.png)
Dominando o reconhecimento automático de placas de veículos em ambientes selvagens




Introdução
O reconhecimento automático de placas de veículos (ALPR) se refere à tarefa de extrair com precisão as informações da placa de veículos de uma variedade de fontes visuais, que podem variar de imagens estáticas de alta resolução a transmissões de vídeo em tempo real de câmeras de vigilância. [caption id="attachment_3632" align="aligncenter” width="512"]

Exemplo de tarefa ALPR. [/caption] As aplicações do ALPR são amplas e impactantes. Os sistemas ALPR são usados para identificar veículos roubados, rastrear suspeitos e gerenciar a fiscalização do estacionamento. Eles também desempenham um papel crucial nos sistemas de cobrança de pedágio, melhorando o fluxo de tráfego automatizando os pagamentos e reduzindo o congestionamento nas cabines de pedágio. Além disso, a tecnologia ALPR é usada em segurança e vigilância, ajudando a monitorar e controlar o acesso a áreas seguras por meio do reconhecimento de veículos autorizados.
ALPR na natureza
Ao lidar com boas imagens, a tarefa do ALPR está praticamente resolvida: a maioria dos modelos de última geração pode facilmente alcançar alta precisão. Mas ambientes selvagens são imprevisíveis por definição. Mesmo quando projetamos e implantamos a configuração perfeita da câmera, condições climáticas como chuva, neblina ou brilho podem obscurecer as placas e complicar o reconhecimento. Portanto, ao desenvolver tubulações para aplicações de ALPR em ambientes selvagens, precisamos fazer medições para manter a precisão mesmo em condições adversas.
[caption id="attachment_3757" align="aligncenter” width="1024"]

Alguns exemplos do que chamaremos de “ambientes selvagens” ao longo deste blog, extraídos do banco de dados OpenALPR e LPR. [/legenda]
Requisitos usuais
A implementação de um sistema eficaz de reconhecimento automático de placas de veículos (ALPR) envolve vários requisitos importantes, sendo a precisão crucial. Para conseguir isso, o hardware normalmente precisa de equipamentos de imagem de alta qualidade capazes de capturar imagens nítidas e detalhadas de placas de veículos em várias condições. No entanto, em muitos cenários, as câmeras já estão instaladas para outros fins, como vigilância. Aproveitar essas configurações preexistentes pode ser vantajoso, mas requer um pipeline robusto que possa lidar com desafios como imagens desfocadas e de baixa resolução sem comprometer a precisão. Os requisitos se tornam ainda mais exigentes quando se opera em ambientes do mundo real. A configuração da câmera deve ser estável o suficiente para permanecer imóvel em condições de vento. Por outro lado, o pipeline de processamento deve ser capaz de gerenciar imagens de baixa qualidade. Os aplicativos em tempo real também têm restrições de tempo, exigindo câmeras rápidas e um canal de processamento eficiente.
Sistemas ALPR personalizados
Os sistemas ALPR gerais são projetados para fornecer resultados satisfatórios em uma ampla variedade de ambientes. Por outro lado, os sistemas personalizados podem ser personalizados especificamente para atender a necessidades específicas, seja para segurança, gerenciamento de estacionamento ou monitoramento de tráfego. Essa abordagem personalizada permite o ajuste fino dos modelos, melhorando significativamente a precisão ao otimizar o desempenho para ambientes específicos. Além disso, sistemas personalizados podem se integrar à infraestrutura e ao software existentes, garantindo a escalabilidade à medida que os requisitos evoluem. Além disso, eles oferecem a capacidade de implementar medidas específicas de proteção de dados, atendendo efetivamente às necessidades de conformidade. Neste blog, exploraremos as etapas essenciais dos pipelines ALPR personalizados que lidam com imagens desafiadoras e de alta qualidade capturadas em ambientes selvagens.
Arquiteturas usuais
Arquitetura v1
Uma primeira abordagem envolve trabalhar em uma imagem única e clara do veículo, onde a placa é visível e legível. Um pipeline básico para obter o texto incluiria as seguintes etapas: [caption id="attachment_3634" align="aligncenter” width="934"]

Uma primeira arquitetura ALPR. [/legenda]
- Aquisição de imagens: capture uma imagem de um carro/placa de carro.
- Pré-processamento de imagens: prepare a imagem para melhorar os resultados de detecção de placas de veículos.
- Detecção de matrículas: localize as placas dentro da imagem.
- Pré-processamento de placas de veículos: prepare a imagem da placa do carro para melhorar os resultados do reconhecimento de texto.
- Reconhecimento óptico de caracteres (OCR): extraia o texto das placas.
Embora essa primeira abordagem seja direta, sua robustez é limitada por sua forte dependência da qualidade da imagem adquirida e da adequação da etapa de pré-processamento. Se a imagem adquirida for uma imagem nítida e aproximada da placa do carro, as etapas subsequentes geralmente enfrentarão menos ou nenhum desafio para retornar os melhores resultados. Podemos obter essa imagem de alta qualidade posicionando estrategicamente uma câmera bem escolhida. No entanto, é sabido que ambientes selvagens são afetados por fatores incontroláveis, como condições climáticas, mudanças de iluminação, erro humano e outras circunstâncias imprevistas que afetam a aquisição, mesmo com uma configuração de câmera perfeita. Por esse motivo, é crucial ter um pipeline de pré-processamento robusto sob nossa manga! Há esforços contínuos na literatura com o objetivo de abordar essas situações aprimorando a fase de pré-processamento, que serão discutidas posteriormente neste blog.
Arquitetura v2: uma arquitetura com reconhecimento de formato
Os conjuntos de dados de placas de veículos geralmente são coletados de veículos de um país, estado ou região específicos. Consequentemente, o desafio geralmente envolve

está reconhecendo texto em placas de veículos que aderem a um formato ou classe específico e geralmente são muito diferentes umas das outras. Por exemplo, um conjunto de dados de placas dos EUA pode incluir placas de Nevada, com texto preto sobre fundo azul-celeste e montanhas verdes/laranja na parte inferior. Essas placas seguem o NNN-ANN formato, onde “NÃO” representa um número e “UM” uma carta. Em contraste, as placas havaianas, caracterizadas por seu fundo arco-íris e pelo formato AAA-NNN, se destacam claramente das de Nevada. Um modelo de aprendizado de máquina pode capturar e diferenciar com eficácia esses recursos exclusivos, permitindo a identificação precisa das placas de cada estado. Os layouts e formatos de placas de veículos são mais conhecidos, portanto, os textos detectados podem ser forçados a cumprir seu padrão correspondente. Para implementar isso, uma arquitetura mais avançada incluiria duas etapas adicionais: [caption id="attachment_3636" align="aligncenter” width="813"]

Uma arquitetura ALPR com reconhecimento de formato. [/legenda]
- Classificação da placa de licença: classifique as placas detectadas com base em layouts previamente conhecidos, que podem variar de acordo com a localização geográfica ou jurisdição (por exemplo, país, estado ou formatos internacionais).
- Formatação de texto: converta o texto extraído em um formato padronizado, apropriado para cada classe de placa (por exemplo, Mercosul ou estados específicos dos EUA).
Arquitetura v3: aproveitando o vídeo
As imagens de placas de veículos geralmente são capturadas por câmeras de vigilância, resultando em imagens de vídeo em vez de imagens únicas. Esses vídeos fornecem várias imagens do mesmo veículo e placa de várias distâncias, condições de iluminação e ângulos, aprimorando significativamente a robustez da detecção de texto. Para integrar essas informações de forma eficaz, uma arquitetura típica incluiria as seguintes etapas adicionais: [caption id="attachment_3637" align="aligncenter” width="992"]
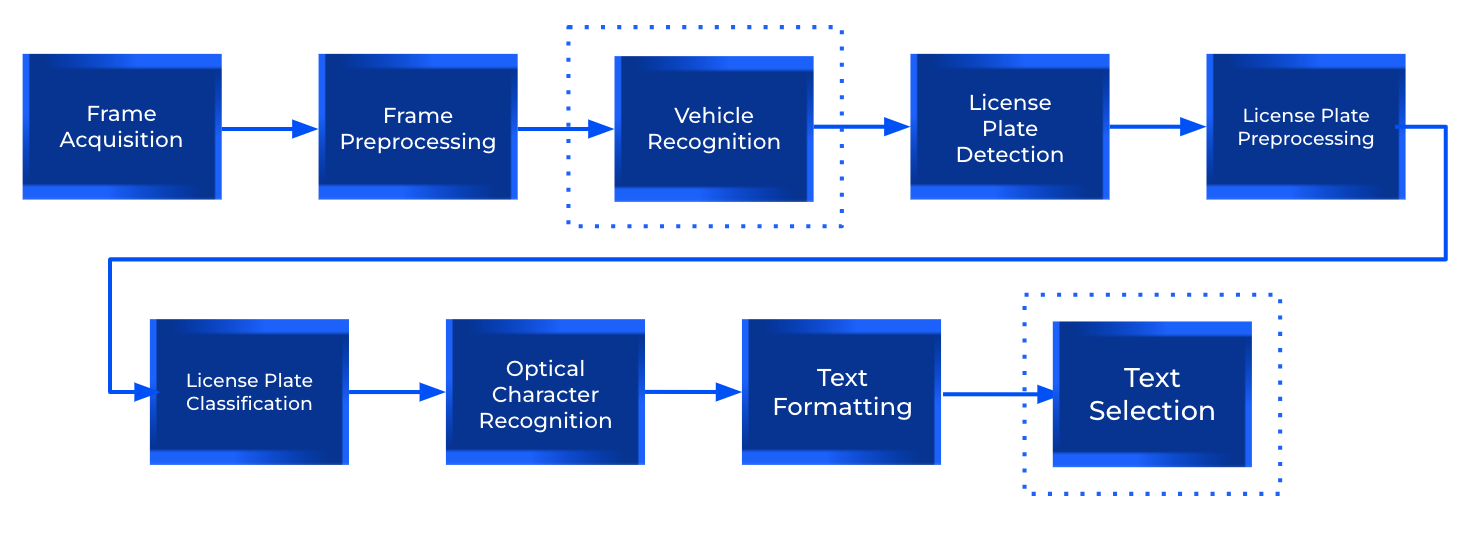
Uma arquitetura ALPR com reconhecimento de formato para filmagens de vídeo. [/legenda]
- Reconhecimento de veículos: identifique e rastreie veículos dentro de cada quadro, agrupando várias detecções do mesmo veículo.
- Seleção de texto: escolha o texto da placa de carro mais preciso dos candidatos em potencial. Essa decisão pode ser baseada em pontuações de confiança de detecção e classificação, confiança no reconhecimento de texto e conformidade com o formato esperado. Como alternativa, poderíamos selecionar cada personagem individualmente, usando o que ocorre com mais frequência nos quadros do mesmo veículo.
Portanto, se houver pelo menos uma imagem nítida da placa de cada veículo, essa abordagem pode atribuir com precisão o texto da placa a cada um, sem exigir um pré-processamento extensivo. [caption id="attachment_3759" align="aligncenter” width="1024"]

Exemplo de detecção de vídeo. Quadros extraídos de Vídeo de ilustração da câmera de matrícula.[/legenda]
Detectando placas de veículos selvagens
Ser capaz de extrair uma imagem recortada de uma placa de carro é claramente uma etapa essencial. Isso inclui verificar a presença de uma placa e, se encontrada, retornar as coordenadas da caixa delimitadora junto com uma pontuação de confiança.
Detectores pré-treinados
Os detectores pré-treinados oferecem uma solução rápida e eficiente para o reconhecimento de placas de veículos com o mínimo esforço de codificação, tornando-os uma opção atraente para muitas aplicações. Eles são projetados para identificar rapidamente o texto em regiões retangulares, o que pode ser vantajoso para um desenvolvimento rápido. No entanto, esses detectores às vezes podem identificar incorretamente o texto em retângulos que não são placas de veículos, levando a falsos positivos. Além disso, eles podem ter dificuldades em condições específicas, como iluminação deficiente, condições climáticas extremas ou ambientes complexos, onde seu desempenho pode ser significativamente comprometido. Consequentemente, embora os detectores pré-treinados ofereçam um ponto de partida sólido, suas limitações em determinados cenários podem exigir personalização adicional ou abordagens alternativas para garantir um reconhecimento confiável em diversos ambientes. As imagens a seguir correspondem aos resultados de detecção com o detector YOLO sobre imagens extraídas de Abrir ALPR conjunto de dados. [caption id="attachment_3764" align="aligncenter” width="1024"]

Resultados de detecção com o detector YOLO sobre imagens extraídas do conjunto de dados OpenALPR [/caption] Os exemplos acima ilustram que, embora os detectores gerais funcionem bem em muitas situações, eles geralmente têm dificuldades quando há um texto no veículo que não corresponde a uma placa. Além disso, a pontuação de detecção geralmente excede os níveis desejados quando o texto que não é da placa é identificado erroneamente como uma placa de licença. Isso o torna um indicador não confiável. Felizmente, podemos minimizar esses falsos positivos por meio do ajuste fino do modelo.
Por que detectores personalizados?
Os detectores personalizados oferecem vantagens significativas ao aproveitar informações específicas sobre layouts de placas de veículos, o que aprimora a precisão do reconhecimento. Além disso, a incorporação de técnicas de aumento de dados que incluem imagens tiradas em condições climáticas adversas permite que o modelo se torne mais robusto e confiável em cenários do mundo real. Essa abordagem personalizada garante que os detectores personalizados não sejam apenas precisos, mas também adaptáveis a uma variedade de ambientes desafiadores. Na seção a seguir, destacamos um artigo esclarecedor que demonstra os resultados alcançáveis por meio da personalização do modelo.
Em foco: YOLO adaptável à imagem para detecção de objetos em condições climáticas adversas (2021)
Modelos gerais de detecção de objetos treinados em imagens de alta qualidade geralmente não conseguem obter resultados satisfatórios em condições climáticas adversas. Além disso, aplicar técnicas de aprimoramento antes da detecção pode obter uma melhor qualidade de imagem, mas não necessariamente melhora a detecção de objetos. Este artigo propõe aprimorar imagens de forma adaptável para melhorar o desempenho de detecção do YOLO em condições de neblina e pouca luz. O pipeline proposto consiste em um preditor de parâmetros baseado em CNN (CNN-PP), um módulo de processamento de imagem diferenciável (DIP) e uma rede de detecção. O módulo CNN-PP prevê os parâmetros do módulo DIP a partir de uma imagem de baixa resolução reduzida (via interpolação bilinear), o módulo DIP é aplicado à imagem de alta resolução para obter uma saída processada e, finalmente, o modelo YOLOv3 é aplicado na saída processada para detectar objetos. [caption id="attachment_3639" align="aligncenter” width="799"]
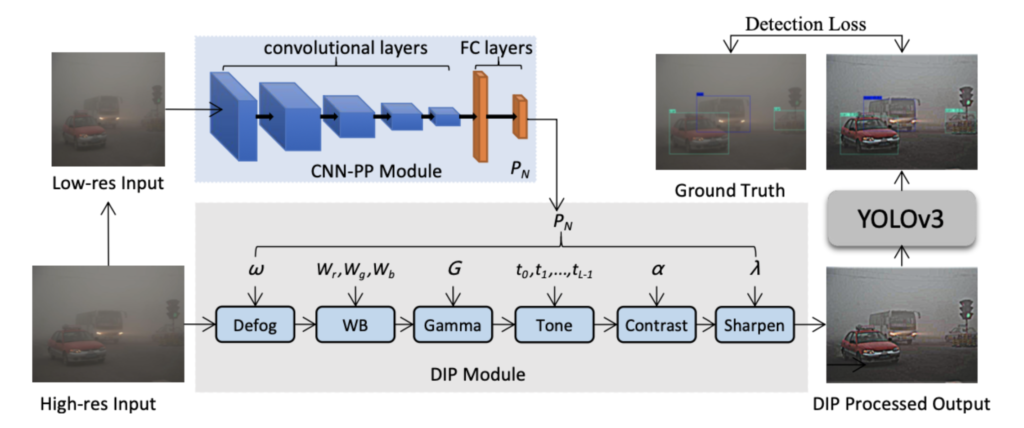
Pipeline de treinamento de ponta a ponta da estrutura proposta. [/caption] A imagem abaixo ilustra como o pré-processamento personalizado pode aprimorar significativamente a detecção de objetos obscurecidos usando essa estratégia. Os resultados são mostrados para saídas processadas por DIP com combinações de filtros de desembaçamento, pixels e nitidez. [caption id="attachment_3640" align="aligncenter” width="597"]

Canto superior esquerdo: resultados de detecção de YOLOv2 na imagem original. Canto superior direito: resultados de detecção para um modelo treinado com filtros de desembaçamento e pixels. Canto inferior esquerdo: resultados de detecção para um modelo treinado com filtros de nitidez e pixels. Canto inferior direito: resultados de detecção para um modelo treinado com filtros de desembaçamento, pixel e nitidez. [/legenda]
Pré-processamento de placas de veículos selvagens
O objetivo principal desta etapa é fornecer a melhor imagem possível da placa de licença ao módulo OCR. O pré-processamento é sempre recomendado, mas se torna obrigatório ao lidar com imagens de placas de veículos de baixa qualidade, como aquelas tiradas em ambientes selvagens por câmeras de vigilância. Mas por que é necessário pré-processar a colheita da placa, se ela já passou pela etapa inicial de pré-processamento? E o que realmente significa “melhor imagem possível de placa de carro”?
Pré-processamento da região de interesse
O pré-processamento local tem como alvo regiões específicas de uma imagem, como a área que contém uma placa de carro. Os parâmetros de pré-processamento são determinados usando somente pixels na imagem recortada, que é a abordagem adequada para tarefas que exigem detalhes refinados em áreas específicas. Em contraste, o pré-processamento global aplica transformações em toda a imagem. Embora essa abordagem possa ser útil para algumas tarefas, ela é menos eficaz em cenários que exigem precisão em áreas específicas e também pode ser ineficiente para aplicativos em tempo real. Portanto, para evitar ignorar as características específicas da área da placa, incorporar uma etapa de pré-processamento específica da placa é essencial. Isso é especialmente importante se o módulo OCR não tiver seus próprios recursos de pré-processamento.
Melhor imagem possível
Cada módulo de OCR tem requisitos específicos de pré-processamento para um desempenho ideal, portanto, aqueles que incorporam o pré-processamento integrado (como Paddle OCR) geralmente são preferíveis. Essa variação significa que não há um tamanho único padrão para o que constitui uma boa imagem de placa de carro, mas existem fatores-chave que são importantes em todos os sistemas de OCR. As seguintes imagens foram extraídas de Conjunto de dados OpenALPR.
- Primeira fila: essas imagens são ideais para desempenho de OCR. Eles apresentam vistas frontais de placas que estão em foco, quase livres de borrões, distorções ou oclusões no texto. A iluminação é uniforme, a exposição é adequada e há alto contraste entre o texto e o fundo, garantindo resultados de reconhecimento precisos.
- Segunda fila: essas imagens apresentam cenários em que os módulos de OCR ainda podem funcionar bem, apesar de algumas imperfeições. Eles podem apresentar um leve desfoque, inclinação, baixa resolução, iluminação deficiente, pequenos problemas de foco e pequena distorção devido à perspectiva.
- Terceira fila: essas imagens, embora legíveis, são mais desafiadoras para o OCR. Problemas graves, como baixa resolução, altos níveis de ruído e baixo contraste, podem impedir o reconhecimento preciso do texto.
[caption id="attachment_3754" align="aligncenter” width="1024"]

Placas de licença do conjunto de dados OpenALPR. [/caption] Resumindo, os sistemas de OCR tendem a atingir o desempenho ideal em imagens que atendem às seguintes condições:
- Iluminação uniforme
- Alto contraste entre texto e fundo
- Texto em foco
- Texto alinhado horizontalmente
- Visão frontal
Vamos nos aprofundar nas etapas de pré-processamento que podemos aplicar para obter essas imagens.
Pipeline tradicional
Um pipeline tradicional para o pré-processamento de placas de veículos incluiria as seguintes etapas:
- Filtragem gaussiana
- Conversão de RGB para tons de cinza
- Binarização
- Operações morfológicas
Abaixo estão dois exemplos que demonstram os resultados do pipeline de pré-processamento tradicional usando parâmetros idênticos. Enquanto o oleoduto aprimora a primeira placa, ele degrada a segunda. [caption id="attachment_3753" align="aligncenter” width="1024"]

Resultados tradicionais de oleodutos para duas placas de veículos. [/caption] Essa abordagem tradicional pode funcionar bem em certas imagens, mas é provável que falhe em muitas outras. Além disso, ajustar os parâmetros desse pipeline convencional para obter resultados ideais é desafiador e demorado, muitas vezes sem generalização. O emprego de técnicas de aprendizado de máquina para pré-processamento pode oferecer resultados superiores e abordar com eficácia uma gama mais ampla de desafios.
Pré-processamento de placas de veículos com ML
Várias técnicas de aprendizado de máquina são amplamente usadas para pré-processamento para melhorar a precisão do OCR. Redes neurais convolucionais (CNNs) e codificadores automáticos, em particular, demonstraram ótimo desempenho em tarefas de eliminação de ruído. Podemos treiná-los especificamente para limpar e melhorar a qualidade das imagens de placas de veículos no conjunto de dados, resultando em resultados de OCR significativamente melhores.
Por que pré-processadores de ML personalizados?
Usar pré-processadores personalizados para reconhecimento de placas de veículos é crucial para ajustar o sistema para lidar com as particularidades do conjunto de dados. Elementos climáticos, como chuva, neblina ou brilho, podem obscurecer as placas e complicar o reconhecimento, enquanto origens variadas, como ambientes urbanos ou rurais, podem causar distrações que confundem modelos pré-treinados. Podemos personalizar pré-processadores personalizados para enfrentar esses desafios em ambientes, layouts de placas e fontes específicos. Isso garante que o sistema de reconhecimento permaneça preciso e confiável, melhorando o desempenho geral e reduzindo as taxas de erro. Nas subseções a seguir, apresentaremos algumas abordagens de última geração para técnicas de pré-processamento para melhorar o desempenho do OCR, desenvolvidas especificamente para detecção de placas de veículos em imagens de baixa qualidade e condições climáticas adversas.
Aprimorando a superresolução de placas de veículos: uma abordagem baseada em caracteres e com reconhecimento de layout (2024)
Um desafio comum do OCR em imagens de baixa qualidade é a mistura de caracteres com o plano de fundo ou caracteres adjacentes. Para resolver isso, os autores desenvolvem estratégias para produzir imagens de placas de veículos que não sejam apenas de alta qualidade e resolução, mas também identificáveis com mais precisão pelos modelos de OCR. Eles introduzem uma nova função de perda, projetada para integrar o reconhecimento de caracteres diretamente ao processo de super-resolução: a Layout and Character Oriented Focal Loss (LCOFL), que explica fatores como resolução, textura e detalhes estruturais, otimizando o processo de super-resolução para melhorar a precisão do LPR. Além disso, eles aprimoram o aprendizado de características do personagem por meio de convoluções deformáveis e pesos compartilhados em um módulo de atenção. Eles empregam um modelo de OCR como discriminador em uma estratégia baseada em GaN para guiar e refinar o processo de super-resolução e treinam seu modelo usando pares de imagens, conforme mostrado abaixo: [caption id="attachment_3643" align="aligncenter” width="858"]

Pares de treinamento para a estratégia de super-resolução baseada em GaN. [/caption] Eles conduzem experimentos no Rodosol-ALPR conjunto de dados, produzindo resultados notáveis, conforme demonstrado na figura a seguir: [caption id="attachment_3644" align="aligncenter” width="842"]

Superresolução aprimorada em imagens Rodosol-ALPR. [/legenda]
SNIDER: eliminação de ruído e retificação de imagens ruidosas únicas para melhorar o reconhecimento de placas de veículos (2019)
A eliminação de ruído e a retificação de placas de veículos tendem a ser tratadas separadamente. Este artigo se concentra em resolver os dois problemas em conjunto, usando uma sub-rede de eliminação de ruído (DSN) e uma sub-rede de retificação (RSN), ambas tendo a U-Net como backbone. A abordagem proposta consiste em três partes: eliminação de ruído + retificação, classificação de contagem + predição de segmento binário e detecção de texto + classificação. [caption id="attachment_3645" align="aligncenter” width="775"]
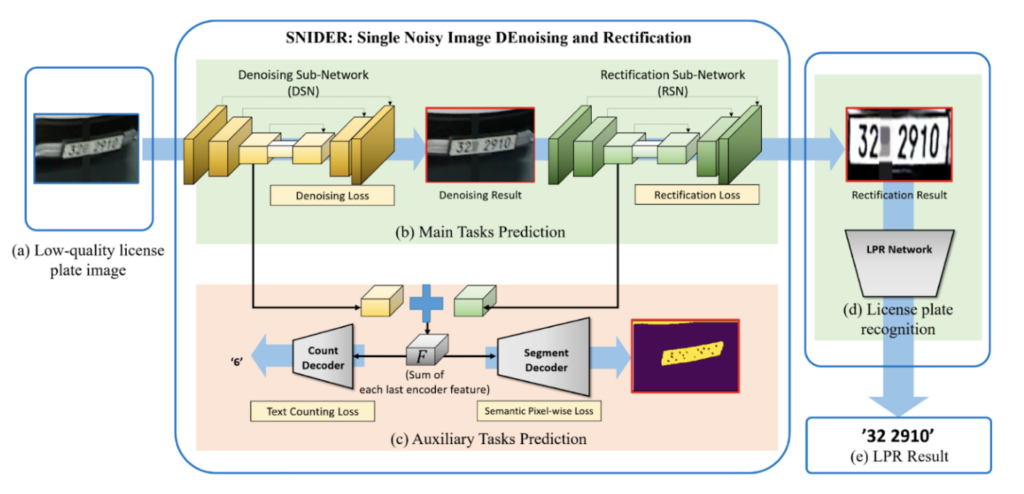
Processo de treinamento e teste da abordagem SNIDER. [/caption] Eles propõem usar uma soma ponderada de perdas como métrica de perda de treinamento, incorporando retificação, eliminação de ruído, segmentação e contagem de perdas. Isso garante que a rede aborde todas essas tarefas de forma abrangente. O artigo apresenta resultados promissores, incluindo a recuperação de placas ilegíveis para humanos, conforme mostrado abaixo. [caption id="attachment_3646" align="aligncenter” width="817"]

Resultados do estudo de ablação SNIDER. [/legenda]
Reconhecendo textos não tão selvagens
Chegamos aqui com uma placa de carro bem pré-processada, contendo um texto legível e não tão selvagem. Nesse caso, é muito provável que uma estrutura geral de OCR (por exemplo, Tesseract, EasyOCR, PaddleOCR) produza textos precisos com altas pontuações de reconhecimento, e nosso trabalho termina aqui. Mas se estamos obtendo pontuações de reconhecimento baixas, precisamos continuar com o bom trabalho. [caption id="attachment_3773" align="aligncenter” width="1024"]

Resultados de reconhecimento de diferentes módulos de OCR em duas placas pré-processadas. [/legenda]
O que fazer quando o OCR falha: fazer alterações no módulo OCR
A primeira coisa a experimentar é fazer experimentos com outro módulo de OCR. Conforme mencionado anteriormente, módulos diferentes têm diferentes requisitos de pré-processamento. Os módulos de OCR que vêm com um recurso de pré-processamento integrado são mais fáceis de usar e geralmente têm melhor desempenho em uma variedade de imagens. Além disso, alguns módulos de OCR são mais sensíveis do que outros ao pré-processamento de LP. Isso significa que mesmo pequenos ajustes nos parâmetros de pré-processamento podem levar a mudanças significativas nos resultados, o que é um comportamento indesejável. Depois de selecionar o módulo de OCR com melhor desempenho, podemos aprimorar sua robustez ajustando-o. Isso permite que o módulo gerencie melhor layouts específicos, fontes de texto e condições exclusivas dos dados. Também vale a pena explorar o aumento de dados: ao adicionar efeitos como desfoque, inclinação e outros artefatos às imagens, podemos ajudar o modelo a se tornar mais robusto ao lidar com situações desafiadoras. Alterar e ajustar a biblioteca de OCR pode aumentar significativamente o desempenho com ajustes mínimos de código, mas ainda é muito provável que alguns casos importantes precisem de atenção extra. Para resolver esses casos selvagens, talvez precisemos revisitar e ajustar o estágio de pré-processamento. Ajustar as técnicas tradicionais de pré-processamento de imagens pode ser muito demorado e pode não se generalizar bem em diferentes cenários. Para obter resultados mais robustos em ambientes variados, processadores de aprendizado de máquina aperfeiçoados são a melhor escolha. Outra estratégia interessante é o uso de uma cascata de módulos de OCR. Começando com o módulo mais simples e rápido, se ele não produzir resultados satisfatórios (ou seja, retornar uma baixa pontuação de confiança de texto ou nenhum texto), vá para o próximo na sequência. Os módulos podem ser priorizados com base em seu desempenho e velocidade para se alinharem aos requisitos do sistema ALPR, garantindo eficiência e precisão.
Faixa bônus: aplicação da conformidade de formatos
Inicialmente, poderíamos apenas verificar a conformidade (por exemplo, garantir que uma placa havaiana adira ao AAA-NNN formato) e descarte as detecções que não estão em conformidade. Dando um passo adiante, também podemos forçar a detecção a ser cumprida, corrigindo erros simples de OCR.
Formatação básica usando heurística
A primeira abordagem para a formatação de detecção envolve a definição de dois dicionários. Um dicionário mapeia caracteres para números inteiros, enquanto o outro mapeia números inteiros de volta para caracteres. São necessários dois dicionários, pois as confusões entre caracteres e números inteiros podem não ser simétricas. Podemos determinar esses dicionários com regras heurísticas, de acordo com as confusões comuns entre os módulos de OCR. [caption id="attachment_3649" align="aligncenter” width="799"]

Dicionários para conversão de char/int. [/caption] Por exemplo, um erro frequente é interpretar erroneamente um “4" como um “A” e vice-versa. Se uma placa de licença no NAA-NNN o formato começa com um “A”, quase certamente é um erro, com o caractere correto provavelmente sendo um “4". [caption id="attachment_3775" align="aligncenter” width="1024"]

Exemplo de formatação para correção de erros. [/legenda]
Formatação avançada usando dicionários personalizados
Embora a estratégia descrita acima melhore significativamente os resultados, ela se baseia em dicionários gerais de confusões de OCR em diversos conjuntos de dados. Esses dicionários não levam em conta que tipos específicos de fonte podem evitar ou causar confusões específicas. Por exemplo, as placas do Mercosul apresentam um “D” que se assemelha a um “O”, causando erros de reconhecimento em alguns módulos de OCR. Portanto, uma estratégia de formatação avançada deve incluir dicionários personalizados para cada fonte de matrícula. Podemos implementar essa estratégia avançada da seguinte forma:
- Classifique placas de veículos: categorize-os com base em seu layout (por exemplo, Nevada, Havaí).
- Executar detecção de texto: identifique e extraia o texto das placas.
- Crie matrizes de confusão: compare o texto detectado com a verdade básica, para criar matrizes de confusão para cada layout e entender os problemas de reconhecimento de caracteres em cada classe.
- Gere os dicionários: crie dicionários para cada classe de matrícula, concentrando-se nas confusões comuns de caracteres inteiros identificadas nas matrizes.
Conclusões
Neste blog, destacamos a importância de desenvolver pipelines ALPR que possam lidar com imagens desafiadoras com eficácia em ambientes selvagens, onde a robustez é fundamental. Essa abordagem ajuda a minimizar o impacto de eventos incontroláveis na precisão. Apresentamos três arquiteturas versáteis comumente usadas para ALPR, cada uma adaptável a várias entradas de câmera e requisitos do sistema. Ao trabalhar com vídeo, podemos empregar estratégias de reconhecimento de veículos para extrair a imagem mais nítida da placa de cada veículo. Além disso, exploramos a importância de estratégias de ajuste fino para o detector, o pré-processador e o OCR para garantir que cada etapa ofereça suporte ideal à próxima, aumentando a precisão. Também discutimos como a implementação de estratégias de aumento de dados pode aumentar consideravelmente a robustez do sistema. Por fim, mostramos como um classificador de placas de veículos pode usar o conhecimento dos padrões de formato para corrigir erros comuns de matrizes de confusão personalizadas, melhorando ainda mais a precisão e a confiabilidade.
Referências
- PP-OCR: um sistema OCR prático e ultraleve
- Autoblog: A partir de março será empatronado com a patente Mercosul
- Reconhecimento de matrículas em imagens de baixa qualidade usando difusão latente YOLOv7
- Uma avaliação justa de várias abordagens de binarização de imagens de documentos baseadas em aprendizado profundo
- Detecção e reconhecimento de placas de veículos em tempo real usando redes neurais convolucionais profundas
- Uma abordagem baseada na CNN para reconhecimento automático de placas de veículos na natureza
- Detecção e reconhecimento de placas de veículos em cenários irrestritos
- Aprimorando a superresolução de placas de veículos: uma abordagem baseada em caracteres e com reconhecimento de layout (2024)
- SNIDER: Remoção de ruído e retificação de imagens ruidosas únicas para melhorar o reconhecimento de placas de veículos
- Abrir ALPR
- Rodosol-ALPR
- Banco de dados LPR
- Detecção e reconhecimento de placas usando o YOLO V8 EasyOCR



.png)