.png)
Guiar el comportamiento del LLM: el arte de la ingeniería rápida




Los grandes modelos lingüísticos (LLM) han revolucionado el campo de la inteligencia artificial y el procesamiento del lenguaje natural. Estos poderosos modelos poseen una increíble capacidad para generar textos similares a los humanos y realizar una amplia gama de tareas relacionadas con el lenguaje. Sin embargo, para dar rienda suelta a su poder y lograr objetivos específicos, es esencial contar con una ingeniería rápida, cuidadosa y estratégica. Al elaborar instrucciones o indicaciones bien diseñadas, podemos guiar el resultado del modelo y garantizar la precisión y la adecuación contextual. En esta entrada del blog, analizaremos algunas de las técnicas de ingeniería rápida más populares que sirven como herramientas eficaces para moldear el comportamiento de los LLM y mejorar su rendimiento.
Pensando en los tokens

De la charla Estado de GPT[1], de Andrej Karpathy
La diapositiva de la charla (recomendada) sobre el estado del GPT de Andrej Karpathy presenta un ejemplo de un proceso que un humano normalmente seguiría para responder a la pregunta «¿Cómo se compara la población de California con la de Alaska?». En concreto, el proceso consiste en dividir la pregunta en partes más pequeñas, recopilar información de fuentes externas, utilizar una calculadora, realizar dos pasos de verificación (uno para comprobar si es razonable y otro para comprobar la ortografía) y corregir cualquier error. Es importante tener en cuenta que este proceso es más complejo que simplemente obtener el número 53 de una sola vez. La formación de los grandes modelos lingüísticos (LLM) consiste en predecir cuál será el próximo token más probable basándose en las estadísticas de un gran corpus de datos. Sin embargo, la mayoría de estos datos no están estructurados de la misma manera que el complejo proceso de pensamiento, investigación y verificación que implica responder a preguntas complejas. En pocas palabras: en los datos de entrenamiento veremos con mucha más frecuencia textos como «La población de California es 53 veces mayor que la población de Alaska» que el proceso de razonamiento ampliado que presentamos anteriormente. Pero, ¿qué ocurre cuando la información exacta que buscamos no está presente en los datos de entrenamiento y hay que obtenerla combinando y refinando diferentes partes? Para garantizar que los LLM sigan un proceso de razonamiento para llegar a las respuestas, debemos guiarlos proporcionándoles «elementos para pensar». En otras palabras, debemos dirigir el proceso de generación de respuestas del LLM para estimular el proceso de pensamiento a través de los tokens de salida. Las técnicas de ingeniería rápida nos ayudarán a hacer precisamente eso.
Recomendaciones para tratar los problemas de LLM
El siguiente es un posible conjunto de pasos a seguir cuando se trabaja con LLM extraídos (con cambios menores) del estado de conversación de GPT[1].
- Usa indicaciones con el contexto detallado de la tarea, información relevante e instrucciones.
- Experimente con algunos ejemplos de disparos que sean: 1) relevantes para el caso de prueba, 2) diversos (si corresponde)
- Recupere y añada cualquier información de contexto relevante al mensaje (Generated Knowledge Prompting)
- Experimente con técnicas de ingeniería rápida (CoT, autorreflexión, incitación descompuesta, autoconsistencia)
- Experimente con herramientas para descargar tareas difíciles para los LLM (calculadora, ejecución de código, API de búsqueda, etc.)
- Dedique tiempo de calidad a optimizar la canalización/cadena.
- Si está seguro de que ha agotado al máximo las solicitudes, considere la posibilidad de recopilar datos y realizar ajustes supervisados.
- Zona experta, frágil o de investigación: considere la recopilación de datos para un modelo de recompensas y un ajuste del RLHF.
En el resto de esta entrada del blog, revisaremos las estrategias de promoción que son relevantes para los pasos 2 a 4 del proceso de desarrollo de una solución basada en LLM.
Técnicas rápidas de ingeniería
En esta sección proporcionaremos una descripción general de algunas de las técnicas de incitación más populares, ofreciendo explicaciones concisas, ejemplos de uso y referencias para leer más. Según tu caso práctico, algunas técnicas serán más relevantes que otras. No te limites demasiado a los ejemplos, ya que no son exhaustivos: es mejor pensar en las técnicas como herramientas conceptuales que podrían aplicarse a tu caso de uso.
Pocos disparos
Implica proporcionar ejemplos al modelo del tipo de respuesta que esperamos.
Ejemplo

Algunos ejemplos que incitan a disparar
Impulsar el conocimiento generado
Consiste en incorporar conocimientos relevantes relacionados con la instrucción antes de generar la respuesta final. Es análogo a realizar un proceso de investigación antes de responder. Para generar conocimiento relevante, se puede utilizar tanto el modelo en sí (ponderaciones netas) como una fuente externa (recuperación de una base de datos de documentos).
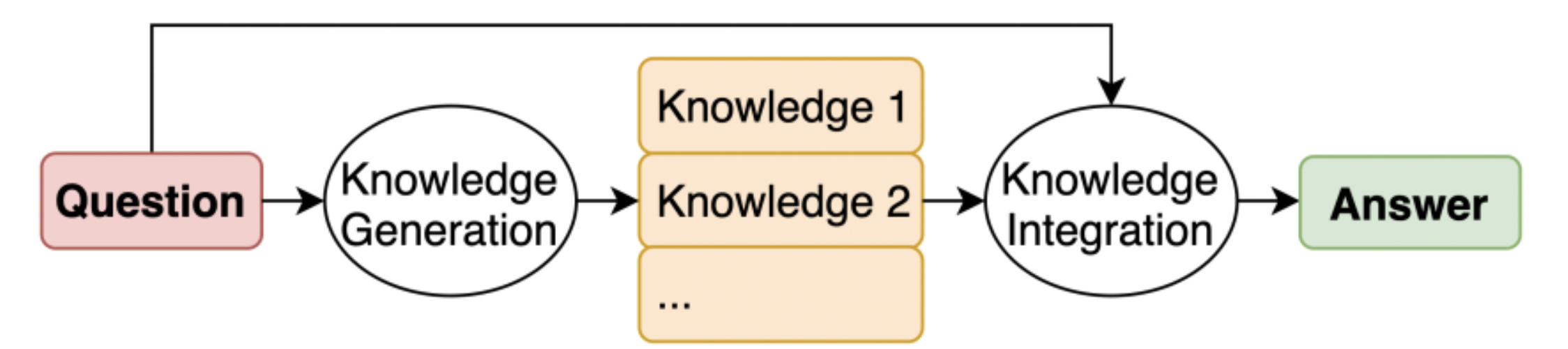
Imagen tomada del periódico El conocimiento generado impulsa el razonamiento con sentido común[3]
La generación de conocimiento se logra mediante un indicador Few-Shot. Para cada instrucción, se generan M frases de conocimiento (donde M = 20 en el artículo). Luego, estas oraciones se concatenan con la instrucción, lo que da como resultado M respuestas distintas. La respuesta final se obtiene al combinar todas las respuestas (en el caso de la clasificación, esto se hace por mayoría de votos).
Ejemplo

Ejemplo extraído del artículo El conocimiento generado impulsa el razonamiento con sentido común[3]
Impulsión de la cadena de pensamiento (CoT)
Implica dar instrucciones al modelo para que descomponga el proceso de respuesta en pasos intermedios antes de proporcionar la respuesta final. La forma más sencilla de lograrlo es incluir la instrucción «Pensemos paso a paso» (Zero Shot CoT, consulte Los modelos lingüísticos de gran tamaño no tienen nada que hacer[4]), pero también puede ser útil incluir ejemplos de la descomposición de la respuesta (Few Shot CoT, consulte La incitación a la cadena de pensamiento provoca el razonamiento en modelos lingüísticos grandes[5]).
Ejemplos

Ejemplo de CoT Zero-shot tomado del periódico Los modelos lingüísticos de gran tamaño no tienen nada que hacer[4]

Ejemplo de CoT de algunas fotos del periódico Los modelos lingüísticos de gran tamaño no tienen nada que hacer[4]
Autorreflexión
Implica agregar una capa de verificación a la respuesta generada para detectar errores, inconsistencias, etc. Se puede usar en un marco de Iterate-Refine, donde se pregunta al modelo si la respuesta generada cumple con la instrucción (o si contiene errores) y, de no ser así (en caso afirmativo), se genera una respuesta refinada.
Ejemplo

Respuesta GPT4, desde ¿Pueden los LLM criticar e iterar sus propios resultados?[6]
Indicaciones descompuestas
Implica generar una descomposición del mensaje original en diferentes submensajes y, a continuación, combinar los resultados para proporcionar la respuesta final. Un ejemplo de uso es la recuperación del control de calidad en varios saltos (preguntas que requieren la combinación de diferentes fuentes de información para obtener una respuesta). En el papel original[7], las subindicaciones se generan en función de una solicitud de pocos disparos específica para el caso de uso.
Ejemplo

Ejemplo de solicitud descompuesta
Autoconsistencia
Este enfoque implica aumentar la temperatura del modelo (una temperatura más alta equivale a una mayor aleatoriedad de las respuestas del modelo) para generar diferentes respuestas a la misma pregunta y luego proporcionar una respuesta final mediante la combinación de los resultados. En el caso de problemas de clasificación, esto se hace por mayoría de votos.
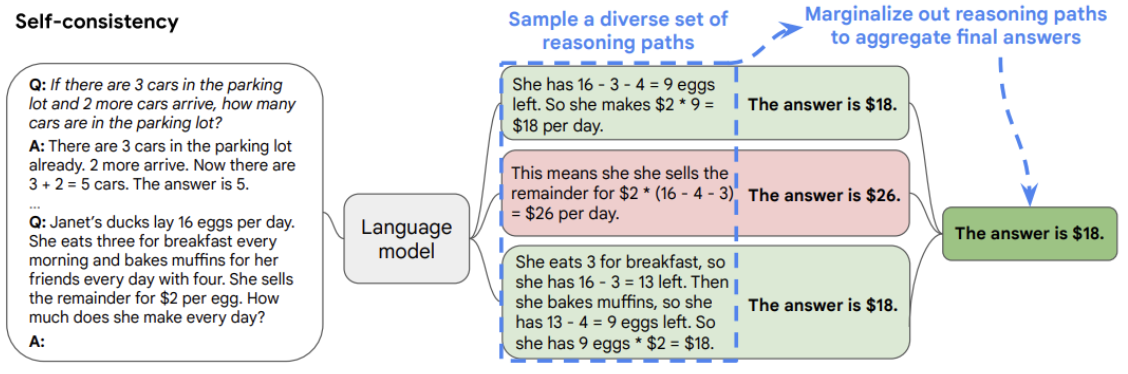
Imagen tomada del periódico La autoconsistencia mejora la cadena de razonamiento en los modelos lingüísticos[8]
La lista continúa...
El reciente aumento de los modelos de grandes lenguajes ha llevado a la publicación de numerosos artículos en el último año, centrados en diferentes técnicas de ingeniería rápida. Uno de los enfoques más notables es el denominado «Árbol de los pensamientos». En esta técnica, los autores deconstruyen el proceso de respuesta en pasos, de forma similar a la provocación descompuesta. Para cada paso, se generan múltiples respuestas potenciales, como en el caso de la autocoherencia. Por último, la selección de las mejores respuestas se determina mediante la autoevaluación del modelo, como en la autorreflexión. No dudes en leer más sobre esto en el artículo[9] si estás interesado.
Conclusión y reflexiones finales
Con la llegada de los LLM, el campo de la inteligencia artificial y el procesamiento del lenguaje natural ha sido testigo de una transformación notable. Estos potentes modelos han revolucionado la generación de textos y las tareas relacionadas con el lenguaje, con una capacidad extraordinaria para crear textos que se parecen mucho al lenguaje humano. Sin embargo, para aprovechar su verdadero poder, es esencial utilizar técnicas de ingeniería rápida. Al comprender las complejidades del diseño rápido y reproducir los elementos del proceso de pensamiento humano, podemos proporcionar a los LLM las «claves para pensar» que necesitan. De esta manera, podemos dirigir su proceso de razonamiento para llegar a respuestas más precisas y adecuadas al contexto. Recuerde que la lista de ejemplos que se proporciona aquí no es exhaustiva: piense en las técnicas como herramientas conceptuales que pueden o no tener sentido en su escenario específico. ¡Diviértete diseñando!
Referencias
- Estado de GPT, charla de Andrej Karpathy, miembro fundador de OpenAI.
- Una guía de incorporación a los LLM, excelente publicación para entender mejor los LLM.
- El conocimiento generado impulsa el razonamiento con sentido común.
- Los modelos de lenguaje extensos no tienen nada que hacer.
- La incitación a la cadena de pensamiento provoca el razonamiento en modelos lingüísticos grandes.
- ¿Pueden los LLM criticar e iterar sus propios resultados?
- Prompting descompuesto: un enfoque modular para resolver tareas complejas.
- La autoconsistencia mejora el razonamiento en cadena de pensamiento en los modelos lingüísticos.
- Árbol de pensamientos: resolución deliberada de problemas con modelos lingüísticos de gran tamaño.



.png)