.png)
Explicação da dieta do transformador de PNL




Os transformadores são um tipo de arquitetura de rede neural que revolucionou o setor nos últimos anos. Sua popularidade tem aumentado devido à capacidade dos modelos de superar os modelos de última geração em tradução automática neural e outras diversas tarefas. Na Marvik, usamos esses modelos em vários projetos de PNL e gostaríamos de compartilhar um pouco da nossa experiência. Em particular, neste artigo, vamos revisar e discutir RASAa arquitetura de transformador mais recente e as vantagens que essa arquitetura inovadora apresenta.
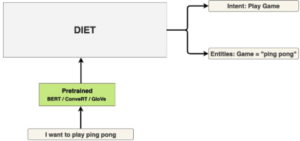
O que é DIETA?
DIET é um transformador multitarefa desenvolvido pela RASA, que funciona para reconhecimento de entidades e classificação de intenções. É altamente adaptável a diferentes cenários e configurações. Graças à sua arquitetura modularizada, é muito ajustável, o que o torna muito útil em várias aplicações. Ele ainda fornece uma interface interativa demonstração de seus módulos de arquitetura.
Como isso funciona?
Nesta seção, descreveremos a arquitetura e como o treinamento e a inferência são executados. Para explicar como ele executa as duas tarefas (classificação de intenções e reconhecimento de entidades) ao mesmo tempo.
Arquitetura
No próximo diagrama, há um diagrama de arquitetura de alto nível que mostra as diferentes partes do modelo e como elas estão conectadas.
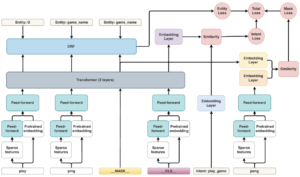
Imagem da arquitetura DIET do blog da RASA
Módulos
A arquitetura do DIET é baseada em módulos, que têm um transformador multicamada como componente chave da arquitetura. Os diferentes módulos serão descritos nesta seção.
Pré-processamento de entrada
Os módulos descritos abaixo são responsáveis pelo pré-processamento dos dados de entrada para gerar os recursos necessários para o módulo transformador.
Incorporação pré-treinada
O objetivo deste módulo é fornecer uma entrada para o transformador relacionada ao token em uma determinada incorporação. Este é um módulo pré-treinado “plug-and-play”, pois há muitas alternativas, entre elas: BERT, ConVe, ConverT, quase qualquer incorporação de palavras funcionaria sem escrever nenhum código. Se for necessária uma versão mais leve do modelo, esse módulo pode até ser removido.
Características esparsas
Esse módulo gera recursos esparsos para os tokens em treinamento; é essencialmente um FFN, com conexões esparsas. A ideia é que, além da incorporação gerada pelo módulo de incorporação pré-treinado, mais recursos sejam adicionados à medida que os dados de treinamento passam pelo modelo, de modo a fornecer mais informações sobre o token ao transformador.
Feed Forward
Esse módulo consiste em uma rede neural (NN) totalmente conectada que pode ter entradas diferentes dependendo da parte da arquitetura à qual está conectada, mas sua saída é sempre uma matriz de tamanho 256. Existem 2 redes de feed forward diferentes na arquitetura, a entrada da primeira são os recursos esparsos de algum token e a entrada da segunda é a incorporação pré-treinada, concatenada à saída do primeiro FFN. O caso de uso é o mesmo em ambos os casos, para aprender recursos sobre tokens que serão usados posteriormente como entradas do módulo Transformer. Observe que as entradas dos recursos esparsos são matrizes esparsas, portanto, para tornar o modelo leve, uma queda de 80% das conexões é implementada por padrão (isso é personalizável e geralmente é recomendado aumentar para 90% se um modelo mais leve for necessário).
Máscara e tokens CLS
Esses não são módulos, mas são os principais componentes da arquitetura, porque é assim que o modelo aprende a realizar as duas tarefas ao mesmo tempo. O símbolo de máscara é aplicado aleatoriamente em uma palavra da frase. Isso é então enviado ao transformador, o que permite prever qual token foi mascarado e, em seguida, permitir o aprendizado por meio de gradiente descendente. O token CLS é uma representação de toda a frase, semelhante a uma incorporação de toda a frase, e fornece ao transformador a capacidade de aprender a intenção da frase.
Reconhecimento de intenções
Essa tarefa é realizada essencialmente por dois componentes: a camada de incorporação e sua perda, que são usados durante o treinamento.
Camada de incorporação
O módulo é usado no treinamento, de forma a gerar a perda de máscara, associada à máscara gerada pelo modelo. Isso basicamente gera uma medição de perda entre o token “previsto” ou “preenchido” pela saída do transformador e a verdade fundamental gerada pelo FFN, que usa entradas da incorporação pré-treinada e dos módulos de recursos esparsos do token.
Perda de intenção
Este módulo calcula a perda da saída do transformador e a classificação da intenção da frase (dada pelo módulo de similaridade). Em seguida, é uma entrada para o módulo de perda total, que fornecerá uma medida de aprendizado.
Reconhecimento de entidades
Essa tarefa identifica as entidades na frase inicial, ambos os módulos são usados durante o treinamento.
Campo aleatório condicional (CRF)
Este módulo é usado durante o treinamento para calcular uma perda para as entidades reconhecidas pelo pipeline NLU e pela saída do transformador; essa perda mede a capacidade do transformador de reconhecer entidades relacionadas à frase de entrada.
Perda da entidade
O módulo de perda de entidade recebe a saída do módulo CRF descrito acima, que calculará a medida de quão bem o transformador está identificando entidades na frase.
Módulos de similaridade e perda total
Existem 4 módulos de perda presentes na arquitetura, o módulo de perda de entidade, o módulo de perda de máscara, o módulo de perda intencional e o módulo de perda total. O objetivo desses módulos é o mesmo: calcular a fórmula para cada perda específica com suas entradas e gerar o valor da perda. Esses módulos são essenciais para o treinamento e fornecem uma das características mais importantes do modelo DIET: a capacidade de inferir a intenção e o reconhecimento da entidade ao mesmo tempo. O módulo de similaridade é apenas um caso particular de módulo de perda, que é usado para comparação de duas entradas diferentes, em um caso, relacionadas à máscara, comparando a saída do transformador com a saída do FFN do token mascarado. Além disso, ao comparar o token CLS de toda a frase com a intenção da frase. Sua saída fornece uma medida de quão semelhantes são suas entradas, essencial para calcular as perdas descritas anteriormente.
Transformador
Esse módulo é a parte principal da arquitetura, ele recebe os recursos processados dos tokens (do FFN e da incorporação pré-treinada) e, em seguida, gera o valor de cada token, se é uma entidade ou não, e qual é a palavra mascarada. Esse módulo, por padrão, consiste em 2 camadas, mas pode ser personalizado. Este módulo é afetado por todas as três perdas durante o treinamento.
Treinamento
Uma função de perda geral é usada para treinar o FFN compartilhado, incorporações pré-treinadas, CRF, transformador e incorporações. Isso é feito combinando três tipos de perdas diferentes em uma métrica: a perda da máscara, a perda da entidade e a perda intencional na perda geral. A ideia é que essas diferentes perdas desencadeiem modificações de pesos por meio de gradiente descendente em diferentes etapas ou iterações, quando alguma parte do pipeline comete um erro, a fim de corrigir e melhorar seu desempenho. Por exemplo, se o transformador falhar em reconhecer alguma entidade, isso se refletirá na “perda de entidade” gerada a partir da saída do módulo CRF, o que levará a um ajuste dos pesos do transformador e das camadas anteriores (FFN, incorporações pré-treinadas). Como outro exemplo, se o transformador não conseguir prever corretamente a palavra mascarada, isso se refletirá na “perda de máscara” calculada a partir do módulo de similaridade. Como resultado das camadas de incorporação, de forma semelhante ao exemplo anterior, o gradiente descendente cuidará disso, ajustando os pesos dos módulos envolvidos. Finalmente, depois de treinar o módulo, dados adicionais podem ser usados para ajustar o modelo, consistindo em exemplos diferentes para cada intenção, que serão então processados. Isso fornecerá ao modelo algum domínio do idioma e uma ideia mais precisa da classificação necessária para as previsões. nlu: - intent: greet examples: | - hey - hello - oi - hello there - bom dia - boa noite - moin - hey there - vamos lá - hey cara - bom dia - boa noite - boa tarde - intenção: adeus exemplos: | - cu - good by - cee você mais tarde - boa noite - tchau - adeus - tenha um bom dia - te vejo por aí - tchau tchau - até mais tarde - intenção: afirme exemplos: | - sim - y - de fato - é claro - isso soa bem - correto - intenção: negue exemplos: | - não - n - nunca - acho que não - não gosto disso - de jeito nenhum - na verdade não - intenção: mood_great examples: | - perfeito - ótimo - incrível - me sentindo como um rei - maravilhoso - estou me sentindo muito bem - eu sou ótimo - eu sou incrível - eu vou salvar o mundo - super feliz - extremamente bom - tão perfeito - tão bom - tão perfeito - tão perfeito - intenção: od_unhappy examples: | - meu dia foi horrível - estou triste - não me sinto muito bem - estou decepcionada - muito triste - estou muito triste - triste - muito triste - infeliz - não está bem - não muito bem - extremamente triste - tão triste - tão triste - tão triste - intent: exemplos de bot_challenge: | - você é um bot? - você é humano? - Estou falando com um bot? - Estou falando com um humano?
Exemplo de ajuste fino de dados para o modelo de treinamento.
Inferência
Após a etapa de ajuste fino, precisamos de um modelo de inferência. A única entrada necessária é uma frase, que será então fornecida ao modelo descrito acima. A saída será a intenção da frase (uma classe entre as listadas durante o ajuste fino) e as entidades reconhecidas nas frases. A inferência é 6x mais rápida do que o BERT treinado nas mesmas tarefas. Isso se deve à arquitetura modular, que permite um modelo leve. O tempo de execução pode variar de acordo com as diferentes configurações. {"text” :"Isso é incrível!” , “intent”: {"name” :"mood_great”, "confidence” :0.9996907711029053}, "entities”: [], "text_tokens”: [[0,4], [5,7], [8,15]], "intent_ranking”: [{"name” :"mood_great”, "confiança” :0.9996907711011011053} 29053}, {"nome” :"negar”, "confiança” :0.0001600375398993492}, {"nome” :"bot_challenge”, "confiança” :5.5457232519984245e-5}, {"nome” :"afirmar”, "confiança” :3.597023169277236e-5}, {"nome” :"gre"et”, "confiança” :2.746816971921362e-5}, {"name” :"adeus”, "confiança” :2.5115507014561445e-5}, {"name” :"mood_unhappy”, "confiança” :5.233784577285405e-6}], "response_selector”: {"all_retrieval_retrieval_intenções”: [], "padrão”: {"resposta”: {"respostas” :null, “confiança” :0.0, “intent_response_key” :null, "utter_action” :"utter_none "}, "classificação”: []}}}
Exemplo de resposta do modelo.
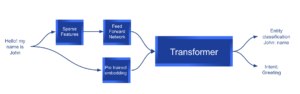
Esse diagrama mostra um exemplo do modelo no momento da inferência.
Vantagens em comparação com modelos similares
O DIET apresenta várias melhorias e vantagens em relação a modelos semelhantes que executam as mesmas tarefas:
- Sua capacidade de se adaptar a diferentes cenários:
- o hardware é restritivo (ou seja, executado em um raspberry pi)
- o tempo de inferência é crucial (aplicação em tempo real)
- Mais rápido que a concorrência (x6 mais rápido que o BERT)
- Cálculo do reconhecimento e da intenção da entidade ao mesmo tempo
- Ele também fornece alguns modelos que estão bem ajustados, prontos para uso em determinados domínios
Quando poucos recursos estão restringindo o modelo que pode ser usado, o DIET fornece diferentes alternativas para lidar com cenários como eliminar o módulo de incorporação pré-treinado, reduzir a quantidade de camadas no transformador e aumentar o parâmetro de abandono nas redes FF. Isso ajuda a reduzir a quantidade de memória usada e a diminuir o tempo de inferência.
DIETA na prática
Na Marvik, experimentamos esse modelo para reconhecer e classificar certas frases com rótulos vagamente definidos (coisas do mundo real e não simulações de laboratório:)). Tivemos a chance de testar isso como uma segunda etapa em um pipeline de processamento de artigos e em aplicativos de chatbot, como parte de um ciclo de reciclagem automática. Os resultados foram promissores, mesmo quando comparados a outras arquiteturas de transformadores, e recomendamos seu uso quando classificadores mais simples não estão à altura da tarefa.
Considerações finais
O transformador DIET da RASA tem uma arquitetura muito poderosa. Ele propõe uma nova maneira de entender os transformadores de última geração, com uma função de perda inteligente que resume todos os aspectos do modelo. Sua alta personalização e adaptabilidade a diferentes cenários nos fazem acreditar que é uma alternativa muito promissora em muitos casos e aplicações. Se você quiser saber mais sobre o DIET e como aplicá-lo em seu próprio aplicativo, não hesite em nos contatar!



.png)