.png)
Orientando o comportamento do LLM: a arte da engenharia rápida




Grandes modelos de linguagem (LLMs) revolucionaram o campo da inteligência artificial e do processamento de linguagem natural. Esses modelos poderosos possuem uma capacidade incrível de gerar texto semelhante ao humano e realizar uma ampla variedade de tarefas relacionadas ao idioma. No entanto, para realmente liberar seu poder e atingir metas específicas, uma engenharia rápida e estratégica é essencial. Ao criar instruções ou prompts bem projetados, podemos orientar a saída do modelo, garantindo precisão e adequação contextual. Nesta postagem do blog, exploraremos algumas das técnicas de engenharia rápida mais populares que servem como ferramentas eficazes para moldar o comportamento dos LLMs e aprimorar seu desempenho.
Pensando em tokens

Da palestra Estado do GPT[1], de Andrej Karpathy
O slide da palestra (recomendada) State of GPT, de Andrej Karpathy, apresenta um exemplo de um processo que um humano normalmente seguiria para responder à pergunta “Como a população da Califórnia se compara à do Alasca?”. Especificamente, o processo envolve dividir a pergunta em partes menores, coletar informações de fontes externas, usar uma calculadora, realizar duas etapas de verificação (uma para razoabilidade e outra para ortografia) e corrigir quaisquer erros. É importante observar que esse processo é mais complexo do que simplesmente obter o número (token) 53 de uma só vez. O treinamento de modelos de linguagem grande (LLMs) consiste em prever o próximo token mais provável com base nas estatísticas de um grande corpus de dados. No entanto, a maioria desses dados não é estruturada da mesma forma que as complexas etapas de processo de pensamento, pesquisa e verificação envolvidas na resposta a perguntas complexas. Em termos simples: nos dados de treinamento, veremos com muito mais frequência textos como “A população da Califórnia é 53 vezes a população do Alasca” do que o processo de raciocínio expandido que apresentamos anteriormente. Mas o que acontece quando a informação exata que estamos procurando não está presente nos dados de treinamento e precisa ser obtida combinando e refinando diferentes partes? Para garantir que os LLMs sigam um processo de raciocínio para chegar às respostas, precisamos orientá-los fornecendo “sinais para pensar”. Em outras palavras, devemos direcionar o processo de geração de respostas do LLM para estimular o processo de pensamento por meio dos tokens de saída. Técnicas rápidas de engenharia nos ajudarão a fazer exatamente isso.
Recomendações para lidar com problemas de LLM
A seguir está um conjunto possível de etapas a serem seguidas ao trabalhar com LLMs extraídos (com pequenas alterações) do Talk State of GPT[1].
- Use prompts com contexto detalhado da tarefa, informações e instruções relevantes.
- Experimente alguns exemplos de fotos que sejam: 1) relevantes para o caso de teste, 2) diversos (se apropriado)
- Recupere e adicione qualquer informação de contexto relevante à solicitação (solicitação de conhecimento gerada)
- Experimente técnicas de engenharia imediata (CoT, autorreflexão, solicitação decomposta, autoconsistência)
- Experimente ferramentas para descarregar tarefas difíceis para LLMs (calculadora, execução de código, apis de pesquisa etc.)
- Passe um tempo de qualidade otimizando a tubulação/cadeia.
- Se você se sentir confiante de que atingiu o limite máximo de solicitação, considere a coleta de dados e o ajuste fino supervisionado.
- Zona especialista/frágeil/de pesquisa: considere a coleta de dados para um modelo de recompensa e o ajuste fino do RLHF.
No restante desta postagem do blog, analisaremos as estratégias de solicitação que são relevantes para as etapas 2 a 4 do processo de desenvolvimento de uma solução baseada em LLMs.
Técnicas rápidas de engenharia
Nesta seção, forneceremos uma visão geral de algumas das técnicas de solicitação mais populares, oferecendo explicações concisas, exemplos de uso e referências para leitura adicional. De acordo com seu caso de uso, algumas técnicas serão mais relevantes do que outras. Não se restrinja muito aos exemplos, pois eles não são exaustivos: é melhor pensar nas técnicas como ferramentas conceituais que podem ser aplicáveis ao seu caso de uso.
Poucos avisos de tiro
Envolve fornecer exemplos para o modelo do tipo de resposta que esperamos.
Exemplo

Alguns exemplos de aviso de fotos
Solicitação de conhecimento gerado
Consiste em incorporar conhecimentos relevantes relacionados à instrução antes de gerar a resposta final. É análogo a conduzir um processo de pesquisa antes de responder. Para a geração de conhecimento relevante, tanto o modelo em si (pesos líquidos) quanto uma fonte externa (recuperação de um banco de dados de documentos) podem ser usados.
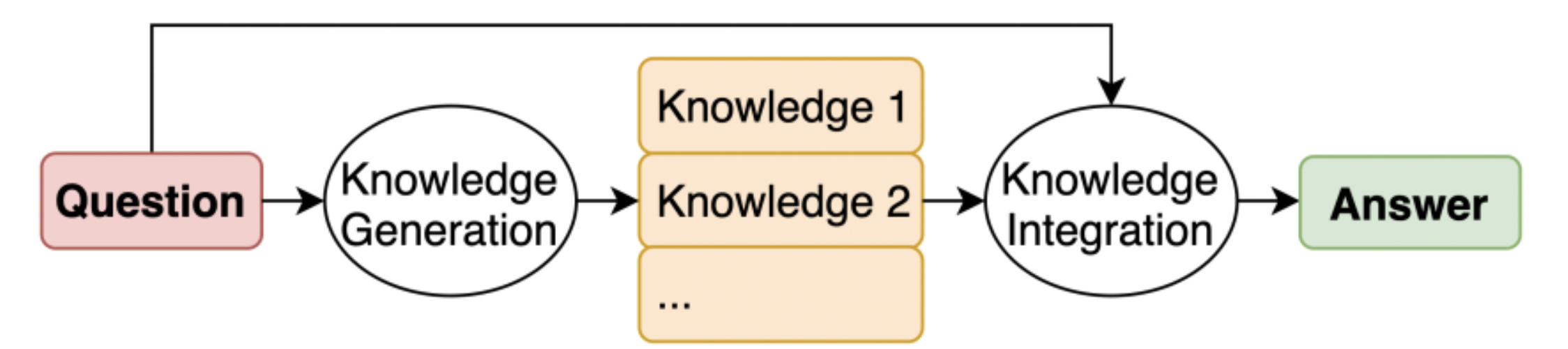
Imagem retirada do jornal Conhecimento gerado que estimula o raciocínio de senso comum[3]
A geração de conhecimento é obtida usando um prompt Few-Shot. Para cada instrução, M frases de conhecimento são geradas (onde M = 20 no artigo). Essas frases são então concatenadas com a instrução, resultando em M respostas distintas. A resposta final é obtida combinando todas as respostas (no caso de classificação, isso é feito por maioria de votos).
Exemplo

Exemplo retirado do jornal Conhecimento gerado que estimula o raciocínio de senso comum[3]
Sugestão da cadeia de pensamento (CoT)
Envolve instruir o modelo a decompor o processo de resposta em etapas intermediárias antes de fornecer a resposta final. A maneira mais simples de conseguir isso é incluir a instrução “Vamos pensar passo a passo” (Zero Shot CoT, consulte Modelos de linguagem grandes são raciocinadores irrepetíveis[4]), mas também pode ser útil incluir exemplos da decomposição da resposta (Few Shot CoT, consulte O estímulo à cadeia de pensamento provoca raciocínio em grandes modelos de linguagem[5]).
Exemplos

Exemplo de CoT Zero-shot do jornal Modelos de linguagem grandes são raciocinadores irrepetíveis[4]

Alguns exemplos de CoT retirados do jornal Modelos de linguagem grandes são raciocinadores irrepetíveis[4]
Auto-reflexão
Envolve adicionar uma camada de verificação à resposta gerada para detectar erros, inconsistências etc. Ela pode ser usada em uma estrutura Iterate-Refine, na qual o modelo é perguntado se a resposta gerada atende à instrução (ou se contém erros) e, se não, (se sim), uma resposta refinada é gerada.
Exemplo

Resposta GPT4, de Os LLMs podem criticar e iterar seus próprios resultados?[6]
Solicitação decomposta
Isso envolve gerar uma decomposição do prompt original em diferentes subprompts e, em seguida, combinar os resultados para fornecer a resposta final. Um exemplo de caso de uso é a recuperação de controle de qualidade em vários saltos (perguntas que exigem a combinação de diferentes fontes de informação para fornecer uma resposta). Na papel original[7], os subprompts são gerados com base em um prompt específico do Few Shot para o caso de uso.
Exemplo

Exemplo de solicitação decomposta
Autoconsistência
Essa abordagem envolve aumentar a temperatura do modelo (temperatura mais alta equivale a maior aleatoriedade das respostas do modelo) para gerar respostas diferentes para a mesma pergunta e, em seguida, fornecer uma resposta final combinando os resultados. No caso de problemas de classificação, isso é feito por maioria de votos.
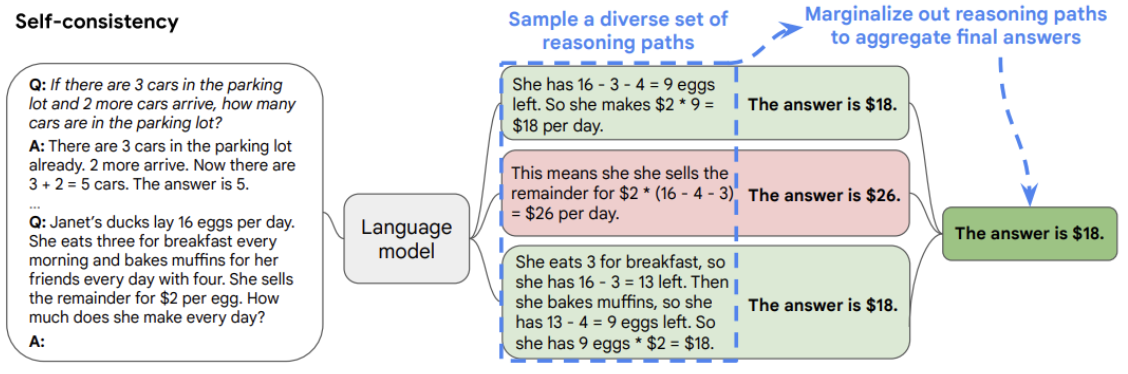
Imagem retirada do jornal A autoconsistência melhora o raciocínio da cadeia de pensamento em modelos de linguagem[8]
A lista continua...
O recente aumento de modelos de linguagem grande levou à publicação de vários artigos no último ano, com foco em diferentes técnicas rápidas de engenharia. Uma das abordagens notáveis é chamada de “Árvore dos Pensamentos”. Nessa técnica, os autores desconstroem o processo de resposta em etapas, semelhantes à Solicitação Decomposta. Para cada etapa, várias respostas potenciais são geradas, como em Autoconsistência. Por fim, a seleção das melhores respostas é determinada por meio da autoavaliação do modelo, como na Autorreflexão. Não hesite em ler mais sobre isso no papel[9] se você estiver interessado.
Conclusão e considerações finais
Com o advento dos LLMs, o campo da inteligência artificial e do processamento de linguagem natural testemunhou uma transformação notável. Esses modelos poderosos revolucionaram a geração de texto e as tarefas relacionadas à linguagem com uma capacidade extraordinária de criar texto que se assemelha muito à linguagem humana. No entanto, para liberar seu verdadeiro poder, o uso de técnicas rápidas de engenharia é essencial. Ao compreender as complexidades do design imediato e da replicação de elementos do processo de pensamento humano, podemos fornecer aos LLMs os “símbolos para pensar” necessários. Dessa forma, podemos direcionar seu processo de raciocínio para chegar a respostas mais precisas e contextualmente apropriadas. Lembre-se de que a lista de exemplos fornecida aqui não é abrangente: pense nas técnicas como ferramentas conceituais que podem ou não fazer sentido em seu cenário específico. Divirta-se fazendo engenharia!
Referências
- Estado do GPT, palestra de Andrej Karpathy, membro fundador da OpenAI.
- Um guia de integração para LLMs, ótimo post para entender melhor os LLMs.
- Conhecimento gerado que estimula o raciocínio de senso comum.
- Modelos de linguagem grandes são raciocinadores irrepetíveis.
- O estímulo à cadeia de pensamento provoca raciocínio em grandes modelos de linguagem.
- Os LLMs podem criticar e iterar seus próprios resultados?
- Solicitação decomposta: uma abordagem modular para resolver tarefas complexas.
- A autoconsistência melhora o raciocínio da cadeia de pensamento em modelos de linguagem.
- Árvore de pensamentos: resolução deliberada de problemas com grandes modelos de linguagem.



.png)