
Tutorial de Vertex AI + Kubeflow




Por lo general, llevar un modelo de aprendizaje automático del entorno de experimentación a la producción consume una enorme cantidad de tiempo y recursos. Vertex AI facilita el entrenamiento, la implementación y la comparación de los resultados de los modelos. Es una herramienta excelente que nos permite centrarnos en las soluciones de aprendizaje automático en lugar de en la gestión de la infraestructura. En la siguiente publicación, profundizaremos en Vertex AI. Esta es una guía paso a paso para definir un Kubeflow canalización que implementará un modelo de aprendizaje automático personalizado con Vertex ai y, a continuación, realizará inferencias en tiempo real con el modelo implementado. Vamos a entrenar nuestro modelo utilizando un conjunto de datos público sobre delitos en Chicago; sin embargo, este modelo no será el tema central del tutorial y, al final, ya podréis crear vuestros propios canales para implementar cualquier modelo personalizado en Vertex AI. Puedes encontrar el código utilizado en este tutorial en este repositorio de Github. Al final del tutorial, queremos lograr el siguiente proceso:
¿Qué es Vertex AI?
Si echamos un vistazo a la Vertex AI oficial página web:
[perfectpullquote align="full» bordertop="false» cite= "» link= "» color= "» class= "» size=" "]" Vertex AI reúne los servicios de Google Cloud para crear ML en una interfaz de usuario y API unificadas. En Vertex AI, ahora puedes entrenar y comparar modelos fácilmente mediante AutoML o el entrenamiento de código personalizado, y todos tus modelos se almacenan en un repositorio de modelos central. Estos modelos ahora se pueden implementar en los mismos puntos finales de Vertex AI». [/perfectpullquote]
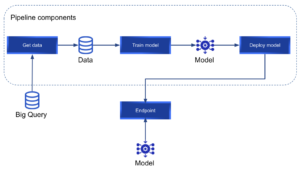
Mencionan que podemos «entrena y compara modelos usando AutoML o entrenamiento de código personalizado». Este tutorial se centrará en el entrenamiento de código personalizado en lugar de en AutoML. Vertex AI nos permite ejecutar canalizaciones con Kubeflow o Tensorflow Extended (TFX). En nuestro caso, utilizaremos Kubeflow para definir nuestra canalización personalizada. Nos referiremos al concepto «canalización» con frecuencia en este tutorial. Una canalización es un conjunto de componentes que se concatenan en forma de gráfico. Cada componente será un nodo del grafo y realizará una tarea específica. Una canalización de Vertex AI Kubeflow tiene este aspecto:
Donde cada componente puede tener entradas, salidas y está conectado al siguiente de la canalización. Kubeflow es un proyecto de código abierto diseñado para implementar canalizaciones de aprendizaje automático en Kubernetes. Nos permite definir una serie de componentes como funciones de Python, estos componentes serán los nodos de la canalización que queremos implementar. Cada uno de los componentes de la canalización se ejecutará en un contenedor aislado; por lo tanto, cada componente instalará solo los paquetes de Python necesarios para el paso actual. Es una buena práctica diseñar canalizaciones que promuevan la reutilización de los componentes. Para lograrlo, cada componente debe tener una única responsabilidad. Google ha definido un conjunto de componentes reutilizables prediseñados que se pueden encontrar aquí. Sin embargo, podemos definir nuestros componentes personalizados para construir nuestra canalización.
Configuración
El siguiente tutorial se puede ejecutar en su totalidad en una cuenta de GCP de nivel gratuito. Para empezar, vamos a instalar y configurar todos los paquetes necesarios.
- Instala el GCP SDK. Siga las instrucciones de este enlace según su sistema operativo. Una vez instalado, deberías poder ejecutar los comandos de «gcloud». Por ejemplo:
gcloud --versióndonde deberías ver algo como»Google Cloud SDK 373.0.0" y otras versiones de la lista. - A continuación, en un proyecto con la facturación ya activada, APIs debe estar activado.
- Inicia sesión en GCP en tu terminal con el comando:
inicio de sesión de gcloud auth - El comando
inicio de gcloudle permitirá especificar un proyecto, región y zona. - Actualiza e instala los componentes de gcp:
Actualización de los componentes de gcloud e instalación de la versión beta de los componentes de gcloud - Activa Vertex AI en tu proyecto. Para activarlo, debe navegar hasta el Servicio Vertex AI en tu consola de GCP y haz clic en el botón «Habilitar la API de Vertex AI»:

- Usos de Vertex almacenamiento en la nube cubos como área de preparación (para almacenar datos, modelos y todos los objetos que necesite su canalización). Por lo tanto, necesitamos crear un nuevo depósito para nuestra canalización. Los nombres de los grupos deben ser únicos (no puede haber 2 grupos con el mismo nombre, incluso en diferentes organizaciones). Crea el nuevo bucket con el comando:
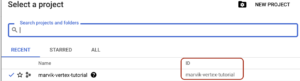
gsutil mb -p PROJECT_ID gs: //BUCKET_NAME. Puedes encontrar el identificador de tu proyecto en la barra superior de tu consola de GCP:

- Cuando presiones el nombre de tu proyecto, aparecerá una ventana emergente en la que podrás ver la identificación de tu proyecto:
- Puedes elegir el nombre de tu depósito.
- En cuanto al control de acceso, puedes ejecutar tus canalizaciones de Vertex AI con la cuenta de servicio predeterminada de Compute Engine o crear una nueva cuenta de servicio con acceso granular. Para los fines de esta publicación, utilizaremos la cuenta de servicio predeterminada de Compute Engine; por lo tanto, debes habilita la API de Compute Engine. A continuación, necesitará el número de su proyecto. El comando:
lista de cuentas de servicio de gcloud iammostrará una lista de todas sus cuentas de servicio:

- La que quieres es «cuenta de servicio predeterminada de Compute Engine» y, más específicamente, necesitas el número que se encuentra en el CORREO ELECTRÓNICO (346590416306 en mi caso). Con este número a mano, podemos ejecutar el siguiente comando para dar acceso a esta cuenta de servicio a nuestro bucket creado recientemente:
gsutil iam ch ServiceAccount: [email protected]:roles/storage.ObjectCreator, ObjectViewer gs: //BUCKET_NAME- PROJECT_NUMBER: es el número que acabamos de recibir (346590416306 en mi caso)
- BUCKET_NAME: el nombre del bucket que creaste
- Más adelante, cuando queramos ejecutar nuestra canalización, necesitaremos tener una clave json de nuestra cuenta de servicio predeterminada de Compute Engine. Para obtener esta clave json, usaremos la Servicio de IAM en nuestra consola de GCP. En el panel izquierdo, debemos navegar hasta la pestaña «Cuentas de servicio»:
- Una vez que esté en esta sección, se mostrará una lista de cuentas de servicio:

- Aquí debe hacer clic en el botón «Acciones» y luego navegar hasta la opción «Administrar claves»:
- Tienes que hacer clic en el botón «AÑADIR CLAVE» y crear una nueva clave:
- Una vez creada, se descargará una clave JSON a tu ordenador. Debes guardarla en un lugar seguro y no compartirla con nadie. Utilizaremos esta clave más adelante cuando queramos ejecutar nuestra canalización. ¡Ya está todo preparado! Pasemos a las secciones divertidas en las que vamos a definir nuestro proceso de formación personalizado.
Los datos y el modelo
Big Query tiene algunos conjuntos de datos disponibles públicamente. En este caso, vamos a utilizar un conjunto de datos sobre delitos en Chicago. El conjunto de datos consta de 7.491.936 muestras sobre delitos con una breve descripción, algunas otras características y una columna booleana que indica si terminó con un arresto o no. Los datos van desde el año 2001 hasta el año 2022.
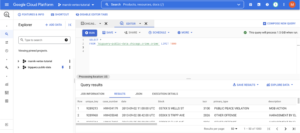
Puedes obtener más información sobre este conjunto de datos al ejecutar la siguiente consulta en bigquery: SELECT * FROM `bigquery-public-data.chicago_crime.crime` LIMIT 10 En nuestro modelo, usaremos las columnas: primary_type, location_description, domestic y arrest. Queremos predecir si un delito terminó con un arresto o no. El modelo usado será un bosque aleatorio; sin embargo, este no será el tema central de nuestro tutorial y puedes intentar mejorar el modelo tanto como quieras, o incluso usar un conjunto de datos y un modelo diferentes.
Componentes
Como se mencionó anteriormente, un componente será un nodo en nuestro grafo dirigido (canalización). Una vez compilado, un componente se representará como un archivo.yaml que Vertex usará más adelante para ejecutar nuestra canalización. Cada componente se definirá como una función de Python, con algunas peculiaridades:
- Una función de Python que represente un componente de Kubeflow tendrá el decorador:
@componenty dentro de este decorador necesitamos especificar:paquetes_para_instalar: dado que cada componente instala sus propios paquetes, necesitamos especificar una lista de paquetes para instalar para cada componenteimagen_base: python:3.9 en nuestro casoarchivo_component_de salida: el nombre del archivo .yaml de salida generado al compilar el componente
- Un componente puede recibir entradas y generar salidas. Esto debe especificarse en los parámetros de la función de Python. Por ejemplo, si nuestro componente llamado «train» recibe un conjunto de datos como entrada y genera un modelo entrenado como salida, la definición de nuestro componente podría ser: @component (packages_to_install= ["sklearn», «pandas"], base_image="python:3.9", output_component_file="train_component.yaml»,) def train (dataset: Input [Dataset], model: Output [Model]):
- Como un componente se ejecuta en un entorno aislado, cada componente debe importar los paquetes necesarios.
Estamos listos para empezar a definir nuestros componentes. En un nuevo archivo de python, importe los paquetes necesarios: del compilador de importación kfp.v2, de kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, OutputPath «dsl» significa lenguaje específico del dominio y utilizaremos estos paquetes para definir los componentes de la canalización e interactuar con ellos. Vamos a utilizar entradas y salidas para llevar a cabo la comunicación entre los componentes de nuestra canalización. Las métricas nos permitirán registrar algunos metadatos de métricas o modelos para realizar análisis adicionales. Tras importar estos paquetes, necesitamos definir algunas constantes: PROJECT_ID = «YOUR_PROJECT_ID» BUCKET_NAME = «gs: //BUCKET_NAME/» PIPELINE_ROOT = f "{BUCKET_NAME} pipeline_root/» Aquí tienes que poner el ID del proyecto y el nombre del bucket y dejar el PIPELINE_ROOT tal y como se define en el ejemplo.
Obtenga el marco de datos
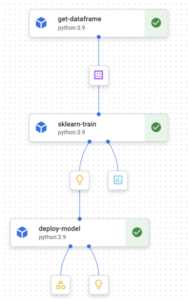
El primer componente que vamos a definir es get_dataframe. Mencionamos anteriormente que se utilizará un conjunto de datos público sobre los delitos de Chicago. Este conjunto de datos se recuperará de Big Query. Por lo tanto, vamos a almacenar la consulta en un archivo separado. En un archivo.sql, escriba la siguiente consulta con parámetros: SELECT DISTINCT primary_type, location_description, domestic, arrest FROM `bigquery-public-data.chicago_crime.crime` DONDE year > @year En Big Query, los parámetros se especifican con «@». Ahora, volviendo a nuestro archivo principal de Python con nuestra definición de componentes, vamos a crear el primer componente de la canalización. La definición del primer componente es: @component (packages_to_install= ["google-cloud-bigquery», «pandas», «pyarrow"], base_image="python:3.9", output_component_file="get_crime_dataset.yaml») def get_dataframe (query_string: str, year_query_param: int, output__data_path: outputPath («Conjunto de datos»)): desde google.cloud importar bigquery bqclient = bigQuery.client (project="marvik-vertex-tutorial») job_config = bigquery.queryJobConfig (query_parameters= [bigquery.scalarQueryParameter («year», «INT64", year_query_param)]) df = (bqclienter .query (query_string, job_config= job_config) .result () .to_dataframe (create_bqStorage_client=true)) print (f"Dataset shape: {df.shape}») df.to_csv (output_data_path) Este componente tiene como objetivo realizar una consulta parametrizada a Big Query, transformar los resultados en un marco de datos de Pandas y almacenar los resultados en una ruta de salida (como puede imaginar, los resultados se almacenará en nuestro depósito provisional de almacenamiento en la nube). Usamos el SDK de Big Query para realizar la consulta parametrizada; por lo tanto, google-cloud-bigquery debe instalarse en nuestro componente. La salida se almacena en una output_data_path generada a la que se puede acceder más adelante para recuperar estos datos.
Entrenamiento modelo
A continuación, definimos el componente para recuperar los datos, entrenar un modelo de bosque aleatorio, registrar algunas métricas y almacenar nuestro modelo entrenado. La definición del componente es: @component (packages_to_install= ["sklearn», «pandas», «joblib"], base_image="python:3.9", output_component_file="model_component.yaml»,) def train_model (conjunto de datos: Input [Dataset], metrics: Output [Metrics], model: Output [Model]): importar pandas como pd desde sklear+ n.model_selection importar train_test_split desde sklearn.ensemble importar RandomForestClassifier desde joblib importar dump desde sklearn.metrics importar accuracy_score, f1_score desde sklearn.pipeline importar Pipeline desde sklearn.preprocessing importar OneHotEncoder df = pd.read_csv ( dataset.path) X = df [["primary_type», «location_description», «domestic"] .copy () y = df ["arrest"] .copy () X_train, x_test, y_train, y_test = train_test_split (X, y, test_size=0.2, random_state=42, stratify=y) random_forest_model = Pipeline ([('vec', OneHotEncoder (sparse=false, handle_unknown="ignore»)), ('clf', randomForestClassifier ())]) random_forest_model.fit (x_train, y_train) acc = accuracy_score (y_test, random_forest_model.predict (x_test)) f1 = f1_score (y_test), random_forest_model.predict (x_Test)) metrics.log_metric («dataset_shape», df.shape) metrics.log_metric («accuracy», acc) metrics.log_metric («f1", f1) dump (random_forest_model, model.path + «.joblib») Dentro de este componente definimos toda la lógica de nuestro modelo. Como tenemos características categóricas, definimos una canalización que puede gestionar este tipo de datos. Puedes jugar con este paso intentando añadir más funciones, hacer una ingeniería de funciones más inteligente, ajustar los hiperparámetros, etc. Como puedes ver en los parámetros, este componente toma una entrada (el conjunto de datos) y genera 2 salidas (métricas y modelo). Una vez entrenado el modelo, calculamos la puntuación f1 y la puntuación de precisión. Estas puntuaciones se registran utilizando la salida de las métricas. Además, agregamos algunos metadatos a estas métricas: dataset_shape. Podrás acceder fácilmente a todos estos datos más adelante desde la consola de GCP y serán útiles para comparar las ejecuciones de los procesos. Además, puedes almacenarlos en una tabla de Big Query para realizar análisis más detallados. Una vez que nuestro modelo está entrenado y las métricas se registran, en la última línea de la definición de nuestro componente, volcamos nuestro modelo entrenado (otro resultado). Se accederá a todos estos resultados más adelante, cuando juntemos todo lo que esté en proceso.
Despliegue
Nuestro tercer (y último) componente se encargará de la implementación. Por implementación me refiero a generar un nuevo punto final para consumir nuestro modelo entrenado en tiempo real: @component (packages_to_install= ["google-cloud-aiplatform"], base_image="python:3.9", output_component_file="deploy_component.yaml»,) def deploy_model (model: Input [Model], project: str, vertex_endpoint: Output [Artifact], vertex_endpoint: Output [Artifact], vertex_endpoint _model: Salida [Modelo]): desde google.cloud importar aiplatform aiplatform.init (project=project) deploy_model = AIPlatform.model.upload (display_name="chicago-crime-pipeline», artifact_uri=model.uri.replace («/model», «/»), serving_container_image_uri= «us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:latest») endpoint = deployyed_model.deploy (machine_type="n1-standard-8") vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployyed_model.resource_name Haciendo uso del SDK Python para plataformas aéreas, desplegamos nuestro modelo entrenado en un punto final. Tenemos que cargar nuestro modelo antes de la implementación, y lo hacemos con la función «cargar». Como estamos usando sklearn, el usadouser_container_image_uri es us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-0:último sin embargo, puedes usar cualquier preconstruido o imagen personalizada. Por ejemplo, si quieres usar XGBoost, puedes probar us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4: última. Una vez cargado nuestro modelo, podemos obtener el punto final. Uno de los parámetros más importantes que hay que definir aquí es eltipo_máquina. En este caso, estamos utilizando solo una máquina n1-standard-8 y es suficiente. Puede encontrar otros tipos de máquinas aquí.
Ponerlo todo junto en preparación
Acabamos de definir todos los componentes necesarios para entrenar e implementar nuestro modelo. Sin embargo, definimos aislado componentes y ahora necesitamos unirlos en una canalización. Como los componentes tenían el @componentdecorador, una tubería tendrá el @pipelinedecorador. Nuestra definición de canalización será: @pipeline (pipeline_ROOT=PIPELINE_ROOT, name="chicago-crime-pipeline»,) def pipeline (query_string: str, year_query_param: int, output_data_path: str = "crime_data.csv «, project: str = PROJECT_ID): dataset_task = get_dataframe (query_string, year_query_param) model_task = train_model (dataset=dataset_task.output) deploy_task = deploy_model (model=model_task.outputs [" model "], project=project) Aquí utilizamos elraíz_de_tuberíadefinido al principio. Esta es la ruta de almacenamiento en la nube donde se almacenan todos nuestros artefactos. En la función de Python, llamamos a cada uno de nuestros componentes (en orden) y obtenemos los resultados. En el primer paso (dataet_task) solo tenemos 1 salida y, por lo tanto, en el siguiente paso (model_task) accedemos a esta salida con: dataset_task.output. Sin embargo, en model_task tenemos 2 salidas (modelo y métricas); por lo tanto, accedemos a la salida del modelo como: model_task.outputs ["modelo"].
Compila la canalización
Por último, pero no por ello menos importante, necesitamos compilar la canalización. Este paso se encargará de generar los archivos .yaml y .json necesarios. Al final del archivo de Python, pega el siguiente código: if __name__ == «__main__»: compiler.compiler () .compile (pipeline_func=pipeline, package_path="chicago_crime_model_pipeline.json») Cuando ejecutemos este script de Python, nuestra canalización se compilará y se generarán los archivos de componentes y canalización:
- chicago_crime_model_pipeline.json
- deploy_component.yaml
- get_crime_dataset.yaml
- model_component.yaml
Una vez que hayamos ejecutado este script y tengamos todos los archivos.yaml y .json necesarios, podemos pasar al siguiente paso: ejecutar nuestra canalización.
Gestionar nuestro oleoducto
Estamos listos para ejecutar nuestro proceso e implementar nuestro modelo en un punto final de GCP. En la fase de configuración, descargamos un archivo.json con una clave de acceso. Ahora es el momento de usarlo. Necesitamos exportar elCREDENCIALES DE APLICACIÓN DE GOOGLEvariable env. Para exportar esta variable tienes que ejecutar el comando: exportar GOOGLE_APPLICATION_CREDENTIALS = «ruta al archivo de claves JSON»en tu terminal. En un archivo nuevo de Python, pega el siguiente código: if __name__ == «__main__»: from datetime import datetime from google.cloud import aiplatform aiplatform.init (project="marvik-vertex-tutorial», staging_bucket="marvik-vertex-tutorial») TIMESTAMP = datetime.now () .strftime («%y%m%dHhH %m%s») con open (». /crime_query.sql «, «r») como query_file: query_string = query_file.read () print (TIMESTAMP) run = AIPlatform.pipelineJob (display_name="chicago-crime-model-pipeline», template_path="chicago_crime_model_pipeline.json», job_id="chicago-crime-model-pipeline- {0}» .format (TIMESTAMP), parameter_values= {"query_string»: query_string, «year_query_param»: 2010}, enable_caching=false) run.submit () Con este script, podemos ejecutar toda nuestra canalización e implementar nuestro modelo. Recuerde exportar el CREDENCIALES DE APLICACIÓN DE GOOGLEvariable env antes de ejecutar el script. Este script lee el archivo sql como una cadena y, a continuación, ejecuta el archivo compilado anteriormente con el SDK de Python de aiplatform. Todos los parámetros que queremos pasar a nuestra canalización deben especificarse en el valores_parámetros dictado. Por ejemplo, si desea obtener más datos, puede intentar cambiar el año 2010 por el 2001. Una vez que haya ejecutado este script:

Puedes ir al servicio Vertex en la consola de GCP y hacer clic en la pestaña «canalizaciones».
Aquí verás un nuevo tramo de tu oleoducto en el estado «En ejecución». Puedes abrir la canalización haciendo clic en ella:
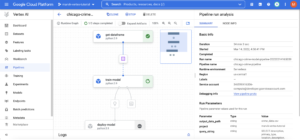
Si tu canalización falla, verás el letrero rojo en el componente que recibió el error. Podemos leer los registros de los componentes para depurarlos. Para acceder a los registros de los componentes, debe hacer clic en el componente y, a continuación, verá una pestaña de «registros» en la parte inferior.

La pestaña de registros tiene este aspecto:
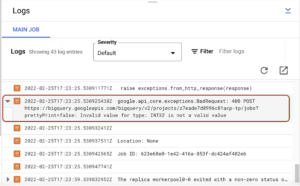
En mi caso, tuve un error que indicaba que INT32 no es un valor válido para un tipo de parámetro de consulta grande. Lo arreglé y volví a ejecutar todo. Cuando tu canalización se ejecute sin errores, podrás ver el estado en el que se ha realizado correctamente:

Mientras tu canalización está en ejecución, almacena algunos artefactos intermedios en tu depósito provisional. Puedes encontrarlos en la consola de GCP de Cloud Storage. Si navegas hasta el depósito que creaste al principio, podrás ver lo siguiente:
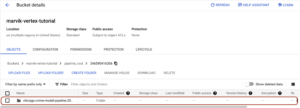
Una vez ejecutada toda la canalización sin errores, puede encontrar un directorio para cada componente.

Resultados
Durante la etapa de entrenamiento, registramos algunas métricas. Para encontrar estas métricas, tienes que volver a la consola de GCP de Vertex y volver a navegar hasta tu canalización. En la etapa de entrenamiento, deberías tener el artefacto de las métricas.
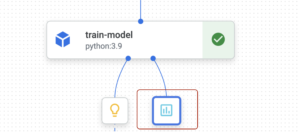
Al hacer clic en él, se mostrarán las métricas registradas:
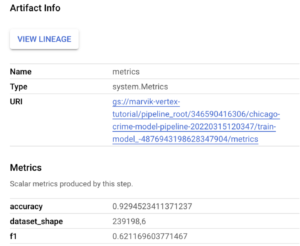
Además, si hace clic en la pestaña Resumen, puede ver los parámetros que se utilizaron para ejecutar la canalización:
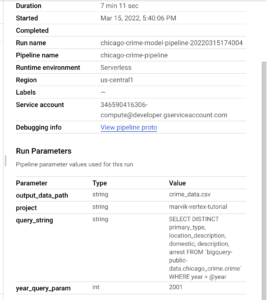
A estas alturas, ya deberías poder ejecutar tus propias canalizaciones de Vertex e implementar modelos personalizados en GCP o incluso mejorar el que desarrollamos durante este tutorial. En los próximos pasos, probaremos nuestro modelo implementado y automatizaremos la ejecución de las canalizaciones.
Obtenga predicciones en tiempo real
Si navega hasta la pestaña de puntos finales, verá el punto final que acabamos de implementar. Aquí puede hacer clic en el botón «Solicitud de muestra»:

Luego, en la pestaña «Python», nos interesa el código Python que se muestra:
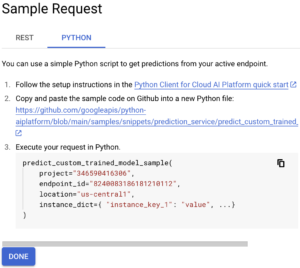
A partir de este código de Python, copiaremos el id de nuestro proyecto, el endpoint _id y la ubicación. Luego, definiremos una lista de instancias que queremos predecir. Por ejemplo: ["OBSCENIDAD», «RESIDENCIA», «falso"] Ahora podemos usar el siguiente código para llamar a nuestro punto final y obtener predicciones: desde google.cloud import aiplatform def endpoint_predict_sample (project: str, location: str, instances: list, endpoint: str): aiplatform.init (project=project, location=location) endpoint = aiplatform.Endpoint (endpoint) prediction = endpoint.predict (instances=instances) print (prediction) devuelve la predicción si __name__ == «__main__»: instances_to_test = [["OBSCENITY», «RESIDENCE», «false"]] endpoint_predict_sample (project="SU ID DE PROYECTO», endpoint="SU ID DE ENDPOINT», location="us- central1", instances=instances_to_test) Google propone la función endpoint_predict_sample en su repositorio de github. Ejecute el script y obtenga predicciones en tiempo real:

Limpiar los recursos
Este paso es importante para evitar costes no deseados. Sin embargo, si está utilizando el nivel gratuito, Google no le cobrará nada, pero gastará sus créditos gratuitos. A medida que creábamos modelos y terminales, necesitamos eliminarlos. Para eliminar los modelos, necesitamos dejar de desplegar ellos. Para anular la implementación de un modelo, navegue hasta la pestaña «modelos». Aquí verás una lista de modelos y un botón con el signo «MOSTRAR PUNTOS FINALES». Al hacer clic en «MOSTRAR PUNTOS FINALES», verá el punto final en el que se implementó cada modelo:
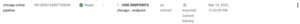
Debe hacer clic en el punto final y, a continuación, anular la implementación del modelo en la siguiente página, tal y como se muestra en la siguiente imagen:
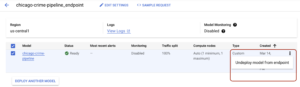
Una vez desimplementado, puede volver a la pestaña de modelos y eliminar el modelo y los puntos finales en la pestaña de puntos finales. Además, como mencionamos anteriormente, mientras tu canalización esté en ejecución, se crearán algunos archivos en tu depósito de GCS. Eliminaremos estos archivos. Navega hasta el bucket que creaste al principio y elimina el directorio pipeline_root. Después de eso, puedes eliminar todo el cubo. ¡Hemos terminado! 🎉 Creamos una canalización de Kubeflow para entrenar un modelo personalizado que recupere datos de Big Query y lo implementamos mediante el servicio Vertex AI de Google. Ahora puedes intentar desarrollar tus propias canalizaciones con tus propios datos.



.png)