.png)
Dominar el reconocimiento automático de matrículas en entornos salvajes




Introducción
El reconocimiento automático de matrículas (ALPR) se refiere a la tarea de extraer con precisión la información de las matrículas de una variedad de fuentes visuales, que pueden ir desde imágenes fijas de alta resolución hasta transmisiones de vídeo en tiempo real de las cámaras de vigilancia. [caption id="attachment_3632" align="aligncenter» width="512"]

Ejemplo de tarea de ALPR. [/caption] Las aplicaciones del ALPR son amplias e impactantes. Los sistemas ALPR se utilizan para identificar vehículos robados, rastrear a los sospechosos y gestionar el control del estacionamiento. También desempeñan un papel crucial en los sistemas de cobro de peajes, ya que mejoran el flujo de tráfico al automatizar los pagos y reducir la congestión en las cabinas de peaje. Además, la tecnología ALPR se utiliza en la seguridad y la vigilancia, ya que ayuda a monitorear y controlar el acceso a las áreas seguras mediante el reconocimiento de los vehículos autorizados.
ALPR en estado salvaje
Cuando se trata de buenas imágenes, la tarea de ALPR está prácticamente resuelta: la mayoría de los modelos más avanzados pueden alcanzar fácilmente una alta precisión. Pero los entornos salvajes son impredecibles por definición. Incluso si hemos diseñado y desplegado la configuración de cámara perfecta, las condiciones meteorológicas, como la lluvia, la niebla o el deslumbramiento, pueden ocultar las matrículas y complicar el reconocimiento. Por lo tanto, al desarrollar canalizaciones para aplicaciones de ALPR en entornos salvajes, necesitamos tomar medidas para mantener la precisión incluso en condiciones adversas.
[caption id="attachment_3757" align="aligncenter» width="1024"]

Algunos ejemplos de lo que denominaremos «entornos salvajes» a lo largo de este blog, extraídos de las bases de datos OpenALPR y LPR. [/caption]
Requerimientos habituales
La implementación de un sistema efectivo de reconocimiento automático de matrículas (ALPR) implica varios requisitos clave, siendo la precisión crucial. Para lograrlo, el hardware normalmente necesita un equipo de procesamiento de imágenes de alta calidad capaz de capturar imágenes nítidas y detalladas de las matrículas en diversas condiciones. Sin embargo, en muchos escenarios, las cámaras ya están instaladas para otros fines, como la vigilancia. Aprovechar estas configuraciones preexistentes puede resultar ventajoso, pero requiere una cartera sólida que pueda gestionar desafíos como la baja resolución y las imágenes borrosas sin comprometer la precisión. Los requisitos se vuelven aún más exigentes cuando se opera en entornos del mundo real. La configuración de la cámara debe ser lo suficientemente estable como para permanecer inmóvil en condiciones de viento. Por otro lado, el proceso de procesamiento debe ser experto en la gestión de imágenes de baja calidad. Las aplicaciones en tiempo real también tienen limitaciones de tiempo, ya que requieren cámaras rápidas y un proceso de procesamiento eficiente.
Sistemas ALPR personalizados
Los sistemas ALPR generales están diseñados para ofrecer resultados satisfactorios en una amplia gama de entornos. Por el contrario, los sistemas personalizados se pueden adaptar específicamente para satisfacer necesidades únicas, ya sea en materia de seguridad, administración de estacionamientos o monitoreo del tráfico. Este enfoque personalizado permite ajustar los modelos con precisión, lo que mejora significativamente la precisión al optimizar el rendimiento para entornos específicos. Además, los sistemas personalizados pueden integrarse con la infraestructura y el software existentes, lo que garantiza la escalabilidad a medida que evolucionan los requisitos. Además, ofrecen la capacidad de implementar medidas de protección de datos específicas, abordando de manera efectiva las necesidades de cumplimiento. En este blog, analizaremos los pasos esenciales de las canalizaciones ALPR personalizadas que gestionan imágenes complejas y de alta calidad capturadas en entornos salvajes.
Arquitecturas habituales
Arquitectura v1
Un primer enfoque implica trabajar en una imagen única y clara del vehículo en la que la matrícula sea visible y legible. Un proceso básico para obtener el texto incluiría los siguientes pasos: [caption id="attachment_3634" align="aligncenter» width="934"]

Una primera arquitectura ALPR. [/caption]
- Adquisición de imágenes: captura una imagen de un coche o una matrícula.
- Preprocesamiento de imágenes: prepare la imagen para mejorar los resultados de detección de matrículas.
- Detección de matrículas: localice las matrículas dentro de la imagen.
- Preprocesamiento de matrículas: prepare la imagen de la matrícula para mejorar los resultados del reconocimiento de texto.
- Reconocimiento óptico de caracteres (OCR): extraer texto de las matrículas.
Si bien este primer enfoque es sencillo, su robustez está limitada por su gran dependencia de la calidad de la imagen adquirida y de la adecuación de la etapa de preprocesamiento. Si la imagen obtenida es una imagen nítida y cercana de la placa de matrícula, los pasos posteriores generalmente tendrán menos dificultades o ninguna dificultad para obtener resultados óptimos. Podemos obtener esta imagen de alta calidad si colocamos estratégicamente una cámara bien elegida. Sin embargo, es bien sabido que los entornos salvajes se ven afectados por factores incontrolables, como las condiciones meteorológicas, los cambios de iluminación, los errores humanos y otras circunstancias imprevistas que influyen en la captura, incluso teniendo una configuración de cámara perfecta. Por esta razón, ¡es crucial tener bajo la manga un proceso de preprocesamiento sólido! En la literatura se están realizando esfuerzos para abordar estas situaciones mediante la mejora de la fase de preprocesamiento, que analizaremos más adelante en este blog.
Arquitectura v2: una arquitectura compatible con el formato
Los conjuntos de datos de matrículas generalmente se recopilan de vehículos de un país, estado o región específicos. En consecuencia, el desafío a menudo implica

reconoce el texto de las matrículas que se adhieren a un formato o clase en particular y, por lo general, son muy diferentes entre sí. Por ejemplo, un conjunto de datos de matrículas estadounidenses puede incluir matrículas de Nevada, con texto negro sobre un fondo azul celeste y montañas verdes/anaranjadas en la parte inferior. Estas matrículas siguen las NNN-ANN formato, donde «N» representa un número y «UNA» una carta. Por el contrario, las matrículas hawaianas, que se caracterizan por su fondo arcoíris y el formato AAA-NNN, se diferencian claramente de las de Nevada. Un modelo de aprendizaje automático puede capturar y diferenciar de manera eficaz estas características únicas, lo que permite identificar con precisión las matrículas de cada estado. Los diseños y formatos de las matrículas son los más conocidos, por lo que se puede obligar a los textos detectados a cumplir con su estándar correspondiente. Para implementar esto, una arquitectura más avanzada incluiría dos pasos adicionales: [caption id="attachment_3636" align="aligncenter» width="813"]

Una arquitectura ALPR compatible con el formato. [/subtítulo]
- Clasificación de matrículas: clasifique las matrículas detectadas según los diseños conocidos anteriormente, que pueden variar según la ubicación geográfica o la jurisdicción (por ejemplo, país, estado o formatos internacionales).
- Formato de texto: convertir el texto extraído en un formato estandarizado, apropiado para cada clase de matrícula (por ejemplo, Mercosur o estados específicos de EE. UU.).
Arquitectura v3: aprovechar el vídeo
Las imágenes de las matrículas suelen ser capturadas por las cámaras de vigilancia, lo que da como resultado imágenes de vídeo en lugar de imágenes individuales. Estos vídeos muestran varios fotogramas del mismo vehículo y matrícula desde diferentes distancias, condiciones de iluminación y ángulos, lo que mejora considerablemente la solidez de la detección de textos. Para integrar esta información de manera eficaz, una arquitectura típica incluiría los siguientes pasos adicionales: [caption id="attachment_3637" align="aligncenter» width="992"]
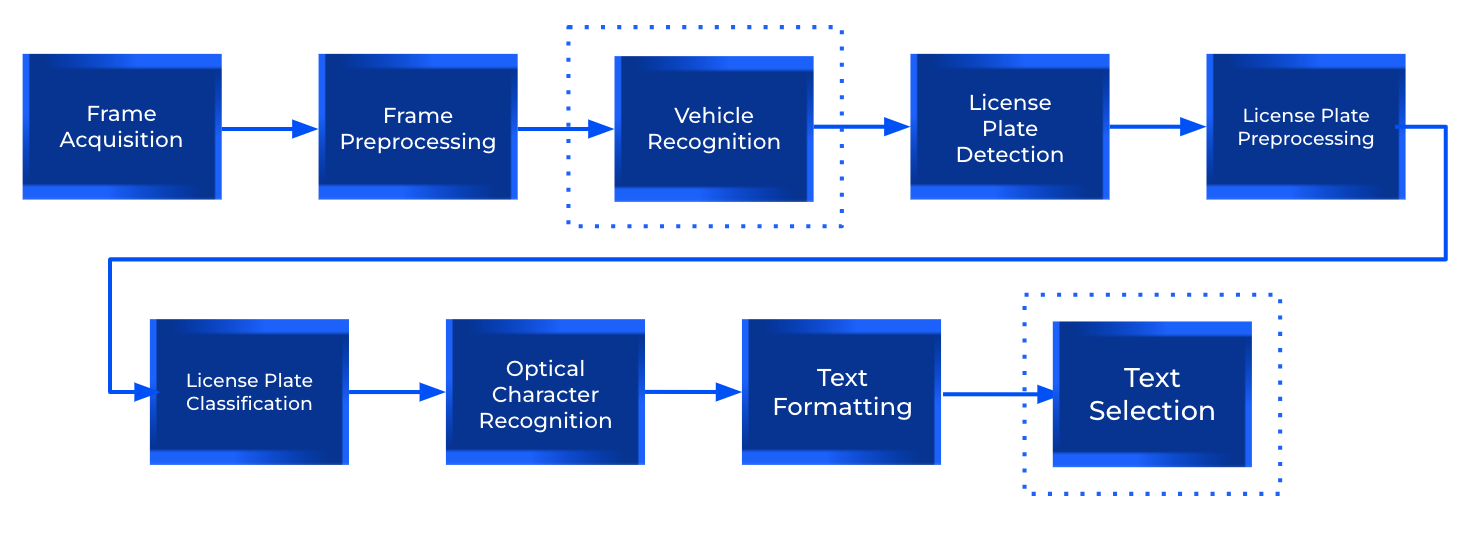
Una arquitectura ALPR compatible con el formato para secuencias de vídeo. [/caption]
- Reconocimiento de vehículos: identificar y rastrear los vehículos dentro de cada cuadro, agrupando varias detecciones del mismo vehículo.
- Selección de texto: elija el texto de matrícula más preciso de los posibles candidatos. Esta decisión puede basarse en los puntajes de confianza en la detección y la clasificación, en la confianza en el reconocimiento del texto y en el cumplimiento del formato esperado. Como alternativa, podríamos seleccionar cada personaje de forma individual, utilizando el que aparezca con más frecuencia entre los chasis del mismo vehículo.
Por lo tanto, si hay al menos una imagen clara de la matrícula para cada vehículo, este enfoque puede asignar con precisión un texto de placa a cada uno, sin requerir un procesamiento previo extenso. [caption id="attachment_3759" align="aligncenter» width="1024"]

Ejemplo de detección de vídeo. Fotogramas extraídos de Vídeo ilustrativo de la cámara de matrícula.[/subtítulo]
Detección de matrículas salvajes
Poder extraer una imagen recortada de una matrícula es claramente un paso fundamental. Esto incluye comprobar la presencia de una matrícula y, si la encuentra, devolver las coordenadas de su casilla delimitadora junto con un puntaje de confianza.
Detectores preentrenados
Los detectores preentrenados ofrecen una solución rápida y eficiente para el reconocimiento de matrículas con un mínimo esfuerzo de codificación, lo que los convierte en una opción atractiva para muchas aplicaciones. Están diseñados para identificar rápidamente el texto dentro de regiones rectangulares, lo que puede resultar ventajoso para un desarrollo rápido. Sin embargo, estos detectores a veces pueden identificar incorrectamente el texto en rectángulos que no son matrículas, lo que produce falsos positivos. Además, pueden tener dificultades en condiciones específicas, como una iluminación deficiente, condiciones meteorológicas extremas o entornos complejos, en las que su rendimiento puede verse considerablemente comprometido. En consecuencia, si bien los detectores previamente entrenados ofrecen un punto de partida sólido, sus limitaciones en ciertos escenarios pueden requerir una personalización adicional o enfoques alternativos para garantizar un reconocimiento confiable en diversos entornos. Las siguientes imágenes corresponden a los resultados de detección con el detector YOLO sobre imágenes extraídas de Abrir ALPR conjunto de datos. [caption id="attachment_3764" align="aligncenter» width="1024"]

Resultados de detección con el detector YOLO sobre imágenes extraídas del conjunto de datos de OpenALPR [/caption] Los ejemplos anteriores ilustran que, si bien los detectores generales funcionan bien en muchas situaciones, a menudo tienen problemas cuando hay texto en el vehículo que no corresponde a una matrícula. Además, la puntuación de detección suele superar los niveles deseados cuando el texto que no es de la matrícula se identifica erróneamente como tal. Esto lo convierte en un indicador poco fiable. Afortunadamente, podemos minimizar estos falsos positivos mediante el ajuste del modelo.
¿Por qué detectores personalizados?
Los detectores personalizados ofrecen ventajas significativas al aprovechar la información específica sobre la disposición de las matrículas, lo que mejora la precisión del reconocimiento. Además, la incorporación de técnicas de aumento de datos que incluyen imágenes tomadas en condiciones climáticas adversas permite que el modelo sea más sólido y confiable en escenarios del mundo real. Este enfoque personalizado garantiza que los detectores personalizados no solo sean precisos sino que también se adapten a una variedad de entornos desafiantes. En la siguiente sección, destacamos un documento revelador que demuestra los resultados que se pueden lograr mediante la personalización de los modelos.
En foco: YOLO adaptable a imágenes para la detección de objetos en condiciones climáticas adversas (2021)
Los modelos generales de detección de objetos entrenados con imágenes de alta calidad a menudo no logran resultados satisfactorios en condiciones climáticas adversas. Además, la aplicación de técnicas de mejora antes de la detección puede lograr una mejor calidad de imagen, pero no necesariamente mejora la detección de objetos. Este documento propone mejorar las imágenes de forma adaptativa para mejorar el rendimiento de la detección de YOLO en condiciones de niebla y poca luz. La canalización propuesta consiste en un predictor de parámetros basado en CNN (CNN-PP), un módulo de procesamiento de imágenes diferenciable (DIP) y una red de detección. El módulo CNN-PP predice los parámetros del módulo DIP a partir de una imagen de baja resolución submuestreada (mediante interpolación bilineal), el módulo DIP se aplica a la imagen de alta resolución para obtener una salida procesada y, por último, se aplica el modelo YOLoV3 a la salida procesada para detectar objetos. [caption id="attachment_3639" align="aligncenter» width="799"]
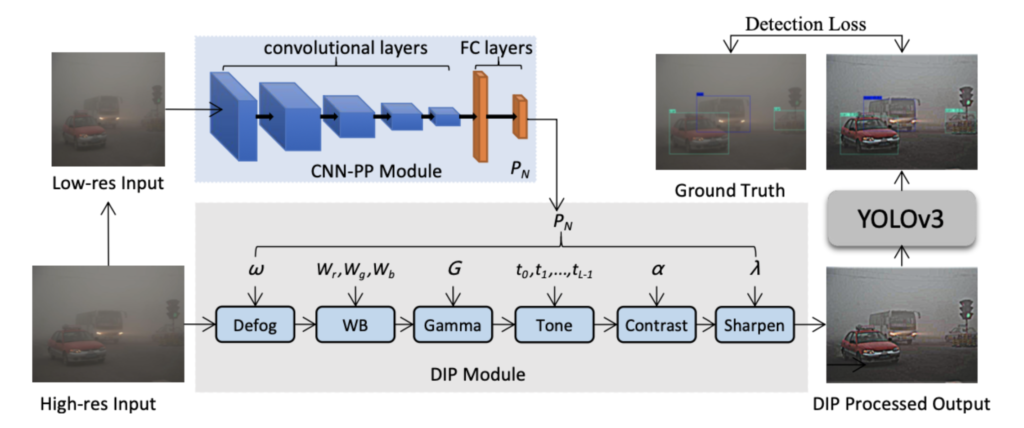
Proceso de formación integral del marco propuesto. [/caption] La siguiente imagen ilustra cómo el preprocesamiento personalizado puede mejorar significativamente la detección de objetos ocultos con esta estrategia. Se muestran los resultados de las salidas procesadas por DIP con combinaciones de filtros antivaho, por píxeles y de nitidez. [caption id="attachment_3640" align="aligncenter» width="597"]

Arriba a la izquierda: resultados de detección de YoloV2 en la imagen original. Arriba a la derecha: resultados de detección de un modelo entrenado con filtros antivaho y por píxeles. Abajo a la izquierda: resultados de detección del modelo entrenado con filtros de nitidez y por píxeles. Abajo a la derecha: resultados de detección del modelo entrenado con filtros antivaho, por píxeles y de nitidez. [/subtítulo]
Preprocesamiento de matrículas salvajes
El objetivo principal de este paso es entregar la mejor imagen de matrícula posible al módulo OCR. Siempre se recomienda el procesamiento previo, pero es obligatorio cuando se trata de imágenes de matrículas de baja calidad, como las que las cámaras de vigilancia toman en entornos salvajes. Pero, ¿por qué es necesario preprocesar la cosecha de las matrículas si ya se ha sometido a la etapa inicial de preprocesamiento? ¿Y qué significa realmente «la mejor imagen de matrícula posible»?
Preprocesamiento de la región de interés
El preprocesamiento local se dirige a regiones específicas de una imagen, como el área que contiene una matrícula. Los parámetros de preprocesamiento se determinan utilizando únicamente los píxeles de la imagen recortada, que es el enfoque adecuado para las tareas que requieren detalles detallados en áreas específicas. Por el contrario, el preprocesamiento global aplica transformaciones en toda la imagen. Si bien este enfoque puede resultar útil para algunas tareas, es menos efectivo en escenarios que requieren precisión en áreas específicas y también puede resultar ineficaz para aplicaciones en tiempo real. Por lo tanto, para evitar pasar por alto las características específicas de la zona de la matrícula, es esencial incorporar un paso de preprocesamiento específico para cada matrícula. Esto es especialmente importante si el módulo de OCR carece de sus propias capacidades de preprocesamiento.
La mejor imagen posible
Cada módulo de OCR tiene requisitos de preprocesamiento específicos para un rendimiento óptimo, por lo que aquellos que incorporan el preprocesamiento incorporado (como Paleta OCR) son generalmente preferibles. Esta variación significa que no hay talla única estándar para lo que constituye una buena imagen de matrícula, pero hay factores clave que son importantes en todos los sistemas de OCR. Las siguientes imágenes se extrajeron de Abrir conjunto de datos ALPR.
- Primera fila: estas imágenes son óptimas para el rendimiento del OCR. Presentan imágenes frontales de láminas enfocadas, prácticamente sin imágenes borrosas, distorsionadas u oclusiones en el texto. La iluminación es uniforme, la exposición es adecuada y hay un alto contraste entre el texto y el fondo, lo que garantiza unos resultados de reconocimiento precisos.
- Segunda fila: estas imágenes muestran escenarios en los que los módulos de OCR pueden seguir funcionando bien a pesar de algunas imperfecciones. Pueden presentar un ligero desenfoque, inclinación, baja resolución, mala iluminación, leves problemas de enfoque y una leve distorsión debido a la perspectiva.
- Tercera fila: estas imágenes, si bien son legibles, son más difíciles para el OCR. Los problemas graves, como la baja resolución, los altos niveles de ruido y el bajo contraste, pueden dificultar el reconocimiento preciso del texto.
[caption id="attachment_3754" align="aligncenter» width="1024"]

La matrícula se recorta del conjunto de datos de OpenALPR. [/caption] En resumen, los sistemas de OCR tienden a lograr un rendimiento óptimo en imágenes que cumplen las siguientes condiciones:
- Iluminación uniforme
- Alto contraste entre el texto y el fondo
- Texto enfocado
- Texto alineado horizontalmente
- Vista frontal
Profundicemos en los pasos de preprocesamiento que podemos aplicar para obtener dichas imágenes.
Tubería tradicional
Un proceso tradicional para el preprocesamiento de matrículas incluiría los siguientes pasos:
- Filtrado gaussiano
- Conversión de RGB a escala de grises
- Binarización
- Operaciones morfológicas
A continuación se muestran dos ejemplos que muestran los resultados de la canalización de preprocesamiento tradicional con parámetros idénticos. Si bien el oleoducto mejora la primera placa, degrada la segunda. [caption id="attachment_3753" align="aligncenter» width="1024"]

Resultados de canalización tradicionales para dos matrículas. [/caption] Este enfoque tradicional puede funcionar bien en ciertas imágenes, pero es probable que no funcione con muchas otras. Además, ajustar los parámetros de esta canalización convencional para obtener resultados óptimos es a la vez difícil y lleva mucho tiempo, ya que a menudo carece de generalización. El uso de técnicas de aprendizaje automático para el preprocesamiento puede ofrecer resultados superiores y abordar de manera eficaz una gama más amplia de desafíos.
Preprocesamiento de matrículas con ML
Se utilizan ampliamente diversas técnicas de aprendizaje automático para el preprocesamiento a fin de mejorar la precisión del OCR. Las redes neuronales convolucionales (CNN) y los codificadores automáticos, en particular, han demostrado un gran rendimiento en las tareas de eliminación de ruido. Podemos capacitarlos específicamente para que limpien y mejoren la calidad de las imágenes de las matrículas del conjunto de datos, lo que permitirá obtener resultados de OCR significativamente mejores.
¿Por qué elegir preprocesadores ML personalizados?
El uso de preprocesadores personalizados para el reconocimiento de matrículas es crucial para ajustar el sistema a fin de gestionar las particularidades del conjunto de datos. Los elementos meteorológicos, como la lluvia, la niebla o el resplandor, pueden ocultar las matrículas y complicar el reconocimiento, mientras que los distintos entornos, como los entornos urbanos o rurales, pueden generar distracciones que confundan a los modelos previamente entrenados. Podemos adaptar los preprocesadores personalizados para abordar estos desafíos en entornos, diseños de matrículas y fuentes específicos. Esto garantiza que el sistema de reconocimiento siga siendo preciso y fiable, lo que mejora el rendimiento general y reduce las tasas de error. En las siguientes subsecciones, presentaremos algunos enfoques avanzados de las técnicas de preprocesamiento para mejorar el rendimiento del OCR, desarrolladas específicamente para la detección de matrículas en imágenes de baja calidad y en condiciones meteorológicas adversas.
Mejora de la superresolución de las matrículas: un enfoque centrado en los personajes y teniendo en cuenta el diseño (2024)
Un problema habitual del OCR en imágenes de baja calidad es que los caracteres se mezclan con el fondo o con los caracteres adyacentes. Para solucionar este problema, los autores desarrollan estrategias para producir imágenes de matrículas que no solo sean de alta calidad y resolución, sino que también puedan identificarse con mayor precisión mediante modelos de OCR. Introducen una novedosa función de pérdida, diseñada para integrar el reconocimiento de caracteres directamente en el proceso de superresolución: la pérdida focal orientada al diseño y a los caracteres (LCOFL), que tiene en cuenta factores como la resolución, la textura y los detalles estructurales. optimizar el proceso de superresolución para mejorar la precisión de la LPR. Además, mejoran el aprendizaje de las características del personaje mediante circunvoluciones deformables y pesos compartidos en un módulo de atención. Emplean un modelo de OCR como factor discriminatorio en una estrategia basada en GAN para guiar y refinar el proceso de superresolución, y entrenan su modelo con pares de imágenes, como se muestra a continuación: [caption id="attachment_3643" align="aligncenter» width="858"]

Entrena a parejas para la estrategia de superresolución basada en GAN. [/caption] Realizan experimentos con el Rodosol-ALPR conjunto de datos, que arroja resultados notables, como se demuestra en la siguiente figura: [caption id="attachment_3644" align="aligncenter» width="842"]

Súper resolución mejorada en imágenes Rodosol-ALPR. [/caption]
SNIDER: Eliminación de ruido y rectificación de una sola imagen ruidosa para mejorar el reconocimiento de matrículas (2019)
La eliminación de ruido y la rectificación de las matrículas tienden a abordarse por separado. Este documento se centra en resolver ambos problemas de manera conjunta, utilizando una subred de eliminación de ruido (DSN) y una subred de rectificación (RSN), ambas con U-Net como columna vertebral. El enfoque propuesto consta de tres partes: eliminación de ruido + rectificación, clasificación por recuento + predicción de segmentos binarios y detección de texto + clasificación. [caption id="attachment_3645" align="aligncenter» width="775"]
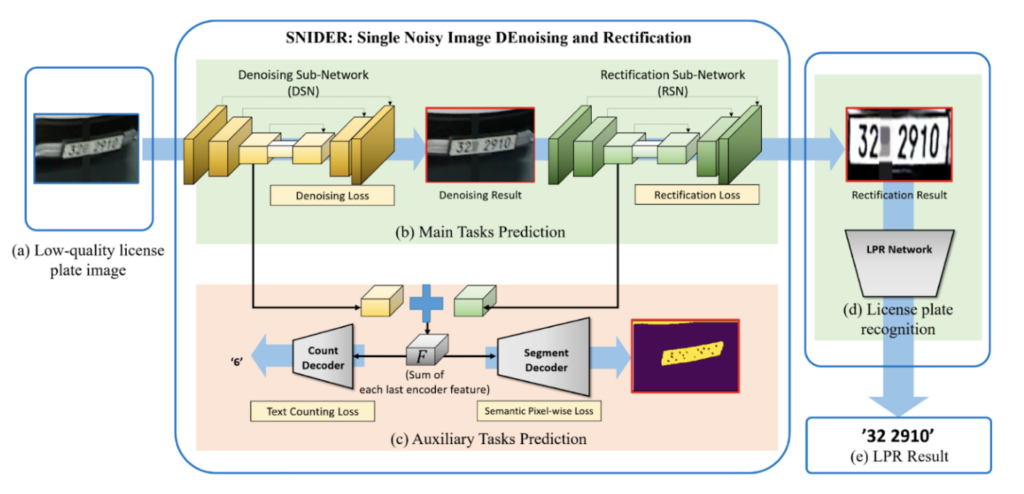
Proceso de entrenamiento y prueba del enfoque SNIDER. [/caption] Proponen utilizar una suma ponderada de las pérdidas como métrica de las pérdidas por entrenamiento, incorporando la rectificación, la eliminación de ruido, la segmentación y el recuento de las pérdidas. Esto garantiza que la red aborde todas estas tareas de manera integral. El documento presenta resultados prometedores, incluida la recuperación de matrículas ilegibles para los humanos, como se muestra a continuación. [caption id="attachment_3646" align="aligncenter» width="817"]

Resultados del estudio de ablación SNIDER. [/subtítulo]
Reconocimiento de texto no tan salvaje
Llegamos aquí con una matrícula muy bien preprocesada, que contenía texto legible y no tan descabellado. En este caso, es muy probable que un marco de OCR general (por ejemplo, Tesseract, EasyOCR, PaddleOCR) genere textos precisos con puntuaciones de reconocimiento altas, y nuestro trabajo termina aquí. Pero si estamos obteniendo puntajes de reconocimiento bajos, debemos continuar con el buen trabajo. [caption id="attachment_3773" align="aligncenter» width="1024"]

Resultados de reconocimiento de diferentes módulos de OCR en dos matrículas preprocesadas. [/caption]
Qué hacer cuando el OCR falla: realizar cambios en el módulo de OCR
Lo primero que hay que probar es ejecutar experimentos con otro módulo de OCR. Como se indicó anteriormente, los diferentes módulos tienen diferentes requisitos de preprocesamiento. Los módulos de OCR que vienen con una función de preprocesamiento integrada son más fáciles de usar y, por lo general, funcionan mejor en una variedad de imágenes. Además, algunos módulos de OCR son más sensibles que otros al preprocesamiento de LP. Esto significa que incluso pequeños ajustes en los parámetros de preprocesamiento pueden provocar cambios significativos en los resultados, lo que constituye un comportamiento indeseable. Tras seleccionar el módulo de OCR que mejor funcione, podemos mejorar su solidez ajustándolo con precisión. Esto permite que el módulo gestione mejor los diseños específicos, las fuentes de texto y las condiciones exclusivas de los datos. También vale la pena explorar el aumento de datos: al añadir efectos como el desenfoque, la inclinación y otros efectos a las imágenes, podemos ayudar a que el modelo sea más sólido a la hora de hacer frente a situaciones difíciles. Cambiar y ajustar la biblioteca de OCR puede mejorar considerablemente el rendimiento con unos ajustes mínimos en el código, pero aun así es muy probable que algunos casos importantes requieran más atención. Para abordar estos casos infrecuentes, es posible que necesitemos revisar y ajustar la etapa de preprocesamiento. Ajustar las técnicas tradicionales de preprocesamiento de imágenes puede llevar bastante tiempo y es posible que no se generalice bien en diferentes escenarios. Para obtener resultados más sólidos en entornos variados, la mejor opción son los procesadores de aprendizaje automático ajustados. Otra estrategia interesante es el uso de una cascada de módulos de OCR. Empezando por el módulo más sencillo y rápido, si no arroja resultados satisfactorios (es decir, devuelve una puntuación de confianza baja o no contiene ningún texto), pasa al siguiente de la secuencia. Los módulos se pueden priorizar en función de su rendimiento y velocidad para alinearlos con los requisitos del sistema ALPR y garantizar tanto la eficiencia como la precisión.
Bonus track: cumplimiento del formato
Al principio, solo podíamos comprobar el cumplimiento (por ejemplo, asegurarnos de que un plato hawaiano se adhiera al AAA-NNN formato) y descartar las detecciones que no cumplan con las normas. Si vamos un paso más allá, también podríamos obligar a la detección a cumplir los requisitos, corrigiendo errores simples de OCR.
Formato básico mediante heurística
El primer enfoque para el formato de detección implica definir dos diccionarios. Un diccionario asigna caracteres a números enteros, mientras que el otro asigna números enteros a caracteres. Se necesitan dos diccionarios, ya que las confusiones entre caracteres y números enteros pueden no ser simétricas. Podemos determinar estos diccionarios con reglas heurísticas, según las confusiones más comunes entre los módulos de OCR. [caption id="attachment_3649" align="aligncenter» width="799"]

Diccionarios para la conversión char/int. [/caption] Por ejemplo, un error frecuente es malinterpretar un «4» con una «A» y viceversa. Si hay una matrícula en el NAA-NNN el formato comienza con una «A», es casi seguro que es un error, y es probable que el carácter correcto sea un «4". [caption id="attachment_3775" align="aligncenter» width="1024"]

Ejemplo de formato para la corrección de errores. [/caption]
Formato avanzado mediante diccionarios personalizados
Si bien la estrategia descrita anteriormente mejora los resultados de manera significativa, se basa en diccionarios generales de confusiones de OCR en diversos conjuntos de datos. Estos diccionarios no tendrán en cuenta que los tipos de fuente específicos pueden evitar o generar confusiones específicas. Por ejemplo, las matrículas del Mercosur tienen una «D» que se parece a una «O», lo que provoca errores de reconocimiento en algunos módulos de OCR. Por lo tanto, una estrategia de formato avanzada debe incluir diccionarios personalizados para cada fuente de matrícula. Podemos implementar esta estrategia avanzada de la siguiente manera:
- Clasifica las matrículas: clasifíquelos según su diseño (por ejemplo, Nevada, Hawái).
- Ejecutar detección de texto: identificar y extraer texto de las láminas.
- Crear matrices de confusión: compare el texto detectado con la verdad básica para crear matrices de confusión para cada diseño y comprender los problemas de reconocimiento de caracteres de cada clase.
- Generar los diccionarios: crear diccionarios para cada clase de matrícula, centrándose en las confusiones comunes entre caracteres y números enteros identificadas en las matrices.
Conclusiones
En este blog, hemos destacado la importancia de desarrollar canalizaciones de ALPR que puedan gestionar eficazmente imágenes desafiantes en entornos salvajes, donde la solidez es fundamental. Este enfoque ayuda a minimizar el impacto de los eventos incontrolables en la precisión. Hemos presentado tres arquitecturas versátiles que se utilizan habitualmente en el ALPR, cada una de las cuales se adapta a las distintas entradas de la cámara y a los requisitos del sistema. Cuando trabajamos con vídeo, podemos emplear estrategias de reconocimiento de vehículos para obtener la imagen más nítida de la matrícula de cada vehículo. Además, hemos analizado la importancia de ajustar con precisión las estrategias del detector, el preprocesador y el OCR para garantizar que cada paso sea compatible de forma óptima con el siguiente y, en última instancia, aumentar la precisión. También analizamos cómo la implementación de estrategias de aumento de datos puede mejorar en gran medida la solidez del sistema. Por último, hemos demostrado cómo un clasificador de matrículas puede utilizar el conocimiento de los estándares de formato para corregir errores comunes a partir de matrices de confusión personalizadas, lo que mejora aún más la precisión y la fiabilidad.
Referencias
- PP-OCR: un práctico sistema de OCR ultraligero
- Autoblog: A partir de marzo se empadronará con la patente Mercosur
- Reconocimiento de matrículas en imágenes de baja calidad mediante Latent Diffusion YOLov7
- Una evaluación justa de varios enfoques de binarización de imágenes de documentos basados en el aprendizaje profundo
- Detección y reconocimiento de matrículas en tiempo real mediante redes neuronales convolucionales profundas
- Un enfoque basado en la CNN para el reconocimiento automático de matrículas en la naturaleza
- Detección y reconocimiento de matrículas en escenarios sin restricciones
- Mejora de la superresolución de las matrículas: un enfoque centrado en los personajes y teniendo en cuenta el diseño (2024)
- SNIDER: Eliminación de ruido y rectificación de una sola imagen ruidosa para mejorar el reconocimiento de matrículas
- Abrir ALPR
- Rodosol-ALPR
- Base de datos LPR
- Detección y reconocimiento de matrículas con YOLO V8 EasyOCR



.png)