.png)
Identificación de grandes talentos: desde currículos hasta habilidades para aplicar la PNL




Introducción
El desafío de conectar los talentos con las oportunidades de empleo ha sido una tarea importante de los reclutadores durante mucho tiempo. La búsqueda siempre depende del presupuesto, las especificaciones del puesto y el tiempo, por lo que siempre surgen dudas: ¿estamos obteniendo la mejor opción? ¿o uno lo suficientemente bueno? Los sistemas de recomendación son una herramienta poderosa para proporcionar a los usuarios sugerencias personalizadas y en tiempo real. Probablemente los hayas estado usando mucho, al pedir comida, al elegir un programa para ver o al comprar productos y servicios en línea. En este post te explicamos cómo el equipo de Marvik abordó la fase de extracción de habilidades en una aplicación en la que nos preguntábamos cómo hacer coincidir los mejores perfiles con los puestos vacantes, pasando por el aprendizaje automático y muchísimas (¡muchísimas!) de datos. El proyecto ha sido un viaje increíble (a veces una montaña rusa) que ha requerido mucha innovación en términos de combinación de técnicas, algoritmos de aprendizaje automático y las herramientas adecuadas para crear las coincidencias.

🔥 El desafío
En nuestro objetivo de generar pares de ofertas de trabajo: solicitantes, nos enfrentamos a varios desafíos. Para empezar, como cualquier proyecto relacionado con los datos, los datos en sí mismos. Aunque podríamos acceder a un gran volumen de datos (miles de gigas), estos podrían no estar estructurados, tener una extensión diferente (es decir, doc, docx o pdf, entre otros) o estar incompletos. Además, el rendimiento era imprescindible (nadie quiere esperar a obtener los resultados), por lo que aplicar las mejores técnicas y prácticas de desarrollo, como vapor, lematización, árboles de búsqueda, con las herramientas adecuadas (índice invertido por ejemplo), fue crucial en cada etapa.
Del texto al la representación vectorial
📄 Un poco de calentamiento
La bolsa continua de palabras (CBOW) es una técnica en la que el objetivo es predecir la palabra actual, teniendo en cuenta una ventana de palabras circundantes (antes y después). Como alternativa, el diagrama de omisión continua intenta predecir la posición del contexto mencionado en la palabra actual. Habilidad 2 Vec es una técnica basada en el gramaje CBOW y C-Skip para obtener habilidades a partir de documentos. Su principal ventaja es el espacio vectorial generado donde se representa la relación entre las habilidades. Además, Doc2Vec tiene una usabilidad similar, ya que se reciben entradas de fichas y se obtiene un vector único, con la ventaja de la similitud entre las distancias vectoriales cuando las entradas tienen significados similares.
Basta de teoría: ¡manos a la obra!
Para obtener un vector que describa el perfil de un candidato y los requisitos básicos de un puesto, hemos agrupado skill2vec y doc2vec para utilizarlos como lista blanca para extraer las habilidades mencionadas y crear plano (vector único), respectivamente.
🙋 Candidatos y oportunidades
El proceso de extracción de habilidades fue nuestra primera tarea y la entrada involucrada (CV) no tenía un formato definido, como dijimos antes. Una vez que lo recibimos, extrajimos el texto y obtuvimos las habilidades a través de Skill2vec. Lo mismo se hizo con la descripción del puesto. Por ejemplo, dado el siguiente extracto de currículum: «Actualmente trabajo como ingeniero de software en company_name. Trabajo basado en ERP. En este trabajo estoy realizando el módulo de recursos humanos. Básicamente hago este trabajo usando postgresql, osslib, js y PHP. Además de mi profesión, he completado mi maestría.« Obtuvimos este conjunto de habilidades: postgresql, osslib, js, php. Y, de la siguiente descripción del puesto: «En este puesto, debes ser un jugador de equipo con un buen ojo para los detalles y habilidades para resolver problemas. Si también tienes experiencia en marcos ágiles y lenguajes de programación populares (por ejemplo, JavaScript), nos gustaría conocerte. Este puesto requiere:
- Trabaje con los desarrolladores para diseñar algoritmos y diagramas de flujo
- Produzca código limpio y eficiente basado en las especificaciones
- Integre componentes de software y programas de terceros
- Experiencia comprobada como desarrollador de software, ingeniero de software o puesto similar
- Experiencia en diseño y desarrollo de software en un entorno basado en pruebas
- Conocimiento de lenguajes de codificación (por ejemplo, C++, Java, JavaScript) y marcos/sistemas (por ejemplo, AngularJS, Git)
- Experiencia con bases de datos y marcos de mapeo relacional de objetos (ORM) (por ejemplo, Hibernate)
- Capacidad para aprender nuevos idiomas y tecnologías»
Hemos extraído: agile, javascript, C++, Java, AngularJS, Git, ORM, Hibernate. El siguiente es el proceso que utilizamos para extraer las habilidades:
- extraer texto
- dividirlo por palabras (además, referenciado como token)
- eliminar palabras de parada
- lematizar
- vocabulario de comparación
Estos pasos también se replican con la descripción del trabajo como entrada.
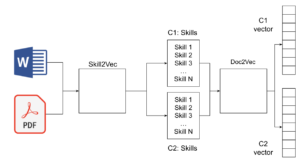
Por lo tanto, en este punto teníamos las habilidades en forma de lista de fichas. Esa estructura era nuestra documento, que se utiliza para obtener la representación vectorial. A diferencia de Skill2Vec, que ya estaba entrenado, tuvimos que entrenar a doc2vec por nuestra cuenta. Nos ajustamos al modelo, introduciendo más de un millón de documentos y obtuvimos un resultado impresionante. Una de las principales ventajas de doc2vec es la incrustación que contiene, por lo que las salidas son muy precisas.
🔍 Comprobar los resultados
En ese momento, estábamos entusiasmados con la exactitud de nuestro resultado (recomendaciones), pero también necesitábamos tener en cuenta los requisitos de nuestro cliente con respecto al rendimiento. Por lo tanto, combinamos dos técnicas extraordinarias para obtener resultados: la aproximación de los vecinos más cercanos (ANN) y la distancia de movimiento de palabras (WMD). Con ANN, tenemos (en términos generales) un vecindario de talentos que podrían estar relacionados, pero estos resultados preliminares necesitaron un poco de limpieza y depuración. Después de eso, aplicamos la distancia entre palabras como filtro en los documentos relacionados (vectores), a fin de obtener los mejores candidatos (más cercanos) para un puesto vacante.
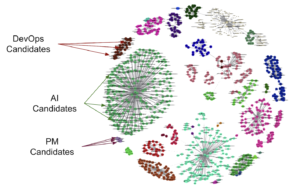
Vale, ¿y ahora qué? Lecciones y conclusiones
Para concluir, ¡hay algunos puntos destacados y lecciones para compartir! Probablemente el básico era el antiguo, pero confiable divide y conquista, teniendo en cuenta que nos enfrentamos a muchos obstáculos para construir el modelo. Del mismo modo, desde su lanzamiento, el cliente ha estado sirviendo varios partidos y está muy contento con el resultado. Además, estamos haciendo una lluvia de ideas para aplicar estas técnicas al asesoramiento profesional a fin de combinar las trayectorias profesionales con los talentos, una medida proactiva por nuestra parte. Antes de despedirnos, no olvides que puedes enviarnos un ping a marvik.ai para comentar las ideas, los proyectos o las dudas que puedas tener.



.png)