.png)
Processamento de vídeo em tempo real: implantando aplicativos na nuvem




Como funciona Amazon Go cobrar você sem a necessidade de um checkout físico? É possível detectar falhas em produtos fabricados apenas analisando a gravação de uma câmera? Podemos desenvolver um aplicativo que supervisione os campos cultivados para detectar pragas e otimizar a irrigação? A resposta para todas essas perguntas está no campo do aprendizado de máquina com processamento de vídeo em tempo real: uma câmera (ou um conjunto de câmeras) é usada para gravar vídeo e esse vídeo é processado em tempo real para que o resultado desejado esteja disponível o mais instantaneamente possível, produzindo resultados quase em tempo real que podem impactar todos os tipos de negócios.
Há uma grande variedade de aplicativos de aprendizado de máquina (ML) que podem se beneficiar de uma abordagem de processamento de vídeo em tempo real. Rastreamento de objetos ou pessoas ao longo do tempo (para aplicativos de vigilância por vídeo), detecção automática de objetos em aplicativos de direção autônoma, alerta em uma indústria de manufatura sempre que algum incidente é detectado por uma câmera de vídeo e muito mais. Todos esses aplicativos compartilham alguns princípios básicos do computador e é possível implantá-los usando arquiteturas semelhantes.
Neste post, exploraremos algumas alternativas para projetar arquiteturas para implantar aplicativos de aprendizado de máquina prontos para produção que aproveitam o processamento de vídeo em tempo real. Analisaremos as vantagens e desvantagens de diferentes arquiteturas e exploraremos alternativas de nuvem nos fornecedores de nuvem mais relevantes. O objetivo principal desta postagem é fornecer um conjunto de possíveis arquiteturas de processamento de vídeo em tempo real que podem ser úteis nas etapas de design.
Enquadrando o problema
A imagem abaixo mostra um diagrama de alto nível do que estamos tentando construir. Um dispositivo captura vídeo e o envia para um módulo de comunicação que transmite o vídeo em um módulo de processamento. Nesta etapa de processamento, preparamos o vídeo quadro a quadro para aprendizado de máquina. A inferência ocorre no próximo módulo, em que um aplicativo de ML gera previsões com base na entrada. O aplicativo pode envolver detecção de objetos, reconhecimento facial, segmentação de imagens ou qualquer outra tarefa de visão computacional. Finalmente, enviamos a saída para o último módulo, onde os usuários finais a consomem.
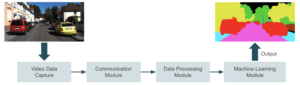
Existem duas abordagens principais para resolver esse problema:
- Usar os dispositivos da câmera somente para captura de dados e enviar o vídeo para um provedor de nuvem ou servidor dedicado. O servidor lida com todo o processamento de dados, inferência de aprendizado de máquina e geração de saída. Nesse caso, os pipelines de treinamento e implantação de modelos ocorrem no mesmo ambiente de nuvem.
- Aproveitando dispositivos de computação de ponta para aproximar a inferência de aprendizado de máquina dos dispositivos de câmera e transmitir somente a saída da inferência para um provedor de nuvem. Aqui é necessário implantar os modelos treinados na borda e usar aceleradores de GPU para executar a inferência no local.
A imagem abaixo mostra um diagrama de alto nível comparando essas duas abordagens.
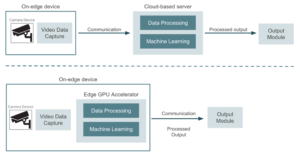
Apenas como referência, algumas das alternativas de hardware que podem ser usadas ao optar por uma arquitetura baseada em bordas são as Dispositivos NVIDIA (Jetson Nano, Jetson Xavier NX e Jetson AGX Xavier, com preços diferentes e capacidades de computação diferentes). Esses são essencialmente dispositivos de GPU com recursos de computação de desempenho que podemos conectar diretamente aos dispositivos de vídeo. Também é possível usar dispositivos baseados em USB, como Google Coral. Eles consistem em aceleradores USB conectados a dispositivos existentes, como placas Raspberry Pi, e oferecem recursos de TPU (unidade de processamento tensor). Nesse ponto, faz sentido nos perguntar qual abordagem nos dará o melhor resultado de custo/benefício e como tomar essa decisão. Vamos pensar na primeira abordagem, um conjunto de câmeras de segurança que capturam vídeo e o enviam para um ambiente de nuvem onde hospedamos um modelo de aprendizado de máquina implantado para detecção de objetos. Todos os dispositivos de vídeo realizam o processo de captura de dados, mas o ambiente em nuvem cuida do processamento do restante do pipeline, longe dos dispositivos periféricos. Há algumas vantagens de uma abordagem baseada em nuvem em comparação com a execução de uma inferência de aprendizado de máquina (ML) diretamente em dispositivos periféricos:
- A carga computacional em dispositivos de ponta é relativamente baixa, eles são usados apenas para capturar e enviar dados.
- É fácil aumentar ou diminuir os recursos de nuvem com base nos requisitos de carga de trabalho usando qualquer um dos serviços de nuvem que oferecem escalonamento automático.
- Um ambiente de nuvem centraliza modelos, software e infraestrutura, facilitando o gerenciamento da implantação, do retreinamento de modelos e das atualizações de software. Isso evita a necessidade de implantar modelos em cada dispositivo de ponta.
Agora, existem algumas desvantagens honestas ao adotar essa abordagem que valem a pena mencionar:
- A transmissão de dados para a nuvem introduz latência, que pode não ser adequada para aplicativos sensíveis à latência.
- A conectividade contínua e confiável com a Internet é fundamental para transmitir dados para a nuvem.
- Para evitar problemas com a privacidade de dados, precisamos garantir uma conectividade segura entre os dispositivos de ponta e a nuvem. Em uma arquitetura baseada em computação de ponta, os dados não precisam sair dos dispositivos de ponta na maioria dos casos. Existem aplicativos, por exemplo, em que enviar imagens de pessoas para a nuvem não é um cenário compatível.
A decisão de optar por uma solução baseada na nuvem ou na borda dependerá de uma compensação entre latência e custos. Se o aplicativo projetado admitir alguma tolerância à latência, uma abordagem baseada em nuvem pode ser a melhor opção. Por outro lado, mudar para uma arquitetura baseada em borda garantirá melhores propriedades de latência, mas também aumentará os custos de hardware, o que seria proibitivo em aplicativos com grandes quantidades de dispositivos. Optar por uma solução baseada em ponta também incluirá algum trabalho adicional para coordenar a implantação e as atualizações de modelos em todos os dispositivos. Como queremos nos concentrar na implantação de aplicativos de produção na nuvem, durante o restante desta postagem, nos concentraremos nas arquiteturas baseadas em nuvem e analisaremos os blocos detalhando alguns detalhes da implementação.
Streaming de vídeo para a nuvem
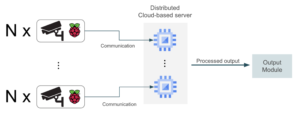
Como vimos anteriormente, o primeiro problema a ser resolvido em uma solução baseada em nuvem é enviar o vídeo capturado em tempo real para a nuvem. Normalmente, teremos um conjunto de câmeras gravando vídeo e será necessária pelo menos alguma interface básica entre esses dispositivos e o servidor em nuvem, para que a comunicação possa ser estabelecida. A maneira mais simples de resolver isso é conectar as câmeras, por exemplo, a um conjunto de placas Raspberry Pi com conexão à Internet:
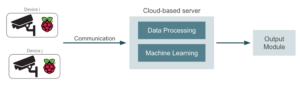
As placas Raspberry Pi serão usadas como uma interface entre as câmeras e o servidor dedicado que executa o aplicativo. No entanto, essa abordagem pode ter um problema. Pense, por exemplo, em uma câmera de segurança que grava um vídeo quase imóvel e emite um alerta sempre que algum intruso é encontrado. A maioria dos quadros de vídeo permanecerá inalterada e, portanto, não valerá a pena ser processada. Nesse caso, faria sentido implantar no Raspberry Pi um modelo pequeno que detectasse quadros relevantes e variados e enviasse somente esses quadros para a nuvem para o aprendizado de máquina adequado. Dessa forma, podemos obter algumas melhorias bastante importantes na largura de banda.
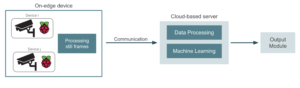
Em aplicativos que precisam processar quadros constantemente, como em um aplicativo de direção autônoma, essa alternativa pode não ser adequada. Agora, vamos ser um pouco mais técnicos e discutir algumas alternativas para realmente estabelecer essa conexão entre câmera e ambiente de nuvem:
Conexão direta entre câmeras e servidor
A maneira mais direta de enviar dados em tempo real é estabelecer uma conexão de streaming das placas Raspberry Pi para a nuvem. Isso pode ser feito configurando uma conexão RTSP (protocolo de streaming em tempo real), o que é possível usando muitas ferramentas de código aberto, como FFmpeg ou OpenCV. O módulo de processamento de dados lê diretamente os dados produzidos nas câmeras de vídeo, um quadro por vez. Também é relevante garantir a criptografia de dados confidenciais nesse tipo de conexão. Se o número de dispositivos de streaming não for tão alto, essa alternativa será suficiente para lidar com dados em tempo real. Mas se o aplicativo incluir milhares de dispositivos, precisaremos configurar uma arquitetura mais robusta e escalável. Vamos pular para a próxima alternativa...
Usando uma arquitetura editor-assinante
Uma alternativa para aplicativos mais escaláveis é fazer uso de uma plataforma de processamento de fluxo, a partir da qual Apache Kafka é provavelmente a mais extensa (mas arquiteturas semelhantes podem ser projetadas com Pulsar Apache, Transmissões do Redise muitas outras ferramentas). Nessa solução, os dados de streaming são estruturados em tópicos, as unidades fundamentais de organização e comunicação de dados. Os tópicos representam uma maneira pela qual os dados são compartilhados entre editores (os dispositivos que geram os dados de streaming) e consumidores (os aplicativos que lêem e processam esses dados). Os editores (câmeras de vídeo) enviam vários blocos de informações para um tópico, e os assinantes (o servidor em nuvem, no nosso caso) podem pesquisar as informações, bloco por bloco, do tópico. Para isso, podemos configurar um cluster de streaming com vários tópicos que recebem dados de streaming de vários dispositivos de vídeo. Os tópicos enviam dados para um servidor centralizado capaz de lidar com cargas de alto tráfego.

Nessa alternativa, precisamos desenvolver, implantar e manter um aplicativo de streaming, além do aplicativo principal de ML. Isso pode levar ao aumento dos custos de engenharia que podem valer a pena em algumas aplicações com cargas de tráfego consideravelmente altas.
Alternativas de streaming, quando devemos usar cada uma delas?
Resumindo, podemos considerar uma conexão direta de streaming nos seguintes cenários:
- Requisitos estritos de baixa latência. O streaming RTSP diretamente da câmera pode fornecer acesso de vídeo em tempo real mais rápido em comparação com um agente de mensagens, o que introduzirá alguma latência adicional.
- Necessidade de uma arquitetura simplificada sem integrações de dados complexas.
- Streaming em pequena escala: ao lidar com um pequeno número de câmeras ou um volume de dados limitado.
Por outro lado, uma abordagem baseada em editor-assinante deve ser usada em qualquer um desses casos:
- Ingestão de dados em grande escala de várias fontes com altos volumes de tráfego.
- Aplicativos que precisam de algum nível de escalabilidade automática. O gerenciamento de um cluster Kafka, por exemplo, fornecerá alguns recursos de escalonamento automático.
- Aplicações tolerantes a falhas.
Processamento de vídeo na nuvem
Vamos agora discutir algumas alternativas para o módulo de processamento. Como comentamos anteriormente, em uma abordagem baseada em nuvem, o ambiente de nuvem realiza tanto o processamento quanto a inferência de dados. Eles podem ser aplicativos diferentes, mas, por uma questão de simplicidade, vamos supor que apenas um aplicativo principal lida com as duas tarefas. Este módulo pegará o vídeo produzido e produzirá a saída de aprendizado de máquina que o módulo de saída receberá. Uma solução típica utiliza um servidor de GPU (que pode ser baseado na nuvem ou até mesmo no local, dependendo dos requisitos do aplicativo); esse servidor é responsável por lidar com todo o tráfego dos dispositivos e realizar inferências para cada quadro de vídeo. A solução mais simples é implantar o aplicativo de ML em uma instância de máquina virtual com recursos de GPU. O servidor manipula o tráfego de streaming de forma centralizada, como na figura abaixo:

Essa solução, embora fácil de implementar, pode ser adequada apenas para aplicativos pequenos com um número reduzido de dispositivos. Ter uma máquina centralizada que processa todos os dados de streaming pode significar que a instância provavelmente está superdimensionada. Como o servidor precisa suportar picos de tráfego (que normalmente não atingimos em um cenário típico), isso pode gerar contas altas. A seleção de uma instância subdimensionada também pode causar gargalos no processamento de dados em momentos de alto tráfego. Além disso, adicionar novos dispositivos de streaming pode apresentar alguns problemas de escalabilidade com um servidor centralizado. Uma alternativa para obter melhores recursos de escalabilidade é configurar vários servidores de GPU menores que lidam com o tráfego de um subconjunto de dispositivos. Dessa forma, é mais fácil escalar o hardware, pois o número de dispositivos aumenta apenas com a adição de novos servidores pequenos. Nessa segunda alternativa, a carga entre as GPUs deve ser distribuída de forma razoável para que nenhum recurso ocioso seja mantido.
Por fim, a solução mais robusta seria implantar um aplicativo de ML em contêineres e usar uma plataforma de orquestração de contêineres, como o Kubernetes, para gerenciar a implantação e o dimensionamento de contêineres. Com essa abordagem, podemos implantar instâncias adicionais de nosso aplicativo com base na demanda, otimizando o desempenho e os custos. Além disso, podemos obter um melhor uso dos recursos da GPU devido ao fato de os contêineres serem mais leves em comparação às máquinas virtuais.
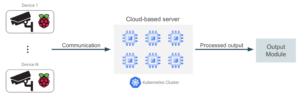
A seleção da arquitetura a ser usada para o módulo do aplicativo dependerá principalmente do tráfego, da possibilidade de aumentar o número de dispositivos ao longo do tempo e também das restrições de custo. A solução orquestrada em contêineres geralmente resultará em um alto custo de engenharia e desenvolvimento, mas também fornecerá a melhor otimização de custos.
Resultado do aprendizado de máquina: impactando os negócios
Uma arquitetura de streaming e processamento bem definida não significa muito se a saída do aplicativo não puder impactar positivamente nossos negócios. Nesta seção, discutiremos o módulo final e mais importante da arquitetura que descrevemos no início. Podemos categorizar os aplicativos de streaming em dois grupos principais:
- Aplicativos em que a saída é um fluxo de processamento de vídeo em tempo real. Rastreando trajetórias específicas de objetos ou pessoas ao longo do tempo, aplicando efeitos visuais em tempo real em um vídeo de entrada (como substituir fundos e remover objetos) e tradução automática de texto por vídeo, aplicada, por exemplo, à tradução de produtos chineses ou japoneses usando uma câmera móvel
- Aplicativos nos quais a saída é um conjunto de métricas que podem mudar com o tempo. Detectar defeitos em peças de fabricação, um problema em uma linha de montagem que aciona um alerta em um painel de controle, rastrear estatísticas de jogadores de futebol em tempo real durante um jogo ou lidar automaticamente com semáforos com base no tráfego atual são exemplos dessa categoria.

Para a primeira categoria, a saída geralmente é um conjunto de quadros processados que mostram a saída da inferência de ML. Nesse caso, talvez precisemos configurar alguma arquitetura de streaming adicional para lidar com a saída; é possível usar qualquer uma das alternativas já discutidas. No segundo caso, a saída é um sinal ou métrica que é armazenado em um banco de dados ou enviado para uma API externa que lida com todas as tarefas posteriores.
Na borda versus na nuvem, existe alguma solução intermediária?
Bem, a resposta é sim. Como mencionamos anteriormente, os custos de hardware associados aos aceleradores de GPU para executar inferência perto da borda são sem dúvida a limitação mais comum para a arquitetura de computação de ponta. Em alguns aplicativos, configurar uma GPU por dispositivo pode ser um exagero e uma arquitetura de computação em neblina pode ser adequada. O conceito de computação em neblina está relacionado ao compartilhamento de recursos de hardware entre muitos dispositivos de ponta. Enquanto a inferência é executada em uma rede local conectada à nuvem centralizada. O objetivo principal é aproximar os recursos de computação, o armazenamento e os aplicativos de onde os dados são gerados e consumidos, o que ajuda a reduzir a latência, o uso da largura de banda e a dependência da infraestrutura de nuvem centralizada. O termo “neblina” representa a ideia de uma nuvem que está mais próxima do solo ou dos dispositivos de borda, análoga às nuvens mais baixas que tocam a superfície da Terra. Alguns benefícios da chamada arquitetura são:
- Proximidade com dispositivos de ponta, otimizando a largura de banda da nuvem
- Compartilhamento de hardware entre dispositivos periféricos
- Baixa latência em comparação com uma solução totalmente baseada em nuvem
- Arquitetura distribuída: cada nó de neblina se comunica com outros nós e com a nuvem central, formando uma infraestrutura de rede escalável.
- Privacidade e segurança de dados: talvez precisemos processar e armazenar dados confidenciais localmente na rede de neblina.
Seleção de um provedor de nuvem
Até agora, descrevemos o problema de alto nível do processamento de vídeo em tempo real para realizar o aprendizado de máquina. Na maioria dos casos, os arquitetos de soluções escolherão lidar com essas arquiteturas em um provedor definido pela nuvem. Todos os fornecedores de nuvem estendida fornecem serviços e ferramentas para tornar o desenvolvimento mais fácil e rápido e para centralizar todos os recursos do aplicativo. Descreveremos algumas alternativas nas três nuvens mais extensas, sinta-se à vontade para entrar diretamente em qualquer uma delas.
Amazon Web Services: aproveitando o Kinesis Data Streams
O filho pródigo dos aplicativos de streaming de vídeo na AWS é Stream de vídeo do Kinesis, um serviço totalmente gerenciado que facilita a transmissão segura de vídeo de dispositivos conectados para a nuvem para processamento e análise em tempo real e sob demanda. Com essa abordagem, todos os dispositivos de vídeo devem ser configurados como produtores de stream. Em seguida, é necessário configurar um aplicativo de processamento de vídeo que receba a saída do stream e execute todo o processamento e inferência de dados. Também é possível enviar a saída do modelo para outro Kinesis Stream para processamento adicional. Alguns recursos extras que podem ser implementados para melhorar essa arquitetura são os seguintes:
- Uma política de retenção de dados definida no Kinesis Video Stream para armazenar dados periodicamente em um bucket do S3.
- Uma instância do EC2 hospeda o aplicativo de processamento de vídeo. Também é possível selecionar um AWS Fargate exemplo, melhor para gerenciar o escalonamento automático automaticamente.
- Um modelo SageManager implantado resultante do pipeline de treinamento executa o estágio de inferência. O aplicativo de processamento de vídeo obtém previsões do SageMaker e as envia para um stream de vídeo de saída do Kinesis.
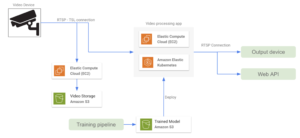
Ao pensar em usar o Kinesis Video Streams para um determinado aplicativo, é necessário abordar sua preços esquema, que é baseado na quantidade de ingestão e saída de dados. Se o preço for uma restrição sensível no aplicativo, outra alternativa seria configurar diretamente uma conexão RTSP entre o aplicativo de processamento de vídeo e os dispositivos, o que pode precisar de algum desenvolvimento adicional em comparação com o Kinesis Video Streams. Nesse caso, um dispositivo de saída pode receber a saída do modelo por meio de uma conexão RTSP.
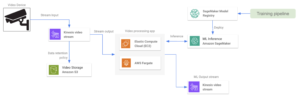
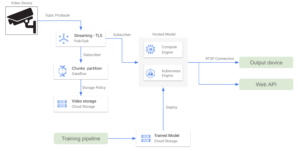
Google Cloud Platform: o Pub/Sub é tudo o que você precisa
O Google Cloud não tem um serviço especializado para lidar com grandes quantidades de dados de streaming, como o Amazon Video Streams. No entanto, é possível usar o Google Pub/Sub para criar arquiteturas semelhantes. O Pub/Sub é um serviço de mensagens de uso geral que permite comunicação confiável e assíncrona entre aplicativos independentes. Pub/Sub preços é baseado na quantidade de dados de taxa de transferência. Podemos configurar todos os dispositivos de vídeo como produtores para um tópico do Pub/Sub e, em seguida, inserir quadros de vídeo em um tópico. Em seguida, um modelo hospedado em execução em um aplicativo em contêiner retira o tópico e obtém todos os quadros de vídeo para processamento. Alguns complementos que podem ser incluídos nessa arquitetura são:
- Configuramos um serviço Cloud Dataflow para armazenar os dados de streaming de entrada em um bucket do Cloud Storage. Outros canais de reciclagem de modelos podem aproveitar esses dados de armazenamento de longo prazo.
- Um dispositivo de saída recebe a saída do modelo por meio de uma conexão RTSP ou de uma API da web.
- O servidor hospedado (ou placa Raspberry Pi) lida com toda a transformação de dados no lado do dispositivo.
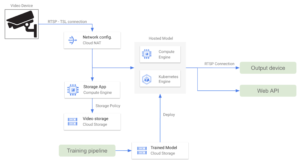
Assim como nas alternativas da AWS, se o preço for uma restrição e o menor número de serviços em nuvem precisar ser usado, podemos configurar uma conexão RTSP direta a partir dos dispositivos periféricos. Como todos os aplicativos do GCP são executados em uma VPC, é necessário configurar NAT na nuvem para que a rede interna possa receber os dados recebidos. Nesse caso, como não estamos considerando o Pub/Sub, podemos configurar um aplicativo para armazenar dados de vídeo no Cloud Storage para reciclagem.
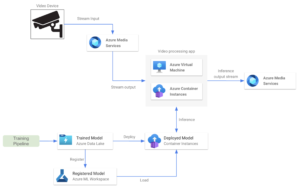
Plataforma de serviços de mídia do Microsoft Azure
Os Serviços de Mídia do Azure são uma plataforma que permite que os usuários criem e forneçam soluções de processamento de vídeo em tempo real escaláveis e seguras. Ele oferece uma variedade de serviços e recursos para codificação, streaming, proteção e análise de conteúdo de mídia em vários dispositivos. É uma plataforma geral com muitos recursos, mas os mais relevantes estão relacionados ao envio e recebimento de dados por meio de protocolos RTMP ou RTSP. Os Serviços de Mídia também incluem recursos para processamento de vídeo ao vivo, como redimensionar, cortar ou ajustar a qualidade do vídeo. Serviços de mídia preços é baseado no número de fluxos de configuração e eles são cobrados diariamente. Em termos de arquitetura, os streams de serviços de mídia funcionam de forma semelhante aos streams de vídeo do Kinesis. Ele permite que o usuário envie vídeo em tempo real de um dispositivo de câmera para um aplicativo de processamento de vídeo. Alguns dos principais recursos dessa alternativa são:
- Implantamos um modelo treinado em um serviço hospedado, como uma máquina virtual do Azure ou uma instância de contêiner. Este aplicativo obtém o streaming da conta de Serviços de Mídia.
- Também é possível implantar o modelo de ML em outra instância de contêiner para executar a etapa de inferência, aproveitando os modelos de ML e os pipelines de treinamento do Azure.
- O aplicativo de processamento de vídeo obtém previsões e as envia para um fluxo de saída.
Conclusões
Neste artigo, descrevemos algumas alternativas básicas de arquitetura para projetar um aplicativo de processamento de vídeo em tempo real de ML. Descrevemos algumas alternativas gerais usando tópicos do Kafka e conexões RSTP entre dispositivos de vídeo e um aplicativo de processamento de vídeo. Em seguida, avaliamos como seria uma implementação básica em cada provedor de nuvem e descrevemos alguns complementos possíveis. Uma arquitetura real pronta para produção pode parecer bem mais complexa do que as descritas neste post. Esperamos que esta postagem sirva para iniciar uma conversa ao decidir como estruturar um aplicativo com esses recursos de streaming.



.png)