
Turning a Unitree G1 EDU+ into a conversational humanoid



A two-tier reasoning brain on OpenClaw, an on-prem Ollama stack, and an audio pipeline that took longer to ship than the LLM.
A few weeks ago I stood next to a Unitree G1 EDU+ in our lab, said "jarvis" out loud, and waited. The robot - we call it Willy - answered in a cloned voice, asked me who I was looking for, and a few seconds later a Slack DM landed on my colleague's phone. The interesting part is not what you can see. It is what had to be in place underneath for it to work.
Willy is a Unitree G1 EDU+ humanoid wrapped in a production conversational stack: a Porcupine wake word on the robot, Whisper large-v3-turbo for STT, an OpenClaw two-tier reasoning brain talking to local Ollama, XTTS-v2 for cloned voice, and DDS-driven gestures. The whole reasoning loop runs on-premise. Nothing the robot hears leaves the network.
This post is the engineering story of how we turned a developer-friendly humanoid into a conversational system: what works today, which architecture choices mattered, and where the hard problems actually were.

The problem: a humanoid is not a product until it can talk
The Unitree G1 EDU+ is one of the few full-size humanoids that is commercially available and developer-friendly. Unitree provides access to open source Python SDK, DDS topics, a Python wrapper, built-in cameras, hands, and an onboard Jetson. That is enough to start building.
Unitree provides the robotic platform, but the production-grade conversational layer has to be built on top.
For real-world human-facing robotics, the robot needs to do more than execute predefined gestures. It needs to listen, determine whether the request is simple or complex, respond as quickly as possible, use predefined tools when appropiate , and fail in ways that are understandable to a human standing in front of it.
This gap is what we built on this use case.
What is up and running
As mentioned before, the current system is not just a scripted demo. It is an end-to-end conversational loop with measurable latency budgets and explicit escalation paths.
These requirements shaped the architecture. A humanoid does not feel human-like because the model is large. It feels alive because it answers before you stop expecting it to.
Three hosts, one robot
The runtime spans three machines:
- Mac: operator console. Development, documentation, and SSH entry. It is not in the runtime path.
- Inference Host: Linux box with 2x NVIDIA A40 GPUs. It runs Ollama, Whisper large-v3-turbo, XTTS-v2, the OpenClaw CLI and Gateway, and the Slack handoff tooling.
- PC2: the Unitree G1's onboard Jetson Orin NX. It runs the conversational orchestrator, the action dispatcher, the wake word listener, the USB mic, and speaker playback via DDS.
PC2 and the Inference Host communicate over SSH and HTTP. PC2 and the G1 EDU+ communicate over DDS on the robot's internal Ethernet bus.
This split is pragmatic: PC2 stays close to the robot for I/O and control, while the Inference Host carries the heavy inference and tool-using agent work.
Based on the provided resources and the requirements, the main architectural decisions made for the full design were the following:
Decision 1: two tiers, one brain
Most utterances do not need as 'big' a model as one with 30B hyperparameters. "What time is it?", "Where is the meeting room?", and "Wave hi" need a fast answer. More complex requests like"Tell Lucas I'll be late and ask him to move the meeting" requires tool usage, identity resolution, and Slack delivery.
So, we split the brain in two: a Fast path for simple-quick responses, a Complex path for higher reasoning demand.
The full loop is easier to understand as a routed tree: firstly, the wake word and initial capture, secondly, transcription. Third and lastly a fast router that either answers locally, asks a clarification, or escalates to OpenClaw.
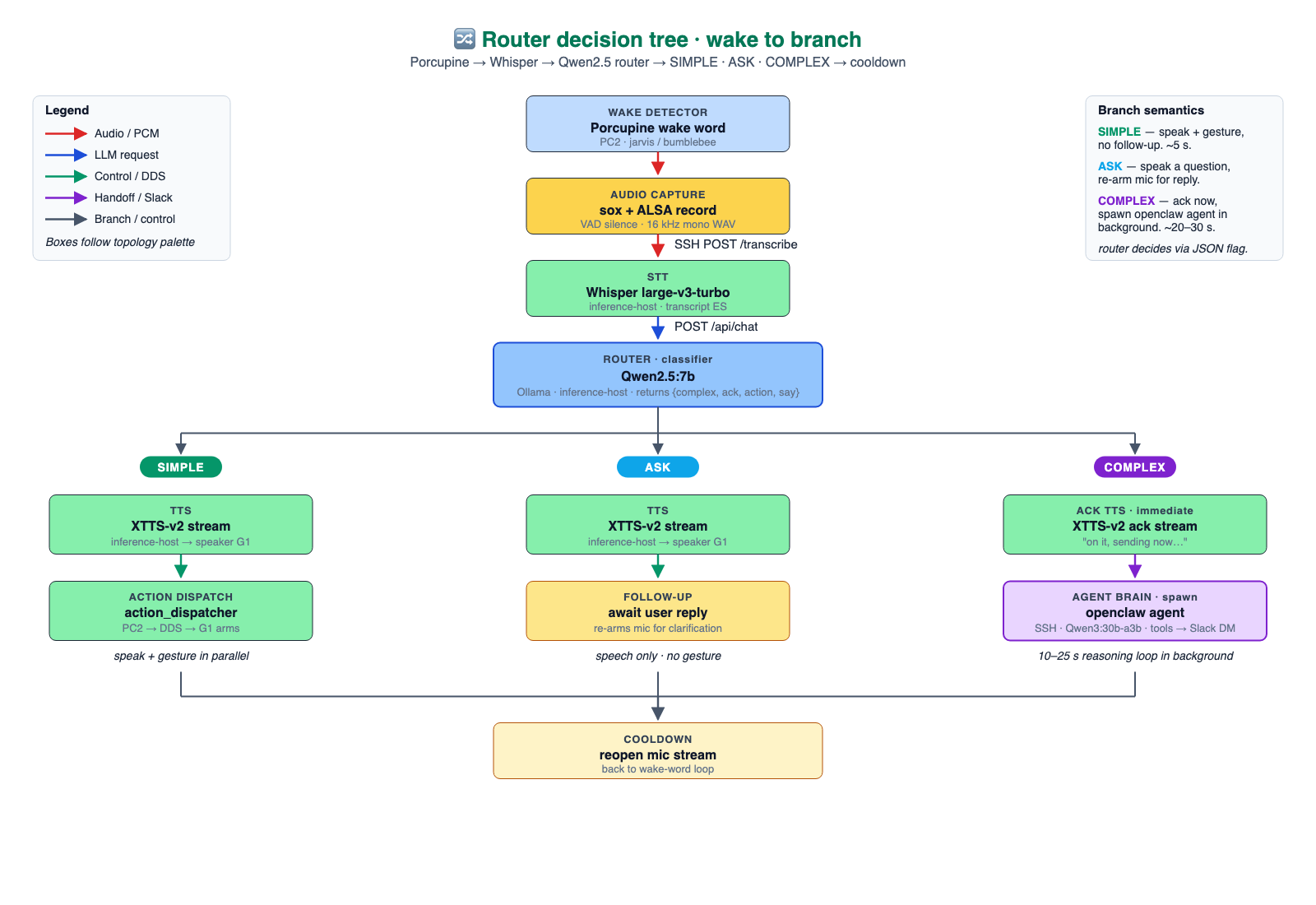
Fast path: Qwen2.5-7B as a JSON router
When a transcript arrives at the conversation function (willy_conversational_v2.py) on PC2, it is routed to Qwen2.5-7B on Ollama with a strict JSON-mode prompt. The router emits one of three shapes:
{ "complex": false, "action": "shake_hand", "say": "Hola." }
{ "ask": true, "question": "Can you repeat the name?" }
{ "complex": true, "ack": "Give me a second.", "intent": "..." }
With prewarm, the router responds in about 600 ms. That budget is the difference between a robot that feels present and a robot that feels like a kiosk with legs.
.png)
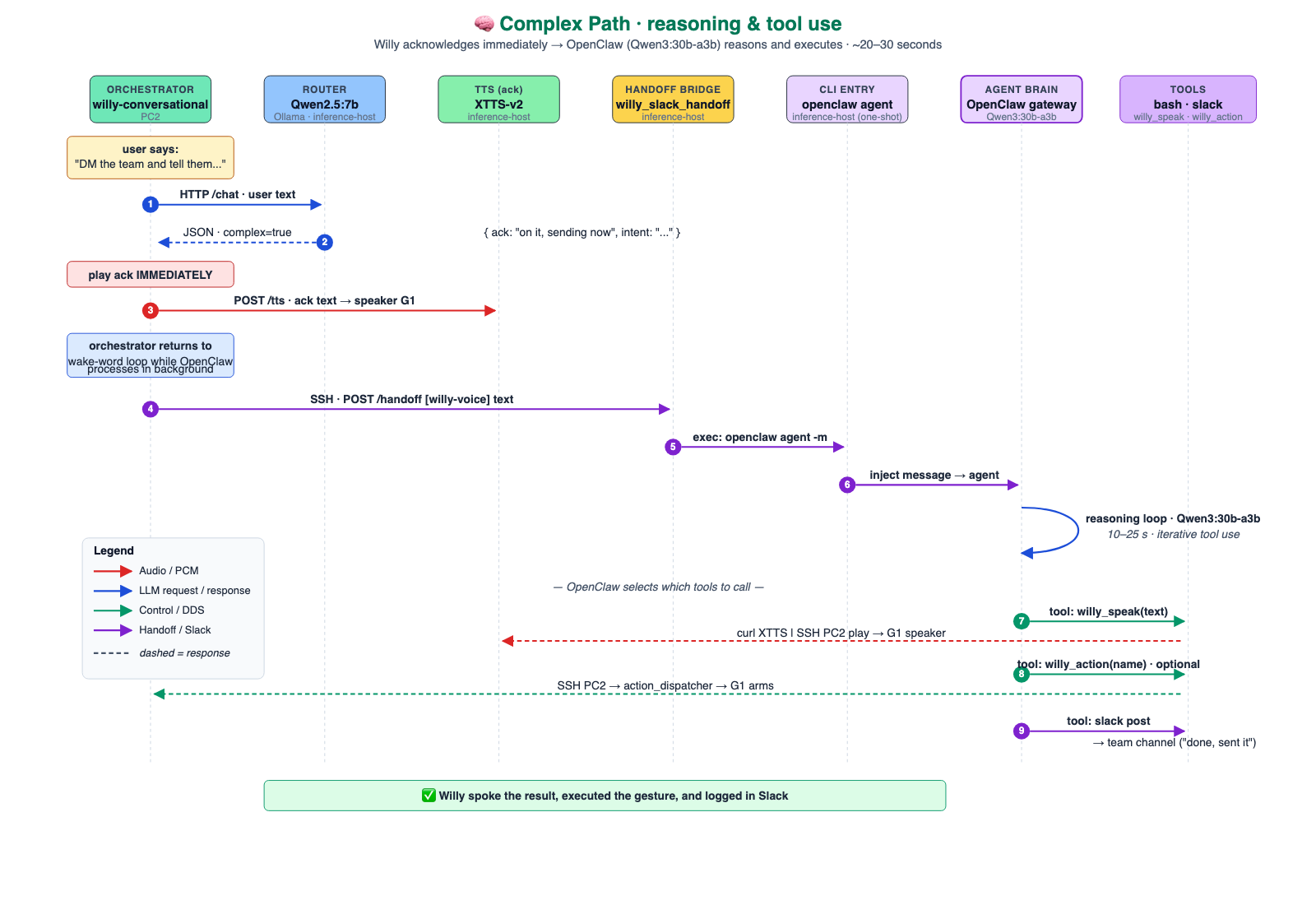
Complex path: OpenClaw + Qwen3-30B-A3B
When the router returns complex: true, two things happen in parallel:
- XTTS-v2 streams a short voice acknowledgment so the human is not waiting in silence.
- PC2 SSHes into the Inference Host and spawns openclaw agent as a one-shot CLI, passing the transcript and routed intent.
OpenClaw loads its identity and skills, invokes Qwen3-30B-A3B through Ollama, and lets the model choose tools such as shell commands, Slack delivery, and web search. The final action is usually a Slack DM through chat.postMessage.
This separation is intentional. The robot's local loop stays small and predictable: listen, route, speak, and execute bounded actions. OpenClaw handles the slower work: reasoning over context, choosing tools, writing Slack messages, and returning a traceable outcome. That is what keeps the humanoid responsive while still giving it access to richer workflows.
Decision 2: audio, the real bottleneck
The most surprising part of building Willy is that the LLM was not the hard part (model selection took about a week). The audio pipeline took about a month.
Usable audio acquisition on the Unitree G1 EDU+
Working with the robot's built-in microphones turned out to be one of the more frustrating early blockers. The G1 EDU+ ships with four onboard digital microphones, but in our setup the Signal to Noise Ratio (SNR) was too poor for reliable wake word detection and transcription. The sources of noise were structural: the Jetson Orin NX, motor drivers, and mechanical vibration from the body contaminated the signal. Software-side fixes — gain correction, custom verifier models, threshold tuning, were not able to compensate meaningfully. The noise floor was simply too high.
The solution was simple: an external USB microphone positioned away from the main noise sources. Once we moved the mic to a location with less mechanical and electrical interference, capture quality improved immediately. ALSA (Advanced Linux Sound Architecture) recognized it out of the box, and from that point on, transcription accuracy stopped being a variable we needed to fight.
The lesson is practical: in a mobile robot, where microphone placement is constrained and the surrounding electronics are noisy, investing in mic position and hardware quality pays off faster than any software workaround. A beamforming array is the likely next step for far-field environments.
We trained a wake word, then replaced it
We trained a custom OpenWakeWord model for "hola willy": 20k Piper-synthesized positives, 20k adversarial negatives, ACAV100M features, room impulse responses and music backgrounds to make it robust. After three iterations we reached 57% recall, mean positive score 0.62, max 0.97, and about 11 false positives per hour. We required a higher success rate to trigger the conversational flow, otherwise the whole thing would be perceived as clumsy or flawed.
Then we benchmarked Picovoice Porcupine with built-in keywords such as jarvis and bumblebee. Porcupine won out of the box: local CPU inference, around 20 ms latency, no training loop, and no account dependency. The custom wake word remains useful knowledge, but for this milestone the zero-config path was the right engineering choice.
Whisper and XTTS as services
Whisper large-v3-turbo runs as an HTTP microservice on the Inference Host. The model loads once at startup and stays in VRAM, so per-utterance inference is around 150 ms on the GPU. We inject an initial prompt with domain-specific vocabulary to reduce mishearing transcription.
For output, XTTS-v2 runs on the same host using a cloned voice reference. The output streams as PCM (Pulse-Code Modulation). into PC2's playback process, which forwards audio to the G1 speaker over DDS.
Decision 3: separated inbound channels for one-shot reasoning
OpenClaw has two entry points, and they solve different problems.
- openclaw-gateway.service is a long-running service. It holds WebSocket connections for inbound channels such as Slack Socket Mode or Discord.
- openclaw agent is a one-shot CLI. It loads the workspace, reasons with Qwen3 through Ollama, uses tools, returns, and terminates the agentic flow.
Willy's voice-to-Slack path uses the OpenClaw CLI. The gateway can be down and the robot can still process complex voice requests because PC2 spawns a fresh openclaw agent for that handoff.
This distinction is highly relevant from the operational perspective; treating both entry points as the same thing creates avoidable debugging noise.
Runtime API and safety
Above the audio loop, Willy exposes a minimal HTTP/WebSocket runtime so the other systems can drive or observe it:
- GET /status: runtime mode, queue depth, active job
- GET /observations/latest: voice, vision, depth, LiDAR, hand, and upper-body state
- POST /actions/speak, /actions/search_lock, /actions/make_coffee, /actions/stop
- WS /events: robot state, perception, action updates, and alerts
Two arbitration rules matter. Only one motion-producing job runs at a time, so speech, gestures, and physical actions are serialized.
The safety model is deliberately layered. The router decides whether a request is simple, incomplete, or complex. The runtime queue serializes motion-producing jobs. OpenClaw does not get unrestricted control of the robot; it can only act through exposed tools and runtime endpoints. Higher-risk routines require an explicit safety enable before execution, and stop remains available at all times as an operational interrupt.
What we learned
If we had to summarize the project for our past selves:
- Pick the LLM by stress testing, not vibes. Targeted tests on planning, replanning, strict JSON, deep retrieval, tool summarization, warm-series stability, and format pressure shaped the two-tier Qwen2.5 + Qwen3 design.
- Two tiers beat one large model. A 7B router that decides when to call a 30B reasoner gives a better user experience than always calling the larger model.
- The robot's mic was the bottleneck, not the model. Whisper provides fast model inference; audio capture, silence detection, and microphone quality dominate the experience.
- Separate channels: one for reasoning, one for action: Inbound messages, one-shot agent reasoning, and robot motion should be different layers with explicit boundaries.
- Pre-record the boring greetings. A short WAV for common phrases can feel more alive than waiting for TTS on every line.
Possible applications
The same architecture can generalize to several classes of human-facing robot applications:
- Front-desk and reception flows. Greeting visitors, answering common questions, routing requests, and handing off complex tasks to human teams.
- Guided assistance in physical spaces. Combining voice, gestures and tools can be used to help people navigate buildings, events, or internal operations.
- Light operational support. Triggering internal workflows, sending messages, reporting status, and connecting physical interactions to existing business systems.
At Marvik, we build end-to-end AI products: from on-device perception to production-grade LLM agents. The work that matters is not just the model. It is the integration: audio, latency, safety, identity, tools, and the operational path that turns a humanoid into a system a human is willing to interact with twice.
Every AI journey starts with a conversation. If you are working on humanoid orchestration, on-prem agentic LLMs, or voice-first robotics, we'd love to talk.
Sources
Unitree G1 EDU+ · Ollama · Qwen2.5 / Qwen3 · Whisper large-v3-turbo · XTTS-v2 (Coqui) · Picovoice Porcupine · OpenWakeWord · Piper TTS · unitree_sdk2_python



.png)