.png)
Bienvenido a Marvik Digest 🚀




Tenemos noticias interesantes. Nos complace anunciar el lanzamiento de Marvik Digest 🙌 🚀. Os mantendremos informados sobre los temas más relevantes que se han debatido en la comunidad de aprendizaje automático en las últimas semanas. ¿Quieres que tratemos un tema específico? Envíanos un mensaje de texto o un ping a [email protected] para enviarnos sus sugerencias. ¡Estén atentos para más contenido! Flamenco Como seres humanos, nuestra experiencia del mundo es multimodal. Podemos oír, saborear, ver, sentir y oler cosas. Para #machinelearning para ayudar a resolver los desafíos del mundo real, debe poder crear modelos que puedan procesar e interpretar de manera eficiente la información que proviene de diferentes fuentes de datos (imagen 🌅, texto 📄, discurso 💬, numérico 🔢). Ahora estamos más cerca de lograrlo con Mente profundala reciente introducción de #flamingo 🦩, un modelo de última generación que puede abordar sin problemas imágenes 🌅, texto 📄 e incluso vídeos 📹. Es un modelo de lenguaje visual (#vlm) que puede adaptar rápidamente su comportamiento con solo un par de ejemplos específicos de tareas, sin necesidad de ningún entrenamiento adicional 🏋️ ♀️ (como se ve más abajo al pasar la prueba de Stroop). Hasta ahora, los resultados muestran que, en el caso de las tareas abiertas (como la respuesta visual a las preguntas), 🦩 supera en rendimiento a los modelos que utilizan muchos más datos específicos de la tarea. 👉 Para leer la historia completa, visite https://bit.ly/3vVkj6G

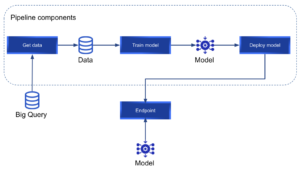
Vertex AI ¿Alguna vez te has esforzado por poner #ml modelos en producción? Por lo general, este proceso consume una gran cantidad de tiempo y recursos. En este artículo, nuestro ingeniero de aprendizaje automático Federico Baiocco nos habla sobre Googlees servicio #vertexai , lo que nos permite crear, implementar y escalar modelos de aprendizaje automático más rápido con herramientas personalizadas y previamente capacitadas dentro de un sistema unificado #AI plataforma. Él explica paso a paso cómo construir un #kubeflow canalización para entrenar un modelo personalizado, recuperando datos de #bigquery e implementarlo usando #vertexai. «La IA de Vertex facilita el entrenamiento, la implementación y la comparación de los resultados de los modelos. Es una herramienta excelente que nos permite centrarnos en las soluciones de aprendizaje automático en lugar de en la gestión de la infraestructura». 👉 Visite nuestro blog para ver la historia completa https://bit.ly/3OUOtQ3 👉 Ponte en contacto con [email protected] para obtener más información sobre nuestra experiencia con Vertex AI
Hugging face eleva la Serie CCara abrazada recaudó recientemente 100 millones de dólares en una ronda de financiación de la Serie C 🚀🚀 Enhorabuena a todo el equipo 👏👏👏👏 Esta es una gran noticia para el #machinelearning campo. Un paso adelante para seguir avanzando y democratizando la inteligencia artificial a través del código abierto y la ciencia abierta. Gracias por todo el apoyo que constantemente dais a #ml comunidad. 👉 Lea la historia completa aquí: https://bit.ly/3yr2WO2 Otra buena noticia para el #machinelearning comunidad 🙌 🎉

Transformador preentrenado abierto (OPT-175B)Meta IA lanzado recientemente #OpenPretrainedTransformer (OPT-175B), un modelo lingüístico de gran tamaño entrenado en 175 mil millones de parámetros. Hasta ahora, el acceso a modelos de tal escala había estado considerablemente restringido. En línea con el compromiso de Meta AI de #openscience, el modelo se capacitó en conjuntos de datos disponibles públicamente y su publicación incluye tanto los modelos previamente entrenados como el código necesario para capacitarlos y usarlos en casos de uso de investigación. Esto abre nuevas oportunidades para entender cómo y por qué funcionan los modelos lingüísticos de gran tamaño, así como para encontrar formas de mejorar su solidez y mitigar los problemas comunes. Felicitaciones a Meta IA por su compromiso de democratizar e impulsar el campo 👏 👏 👏 👉 Obtenga más información aquí https://bit.ly/3MeYDJX

Gato Un solo #AI modelo que puede realizar más de 600 tipos de tareas? 🤯 Esto se está haciendo posible con Mente profundade la reciente publicación de #gato 🐈, un generalista #AI agente al que se le puede entrenar para subtitular imágenes, entablar diálogos, apilar bloques con un brazo robótico real y jugar a Atari con una arquitectura neuronal de un solo transformador. 🟢 Conclusión principal: 📌 Inspirado en el progreso del modelado de lenguajes a gran escala. 📌 La misma red con el mismo peso puede funcionar con varios tipos de datos para realizar varios tipos de tareas. 📌 En 450 de las 604 tareas utilizadas para entrenar a 🐈, los resultados muestran que se desempeña mejor que un experto más de la mitad de las veces. Sin embargo, su rendimiento no es óptimo en comparación con los modelos entrenados para tareas específicas. 📌 Al aumentar el tamaño de los parámetros, 🐈 tiene el potencial de lograr mejores resultados de rendimiento. Gato 🐈 dista mucho de ser perfecto, pero sin duda es un paso adelante en el largo camino hacia #artificialgeneralintelligence (AGI). 👉 Haga clic aquí para leer más sobre Gato 🐈: https://bit.ly/3leTMwm 👉 Para consultar el artículo original: https://bit.ly/3wAZjSX

Escuela de aprendizaje automático Por fin ha llegado el día 🙌 El lunes dimos la bienvenida al primer grupo de pasantes de la Escuela de Aprendizaje Automático 🚀 🎉 Durante 3 meses, emprenderán un viaje para aprender todo sobre el #machinelearning plantéelos y póngalos en práctica para abordar varios proyectos desafiantes. ¡Estén atentos para recibir más actualizaciones! 📢 👉 ¿Conoces a alguien que podría ser una buena opción para las próximas ediciones? Envía un mensaje de texto o ponte en contacto con [email protected] 👉 ¿Quieres saber más? Visite https://bit.ly/3uCXZPP
Sistemas de recomendación: adecuación de las competencias a los puestos Para las empresas que buscan contratar nuevos talentos 🔍, sabemos que encontrar el talento adecuado para el puesto correcto es un gran desafío. Sin mencionar que tiene un impacto directo en el rendimiento 📈. En este nuevo blog, nuestro #mlengineerArturo Collazo Gil da una pista sobre cómo abordar esto con el uso de sistemas de recomendación. Nos guía a través del proceso de cómo el equipo abordó la extracción de habilidades, tomando como insumos los currículums (CV) y las descripciones de los puestos. «El proyecto ha sido un viaje increíble (a veces una montaña rusa 🎢) que ha requerido mucha innovación en cuanto a la combinación de técnicas, #ML algoritmos y las herramientas adecuadas para crear las coincidencias». 👉 Visita nuestro blog para ver la historia completa https://bit.ly/3Nu7uHG 👉 Ponte en contacto con [email protected] para obtener más información sobre nuestros sistemas de recomendaciones para la creación de experiencias
Imagen Google presenta a su competidor para #DALL · E2 🤯 Imagen es Google nuevo #ai sistema que crea imágenes fotorrealistas a partir del texto introducido con un profundo nivel de comprensión del idioma 🚀 ➡️ Conclusiones principales ✅ Se basa en el poder de los grandes #transformer#languagemodels y #diffusionmodels ✅ Considera que escalar el tamaño del codificador de texto previamente entrenado es más importante que escalar el tamaño del modelo de difusión ✅ Consigue una nueva puntuación FID de última generación de 7,27 en el #COCOdataset ✅ Presenta #DrawBench, un punto de referencia completo y desafiante para los modelos de conversión de texto a imagen ✅ Revela que los evaluadores humanos prefieren con creces Imagen sobre otros métodos ➡️ ¿Quiere saber más? 👉 Visita https://bit.ly/3sXM3am 👉 Para leer el artículo completo https://bit.ly/39ThCLE

Embellecedor de voz neuronal para cantar ¿Un modelo capaz de generar grabaciones de canto de alta calidad y, al mismo tiempo, mejorar la entonación y el tono vocal? 🤯 Investigadores de Universidad de Zhejiang han alcanzado nuevas cotas con el reciente lanzamiento del primer #generativemodel para resolver la tarea de embellecer la voz cantando (#SVB). La modelo, apodada Neural Singing Voice Beautifier (#NSVB), aborda no solo la mejora de la entonación sino también la calidad estética general 🟢 Highlights 📌 Se basa en un codificador automático variacional condicional como pilar y es capaz de aprender las representaciones latentes del tono vocal 📌 Introduce un novedoso enfoque de distorsión temporal para la corrección del tono 📌 Introduce un algoritmo de mapeo latente en el espacio latente para transformar los tonos vocales, de aficionados a profesionales 📌 Propone un nuevo conjunto de datos que contiene las mismas grabaciones de canto de versiones amateur y profesionales 📌 Demuestra su eficacia mediante experimentando con canciones en chino e inglés ➡️ ¿Quieres ver este modelo en acción? Echa un vistazo a los ejemplos de audio aquí https://bit.ly/3x1DVHY




.png)