
Aprendizaje por refuerzo: la IA conoce al perro de Pavlov




Introducción
¿Has oído hablar del perro de Pavlov? En 1897, Ivan Pavlov, un fisiólogo ruso, publicó sus hallazgos sobre el comportamiento condicionado, que demostraban cómo se podía condicionar a los perros para que asociaran un estímulo incondicionado (comida) con un estímulo neutro (campana), lo que conducía a una respuesta condicionada (salivación) provocada únicamente por la campana.
La idea detrás de este experimento es que se podría condicionar al perro para que se comporte de una manera determinada de acuerdo con una serie de recompensas o castigos que reciba, que es la idea central detrás del aprendizaje por refuerzo. Tanto el perro de Pavlov como los sistemas de aprendizaje por refuerzo muestran el poder del condicionamiento y la capacidad de adaptar los comportamientos basándose en las señales de refuerzo.
En este blog vamos a explorar los conceptos básicos del aprendizaje por refuerzo, el aprendizaje de arriba hacia abajo. Este blog está dirigido a lectores con algunos conocimientos de cálculo y álgebra, pero no es necesario ser un experto para entenderlo.
¿Qué es el aprendizaje por refuerzo?
El aprendizaje por refuerzo es un enfoque matemático del aprendizaje por ensayo y error, y busca emular una de las formas en que los animales aprenden. Imagina que tienes un cachorro pequeño al que quieres enseñarle trucos. Aprenderá a hacer estos trucos por ensayo y error, cayendo y chocando de vez en cuando contra muebles (comentarios negativos), pero también recibiendo elogios y premios cuando consiga progresar (comentarios positivos). Tras muchos intentos, aprenderán progresivamente a ejecutar mejor los trucos y, finalmente, por su cuenta, sin necesidad de premios. Este es el fenómeno del que el aprendizaje por refuerzo trata de aprender.

La idea principal del aprendizaje por refuerzo es que un agente (un modelo, pero en nuestro ejemplo anterior, el cachorro) aprenderá del entorno (en este caso, tú y tu entorno) interactuando con él (intentando el truco, cayendo) y recibiendo comentarios (siendo elogiado, recibiendo premios) cada vez que interactúe de manera diferente. Cada interacción se conoce como acción (el movimiento que hace el perro) y la retroalimentación recibida viene dada por un recompensa función (el trato que le damos o le negamos), que puede ser positiva o negativa en caso de que una acción tenga una consecuencia negativa.
[caption id="attachment_2328" align="aligncenter» width="665"]
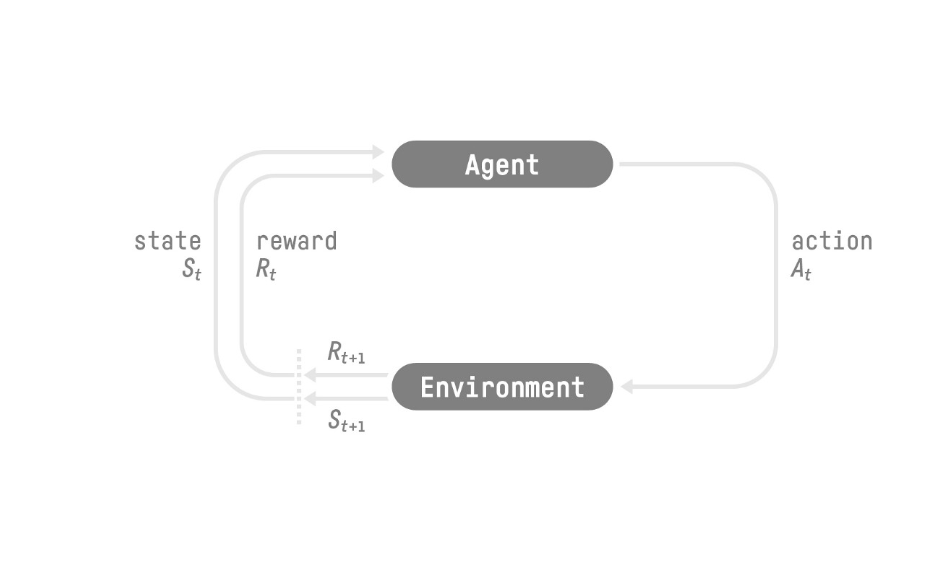
Imagen tomada de Reinforcement Learning An Introduction [/caption]
En la figura anterior, St, At, Rt, hacen referencia al estado, la acción y la recompensa en el momento t. En el ejemplo del cachorro, el estado se referiría a la posición en la que se encuentre el perro en el momento t, a la acción, al movimiento que está realizando y a la recompensa si le vas a dar una golosina o no.
Espacio de acción y estado
Los escenarios de aprendizaje por refuerzo tienen un estado asociado o un espacio de observación, es decir, una descripción completa o parcial del entorno. Por ejemplo, en el caso de un agente que aprende a jugar al ajedrez, tiene una descripción completa del entorno, ya que conoce la posición de todas las demás piezas del tablero en un paso determinado. Las descripciones completas del entorno que están fácilmente disponibles no son la regla y las descripciones parciales se conocen como observaciones.

Este tipo de escenarios también tienen un espacio de acción asociado, es decir, el conjunto de todas las acciones posibles que puede realizar un agente. Este espacio de acción puede ser discreto, como en el caso del ajedrez, en el que hay un conjunto de acciones posibles que puede realizar una pieza determinada, o continuo, como el espacio de acción mientras se conduce un automóvil.

Modelo de recompensa El modelo de recompensa es el núcleo del aprendizaje por refuerzo, ya que proporciona al agente la retroalimentación que necesita para aprender. La recompensa de una trayectoria (en el ajedrez, por ejemplo, una trayectoria podría significar simplemente una serie de acciones secuenciales que el agente lleva a cabo) viene dada por la suma de las recompensas descontadas en cada fase temporal:
R () =r (t+1) +r (t+2) +... + k-1r (t+k)
R es la función de recompensa acumulada a lo largo de toda la trayectoria τy está compuesta por la recompensa obtenida en cada paso temporal del 1 al k necesario para completar τ.
se conoce como tasa de descuento y su introducción es necesaria, ya que es menos probable que se obtengan recompensas más alejadas del estado actual que las que se encuentran más cerca del estado actual. Piénsalo de esta manera: si estás jugando al ajedrez y planeas una serie de 4 movimientos para llevarte a la reina de tu adversario, este podría mover su reina antes de que tú la alcances o llevarse una de tus piezas, lo que sería clave para tu estrategia, y por lo tanto no podrías completar tu jugada. Las recompensas que se encuentran más lejos del estado actual deben descontarse, ya que es menos probable que se obtengan que las que están más cerca del estado.
Tipos de aprendizaje por refuerzo:
Pero, ¿cómo aprenden estos agentes del entorno? ¿Cómo saben qué medidas tomar en un estado determinado para maximizar su recompensa acumulada? Bueno, aquí es donde entra en juego la política. La política de una tarea de aprendizaje por refuerzo, denominada π, es el modelo que le indica al agente cómo comportarse en un estado determinado. Esta es la función que pretendemos aprender para encontrar la política óptima π que maximice la recompensa acumulada del agente.
Hay dos enfoques principales para encontrar π: métodos basados en políticas y métodos basados en valores. Por un lado, los métodos basados en valores tienen como objetivo aprender una función de valor que asigne el estado al valor esperado de estar en ese estado. La política utilizada en este escenario consiste simplemente en tomar la acción que lleve al estado con el valor más alto.
Por otro lado, los métodos basados en políticas tienen como objetivo aprender la función π directamente, es decir, un mapeo de qué acción es mejor tomar en cada estado dado. Esta política puede ser determinista (para un estado S dado, la acción óptima es siempre A) o estocástica, lo que arroja una distribución de probabilidad sobre todas las acciones en cada estado.
[caption id="attachment_2344" align="aligncenter» width="817"]
Métodos basados en valores versus métodos basados en políticas [/caption]
Gradientes de políticas
Uno de los principales enfoques para el aprendizaje estocástico de políticas es el uso de una red neuronal cuyos parámetros se ajustan mediante el descenso de gradientes, un proceso que se denomina gradientes de políticas. El enfoque más simple adoptado es el gradiente de políticas, que simplemente actualiza los parámetros de la política mediante una regla de aprendizaje muy parecida a la que se utiliza en el aprendizaje supervisado:
← + J ()
Donde es el vector con todos los parámetros que componen la política, es una tasa de aprendizaje preestablecida y J () es el gradiente de la función de costo J (la función que mide qué tan lejos está la política de la respuesta óptima) con respecto a los parámetros. Esta estructura se asemeja al descenso más pronunciado de una red neuronal en un problema de aprendizaje supervisado, y la regla de actualización también es muy similar dado que, en términos generales, las políticas se aproximan utilizando redes neuronales.
Sin embargo, el gradiente de políticas adolece de importantes inconvenientes:
- Se trata de un enfoque de aprendizaje de Montecarlo (lo que significa promediar la recompensa que el agente obtiene durante todo un episodio), teniendo en cuenta la trayectoria completa de la recompensa (una muestra), que a menudo presenta una gran varianza, lo que provoca problemas de convergencia.
- Las muestras solo se usan una vez, una vez que se actualiza la política, la nueva política se usa para muestrear una nueva trayectoria, lo cual es un proceso costoso
- Elegir la tasa de aprendizaje correcta es difícil y el sistema presenta gradientes tanto de desaparición como de explosión, lo que hace que la convergencia dependa en gran medida de la muestra.
Optimización de políticas proximales
Para abordar estos y otros inconvenientes de los gradientes políticos, se han explorado varios otros algoritmos. Los modelos de última generación actuales son los derivados de la optimización de políticas proximales (PPO), una artículo publicado en 2017. Los cálculos que lo sustentan son desafiantes y superan el alcance de esta revisión, pero, en esencia, la PPO mejora el gradiente de políticas de dos maneras principales:
- La PPO introduce un término de divergencia objetivo, que penaliza los casos en los que la política actualizada produce resultados que difieren demasiado de los de las muestras anteriores. Nos gustaría que nuestra política arroje resultados en un entorno determinado, de modo que las respuestas sean similares en un paso a otro.
- Dado que esta divergencia limita la diferencia entre dos muestras consecutivas, esto significa que las actualizaciones de la política son pequeñas y, por lo tanto, las muestras se pueden reutilizar más de una vez para actualizar la política.
Aprendizaje reforzado a partir de la retroalimentación humana
A nivel abstracto, hemos analizado algunos de los enfoques utilizados en el aprendizaje por refuerzo. Pero, ¿cómo se entrena exactamente a un agente para que resuelva un problema real si no conocemos el valor de recompensa de un estado determinado en el espacio de estados? Pues bien, el enfoque más utilizado en la actualidad es el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF).
[caption id="attachment_2329" align="aligncenter» width="833"]
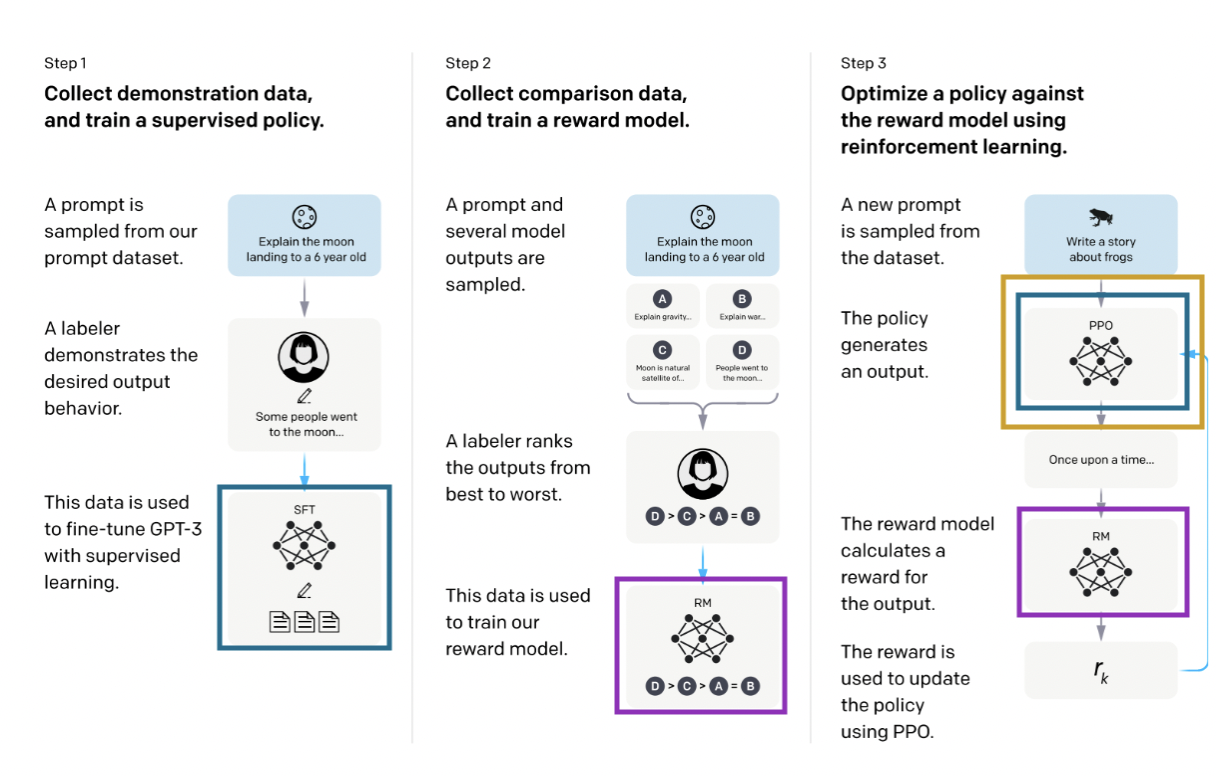
Imagen tomada de Training Language Models para seguir instrucciones con comentarios humanos [/caption]
El proceso consta de tres pasos. El primer paso consiste en entrenar una política supervisada (en azul en el diagrama de arriba), lo que simplemente significa entrenar una red neuronal; en este caso, política y red neuronal son sinónimos. Luego, en el paso 2, los etiquetadores clasifican varios resultados de la política de mejor a peor (otros enfoques incluyen otorgar una puntuación a cada resultado) y este dato se utiliza en el paso 3 para entrenar lo que denominamos un modelo de recompensa (en morado), otra red neuronal que tomará un resultado de una política y le otorgará una recompensa. Este modelo de recompensas se usa luego para actualizar la política utilizando el método PPO (en amarillo), según el cual, para cada paso de entrenamiento, el resultado de la PPO se puntúa según el modelo de recompensas.
Esta modalidad de entrenamiento, que consiste en entrenar primero una política supervisada que luego se ajusta mediante el aprendizaje por refuerzo, se ha utilizado ampliamente últimamente, y su ejemplo más famoso es ChatGPT. Otras áreas en las que la PPO se usa ampliamente son la negociación de acciones y la robótica.
Estudio de caso: Escribir críticas positivas de películas
Uno de los repositorios más completos para afinar modelos mediante el aprendizaje por refuerzo es TRL, que se puede utilizar para afinar transformadores. Lo probamos ajustando el GPT-2 para obtener críticas positivas de películas, utilizando el conjunto de datos de IMDB. Usamos un modelo de DisTilbert previamente entrenado para analizar la opinión sobre las reseñas y lo usamos como modelo de recompensas.
Se usaron dos copias del GPT-2: una congelada, que solo se entrenaba mediante el aprendizaje supervisado, y otra cuyos pesos se cambiaban en cada iteración para comparar el comportamiento pasado y actual.
[caption id="attachment_2331" align="aligncenter» width="907"]
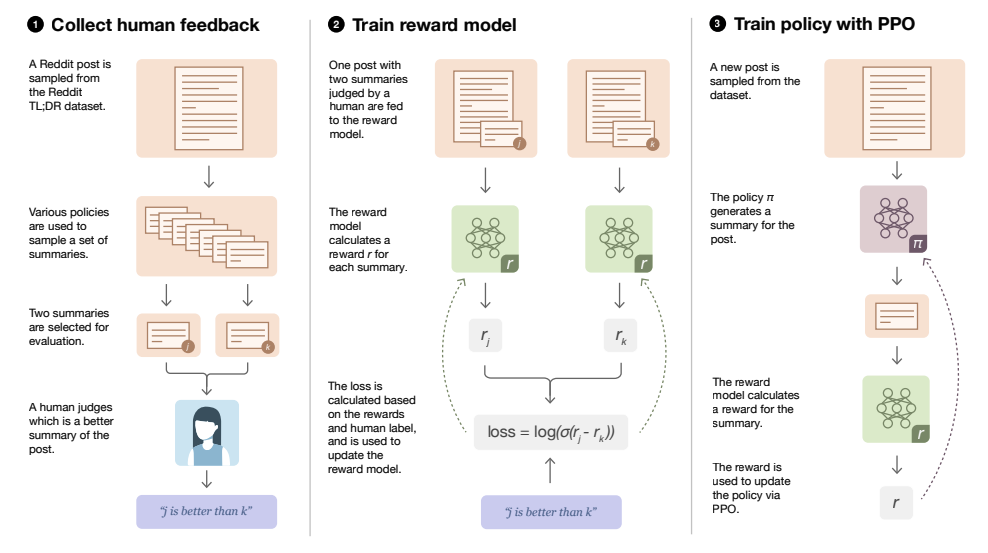
Imagen tomada de Implementando RLHF: Aprender a resumir con TrLx [/caption]
En el diagrama, Prompt simplemente hace referencia a una descripción incompleta que GPT debe completar. Al analizar las opiniones de las dos salidas, se calcula la recompensa de la salida actual del modelo ajustado y, con ello, se modifican sus ponderaciones. A continuación se muestra un ejemplo del rendimiento del modelo antes y después del ajuste fino.
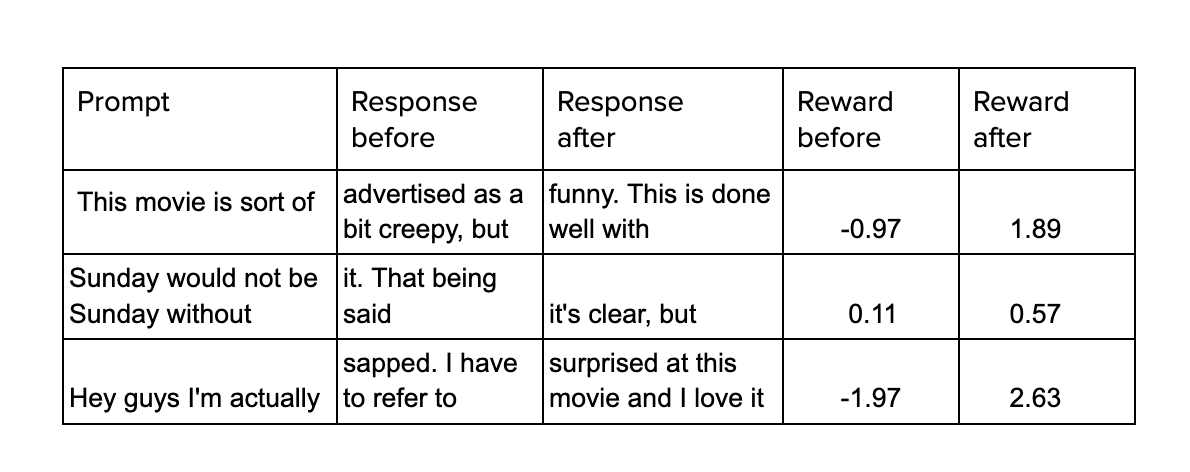
Conclusiones
En este artículo hemos analizado los conceptos básicos del aprendizaje por refuerzo, partiendo de conceptos clave como el espacio de estados, el espacio de acción y el modelo de recompensa hasta cómo utilizar la retroalimentación humana para afinar los modelos lingüísticos. Hemos mencionado algunos ámbitos en los que se utiliza especialmente el aprendizaje por refuerzo y hemos hecho uso de una aplicación en la que hemos escrito críticas positivas para películas. Las técnicas de aprendizaje por refuerzo basadas en la retroalimentación humana están de moda actualmente en la fase de perfeccionamiento de los grandes modelos lingüísticos, pero se pueden utilizar en una amplia serie de escenarios en los que se puede crear una función de recompensa para guiar el proceso de aprendizaje.
Referencias
Sutton, R., Barto, A., «Aprendizaje por refuerzo: una introducción», 2018
Schulman, J. y otros, «Algoritmos de optimización de políticas proximales», 2017
Ouyang, L., et al, «Entrenamiento de modelos lingüísticos para seguir instrucciones con comentarios humanos», 2022



.png)