
Tutorial do Vertex AI + Kubeflow




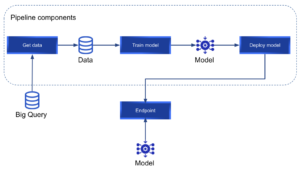
Normalmente, levar um modelo de ML do ambiente de experimentação para a produção consome muito tempo e recursos. A Vertex AI facilita o treinamento, a implantação e a comparação dos resultados do modelo. É uma excelente ferramenta que nos permite focar em soluções de ML em vez de gerenciamento de infraestrutura. Na postagem a seguir, vamos nos aprofundar em IA Vertex. Este é um guia passo a passo para definir um Kubeflow pipeline que implantará um modelo de ML personalizado usando o Vertex ai e, em seguida, fará inferências em tempo real com o modelo implantado. Vamos treinar nosso modelo usando um conjunto de dados público sobre crimes em Chicago; no entanto, o modelo não será o foco do tutorial e, no final, você poderá criar seus próprios pipelines para implantar qualquer modelo personalizado no Vertex AI. Você pode encontrar o código usado ao longo deste tutorial em este repositório Github. Ao final do tutorial, queremos alcançar o seguinte pipeline:
O que é o Vertex AI?
Se dermos uma olhada no AI oficial da Vertex página da web:
[perfectpullquote align="full” bordertop="false” cite= "” link= "” color= "” class= "” size=" "]" A Vertex AI reúne os serviços do Google Cloud para criar ML em uma interface de usuário e API unificadas. No Vertex AI, agora você pode facilmente treinar e comparar modelos usando AutoML ou treinamento de código personalizado, e todos os seus modelos são armazenados em um repositório central de modelos. Esses modelos agora podem ser implantados nos mesmos endpoints no Vertex AI.” [/perfect pullquote]
Eles mencionam que podemos “treine e compare modelos usando AutoML ou treinamento de código personalizado”. Este tutorial se concentrará no treinamento de código personalizado em vez do AutoML. A Vertex AI nos permite executar pipelines usando o Kubeflow ou o Tensorflow Extended (TFX). No nosso caso, usaremos o Kubeflow para definir nosso pipeline personalizado. Vamos nos referir ao conceito de “pipeline” com frequência neste tutorial. Um pipeline é um conjunto de componentes concatenados na forma de um gráfico. Cada componente será um nó do gráfico e executará uma tarefa específica. Um pipeline do Vertex AI Kubeflow tem a seguinte aparência:
Onde cada componente pode ter entradas, saídas e é conectado ao próximo na tubulação. O Kubeflow é um projeto de código aberto projetado para fazer implantações de pipelines de ML em Kubernetes. Isso nos permite definir uma série de componentes como funções python. Esses componentes serão os nós do pipeline que queremos implantar. Cada um dos componentes do pipeline será executado em um contêiner isolado; portanto, cada componente instalará somente os pacotes Python necessários para a etapa atual. É uma boa prática projetar tubulações que promovam a reutilização de componentes. Para conseguir isso, cada componente deve ter uma única responsabilidade. O Google definiu um conjunto de componentes reutilizáveis pré-construídos que podem ser encontrados aqui. No entanto, podemos definir nossos componentes personalizados para criar nosso pipeline.
Configuração
O tutorial a seguir pode ser executado inteiramente em uma conta do GCP de nível gratuito. Para começar, vamos instalar e configurar todos os pacotes necessários.
- Instale o SDK DO GCP. Siga as instruções em este link de acordo com seu sistema operacional. Depois de instalado, você poderá executar os comandos “gcloud”. Por exemplo:
gcloud --versiononde você deveria ver algo como”Google Cloud SDK 373.0.0" e outras versões listadas. - Em seguida, em um projeto com o faturamento já ativado, o APIs deve ser ativado.
- Faça login no GCP em seu terminal com o comando:
login de autenticação do gcloud - O comando
gcloud initpermitirá que você especifique um projeto, região e zona. - Atualize e instale os componentes do gcp:
atualização de componentes do gcloud e instalação beta dos componentes do gcloud - Ative o Vertex AI em seu projeto. Para ativá-lo, você precisa navegar até o Serviço Vertex AI no console do GCP e clique no botão “Ativar a API Vertex AI”:

- Usos do Vertex armazenamento em nuvem buckets como área de preparação (para armazenar dados, modelos e todos os objetos de que seu pipeline precisa). Portanto, precisamos criar um novo bucket para nosso pipeline. Os nomes dos buckets precisam ser exclusivos (não pode haver 2 buckets com o mesmo nome, mesmo em organizações diferentes). Crie o novo bucket com o comando:
gsutil mb -p PROJECT_ID gs: //BUCKET_NAME. O ID do seu projeto pode ser encontrado na barra superior do seu console do GCP:

- Quando você pressiona o nome do seu projeto, um pop-up é exibido e você pode ver o ID do seu projeto:
- Você pode escolher seu próprio nome de bucket.
- Com relação ao controle de acesso, você pode executar seus pipelines de IA da Vertex com a conta de serviço padrão do Compute Engine ou criar uma nova conta de serviço com acesso granular. Para os fins desta publicação, usaremos a conta de serviço padrão do Compute Engine; portanto, você deve habilite a API do Compute Engine. Em seguida, você precisará do número do seu projeto. O comando:
lista de contas de serviço gcloud iamlistará todas as suas contas de serviço:

- A que você quer é “Conta de serviço padrão do Compute Engine” e, mais especificamente, você precisa do número que pode ser encontrado no E-MAIL (346590416306, no meu caso). Com esse número em mãos, podemos executar o próximo comando para dar a essa conta de serviço acesso ao nosso bucket recém-criado:
gsutil iam ch serviceAccount: [email protected]:roles/storage.objectCreator, ObjectViewer gs: //BUCKET_NAME- PROJECT_NUMBER: é o número que acabamos de receber (346590416306 no meu caso)
- BUCKET_NAME: o nome do bucket que você criou
- Posteriormente, quando quisermos executar nosso pipeline, precisaremos ter uma chave json da nossa conta de serviço padrão do Compute Engine. Para obter essa chave json, vamos usar o Serviço IAM em nosso console do GCP. No painel esquerdo, precisamos navegar até a guia “Contas de serviço”:
- Quando você estiver nesta seção, uma lista de contas de serviço será exibida:

- Aqui você precisa clicar no botão “Ações” e depois navegar até a opção “Gerenciar chaves”:
- Você precisa clicar no botão “ADICIONAR CHAVE” e criar uma nova chave:
- Depois de criada, uma chave JSON será baixada para o seu computador. Você deve guardá-lo em um local seguro e não compartilhá-lo com ninguém. Usaremos essa chave mais tarde, quando quisermos executar nosso pipeline. Você está pronto! Vamos às seções divertidas em que definiremos nosso pipeline de treinamento personalizado.
Os dados e o modelo
O Big Query tem alguns conjuntos de dados disponíveis publicamente. Nesse caso, vamos usar um conjunto de dados sobre crimes em Chicago. O conjunto de dados consiste em 7.491.936 amostras sobre crimes com uma breve descrição, algumas outras características e uma coluna booleana indicando se acabou com uma prisão ou não. Os dados são do ano de 2001 ao ano de 2022.
Você pode ver mais sobre esse conjunto de dados executando a seguinte consulta no bigquery: SELECT * FROM `bigquery-public-data.chicago_crime.crime` LIMIT 10 Em nosso modelo, usaremos as colunas: primary_type, location_description, domestic e arrest. Queremos prever se um crime acabou com uma prisão ou não. O modelo usado será uma floresta aleatória; no entanto, esse não será o foco do nosso tutorial e você pode tentar melhorar o modelo o quanto quiser, ou até mesmo usar um conjunto de dados diferente e um modelo diferente.
Componentes
Conforme mencionado anteriormente, um componente será um nó em nosso gráfico direcionado (pipeline). Depois de compilado, um componente será representado como um arquivo.yaml que a Vertex usará posteriormente para executar nosso pipeline. Cada componente será definido como uma função python, com algumas peculiaridades:
- Uma função Python que representa um componente Kubeflow terá o decorador:
@componente dentro desse decorador, precisamos especificar:pacotes_para_instalar: como cada componente instala seus próprios pacotes, precisamos especificar uma lista de pacotes a serem instalados para cada componenteimagem_base: python:3.9 no nosso casoarquivo_do_componente de saída: o nome do arquivo de saída .yaml gerado quando o componente é compilado
- Um componente pode receber entradas e gerar saídas. Isso precisa ser especificado nos parâmetros da função python. Por exemplo, se nosso componente chamado “train” receber um conjunto de dados como entrada e gerar um modelo treinado como saída, nossa definição de componente poderia ser: @component (packages_to_install= ["sklearn”, “pandas"], base_image="python:3.9", output_component_file="train_component.yaml”,) def train (dataset: Input [Dataset], modelo: Saída [Modelo]):
- Como um componente é executado em um ambiente isolado, cada componente precisa importar os pacotes necessários.
Estamos prontos para começar a definir nossos componentes. Em um novo arquivo python, importe os pacotes necessários: do compilador de importação kfp.v2 do pipeline de importação kfp.v2.dsl, componente, artefato, conjunto de dados, entrada, métricas, modelo, saída, outputPath “dsl” significa linguagem específica do domínio e usaremos esses pacotes para definir e interagir com os componentes do pipeline. Vamos usar entradas e saídas para realizar a comunicação entre os componentes do nosso pipeline. As métricas nos permitirão registrar alguns metadados de métricas ou modelos para análises adicionais. Depois de importar esses pacotes, precisamos definir algumas constantes: PROJECT_ID = “YOUR_PROJECT_ID” BUCKET_NAME = “gs: //BUCKET_NAME/” PIPELINE_ROOT = f "{BUCKET_NAME} pipeline_root/” Aqui você precisa colocar o ID do projeto, o nome do bucket e deixar o PIPELINE_ROOT conforme definido no exemplo.
Obtenha o dataframe
O primeiro componente que vamos definir é get_dataframe. Mencionamos acima que um conjunto de dados público sobre crimes em Chicago será usado. Esse conjunto de dados será recuperado do Big Query. Portanto, vamos armazenar a consulta em um arquivo separado. Em um arquivo.sql, escreva a seguinte consulta parametrizada: SELECT DISTINCT primary_type, location_description, domestic, arrest FROM `bigquery-public-data.chicago_crime.crime` WHERE year > @year No Big Query, os parâmetros são especificados com “@”. Agora, voltando ao nosso arquivo python principal com nossa definição de componentes, criaremos o primeiro componente do pipeline. A definição do primeiro componente é: @component (packages_to_install= ["google-cloud-bigquery”, “pandas”, “pyarrow"], base_image="python:3.9", output_component_file="get_crime_dataset.yaml”) def get_dataframe (query_string: str, year_query_param: int, output_data_path: outputPath (“Conjunto de dados”)): do google.cloud importe bigquery bqclient = bigquery.client (project="marvik-vertex-tutorial”) job_config = bigquery.queryJobConfig (query_parameters= [bigquery.scalarQueryParameter (“year”, “INT64", year_query_parameters= [bigquery.scalarQueryParameter (“year”, “INT64", year_query_parameters= [bigquery.scalarQueryParameter (“year”, “INT64", year_query_query_Parameters= [bigquery.scalarQueryParameter (“ano”, “INT64", param)]) df = (bqclient.query (query_string, job_config= job_config) .result () .to_dataframe (create_bqstorage_client=True)) print (F"Dataset shape: {df.shape}”) df.to_csv (output_data_path) Esse componente tem como objetivo realizar uma consulta parametrizada no Big Query, transformar os resultados em um dataframe Pandas e armazenar os resultados em um caminho de saída (como você pode imagine, os resultados serão armazenados em nosso bucket de armazenamento em nuvem de teste). Usamos o SDK do Big Query para realizar a consulta parametrizada; portanto, google-cloud-bigquery precisa ser instalado em nosso componente. A saída é armazenada em um output_data_path gerado que pode ser acessado posteriormente para recuperar esses dados.
Treinamento de modelos
Em seguida, definimos o componente para recuperar os dados, treinar um modelo florestal aleatório, registrar algumas métricas e armazenar nosso modelo treinado. A definição do componente é: @component (packages_to_install= ["sklearn”, “pandas”, “joblib"], base_image="python:3.9", output_component_file="model_component.yaml”,) def train_model (conjunto de dados: entrada [conjunto de dados], métricas: saída [métricas], modelo: saída [modelo]): importação pandas como pd de sklearn.model_selection importe train_test_split de sklearn.ensemble importe RandomForestClassifier de joblib importe dump de sklearn.metrics importe accuracy_score, f1_score de sklearn.pipeline import Pipeline de sklearn.preprocessing import OneHotEncoder df = pd.read_csv ( dataset.path) X = df [["primary_type”, “location_description”, “doméstico"]] .copy () y = df ["arrestar"] .copy () X_train, X_test, y_train, y_test = train_test_split (X, y, test_size=0,2, random_state=42, estratify=y) random_size forest_model = Pipeline ([('vec', OneHotEncoder (SPARSE=false, handle_unknown="ignore”)), ('clf', RandomForestClassifier ())]) random_forest_model.fit (X_train, y_train) acc = accuracy_score (y_test, random_forest_model.predict (X_test)) f1 = f1_score (y_test, random_forest_model.predict (X_test)) metrics.log_metric (“dataset_shape”, df.shape) metrics.log_metric (“accuracy”, acc) metrics.log_metric (“f1", f1) dump (random_forest_model, model.path + “.joblib”) Dentro desse componente, definimos toda a lógica do nosso modelo. Como temos características categóricas, definimos um pipeline que pode lidar com esse tipo de dados. Você pode jogar com esta etapa tentando adicionar mais recursos, tornar a engenharia de recursos mais inteligente, o ajuste de hiperparâmetros e assim por diante. Como você pode ver nos parâmetros, esse componente usa uma entrada (o conjunto de dados) e gera duas saídas (métricas e modelo). Depois que o modelo é treinado, calculamos a pontuação f1 e a pontuação de precisão. Essas pontuações são registradas usando a saída das métricas. Além disso, adicionamos alguns metadados a essas métricas: dataset_shape. Todos esses dados podem ser facilmente acessados posteriormente no console do GCP e serão úteis para comparar as execuções do pipeline. Além disso, você pode armazenar isso em uma tabela do Big Query para realizar análises mais detalhadas. Depois que nosso modelo é treinado e as métricas registradas, na última linha de nossa definição de componente, despejamos nosso modelo treinado (outra saída). Todas essas saídas serão acessadas posteriormente, quando juntarmos tudo no pipeline.
Implantação
Nosso terceiro (e último) componente será responsável pela implantação. Com implantação, pretendo gerar um novo endpoint para consumir nosso modelo treinado em tempo real: @component (packages_to_install= ["google-cloud-aiplatform"], base_image="python:3.9", output_component_file="deploy_component.yaml”,) def deploy_model (model: Input [Model], project: str, vertex_endpoint: Saída [Artefato], vertex_model: Saída [Modelo]): do google.cloud, importe aiplatform aiplatform.init (project=project) deployed_model = aiplatform.model.upload (display_name="chicago-crime-pipeline”, artifact_uri=model.uri.replace (“/model”, “/”), serving_container_image.ge_ury= “us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest”) endpoint = deployed_model.deploy (machine_type="n1-standard-8") vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name Fazendo uso do SDK Python de plataforma aiplatform, implantamos nosso modelo treinado em um endpoint. Precisamos fazer o upload do nosso modelo antes da implantação, e fazemos isso com a função “upload”. Como estamos usando o sklearn, o usadoserving_container_image_uri é us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest no entanto, você pode usar qualquer pré-construído ou imagem personalizada. Por exemplo, se você quiser usar o XGBoost, você pode tentar us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest. Depois que nosso modelo for carregado, podemos obter o endpoint. Um dos parâmetros mais importantes a serem definidos aqui é otipo_máquina. Nesse caso, estamos usando apenas uma máquina n1-standard-8 e isso é suficiente. Você pode encontrar outros tipos de máquinas aqui.
Colocando tudo junto no pipeline
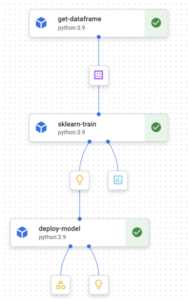
Acabamos de definir todos os componentes necessários para treinar e implantar nosso modelo. No entanto, definimos isolado componentes e agora precisamos uni-los em um pipeline. Como os componentes tinham o @componentdecorador, um oleoduto terá o @pipelinedecorador. Nossa definição de pipeline será: @pipeline (pipeline_root=PIPELINE_ROOT, name="chicago-crime-pipeline”,) def pipeline (query_string: str, year_query_param: int, output_data_path: str = "crime_data.csv “, project: str = PROJECT_ID): dataset_task = get_dataframe (query_string, year_query_param) model_task = train_model (dataset=dataset_task.output) deploy_task = deploy_model (model=model_task.outputs [" model "], project=project) Aqui usamos oraiz do pipelinedefinido no início. Esse é o caminho de armazenamento em nuvem em que todos os nossos artefatos são armazenados. Na função Python, chamamos cada um dos nossos componentes (em ordem) e obtemos os resultados. Na primeira etapa (dataet_task), temos apenas 1 saída e, portanto, na próxima etapa (model_task), acessamos essa saída com: dataset_task.output. No entanto, em model_task, temos 2 saídas (modelo e métricas); portanto, acessamos a saída do modelo como: model_task.outputs ["modelo"].
Compile o pipeline
Por último, mas não menos importante, precisamos compilar o pipeline. Esta etapa será responsável por gerar os arquivos.yaml e.json necessários. No final do seu arquivo python, cole o seguinte código: if __name__ == “__main__”: compiler.compiler () .compile (pipeline_func=pipeline, package_path="chicago_crime_model_pipeline.json”) Quando executarmos esse script Python, nosso pipeline será compilado e os componentes e arquivos do pipeline serão gerados:
- chicago_crime_model_pipeline.json
- deploy_component.yaml
- get_crime_dataset.yaml
- model_component.yaml
Depois de executar esse script e ter todos os arquivos.yaml e .json necessários, podemos passar para a próxima etapa: executar nosso pipeline.
Executando nosso pipeline
Estamos prontos para executar nosso pipeline e implantar nosso modelo em um endpoint no GCP. Na etapa de configuração, baixamos um arquivo.json com uma chave de acesso. Agora é hora de usá-lo. Precisamos exportar oGOOGLE_APPLICATION_CREDENTIALSvariável env. Para exportar essa variável, você precisa executar o comando: export GOOGLE_APPLICATION_CREDENTIALS = “caminho para o arquivo-chave json”em seu terminal. Em um novo arquivo Python, cole o seguinte código: if __name__ == “__main__”: from datetime import datetime from google.cloud import aiplatform aiplatform.init (project="marvik-vertex-tutorial”, staging_bucket="marvik-vertex-tutorial”) TIMESTAMP = datetime.now () .strftime (“%Y%Y% M%D%h%m%s”) com open (”. /crime_query.sql “, “r”) como query_file: query_string = query_file.read () print (TIMESTAMP) run = aiPlatform.pipelineJob (display_name="chicago-crime-model-pipeline”, template_path="chicago_crime_model_pipeline.json”, job_id="chicago-crime-model-pipeline.json” pipeline- {0}” .format (TIMESTAMP), parameter_values= {"query_string”: query_string, “year_query_param”: 2010}, enable_caching=False) run.submit () Com esse script, podemos executar nosso pipeline inteiro e implantar nosso modelo. Lembre-se de exportar o GOOGLE_APPLICATION_CREDENTIALSvariável env antes de executar o script. Esse script lê o arquivo sql como string e, em seguida, executa o arquivo previamente compilado usando o SDK para Python da aiplatform. Todos os parâmetros que queremos passar para nosso pipeline devem ser especificados no valores_parâmetros ditado. Por exemplo, se você quiser obter mais dados, tente alterar o ano de 2010 para 2001. Depois de executar esse script:

Você pode navegar até o serviço Vertex no console do GCP e clicar na guia “pipelines”.
Aqui você verá uma nova execução do seu pipeline no estado “Em execução”. Você pode abrir o funil clicando nele:
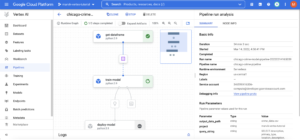
Se seu pipeline falhar, você verá o sinal vermelho no componente que recebeu o erro. Podemos ler os registros dos componentes para depurar. Para acessar os registros do componente, você deve clicar no componente e, em seguida, verá uma guia “registros” na parte inferior.

A guia de registros tem a seguinte aparência:
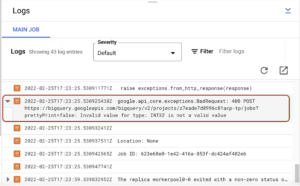
No meu caso, tive um erro indicando que INT32 não é um valor válido para um tipo de parâmetro de consulta grande. Eu consertei e executei tudo de novo. Quando seu pipeline for executado sem erros, você poderá ver o status de sucesso:

Enquanto seu pipeline está em execução, ele armazena alguns artefatos intermediários em seu bucket de teste. Você pode encontrá-los no console do GCP do Cloud Storage. Se você navegar até o bucket que criou no início, poderá ver o seguinte:
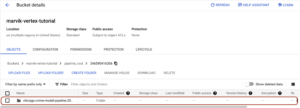
Depois que todo o pipeline for executado sem erros, você poderá encontrar um diretório para cada componente.

Resultados
Durante a etapa de treinamento, registramos algumas métricas. Para encontrar essas métricas, você precisa voltar ao console do Vertex GCP e navegar até seu funil novamente. Na etapa de treinamento, você deve ter o artefato de métricas.
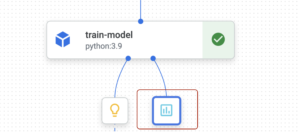
Quando você clicar nele, as métricas registradas serão mostradas:
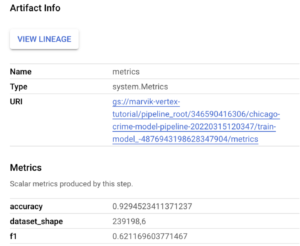
Além disso, se você clicar na guia Resumo, poderá visualizar os parâmetros que foram usados para executar o pipeline:
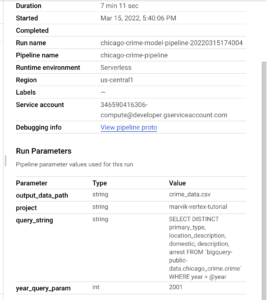
Agora, você deve ser capaz de executar seus próprios pipelines da Vertex e implantar modelos personalizados no GCP ou até mesmo melhorar o que desenvolvemos durante este tutorial. Nas próximas etapas, testaremos nosso modelo implantado e automatizaremos as execuções do pipeline.
Obtenha previsões em tempo real
Se você navegar até a guia de endpoints, verá o endpoint que acabamos de implantar. Aqui você pode clicar no botão “Solicitação de amostra”:

Então, na guia “Python”, estamos interessados no código Python mostrado:
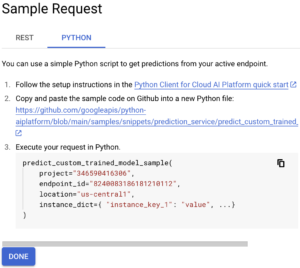
A partir desse código Python, copiaremos nosso ID do projeto, endpoint _id e localização. Em seguida, definiremos uma lista de instâncias que queremos prever. Por exemplo: ["OBSCENIDADE”, “RESIDÊNCIA”, “FALSO"] Agora podemos usar o código a seguir para chamar nosso endpoint e obter previsões: de google.cloud import aiplatform def endpoint_predict_sample (project: str, location: str, instances: list, endpoint: str): aiplatform.init (project=project, location=location) endpoint = aiplatform.endpoint (endpoint) prediction = endpoint.predict (instance (es=instances) print (prediction) retorna a previsão se __name__ == “__main__”: instances_to_test = [["OBSCENITY”, “RESIDENCE”, “false"]] endpoint_predict_sample (PROJECT="Your PROJECT ID”, endpoint="Your ENDPOINT ID”, location="us- central1", instances=instances_to_test) A função endpoint_predict_sample é proposta pelo Google em seu repositório github. Execute o script e obtenha previsões em tempo real:

Limpe os recursos
Essa etapa é importante para evitar custos indesejados. No entanto, se você estiver usando o nível gratuito, o Google não cobrará nada, mas você gastará seus créditos gratuitos. À medida que criamos modelos e endpoints, precisamos removê-los. Para remover modelos, precisamos desimplantar eles. Para desimplantar um modelo, navegue até a guia “modelos”. Aqui você verá uma lista de modelos e um botão com o sinal “SHOW ENDPOINTS”. Ao clicar em “MOSTRAR ENDPOINTS”, você verá o endpoint em que cada modelo foi implantado:
Você precisa clicar no endpoint e, na página a seguir, desimplantar o modelo, conforme mostrado na imagem a seguir:
Depois de desimplantado, você pode voltar para a guia modelos e excluir o modelo e os endpoints na guia Endpoints. Além disso, como mencionamos anteriormente, enquanto seu pipeline estiver em execução, ele criará alguns arquivos em seu bucket do GCS. Nós removeremos esses arquivos. Navegue até o bucket que você criou no início e exclua o diretório pipeline_root. Depois disso, você pode remover o balde inteiro. Nós terminamos! 🎉 Criamos um pipeline Kubeflow para treinar um modelo personalizado que recupera dados do Big Query e o implantamos usando o serviço Vertex AI do Google. Agora você pode tentar desenvolver seus próprios pipelines com seus próprios dados.



.png)