Como usar o Sapiens para melhorar as imagens humanas geradas pela IA




Os computadores estão mais poderosos do que nunca. Isso significa que podemos fazer coisas com a IA que não podíamos fazer no passado. Mas esses novos modelos de IA precisam de muitos dados para serem aprendidos. Esse apetite por dados foi abordado com sucesso no processamento de linguagem natural (PNL) por meio de um pré-treinamento autosupervisionado. As soluções são fáceis de entender: elas removem uma parte dos dados e aprendem a prever o conteúdo removido. Esses métodos agora permitem o treinamento de modelos de PNL generalizáveis contendo mais de cem bilhões de parâmetros. Essa ideia é natural e aplicável também na visão computacional. Neste blog, estudaremos uma família de modelos, Sapiens, desenvolvida pela Meta com base nessa ideia.

Arquitetura modelo
O modelo fundamental do Sapiens é um autoencoder mascarado (MAE). Os codificadores automáticos mascarados são aprendizes autosupervisionados para visão computacional. Durante o treinamento, uma parte significativa da imagem é mascarada e o autoencoder recebe a tarefa de reconstruir a imagem original. O MAE usado neste caso tem um design de decodificador codificador assimétrico: o codificador recebe apenas as manchas não mascaradas da imagem, enquanto o decodificador é leve e reconstrói a entrada a partir da representação latente (das manchas visíveis) e das manchas mascaradas da imagem. Transferir os tokens mascarados para o decodificador pequeno reduz muito a computação, pois apenas uma parte da imagem precisa ser processada pelo codificador. Na próxima imagem, temos uma representação visual da arquitetura. [caption id="attachment_3624" align="aligncenter” width="703"]

Arquitetura modelo. Fonte: Codificadores automáticos mascarados são aprendizes de visão escaláveis[/caption] O modelo fundamental, treinado na tarefa geral de reconstruir imagens mascaradas, pode ser ajustado para resolver problemas mais específicos, como segmentação, profundidade e outros. Na próxima seção, analisaremos alguns dos casos de uso disponíveis.
Conjunto de dados Sapiens
Que tipo de dados é mais eficaz para o pré-treinamento? Dados os limites computacionais, o foco deve ser reunir o maior número possível de imagens ou é melhor usar um conjunto menor e selecionado? Para explorar isso, os autores criaram um conjunto de dados chamado Humans-300M, com 300 milhões de imagens humanas diversas. Suas descobertas mostraram que um conjunto de dados bem organizado geralmente leva a um melhor desempenho em comparação com a simples coleta de uma quantidade maior de dados. Exploraremos alguns desses resultados nas próximas seções. Para criar o conjunto de dados, eles utilizaram um grande conjunto de dados proprietário de aproximadamente 1 bilhão de imagens selvagens, com foco exclusivo em imagens humanas. O pré-processamento para criar o conjunto de dados final envolveu o descarte de imagens com marcas d'água, texto, representações artísticas ou elementos não naturais. Eles também usaram um detector de caixa delimitadora de pessoas para filtrar imagens, com uma pontuação de detecção menor que 0,9 ou dimensões de caixa delimitadora menores que 300 pixels.
Modelos aperfeiçoados
Estimativa de pose 2D
A estimativa de pose 2D é uma técnica em visão computacional que envolve detectar e localizar pontos-chave em um corpo humano (ou outros objetos) em um quadro de imagem ou vídeo. Esses pontos-chave representam articulações como ombros, cotovelos, joelhos e tornozelos. O objetivo final da estimativa de pose 2D é mapear a posição relativa desses pontos para formar uma estrutura esquelética ou “pose” do sujeito em um espaço bidimensional. [caption id="attachment_3627" align="aligncenter” width="710"]
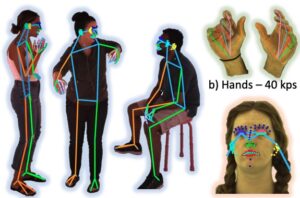
Faça anotações verídicas básicas sobre estimativas. Fonte: Sapiens: Fundação para modelos de visão humana[/caption] Utilizando uma configuração de captura interna, os autores criaram um conjunto de dados de 1 milhão de imagens em 4k e anotaram manualmente os pontos-chave, incluindo 243 pontos-chave faciais. Em comparação com os métodos existentes que utilizam no máximo 68 pontos-chave, esse método captura muito mais nuances nas expressões faciais no mundo real. Esse conjunto de dados foi então usado para ajustar o modelo pré-treinado para poder resolver esse problema específico, alcançando um desempenho de última geração em comparação com os métodos existentes para estimativa de pose humana. Os possíveis casos de uso para estimativa de pose podem ser interação humano-computador (HCI), animação e realidade aumentada [caption id="attachment_3629" align="aligncenter” width="862"]

Estimativa de pose para imagens selvagens. Fonte: Sapiens: Fundação para modelos de visão humana[/legenda]
Segmentação de partes do corpo
A segmentação de partes do corpo humano envolve a divisão de uma imagem ou vídeo de uma pessoa em regiões distintas, onde cada região corresponde a uma parte diferente do corpo (por exemplo, cabeça, tronco, braços, pernas). Essencialmente, o objetivo é rotular cada pixel em uma imagem com sua parte corporal correspondente, permitindo que o modelo diferencie as várias estruturas anatômicas de uma pessoa. [caption id="attachment_3652" align="aligncenter” width="808"]
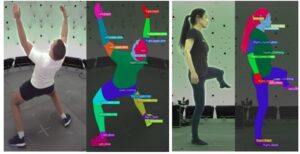
A segmentação corporal fundamenta as anotações verídicas. Fonte: Sapiens: Fundação para modelos de visão humana[/caption] Para ajustar essa tarefa, os autores usaram um conjunto de dados composto por 100 mil imagens com um vocabulário de segmentação de 28 classes. Nesse caso, o menor modelo (parâmetros de 0,3B) superou os métodos de última geração existentes. Isso mostra o impacto da alta resolução e do pré-treinamento centrado no ser humano. Os possíveis casos de uso para segmentação de partes do corpo podem ser estimativa de pose, teste virtual, realidade aumentada, imagens médicas, animação e efeitos visuais. [caption id="attachment_3655" align="aligncenter” width="808"]

Segmentação corporal para imagens selvagens. Fonte: Sapiens: Fundação para modelos de visão humana[/legenda]
Estimativa de profundidade
A estimativa de profundidade envolve prever a distância dos objetos da câmera em uma imagem ou vídeo 2D. Ele fornece uma perspectiva tridimensional, permitindo determinar a que distância cada ponto da cena está em relação à câmera. [caption id="attachment_3670" align="aligncenter” width="712"]

Anotações verídicas básicas da estimativa de profundidade. Fonte: Sapiens: Fundação para modelos de visão humana[/caption] Para ajustar essa tarefa, eles renderizaram 500.000 imagens sintéticas usando 600 digitalizações humanas de fotogrametria de alta resolução. Um plano de fundo aleatório foi selecionado de uma coleção de mapas de ambiente 100 HDRI e uma câmera virtual foi colocada dentro da cena, ajustando aleatoriamente sua distância focal, rotação e tradução para capturar imagens e seus mapas de profundidade reais associados em resolução 4K (veja a imagem acima). É notável que o modelo treinado apenas com dados sintéticos tenha superado os resultados anteriores de última geração em todos os cenários analisados. Alguns casos de uso para estimativa de profundidade são realidade virtual, teste virtual, robótica, vigilância e segurança [caption id="attachment_3672" align="aligncenter” width="605"]

Estimativa de profundidade para imagens selvagens. Fonte: Sapiens: Fundação para modelos de visão humana[/legenda]
Estimativa normal de superfície
A estimativa normal da superfície é uma tarefa de visão computacional focada em determinar a orientação das superfícies em uma cena 3D. Em termos mais simples, uma superfície normal é um vetor perpendicular a uma determinada superfície em um ponto específico. [caption id="attachment_3674" align="aligncenter” width="522"]

Anotações verdadeiras básicas para estimativas normais. Fonte: Sapiens: Fundação para modelos de visão humana[/caption] Para o ajuste fino, neste caso, eles usaram o mesmo conjunto de dados que construíram para o modelo de profundidade. Mais uma vez, esse modelo aperfeiçoado superou os estimadores normais de superfície específicos para humanos de última geração. A estimativa normal pode ser usada para reconstrução 3D, imagens médicas, veículos autônomos e robótica. [caption id="attachment_3677" align="aligncenter” width="515"]

Estimativa normal para imagens na natureza. Fonte: Sapiens: Fundação para modelos de visão humana[/legenda]
Exemplos fora de distribuição
Todos os modelos, incluindo o modelo fundamental, foram treinados usando imagens de humanos reais. Não está claro o que o modelo faria se introduzíssemos uma imagem de um humano gerada pela IA ou mesmo uma imagem animada. Nesta seção, estudaremos alguns exemplos disso e veremos como os modelos funcionam neles. Neste primeiro exemplo, podemos ver que o modelo de estimativa de pose funciona bem mesmo nesse caso, mas o modelo de segmentação funciona mal e a estimativa de profundidade gera um erro porque espera uma imagem com fundo. Dado que o conjunto de dados usado para o modelo de estimativa de pose é o maior de todos, o baixo desempenho do modelo de segmentação pode estar relacionado à quantidade de dados.



Nos próximos exemplos, tiramos a mesma imagem, mas adicionamos um plano de fundo aleatório, como fizeram para criar o modelo de estimativa de profundidade. Nesse caso, todos os modelos funcionam corretamente.




O que acontece se pegarmos um humano gerado com IA? Impressionantemente, os modelos ainda conseguem identificar corretamente a pose, a profundidade e a segmentação da pessoa na imagem, como acontece com o personagem animado. Isso pode ser usado como um método para aumentar o tamanho do conjunto de dados.




Caso de uso do Sapiens
Teste virtual
Dada a precisão da segmentação das roupas, podemos usá-la para criar máscaras sobre as roupas que gostaríamos de substituir. Essa segmentação pode ser usada, por exemplo, para criar um teste virtual, como veremos nos exemplos. Usaremos o Stable Diffusion XL para pintar sobre a zona mascarada e substituir as roupas por novas. Usaremos pessoas geradas por IA para os testes. Usando o mapa de profundidade que obtivemos do Sapiens como entrada para o ControlNet, poderemos preservar a forma corporal de cada indivíduo. Em cada caso, criamos uma máscara sobre as roupas que queremos substituir usando a segmentação que obtivemos com Sapiens. A imagem mascarada é então enviada para o Stable Diffusion XL para pintura.



Na primeira imagem, substituímos o suéter que a mulher estava usando por um novo. Na segunda imagem, substituímos o jeans. Percebemos que a forma do corpo está bem preservada em ambos os casos.


Para o próximo exemplo, usamos o mesmo assunto criado com SD que usamos na seção anterior.
Na primeira imagem, substituímos sua jaqueta por uma nova. No segundo, ele agora está vestindo jeans cinza. Observe como o resto da imagem permanece o mesmo, isso é o resultado da segmentação muito precisa obtida com o Sapiens.


Considerações finais
Este artigo explorou a nova família de modelos criada pela Meta “Sapiens”, examinando os 4 principais ajustes fornecidos. Essas ferramentas foram então usadas para criar um teste virtual para imagens geradas por IA. Também foram realizados experimentos com imagens fora de distribuição, personagens animados e gerados por IA, e é impressionante ver o desempenho dos modelos nelas. As possibilidades que isso abre para desenvolvimentos futuros são empolgantes.



.png)