.png)
Explicación de NLP Transformer DIET




Los transformadores son un tipo de arquitectura de red neuronal que ha revolucionado la industria en los últimos años. Su popularidad ha ido en aumento debido a la capacidad de los modelos para superar a los modelos más avanzados en la traducción automática neuronal y otras tareas diversas. En Marvik, hemos utilizado estos modelos en varios proyectos de PNL y nos gustaría compartir un poco de nuestra experiencia. En particular, en este artículo vamos a revisar y discutir RASAla arquitectura de transformadores más reciente y las ventajas que presenta esta innovadora arquitectura.
¿Qué es DIET?
DIET es un transformador multitarea desarrollado por RASA, que sirve para el reconocimiento de entidades y la clasificación de intenciones. Es altamente adaptable a diferentes escenarios y configuraciones. Gracias a su arquitectura modularizada, se puede ajustar en gran medida, lo que lo hace muy útil en múltiples aplicaciones. Incluso proporciona una interfaz interactiva demostración de sus módulos de arquitectura.
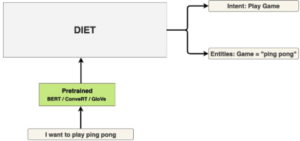
¿Cómo funciona?
En esta sección vamos a describir la arquitectura y cómo se ejecutan el entrenamiento y la inferencia. Para explicar cómo realiza ambas tareas (clasificación de intenciones y reconocimiento de entidades) al mismo tiempo.
Arquitectura
En el siguiente diagrama hay un diagrama de arquitectura de alto nivel que muestra las diferentes piezas del modelo y cómo están conectadas.
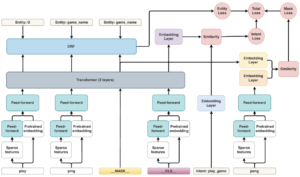
Imagen de arquitectura DIET del blog de RASA
Módulos
La arquitectura de DIET se basa en módulos, que tienen un transformador multicapa como componente clave de la arquitectura. Los diferentes módulos se describirán en esta sección.
Preprocesamiento de entradas
Los módulos que se describen a continuación se encargan de preprocesar los datos de entrada para generar las características necesarias para el módulo transformador.
Incrustación previamente entrenada
El objetivo de este módulo es proporcionar una entrada al transformador relacionada con el token en una determinada incrustación. Se trata de un módulo prediseñado para «conectar y usar», ya que hay muchas alternativas, entre ellas: BERT, ConVe, ConverT. La incrustación de casi cualquier palabra funcionaría sin necesidad de escribir código. Si se necesita una versión más ligera del modelo, este módulo puede incluso eliminarse.
Características dispersas
Este módulo genera funciones dispersas para los tokens en formación; es esencialmente un FFN, con conexiones escasas. La idea es que, además de la incrustación generada por el módulo de incrustación previamente entrenado, se añadan más funciones a medida que los datos de entrenamiento pasan por el modelo, a fin de proporcionar más información sobre el token al transformador.
Alimentación hacia adelante
Este módulo consiste en una red neuronal (NN) totalmente conectada que puede tener diferentes entradas según la parte de la arquitectura a la que esté conectada, pero su salida siempre es una matriz de 256 tamaños. Hay dos redes de alimentación directa diferentes en la arquitectura: la entrada de la primera son las características dispersas de algún token, y la entrada de la segunda es la incrustación previamente entrenada, concatenada con la salida de la primera FFN. El caso de uso es el mismo en ambos casos: aprender las funciones de los tokens que se utilizarán más adelante como entradas del módulo Transformer. Tenga en cuenta que las entradas de las funciones dispersas son matrices dispersas, por lo que, para que el modelo sea más ligero, se implementa de forma predeterminada una interrupción del 80% de las conexiones (esto es personalizable y, a menudo, se recomienda aumentarlo al 90% si se necesita un modelo más ligero).
Tokens Mask y CLS
No se trata de módulos, sino de componentes clave de la arquitectura, porque así es como el modelo aprende a realizar ambas tareas al mismo tiempo. El símbolo de máscara se aplica al azar en una palabra de la oración. Luego, se envía al transformador, que le permite predecir qué ficha estaba enmascarada y, a continuación, aprender a través de un gradiente descendente. El token CLS es una representación de la oración completa, similar a una incrustación de la oración completa, y permite al transformador aprender la intención de la oración.
Reconocimiento de intenciones
Esta tarea la realizan esencialmente dos componentes: la capa de incrustación y su pérdida, que se utilizan durante el entrenamiento.
Capa de incrustación
El módulo se usa en el entrenamiento para generar la pérdida de máscara asociada a la máscara generada por el modelo. Básicamente, esto genera una medición de pérdidas entre el token «previsto» o «rellenado» por la salida del transformador y la verdad básica generada por el FFN, que utiliza las entradas de la incrustación previamente entrenada y los escasos módulos de funciones del token.
Pérdida de intención
Este módulo calcula la pérdida de la salida del transformador y la clasificación de intención de la oración (dada por el módulo de similitud). Luego pasa como entrada al módulo de pérdida total, que proporcionará una medida del aprendizaje.
Reconocimiento de entidades
Esta tarea identifica las entidades de la oración inicial, ambos módulos se utilizan durante la capacitación.
Campo aleatorio condicional (CRF)
Este módulo se usa durante el entrenamiento para calcular una pérdida para las entidades reconocidas por la canalización NLU y la salida del transformador; esta pérdida mide la capacidad del transformador para reconocer las entidades relacionadas con la oración de entrada.
Pérdida de la entidad
El módulo de pérdida de entidades recibe la salida del módulo CRF descrito anteriormente, que calculará la medida de la calidad del transformador para identificar las entidades de la oración.
Módulos de similitud y pérdida total
Hay 4 módulos de pérdida presentes en la arquitectura: el módulo de pérdida de entidad, el módulo de pérdida de máscara, el módulo de pérdida de intención y el módulo de pérdida total. El propósito de estos módulos es el mismo: calcular la fórmula para cada pérdida en particular con sus entradas y generar el valor de la pérdida. Estos módulos son esenciales para la formación y proporcionan una de las características más importantes del modelo DIET: la capacidad de inferir la intención y el reconocimiento de la entidad al mismo tiempo. El módulo de similitud es solo un caso particular de módulo de pérdidas, que se utiliza para comparar dos entradas diferentes, en un caso, relacionadas con la máscara, comparando la salida del transformador con la salida del FFN del token enmascarado. Además, al comparar el token CLS de toda la oración con la intención de la oración. Su salida proporciona una medida de la similitud de sus entradas, algo esencial para calcular las pérdidas descritas anteriormente.
Transformador
Este módulo es la parte clave de la arquitectura, recibe las características procesadas de los tokens (del FFN y de la incrustación previamente entrenada) y, a continuación, genera el valor de cada token, si es una entidad o no, y cuál es la palabra enmascarada. Por defecto, este módulo consta de 2 capas, pero se puede personalizar. Este módulo se ve afectado por las tres pérdidas sufridas durante el entrenamiento.
Entrenamiento
Se utiliza una función de pérdida general para entrenar el FFN compartido, las incrustaciones preentrenadas, el CRF, el transformador y las incrustaciones. Para ello, se combinan tres tipos de pérdidas diferentes en una sola métrica: la pérdida oculta, la pérdida de la entidad y la pérdida intencionada para convertirla en la pérdida general. La idea es que estas diferentes pérdidas provoquen modificaciones de ponderación mediante la reducción del gradiente en diferentes etapas o iteraciones, cuando alguna parte del proceso cometa un error, con el fin de corregir y mejorar su rendimiento. Por ejemplo, si el transformador no reconoce alguna entidad, esto se reflejará en la «pérdida de entidad» generada a partir de la salida del módulo CRF, lo que provocará un ajuste de los pesos del transformador y de las capas anteriores (FFN, incrustaciones preentrenadas). Como otro ejemplo, si el transformador no puede predecir correctamente la palabra enmascarada, esto se reflejará en la «pérdida de máscara» calculada a partir del módulo de similitud. Como resultado de la incrustación de capas, al igual que en el ejemplo anterior, el gradiente descendente se encargará de ello, ajustando los pesos de los módulos involucrados. Por último, después de entrenar el módulo, se podrían usar datos adicionales para ajustar el modelo, que consiste en diferentes ejemplos para cada intención, que luego se procesarán. Esto proporcionará al modelo un poco de dominio del lenguaje y una idea más precisa de la clasificación necesaria para las predicciones. nlu: - intención: saludo ejemplos: | - hey - hola - hola - hola - buenos días - buenas noches - moin - hola, vamos, hola, amigo, buenas noches, buenas tardes, intención: adiós ejemplos: | - cu - cee, más tarde - buenas noches - adiós - adiós - que tengas un buen día - nos vemos - adiós - nos vemos más tarde - intención: afirmar ejemplos: | - sí - y - de hecho - por supuesto - eso suena bien - correcto - intención: negar ejemplos: | - no - n - nunca - no lo creo - no me gusta eso - de ninguna manera - no realmente - intención: mood_great ejemplos: | - perfecto - genial - increíble - me siento como un rey - maravilloso - Me siento muy bien - soy genial - soy increíble - voy a salvar el mundo - súper entusiasmado - extremadamente bueno - tan perfecto - tan perfecto - tan perfecto - mood__ejemplos infelices: | - mi día fue horrible - Estoy triste - No me siento muy bien - Estoy decepcionado - súper triste - estoy tan triste - triste - muy triste - infeliz - no está bien - no muy bien - extremadamente triste - tan triste - tan triste - intent: bot_challenge examples: | - ¿eres un bot? - ¿eres un humano? - ¿estoy hablando con un bot? - ¿Estoy hablando con un humano?
Ejemplo de ajuste fino de datos para un modelo de entrenamiento.
Inferencia
Tras el paso de ajuste, necesitamos un modelo de inferencia. La única entrada necesaria es una oración, que luego se proporcionará al modelo descrito anteriormente. El resultado será la intención de la oración (una clase entre las que figuran durante el ajuste fino) y las entidades reconocidas en las oraciones. La inferencia es 6 veces más rápida que la realizada por BERT para realizar las mismas tareas. Esto se debe a la arquitectura modular, que permite un modelo ligero. El tiempo de ejecución puede variar según las diferentes configuraciones. {"text» :"Eso es increíble!» , "intent»: {"name» :"mood_great», "confidence» :0.9996907711029053}, "entities»: [], "text_tokens»: [[0,4], [5,7], [8,15]], "intent_ranking»: [{"name» :"mood_great», "confidence» :0.9996907711029053}, {«nombre» :"negar», "confianza» :0.0001600375398993492}, {"nombre» :"bot_challenge», "confianza» :5.5457232519984245e-5}, {"nombre» :"afirmar», "confianza» :3.597023169277236e-5}, {"nombre» :"saludo», "confianza» :2.746816971921362e-5}, {"name» :"adiós», "confianza» :2.5115507014561445e-5}, {"name» :"mood_unhappy», "confianza» :5.233784577285405e-6}], "response_selector»: {"all_retrieval_intents»: [], "default»: {"response»: {"responses» :null, "confidence» :0.0, "intent_response_key» :null, "utter_action» :"Utter_none "}, "ranking»: []}}}
Ejemplo de respuesta del modelo.
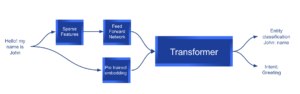
Este diagrama muestra un ejemplo del modelo en el momento de la inferencia.
Ventajas en comparación con modelos similares
DIET presenta varias mejoras y ventajas con respecto a modelos similares que realizan las mismas tareas:
- Su capacidad para adaptarse a diferentes escenarios:
- el hardware es restrictivo (es decir, se ejecuta en una raspberry pi)
- el tiempo de inferencia es crucial (aplicación en tiempo real)
- Más rápido que la competencia (x6 veces más rápido que BERT)
- Cálculo del reconocimiento y la intención de la entidad al mismo tiempo
- También proporciona algunos modelos que están ajustados y listos para usarse en ciertos dominios.
Cuando la escasez de recursos restringe el modelo que se puede utilizar, DIET ofrece diferentes alternativas para hacer frente a situaciones como la eliminación del módulo de incrustación previamente entrenado, la reducción de la cantidad de capas en el transformador y el aumento del parámetro de abandono en las redes FF. Esto ayuda a reducir la cantidad de memoria utilizada y a reducir el tiempo de inferencia.
DIETA en la práctica
En Marvik experimentamos con este modelo para reconocer y clasificar ciertas oraciones con etiquetas poco definidas (cosas del mundo real y no simulaciones de laboratorio:)). Tuvimos la oportunidad de probarlo como segundo paso en un proceso de procesamiento de artículos y en aplicaciones de chatbots, como parte de un ciclo de reentrenamiento automático. Los resultados fueron prometedores, incluso si se comparan con otras arquitecturas de transformadores, y recomendamos su uso cuando los clasificadores más simples no estén a la altura de la tarea.
Reflexiones finales
El transformador DIET de RASA tiene una arquitectura muy potente. Propone una nueva forma de entender los transformadores de última generación, con una función de pérdida inteligente que resume todos los aspectos del modelo. Su alta capacidad de personalización y adaptabilidad a diferentes escenarios nos hace creer que es una alternativa muy prometedora en muchos casos y aplicaciones. Si quieres saber más sobre DIET y cómo aplicarlo en tu propia aplicación, ¡no dudes en ponerte en contacto con nosotros!



.png)