos generativos são treinados para gerar coisas coerentes que nem sempre são precisas. Isso pode errar fatos importantes, o que pode ter um grande impacto em seus clientes ou processos internos.
Se você quiser ser mais técnico, quando você treina esses modelos, há um compensação entre generalização e memorização. Suponha que você treine um modelo para responder perguntas sobre os produtos da sua loja. Você os treina com os dados que você tem no momento e gostaria que eles pudessem responder perguntas sobre produtos que ainda não foram adicionados ao seu catálogo ou estoque. Se você deixar os modelos generalizarem e falarem sobre coisas que você ainda não tem em seu catálogo durante o treinamento, eles precisam inventar coisas. Se você ensinar o modelo a ser preciso, ele só poderá fazê-lo memorizando todo o seu catálogo. Você precisa de um pouco de ambos, você precisa evitar consumir muito de ambos. O ponto exato em que você se posiciona nessa troca faz parte do trabalho de engenharia que você precisa fazer ao desenvolver esses sistemas.
Usando ChatGPT e LLMs
As alternativas são:
- Para usar o ChatGPT com informações mascaradas: sua empresa pode não ter restrições fortes em termos de privacidade das informações ou da precisão das solicitações devolvidas aos usuários. Você é um dos sortudos
- Para usar seu próprio modelo Generativo ou LLM: você pode ter ouvido falar sobre Lhama da equipe de IA da Meta, Vicunha que pode ser encontrado no HuggingFace e em muitos outros modelos com nomes de camelídeos por algum motivo. Esses modelos foram de código aberto para a comunidade treinar alternativas ao ChatGPT. Esses modelos fazem parte do que é chamado de LLMs e podem ser treinados para várias tarefas. A vantagem é que você pode possuir o modelo, eliminando assim quaisquer preocupações com a privacidade e também ensinando os modelos sobre seu domínio ou empresa específica, o que, se feito corretamente, pode melhorar a precisão. Os conjuntos de dados de código aberto facilitam essa tarefa, o que reduz as restrições da necessidade de grandes volumes de informações para treinar. Esses dados de código aberto geralmente são combinados com seus próprios dados para que eles também possam aprender informações específicas do domínio.
- Para usar as duas opções acima e mesclar o resultado: onde você usa o melhor do ChatGPT e seus avanços e combina isso com seus próprios modelos ou funis mais sofisticados. Pipelines complexos podem exigir diferentes estágios gerativos, nos quais o ChatGPT pode ser complementado com um modelo que você treina para se especializar em um tópico específico.
Um aviso importante é que o treinamento do ChatGPT custou milhões de dólares, foi treinado em grandes volumes de informações e é o modelo, que é notoriamente melhor do que quase tudo que existe no momento, não tem código aberto. A comunidade está procurando replicar o que a equipe da OpenAI está fazendo, mas ainda tem uma vantagem tecnológica em um domínio geral. Isso significa que o ChatGPT pode ser melhor na solução de muitos problemas, mas não necessariamente melhor na solução de seus problemas. Você pode fornecer um contexto limitado, que pode ou não ser suficiente para seu aplicativo.
Entrando nos detalhes técnicos
Sistemas como esses precisam ser projetados caso a caso, mas a aparência de um pipeline pronto para produção é vista a seguir.
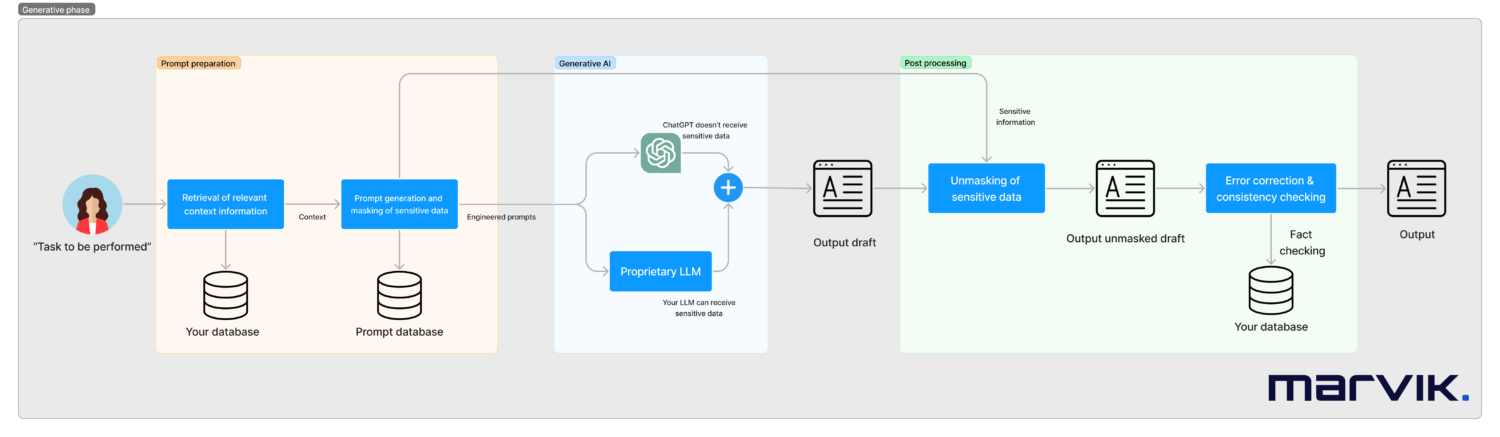
Nesse fluxo de trabalho, vamos:
- Comece com uma tarefa a ser executada (pode ser acionada por um humano ou automaticamente, como um e-mail recebido). Vamos trabalhar com um exemplo de um caso de suporte ao cliente de uma instituição financeira
- Recuperaremos todas as informações contextuais relevantes necessárias para responder à tarefa. No exemplo, isso pode ser o saldo do cartão de crédito.
- Passaremos para uma fase de preparação das instruções para os modelos generativos. Isso será o resultado de um rápido trabalho de engenharia realizado uma vez durante a implementação do sistema.
- Também podemos mascarar quaisquer dados confidenciais, se necessário, neste momento, por exemplo, o nome do cliente ou o saldo da conta. Simplificando demais o mascaramento, isso pode estar substituindo um saldo de $100 pelo saldo de X. Isso é mais complexo do que isso, pois há relacionamentos que precisam ser preservados (se você está tentando comprar um item por $200, não é o mesmo se seu saldo for de $100 ou $300).
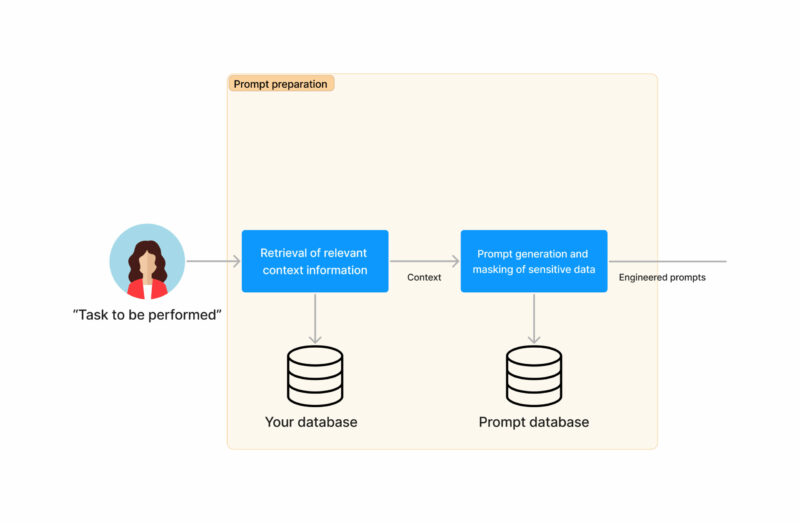
- As solicitações serão feitas automaticamente para o (s) modelo (s) generativo (s). As alternativas são:
- Para usar o ChatGPT com informações mascaradas
- Para usar seu próprio modelo Generativo ou LLM
- Para usar as duas opções acima e mesclar o resultado
- Neste momento, precisamos desmascarar as informações confidenciais que havíamos mascarado antes. Isto é, revertendo o saldo de X para um saldo de $100.
- Faça o real geração de texto usando IA. Isso pode ser feito usando o ChatGPT ou seu próprio modelo LLM.
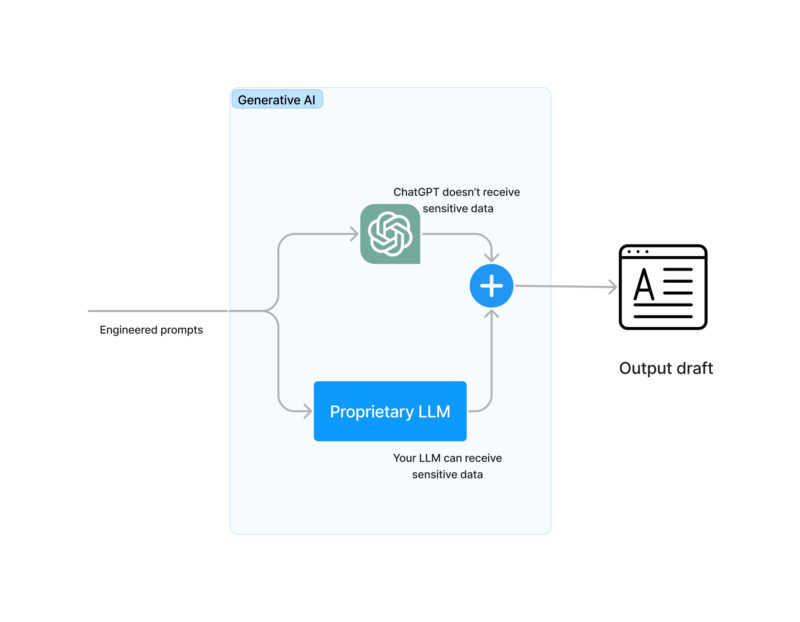
- Agora que você tem uma resposta viável, verifique se não está dizendo nenhuma inconsistência. Neste momento, você coloca no lugar estratégias de correção de erros e contingência para seus dados. Por exemplo, parte da resposta pode ser”Se você tiver alguma dúvida, ligue para 555-1234 das 8h às 17h”. É melhor que esse número de telefone e horário de funcionamento sejam reais. Isso pode ser muito problemático em alguns domínios, como o comércio eletrônico, onde você não pode vender um iPhone com 350 GB, tem 256 GB ou 512 GB e um modelo generativo pode facilmente errar.
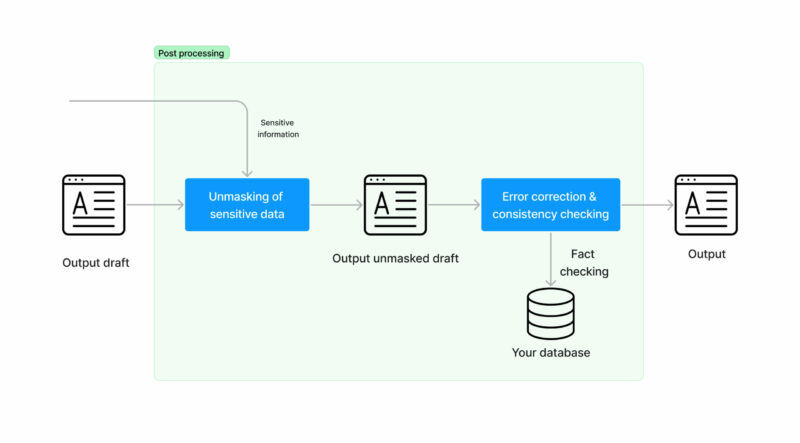
- Nós terminamos! Agora você tem uma resposta gerada automaticamente para uma tarefa de entrada que você pode compartilhar com seus usuários. Os fatos são verificados para que não haja inconsistências e nenhum dado confidencial seja compartilhado com terceiros.
- Já terminamos? Em domínios específicos, é comum que os humanos avisem novamente. Isso pode ser feito por um agente de suporte ao cliente trabalhando como um humano no circuito. Se necessário, instruções podem ser fornecidas aos nossos modelos para iterar as respostas.

Alguns comentários importantes se você está pensando em realmente usar isso:
- O ChatGPT é ótimo e você pode aproveitar todos os novos modelos aprimorados lançados por eles se usar a API deles. Lembre-se de que você precisará definir solicitações para interagir com o ChatGPT, você os otimizará para obter os melhores resultados. Se o ChatGPT lançar um modelo aprimorado, você está propenso a precisam de manutenção.
- Entenda os limites do Políticas de uso de dados do ChatGPT. A versão mais recente no momento pode ser encontrada em https://openai.com/policies/api-data-usage-policies. Basicamente, diz: eles retêm seus dados por 30 dias e, se você quiser, não os usam para treinar novamente seus modelos. Isso se aplica apenas à API, não à interface da web. No momento, todos os dados são processados e armazenados somente nos EUA.
- Qualidade do ChatGPT versus seu próprio LLM: Você pode esperar que a qualidade do ChatGPT seja melhor, mas não tão específica. É preciso um grande investimento para ser o melhor do mercado, e eles fizeram isso, mas você pode ficar impressionado com a qualidade dos LLMs que você pode treinar (muito obrigado à comunidade de código aberto de IA por isso). O ChatGPT está, por exemplo, usando aprendizado por reforço, o que a maioria dos modelos não usa (ainda estamos tentando fazer engenharia reversa exatamente como eles estão usando isso)
- Tendo trabalhado com modelos generativos em vários domínios em grande escala há alguns anos, é altamente recomendável não subestimar a importância do correção de erros e contingências necessário para verificar a qualidade da geração.
Acertando o momento certo
Você pode ter medo de entrar em um projeto de desenvolvimento caro treinando seus próprios LLMs quando a OpenAI ou alguma outra empresa pode lançar um novo modelo aprimorado no futuro ou alterar suas políticas de privacidade e sua solução pode ficar desatualizada rapidamente. Este é um ponto totalmente válido, mas apenas algumas reflexões sobre isso:
- A realidade pode mudar, mas também pode não mudar, e se isso não acontecer, você está desperdiçando um tempo valioso que seus concorrentes podem não estar perdendo
- É mais provável que a comunidade lance um LLM aprimorado ou um novo conjunto de dados de código aberto que torne mais inteligente treinar um novo modelo e simplesmente substituir esse bloco em nosso diagrama do que o OpenAI altere suas políticas de privacidade e isso se torne um investimento desnecessário. A lógica por trás disso é que:
- Este é um campo em rápida evolução e a comunidade está se atualizando muito rapidamente com o estado da arte.
- Não parece ser a decisão mais inteligente da OpenAI lançar seus modelos, onde eles podem ser submetidos à engenharia reversa e, ao mesmo tempo, ter uma vantagem tecnológica.
- Se novos modelos forem lançados, você provavelmente poderá reutilizar qualquer preparação de treinamento que já tenha feito, e o custo e o tempo de atualização serão reduzidos significativamente.
- Mesmo que a parte geradora do sistema precise de uma atualização no futuro (ChatGPT ou seu próprio LLM), é muito provável que o restante do sistema seja necessário para qualquer tarefa que você queira resolver em grande escala.
Considerações finais
Vimos um grande avanço no jogo. Isso se deve a volumes ainda maiores de informações com os quais agora podemos treinar, a modelos maiores e mais sofisticados e ao enorme poder de computação para treinamento. Embora todos os itens acima sejam cruciais, parte dessa evolução também é derivada da mudança no foco do treinamento desses modelos que agora estão tentando resolver tarefas mais complexas. Simplificando, no passado costumávamos treinar chatbots para classificar a intenção de um usuário e criávamos a resposta com uma regra bastante fixa. Treinamos os modelos para precisão na classificação. Agora, nós os treinamos com o objetivo de ter uma conversa realista semelhante à humana. Eles parecem mais inteligentes na compensação de não acertar os fatos. Acertar a conversa e os fatos ao mesmo tempo ainda está à beira do estado da arte. Muitos negócios serão interrompidos. Ainda estamos no meio da revolução, então é difícil prever como será a paisagem. Por exemplo, estou ansioso pelos avanços que obteremos no campo da robótica em breve. Apesar disso, existe não há melhor momento para trabalhar nisso do que agora, amanhã pode ser tarde. Como disse Bill Gates, a era da IA começou. Leia mais sobre isso em nosso site: https://www.marvik.ai/areas/large-language-models



.png)