Cómo usar Sapiens para mejorar las imágenes humanas generadas por IA




Los ordenadores son más potentes que nunca. Esto significa que podemos hacer cosas con la IA que no podíamos hacer en el pasado. Sin embargo, estos nuevos modelos de IA necesitan muchos datos para aprender. Este apetito por los datos se ha abordado con éxito en el procesamiento del lenguaje natural (PNL) mediante una formación previa autosupervisada. Las soluciones son fáciles de entender: eliminan una parte de los datos y aprenden a predecir el contenido eliminado. Estos métodos ahora permiten el entrenamiento de modelos de PNL generalizables que contienen más de cien mil millones de parámetros. Esta idea es natural y también aplicable a la visión artificial. En este blog estudiaremos una familia de modelos, Sapiens, desarrollada por Meta basándose en esta idea.

Arquitectura modelo
El modelo fundamental de Sapiens es un autocodificador enmascarado (MAE). Los codificadores automáticos enmascarados permiten aprender visión artificial de forma autosupervisada. Durante el entrenamiento, se enmascara una parte importante de la imagen y el codificador automático se encarga de reconstruir la imagen original. El MAE que se utiliza en este caso tiene un diseño de codificador-decodificador asimétrico: el codificador solo recibe los parches no enmascarados de la imagen, mientras que el decodificador es ligero y reconstruye la entrada a partir de la representación latente (de los parches visibles) y los parches enmascarados de la imagen. El cambio de los tokens enmascarados al decodificador pequeño reduce en gran medida el cálculo, ya que el codificador solo tiene que procesar una parte de la imagen. En la siguiente imagen tenemos una representación visual de la arquitectura. [caption id="attachment_3624" align="aligncenter» width="703"]

Arquitectura de modelos. Fuente: Los codificadores automáticos enmascarados aprenden con visión escalable[/caption] El modelo fundamental, entrenado en la tarea general de reconstruir imágenes enmascaradas, puede afinarse para resolver problemas más específicos como la segmentación, la profundidad y otros. En la siguiente sección revisaremos algunos de los casos de uso disponibles.
Conjunto de datos Sapiens
¿Qué tipo de datos son más eficaces para la formación previa? Dados los límites computacionales, ¿deberíamos centrarnos en recopilar tantas imágenes como sea posible, o es mejor usar un conjunto más pequeño y organizado? Para explorar esto, los autores crearon un conjunto de datos llamado Humans-300M, con 300 millones de imágenes humanas diversas. Sus hallazgos mostraron que un conjunto de datos bien seleccionado generalmente conducía a un mejor rendimiento en comparación con la simple recopilación de una mayor cantidad de datos. Exploraremos algunos de estos resultados en las siguientes secciones. Para crear el conjunto de datos, utilizaron un gran conjunto de datos patentado de aproximadamente mil millones de imágenes silvestres, centrándose exclusivamente en imágenes humanas. El preprocesamiento para crear el conjunto de datos final implicó descartar imágenes con marcas de agua, texto, representaciones artísticas o elementos no naturales. También utilizaron un detector de cajas delimitadoras individuales para filtrar las imágenes, con una puntuación de detección inferior a 0,9 o con dimensiones de cajas delimitadoras inferiores a 300 píxeles.
Modelos afinados
Estimación de pose 2D
La estimación de posturas en 2D es una técnica de visión artificial que consiste en detectar y localizar puntos clave de un cuerpo humano (u otros objetos) en una imagen o fotograma de vídeo. Estos puntos clave representan articulaciones como los hombros, los codos, las rodillas y los tobillos. El objetivo final de la estimación de posturas en 2D es mapear la posición relativa de estos puntos para formar una estructura esquelética o «pose» del sujeto en un espacio bidimensional. [caption id="attachment_3627" align="aligncenter» width="710"]
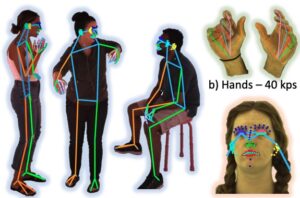
Plantea anotaciones de verdad sobre la base de la estimación. Fuente: Sapiens: base para los modelos de visión humana[/caption] Utilizando una configuración de captura en interiores, los autores crearon un conjunto de datos de 1 millón de imágenes a 4K y anotaron manualmente los puntos clave, incluidos 243 puntos clave faciales. En comparación con los métodos existentes que utilizan como máximo 68 puntos clave, este método captura muchos más matices en las expresiones faciales del mundo real. Luego, este conjunto de datos se usó para ajustar el modelo previamente entrenado a fin de poder resolver este problema específico, logrando un rendimiento de última generación en comparación con los métodos existentes para estimar la postura humana. Los posibles casos de uso para la estimación de posturas podrían ser la interacción humano-computadora (HCI), la animación y la realidad aumentada [caption id="attachment_3629" align="aligncenter» width="862"]

Estimación de poses para imágenes salvajes. Fuente: Sapiens: base para los modelos de visión humana[/subtítulo]
Segmentación de partes del cuerpo
La segmentación de partes del cuerpo humano implica dividir una imagen o un vídeo de una persona en distintas regiones, donde cada región corresponde a una parte diferente del cuerpo (por ejemplo, cabeza, torso, brazos, piernas). Básicamente, el objetivo es etiquetar cada píxel de una imagen con la parte del cuerpo correspondiente, lo que permite al modelo diferenciar entre las diversas estructuras anatómicas de una persona. [caption id="attachment_3652" align="aligncenter» width="808"]
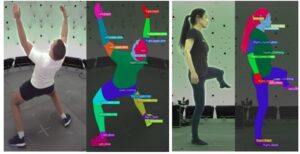
La segmentación corporal fundamenta las anotaciones de verdad. Fuente: Sapiens: base para los modelos de visión humana[/caption] Para afinar esta tarea, los autores utilizaron un conjunto de datos compuesto por 100 000 imágenes con un vocabulario de segmentación de 28 clases. En este caso, el modelo más pequeño (0,3 millones de parámetros) superó a los métodos más avanzados existentes. Esto demuestra el impacto del preentrenamiento centrado en el ser humano y de mayor resolución. Los posibles casos de uso de la segmentación por partes del cuerpo podrían ser la estimación de posturas, la prueba virtual, la realidad aumentada, las imágenes médicas, la animación y los efectos visuales. [caption id="attachment_3655" align="aligncenter» width="808"]

Segmentación corporal para imágenes salvajes. Fuente: Sapiens: base para los modelos de visión humana[/subtítulo]
Estimación de profundidad
La estimación de profundidad implica predecir la distancia de los objetos desde la cámara en una imagen o vídeo 2D. Proporciona una perspectiva tridimensional, lo que nos permite determinar qué tan lejos está cada punto de la escena en relación con la cámara. [caption id="attachment_3670" align="aligncenter» width="712"]

La estimación de profundidad fundamenta las anotaciones de verdad. Fuente: Sapiens: base para los modelos de visión humana[/caption] Para afinar esta tarea, renderizaron 500 000 imágenes sintéticas utilizando 600 escaneos humanos de fotogrametría de alta resolución. Se seleccionó un fondo aleatorio de entre una colección de mapas ambientales de 100 imágenes HDRI y se colocó una cámara virtual dentro de la escena, ajustando aleatoriamente la distancia focal, la rotación y la traslación para capturar imágenes y los correspondientes mapas de profundidad sobre el terreno con una resolución de 4K (véase la imagen de arriba). Cabe destacar que el modelo, basado únicamente en datos sintéticos, obtuvo mejores resultados que los de última generación anteriores en todos los escenarios analizados. Algunos casos de uso para la estimación de la profundidad son la realidad virtual, las pruebas virtuales, la robótica, la vigilancia y la seguridad [caption id="attachment_3672" align="aligncenter» width="605"]

Estimación de profundidad para imágenes en estado salvaje. Fuente: Sapiens: base para los modelos de visión humana[/subtítulo]
Estimación de la superficie normal
La estimación normal de la superficie es una tarea de visión artificial que se centra en determinar la orientación de las superficies en una escena 3D. En términos más sencillos, una superficie normal es un vector que es perpendicular a una superficie dada en un punto específico. [caption id="attachment_3674" align="aligncenter» width="522"]

Anotaciones de verdad básica para una estimación normal. Fuente: Sapiens: base para los modelos de visión humana[/caption] Para realizar ajustes en este caso, utilizaron el mismo conjunto de datos que construyeron para el modelo de profundidad. Una vez más, este modelo afinado superó a los estimadores de normalidad de superficie específicos para humanos de última generación. La estimación normal se puede utilizar para la reconstrucción en 3D, la obtención de imágenes médicas, los vehículos autónomos y la robótica. [caption id="attachment_3677" align="aligncenter» width="515"]

Estimación normal para imágenes en estado salvaje. Fuente: Sapiens: base para los modelos de visión humana[/subtítulo]
Ejemplos de productos fuera de distribución
Todos los modelos, incluido el modelo fundamental, se entrenaron con imágenes de humanos reales. No está claro qué haría el modelo si introdujéramos una imagen de un ser humano generada por la IA o incluso una imagen animada. En esta sección estudiaremos algunos ejemplos de esto y veremos cómo les va a los modelos en ellos. En este primer ejemplo podemos ver que el modelo de estimación de poses funciona bien incluso en este caso, pero el modelo de segmentación funciona mal y la estimación de profundidad da un error porque espera una imagen con un fondo. Dado que el conjunto de datos utilizado para el modelo de estimación de poses es el más grande de todos, el bajo rendimiento del modelo de segmentación podría estar relacionado con la cantidad de datos.



En los siguientes ejemplos tomamos la misma imagen pero agregamos un fondo aleatorio, como hicieron para crear el modelo de estimación de profundidad. En este caso, todos los modelos funcionan correctamente.




¿Qué pasa si tomamos un humano generado con IA? Sorprendentemente, las modelos siguen siendo capaces de identificar correctamente la pose, la profundidad y la segmentación de la persona de la imagen, como ocurre con el personaje animado. Esto podría usarse como un método para aumentar el tamaño del conjunto de datos.




Caso de uso de Sapiens
Prueba virtual
Dada la precisión de la segmentación de la ropa, podemos usarla para crear máscaras sobre la ropa que nos gustaría reemplazar. Esta segmentación podría usarse, por ejemplo, para crear una prueba virtual, como veremos en los ejemplos. Usaremos Stable Diffusion XL para pintar sobre la zona enmascarada y reemplazar la ropa por otra nueva. Utilizaremos personas generadas por IA para los intentos. Usando el mapa de profundidad que obtuvimos de Sapiens como entrada para ControlNet, podremos preservar la forma del cuerpo de cada individuo. En cada caso, creamos una máscara sobre la ropa que queremos reemplazar utilizando la segmentación que obtuvimos con Sapiens. Luego, la imagen enmascarada se envía a Stable Diffusion XL para pintarla.



En la primera imagen sustituimos el jersey que llevaba la mujer por uno nuevo. En la segunda imagen sustituimos los jeans. Notamos que la forma del cuerpo está bien conservada en ambos casos.


Para el siguiente ejemplo, utilizamos el mismo tema creado con SD que utilizamos en la sección anterior.
En la primera imagen cambiamos su chaqueta por una nueva. En la segunda ahora lleva unos vaqueros grises. Observe cómo el resto de la imagen queda igual, este es el resultado de la segmentación muy precisa obtenida con Sapiens.


Reflexiones finales
Este artículo exploró la nueva familia de modelos creada por Meta «Sapiens» y examinó los 4 ajustes clave proporcionados. Estas herramientas se utilizaron luego para crear una versión virtual de prueba de imágenes generadas por IA. También se realizaron experimentos con imágenes fuera de distribución, personajes animados y generados por la IA, y es impresionante ver lo bien que funcionaron los modelos en esas imágenes. Las posibilidades que esto abre para futuros desarrollos son interesantes.



.png)