.png)
Procesamiento de vídeo en tiempo real: implementación de aplicaciones en la nube




¿Cómo lo hace? Amazon Go ¿te cobran sin necesidad de pagar físicamente? ¿Es posible detectar fallos en los productos manufacturados simplemente analizando la grabación de una cámara? ¿Podemos desarrollar una aplicación que supervise los campos cultivados para detectar plagas y optimizar el riego? La respuesta a todas estas preguntas se encuentra en el campo del aprendizaje automático con procesamiento de vídeo en tiempo real: se utiliza una cámara (o un conjunto de cámaras) para grabar vídeo, y este vídeo se procesa sobre la marcha para que el resultado deseado esté disponible lo antes posible, produciendo resultados casi en tiempo real que podrían afectar a todo tipo de empresas.
Existe una amplia gama de aplicaciones de aprendizaje automático (ML) que podrían beneficiarse de un enfoque de procesamiento de vídeo en tiempo real. El seguimiento de objetos o personas a lo largo del tiempo (para aplicaciones de videovigilancia), la detección automática de objetos en aplicaciones de conducción autónoma, la generación de alertas en una industria manufacturera cada vez que una cámara de vídeo detecta algún incidente, y mucho más. Todas estas aplicaciones comparten algunos principios informáticos básicos y es posible desplegarlas utilizando arquitecturas similares.
En esta publicación, exploraremos algunas alternativas para diseñar arquitecturas para implementar aplicaciones de aprendizaje automático listas para la producción que aprovechen el procesamiento de video en tiempo real. Analizaremos las ventajas y desventajas de las diferentes arquitecturas y exploraremos las alternativas de nube en los proveedores de nube más relevantes. El objetivo principal de esta publicación es proporcionar un conjunto de posibles arquitecturas de procesamiento de vídeo en tiempo real que puedan ser útiles en las etapas de diseño.
Enmarcar el problema
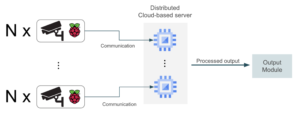
La imagen de abajo muestra un diagrama de alto nivel de lo que estamos intentando construir. Un dispositivo captura vídeo y lo envía a un módulo de comunicación que lo transmite a un módulo de procesamiento. En esta etapa de procesamiento, preparamos el vídeo cuadro por cuadro para el aprendizaje automático. La inferencia se lleva a cabo en el siguiente módulo, en el que una aplicación de aprendizaje automático genera predicciones en función de la entrada. La aplicación puede incluir la detección de objetos, el reconocimiento facial, la segmentación de imágenes o cualquier otra tarea de visión artificial. Finalmente, enviamos el resultado al último módulo, donde los usuarios finales lo consumen.
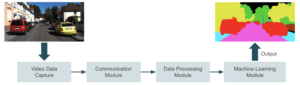
Hay dos enfoques principales para abordar este problema:
- Usar los dispositivos de cámara solo para capturar datos y enviar el vídeo a un proveedor de nube o a un servidor dedicado. El servidor se encarga de todo el procesamiento de datos, la inferencia mediante aprendizaje automático y la generación de resultados. En este caso, las canalizaciones de entrenamiento e implementación de modelos se llevan a cabo en el mismo entorno de nube.
- Aprovechar los dispositivos de computación perimetral para acercar la inferencia del aprendizaje automático a los dispositivos de cámara y transmitir solo la salida de la inferencia a un proveedor de nube. En este caso, es necesario implementar los modelos entrenados en la periferia y utilizar aceleradores de GPU para ejecutar la inferencia in situ.
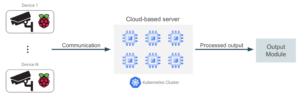
La siguiente imagen muestra un diagrama de alto nivel que compara estos dos enfoques.
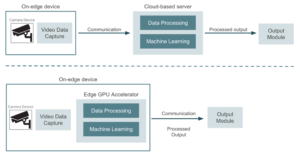
Como referencia, algunas de las alternativas de hardware que se pueden utilizar cuando se opta por una arquitectura basada en bordes son las Dispositivos NVIDIA (Jetson Nano, Jetson Xavier NX y Jetson AGX Xavier, con diferentes precios y diferentes capacidades de potencia de cálculo). Básicamente, se trata de dispositivos de GPU con capacidades de computación de alto rendimiento que podemos conectar directamente a los dispositivos de vídeo. También es posible utilizar dispositivos basados en USB, como Google Coral. Consisten en aceleradores USB conectados a dispositivos existentes, como las placas Raspberry Pi, y ofrecen capacidades de TPU (unidad de procesamiento tensorial). Llegados a este punto, tiene sentido preguntarnos qué enfoque nos proporcionará el mejor resultado en términos de costo/beneficio y cómo tomar esta decisión. Pensemos en el primer enfoque, un conjunto de cámaras de seguridad que capturan vídeo y lo envían a un entorno de nube en el que alojamos un modelo de aprendizaje automático implementado para la detección de objetos. Todos los dispositivos de vídeo llevan a cabo el proceso de captura de datos, pero el entorno de nube se encarga de procesar el resto del proceso, excepto los dispositivos periféricos. Un enfoque basado en la nube presenta algunas ventajas en comparación con la ejecución de una inferencia de aprendizaje automático (ML) directamente en los dispositivos periféricos:
- La carga computacional en los dispositivos periféricos es relativamente baja, solo se usan para capturar y enviar datos.
- Es fácil aumentar o reducir los recursos de la nube en función de los requisitos de la carga de trabajo mediante el uso de cualquiera de los servicios de nube que proporcionan el escalado automático.
- Un entorno de nube centraliza los modelos, el software y la infraestructura, lo que facilita la administración de la implementación, el reentrenamiento de modelos y las actualizaciones de software. Esto evita la necesidad de implementar modelos en cada dispositivo periférico.
Ahora bien, hay algunas desventajas honestas al adoptar este enfoque que vale la pena mencionar:
- La transmisión de datos a la nube introduce latencia, que puede no ser adecuada para aplicaciones sensibles a la latencia.
- La conectividad a Internet continua y confiable es fundamental para transmitir datos a la nube.
- Para evitar problemas de privacidad de datos, debemos garantizar una conectividad segura entre los dispositivos periféricos y la nube. En una arquitectura basada en la computación perimetral, los datos no necesitan salir de los dispositivos periféricos en la mayoría de los casos. Hay aplicaciones, por ejemplo, en las que el envío de imágenes de personas a la nube no es un escenario compatible.
La decisión de optar por una solución basada en la nube o en la periferia dependerá de la compensación entre la latencia y los costos. Si la aplicación diseñada admite cierta tolerancia a la latencia, entonces un enfoque basado en la nube podría ser la mejor opción. Por otro lado, el cambio a una arquitectura basada en el borde garantizará mejores propiedades de latencia, pero también aumentará los costos de hardware, lo que sería prohibitivo en aplicaciones con cantidades masivas de dispositivos. Optar por una solución perimetizada también implicará algunas tareas adicionales para coordinar la implementación y las actualizaciones de los modelos en todos los dispositivos. Como queremos centrarnos en la implementación de aplicaciones de producción en la nube, durante el resto de este artículo nos centraremos en las arquitecturas basadas en la nube y desglosaremos los obstáculos abordando algunos detalles de implementación.
Transmisión de vídeo a la nube
Como hemos visto antes, el primer problema que debe abordarse en una solución basada en la nube es enviar el vídeo capturado en tiempo real a la nube. Por lo general, tendremos un conjunto de cámaras que graban vídeo, y se necesitará al menos alguna interfaz básica entre esos dispositivos y el servidor en la nube para poder establecer la comunicación. La forma más sencilla de solucionar este problema es conectar las cámaras, por ejemplo, a un conjunto de placas Raspberry Pi con conexión a Internet:
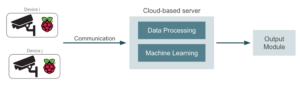
Las placas Raspberry Pi se utilizarán como interfaz entre las cámaras y el servidor dedicado que ejecuta la aplicación. Sin embargo, este enfoque puede tener un problema. Piense, por ejemplo, en una cámara de seguridad que graba un vídeo casi inmóvil y emite una alerta cada vez que encuentra a algún intruso. La mayoría de los fotogramas de vídeo permanecerán sin cambios y, por lo tanto, no valdrá la pena procesarlos. En este caso, tendría sentido implementar en la Raspberry Pi un modelo pequeño que detecte fotogramas relevantes y variables, y enviar solo esos fotogramas a la nube para un aprendizaje automático adecuado. De esta manera, podemos lograr algunas mejoras de ancho de banda bastante importantes.
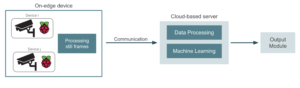
En aplicaciones que necesitan procesar fotogramas constantemente, como en una aplicación de conducción autónoma, esta alternativa puede no ser adecuada. Ahora, pasemos a ser un poco más técnicos y analicemos un par de alternativas para establecer realmente esta conexión entre el entorno de la cámara y la nube:
Conexión directa entre cámaras y servidor
La forma más directa de enviar datos en tiempo real es establecer una conexión de streaming desde las placas Raspberry Pi a la nube. Esto se puede lograr configurando una conexión RTSP (protocolo de transmisión en tiempo real), lo cual es posible con muchas herramientas de código abierto, como FFmpeg o OpenCV. El módulo de procesamiento de datos lee directamente los datos producidos en las cámaras de vídeo fotograma a fotograma. También es importante garantizar el cifrado de los datos confidenciales en este tipo de conexión. Si la cantidad de dispositivos de transmisión no es tan alta, esta alternativa será suficiente para gestionar datos en tiempo real. Pero si la aplicación incluye miles de dispositivos, tendremos que configurar una arquitectura más sólida y escalable. Pasemos a la siguiente alternativa...
Uso de una arquitectura publicador-suscriptor
Una alternativa para aplicaciones más escalables es hacer uso de una plataforma de procesamiento de flujos, desde la cual Apache Kafka es probablemente la más extendida (pero se pueden diseñar arquitecturas similares con Pulsar Apache, Transmisiones de Redis, y muchas más herramientas). En esta solución, la transmisión de datos se estructura según temas, las unidades fundamentales de la organización y la comunicación de los datos. Los temas representan una forma en la que los datos se comparten entre los editores (los dispositivos que generan los datos de streaming) y los consumidores (las aplicaciones que leen y procesan estos datos). Los editores (cámaras de vídeo) envían varios bloques de información a un tema, y los suscriptores (el servidor en la nube, en nuestro caso) pueden consultar la información, bloque por bloque, del tema. Para ello, podemos configurar un clúster de streaming con varios temas que reciba datos de streaming desde varios dispositivos de vídeo. Los temas envían los datos a un servidor centralizado capaz de gestionar cargas de alto tráfico.

En esta alternativa, necesitamos desarrollar, implementar y mantener una aplicación de streaming, además de la aplicación principal de ML. Esto podría llevar a un aumento de los costos de ingeniería, lo que podría valer la pena en algunas aplicaciones con cargas de tráfico considerablemente altas.
Alternativas de streaming, ¿cuándo debemos usar cada una de ellas?
En pocas palabras, podemos considerar una conexión de transmisión directa en los siguientes escenarios:
- Requisitos estrictos de baja latencia. La transmisión RTSP directamente desde la cámara puede proporcionar un acceso de vídeo en tiempo real más rápido que un intermediario de mensajes, lo que introducirá cierta latencia adicional.
- Necesidad de una arquitectura simplificada sin integraciones de datos complejas.
- Transmisión a pequeña escala: cuando se trata de un número reducido de cámaras o un volumen de datos limitado.
Por otro lado, se debe utilizar un enfoque basado en el publicador-suscriptor en cualquiera de estos casos:
- Ingestión de datos a gran escala de múltiples fuentes con altos volúmenes de tráfico.
- Aplicaciones que necesitan cierto nivel de escalabilidad automática. La administración de un clúster de Kafka, por ejemplo, proporcionará algunas funciones de escalado automático.
- Aplicaciones tolerantes a errores.
Procesamiento de vídeo en la nube
Analicemos ahora algunas alternativas para el módulo de procesamiento. Como comentamos anteriormente, en un enfoque basado en la nube, el entorno de nube lleva a cabo tanto el procesamiento como la inferencia de datos. Puede que sean aplicaciones diferentes, pero por motivos de simplicidad, supongamos que solo una aplicación principal se encarga de ambas tareas. Este módulo tomará el vídeo producido y producirá la salida de aprendizaje automático que recibirá el módulo de salida. Una solución típica utiliza un servidor de GPU (que puede estar basado en la nube o incluso en las instalaciones, según los requisitos de la aplicación); este servidor es responsable de gestionar todo el tráfico de los dispositivos y de realizar inferencias para cada fotograma de vídeo. La solución más sencilla es implementar la aplicación de aprendizaje automático en una instancia de máquina virtual con funciones de GPU. El servidor bloquea el tráfico de streaming de forma centralizada, como se muestra en la siguiente figura:

Esta solución, aunque es fácil de implementar, puede que solo sea adecuada para aplicaciones pequeñas con un número reducido de dispositivos. Tener una máquina centralizada que gestione todos los datos de streaming puede significar que la instancia probablemente esté sobredimensionada. Dado que el servidor necesita soportar picos de tráfico (que no solemos alcanzar en un escenario típico), esto puede generar facturas elevadas. La selección de una instancia de tamaño insuficiente también puede provocar cuellos de botella en el procesamiento de datos en momentos de mucho tráfico. Además, la adición de nuevos dispositivos de streaming puede presentar algunos problemas de escalabilidad con un servidor centralizado. Una alternativa para lograr mejores capacidades de escalado es configurar varios servidores de GPU más pequeños que gestionen el tráfico de un subconjunto de dispositivos. De esta manera, escalar el hardware es más fácil a medida que aumenta la cantidad de dispositivos con solo agregar nuevos servidores pequeños. En esta segunda alternativa, la carga entre las GPU debe distribuirse de manera razonable para que no se mantengan los recursos inactivos.
Por último, la solución más sólida sería implementar una aplicación de aprendizaje automático en contenedores y utilizar una plataforma de orquestación de contenedores, como Kubernetes, para gestionar el despliegue y el escalado de los contenedores. Con este enfoque, podemos implementar instancias adicionales de nuestra aplicación en función de la demanda, lo que optimiza el rendimiento y los costos. Además, podemos lograr un mejor uso de los recursos de la GPU gracias a que los contenedores son más livianos en comparación con las máquinas virtuales
La selección de la arquitectura que se utilizará para el módulo de la aplicación dependerá principalmente del tráfico, de la posibilidad de aumentar la cantidad de dispositivos con el tiempo y también de las restricciones de costos. La solución orquestada en contenedores generalmente generará un alto costo de ingeniería y desarrollo, pero también proporcionará la mejor optimización de costos.
Resultado del aprendizaje automático: impacto en las empresas
Una arquitectura de procesamiento y transmisión bien definida no significa mucho si el resultado de la aplicación no puede tener un impacto positivo en nuestro negocio. En esta sección analizaremos el último y más importante módulo de la arquitectura que describimos al principio. Podemos clasificar las aplicaciones de streaming en dos grupos principales:
- Aplicaciones en las que la salida es un flujo de procesamiento de vídeo en tiempo real. Rastrea la trayectoria de objetos o personas específicos a lo largo del tiempo, aplica efectos visuales en tiempo real a un vídeo de entrada (como reemplazar fondos y eliminar objetos) y traduce automáticamente textos a través de vídeos, lo que se aplica, por ejemplo, a la traducción de productos chinos o japoneses con una cámara móvil
- Aplicaciones en las que el resultado es un conjunto de métricas que pueden cambiar con el tiempo. La detección de defectos en la fabricación de las piezas, un problema en una línea de montaje que active una alerta en un panel de control, el seguimiento de las estadísticas de los jugadores de fútbol en tiempo real durante un partido o la gestión automática de los semáforos en función del tráfico actual son algunos ejemplos de esta categoría.

Para la primera categoría, el resultado suele ser un conjunto de fotogramas procesados que muestran el resultado de la inferencia ML. En este caso, es posible que necesitemos configurar alguna arquitectura de transmisión adicional para gestionar el resultado; es posible utilizar cualquiera de las alternativas ya comentadas. En el segundo caso, la salida es una señal o métrica que se almacena en una base de datos o se envía a una API externa que se encarga de todas las tareas posteriores.
En el borde o en la nube, ¿hay alguna solución intermedia?
Bueno, la respuesta es sí. Como mencionamos anteriormente, los costos de hardware asociados a los aceleradores de GPU para ejecutar inferencias cerca del borde son sin duda la limitación más habitual de la arquitectura de computación perimetral. En algunas aplicaciones, configurar una GPU por dispositivo puede resultar exagerado y una arquitectura de computación en la niebla puede ser adecuada. El concepto de computación en la niebla está relacionado con el intercambio de recursos de hardware entre muchos dispositivos periféricos. Mientras la inferencia se ejecuta en una red de área local que está conectada a la nube centralizada. El objetivo principal es acercar los recursos informáticos, el almacenamiento y las aplicaciones al lugar donde se generan y consumen los datos, lo que ayuda a reducir la latencia, el uso del ancho de banda y la dependencia de una infraestructura de nube centralizada. El término «niebla» representa la idea de una nube que está más cerca del suelo o de los dispositivos periféricos, de forma análoga a las nubes más bajas que tocan la superficie de la tierra. Algunas de las ventajas de la denominada arquitectura son las siguientes:
- Proximidad a los dispositivos periféricos, optimización del ancho de banda de la nube
- Uso compartido de hardware entre dispositivos periféricos
- Baja latencia en comparación con una solución totalmente basada en la nube
- Arquitectura distribuida: cada nodo de niebla se comunica con otros nodos y con la nube central, formando una infraestructura de red escalable.
- Privacidad y seguridad de los datos: es posible que necesitemos procesar y almacenar datos confidenciales localmente dentro de la red antiniebla.
Selección de un proveedor de nube
Hasta ahora hemos descrito el problema de alto nivel del procesamiento de vídeo en tiempo real para realizar el aprendizaje automático. En la mayoría de los casos, los arquitectos de soluciones optarán por gestionar estas arquitecturas dentro de un proveedor definido en la nube. Todos los proveedores de nube extendida proporcionan servicios y herramientas para facilitar y acelerar el desarrollo, y para centralizar todas las funciones de las aplicaciones. Describiremos algunas alternativas en las tres nubes más extensas. No dude en utilizar directamente cualquiera de ellas.
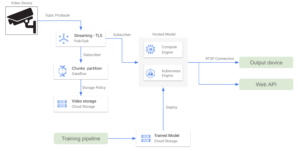
Amazon Web Services: cómo aprovechar Kinesis Data Streams
El hijo pródigo de las aplicaciones de streaming de vídeo en AWS es Transmisión de vídeo de Kinesis, un servicio totalmente gestionado que facilita la transmisión segura de vídeo desde los dispositivos conectados a la nube para su procesamiento y análisis en tiempo real y bajo demanda. Con este enfoque, todos los dispositivos de vídeo deben configurarse como productores de streaming. Luego, es necesario configurar una aplicación de procesamiento de vídeo que reciba la salida de que stream y ejecute todo el procesamiento y la inferencia de datos. También es posible enviar la salida del modelo a otro Kinesis Stream para su posterior procesamiento. Algunas funciones adicionales que se pueden implementar para mejorar esta arquitectura son las siguientes:
- Una política de retención de datos definida en la transmisión de vídeo de Kinesis para almacenar datos periódicamente en un bucket de S3.
- Una instancia EC2 aloja la aplicación de procesamiento de vídeo. También es posible seleccionar un AWS Fargate por ejemplo, mejor para gestionar el escalado automático de forma automática.
- Un modelo de SageMager implementado como resultado del proceso de capacitación ejecuta la etapa de inferencia. La aplicación de procesamiento de vídeo obtiene las predicciones de SageMaker y las envía a una transmisión de vídeo de Kinesis de salida.
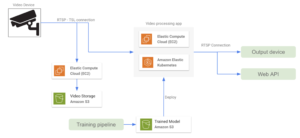
Al pensar en usar Kinesis Video Streams para una aplicación determinada, es necesario abordar su precios esquema, que se basa en la cantidad de datos ingeridos y de egreso de datos. Si los precios son una limitación sensible en la aplicación, otra alternativa sería configurar directamente una conexión RTSP entre la aplicación de procesamiento de vídeo y los dispositivos, lo que podría requerir un desarrollo adicional en comparación con Kinesis Video Streams. En este caso, un dispositivo de salida puede recibir la salida del modelo a través de una conexión RTSP.
Google Cloud Platform: Pub/Sub es todo lo que necesitas
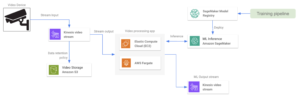
Google Cloud no cuenta con un servicio especializado para gestionar grandes cantidades de datos de streaming, como Amazon Video Streams. Sin embargo, es posible usar Google Pub/Sub para diseñar arquitecturas similares. Pub/Sub es un servicio de mensajería de uso general que permite una comunicación fiable y asincrónica entre aplicaciones independientes. Pub/Sub precios se basa en la cantidad de datos de rendimiento. Podemos configurar todos los dispositivos de vídeo como productores para un tema de Pub/Sub, para luego incluir fotogramas de vídeo en un tema. Luego, un modelo hospedado que se ejecuta en una aplicación en contenedores extrae el tema y obtiene todos los fotogramas de vídeo para su procesamiento. Algunos complementos que se pueden incluir en esta arquitectura son:
- Configuramos un servicio de Cloud Dataflow para almacenar los datos de streaming de entrada en un depósito de Cloud Storage. Otras canalizaciones de reentrenamiento de modelos pueden aprovechar estos datos de almacenamiento a largo plazo.
- Un dispositivo de salida recibe la salida del modelo a través de una conexión RTSP o una API web.
- El servidor hospedado (o placa Raspberry Pi) gestiona toda la transformación de datos en el lado del dispositivo.
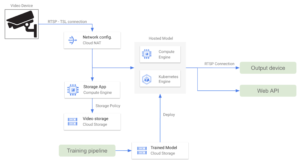
Al igual que en las alternativas de AWS, si los precios son una limitación y es necesario utilizar la menor cantidad de servicios en la nube, podemos configurar una conexión RTSP directa desde los dispositivos periféricos. Como todas las aplicaciones de GCP se ejecutan en una VPC, es necesario configurar NAT en la nube para que la red interna pueda recibir los datos entrantes. En este caso, dado que no estamos pensando en Pub/Sub, podríamos configurar una aplicación para almacenar datos de vídeo en Cloud Storage para volver a capacitarlos.
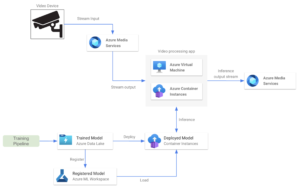
Plataforma de servicios multimedia de Microsoft Azure
Azure Media Services es una plataforma que permite a los usuarios crear y ofrecer soluciones de procesamiento de vídeo en tiempo real escalables y seguras. Ofrece una gama de servicios y funciones para codificar, transmitir, proteger y analizar el contenido multimedia en varios dispositivos. Es una plataforma general con muchas capacidades, pero las más relevantes están relacionadas con el envío y la recepción de datos a través de los protocolos RTMP o RTSP. Los servicios multimedia también incluyen funciones para el procesamiento de vídeo en directo, como cambiar el tamaño, recortar o ajustar la calidad del vídeo. Servicios multimedia precios se basa en la cantidad de transmisiones de configuración y se facturan diariamente. En cuanto a la arquitectura, las transmisiones de Media Services funcionan de manera similar a las transmisiones de video de Kinesis. Permite al usuario enviar vídeo en tiempo real desde un dispositivo de cámara a una aplicación de procesamiento de vídeo. Algunas características clave de esta alternativa son:
- Implementamos un modelo entrenado en un servicio hospedado, como una instancia de contenedor o una máquina virtual de Azure. Esta aplicación obtiene la transmisión desde la cuenta de Media Services.
- También es posible implementar el modelo de aprendizaje automático en otra instancia de contenedor para ejecutar el paso de inferencia, aprovechando los modelos de aprendizaje automático de Azure y las canalizaciones de entrenamiento.
- La aplicación de procesamiento de vídeo obtiene las predicciones y las envía a un flujo de salida.
Conclusiones
En este artículo describimos algunas alternativas de arquitectura básicas para diseñar una aplicación de procesamiento de vídeo en tiempo real de ML. Describimos algunas alternativas generales que utilizan Kafka Topics y conexiones RSTP entre dispositivos de vídeo y una aplicación de procesamiento de vídeo. A continuación, evaluamos el aspecto que tendría una implementación básica en cada proveedor de nube y describimos algunos posibles complementos. Una arquitectura real lista para la producción puede parecer bastante más compleja que las que se describen en este artículo. Esperamos que esta publicación sirva para iniciar una conversación a la hora de decidir cómo estructurar una aplicación con estas funciones de streaming.



.png)