.png)
Destilación de modelos: aprovechar la falta de datos con StyleGan2




En este blog vamos a hablar sobre una técnica llamada destilación de modelos y cómo se puede utilizar para entrenar modelos supervisados a partir de conjuntos de datos sintéticos creados con GAN. Con esta técnica, podemos aprovechar las propiedades de la generación incondicional de imágenes y utilizarlas en modelos condicionales, con un mejora sobresaliente en el tiempo de ejecución (más de 150 veces más rápido) y costo.
Un poco de teoría
Los modelos generativos son un subgrupo de modelos no supervisados con la capacidad de generalizar y crear nuevos elementos a partir de ejemplos de datos. Redes generativas de confrontación (GAN) se encuentran dentro de este grupo.
GAN
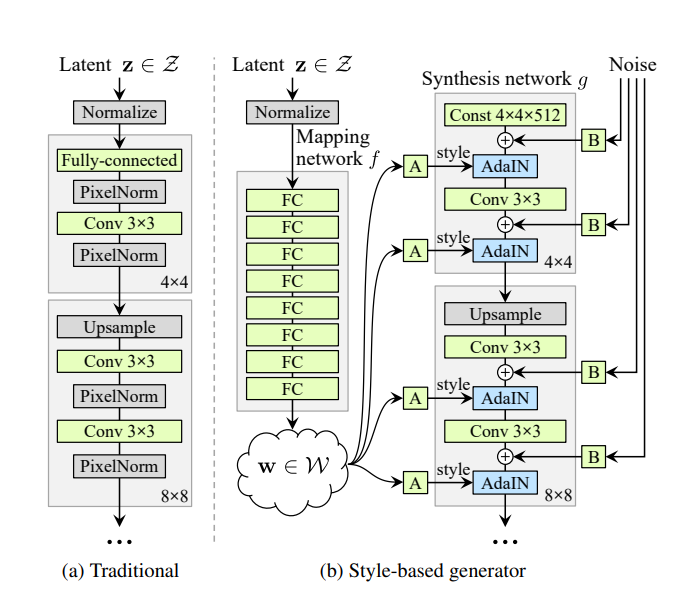
Las GAN definen una arquitectura de redes generativas basada en 2 submodelos: el generador y el discriminador. Ambos compiten en un juego de suma cero, intentando engañar a su adversario. El generador recibe ruido procedente de un espacio latente predefinido y tiene que generar un contenido similar a partir del conjunto de entradas. El discriminador, por otro lado, debe discernir si el contenido dado por el generador pertenece al conjunto de entrada o no. Ambos modelos se entrenan de manera conjunta, dándose retroalimentación entre sí, hasta que el generador pueda engañar al discriminador aproximadamente la mitad de las veces. Hay muchas aplicaciones de las GAN en la visión artificial, desde la creación y edición automática de contenido de alta calidad hasta el aumento de datos. Estilo GAN 2[1] es una arquitectura GAN creada por NVIDIA para la generación de imágenes, utilizada principalmente para rostros humanos, cuyo generador tiene la capacidad de modificar las características individuales de una imagen de forma altamente desacoplada, lo que permite aplicar estilos a la imagen generada con diferentes niveles de granularidad.


Su generador incorpora una red de mapeo de 8 capas totalmente conectadas, que recibe un vector Z y genera 18 vectores a partir del espacio latente W. Estos vectores alimentan cada una de las 18 capas del generador de forma individual, lo que permite modificar solo unas pocas para aplicar cambios específicos en la imagen, sin alterarla en su conjunto.
CGAN
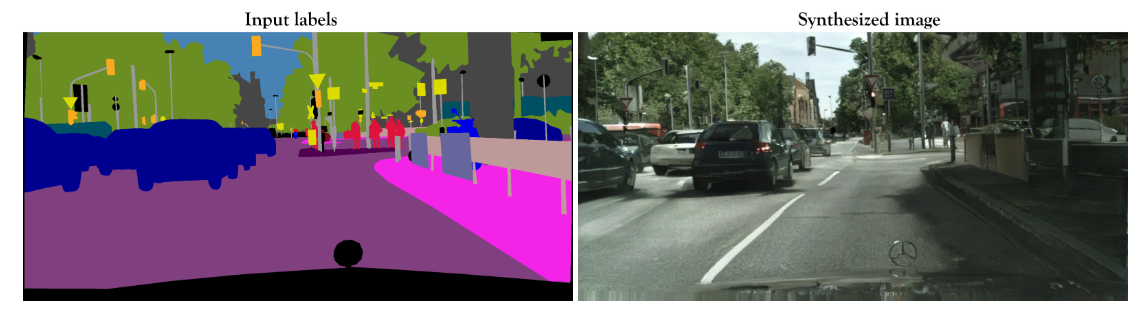
Las GAN condicionales (CGAN), por otro lado, son redes GAN que utilizan información adicional que condiciona la generación de datos. Por lo general, se entrenan con pares de imágenes origen-destino, lo que hace que la tarea sea supervisada. Pix2PixHD[2] es un modelo de CGaN que permite crear imágenes fotorrealistas a partir de mapas de etiquetas semánticas. Este modelo se entrena con pares de imágenes y requiere un gran conjunto de datos.
Aplicación de la vida real
En uno de nuestros proyectos, teníamos un sistema de transformación automática de imágenes hecho con StyleGan. El sistema usó un codificador para encontrar la representación vectorial de una imagen real en el espacio latente de StyleGan, luego modificó el vector aplicando la transformación de características y generó la imagen con el vector resultante. El problema de este sistema es que, para encontrar el vector de la imagen real, debe ejecutar varias iteraciones de retropropagación, comparando las imágenes resultantes con el objetivo e intentando aproximarlo. Esta tarea es realmente costosa en tiempo y computación. En este caso, nuestro trabajo consistía en reducir el tiempo de ejecución del sistema sin comprometer la calidad de las imágenes.
Modelo de destilación
Nuestra solución consistió en utilizar una técnica llamada modelo de destilación para aprovechar la falta de imágenes necesarias para entrenar a Pix2PixHD. Se utilizó para abordar este problema en el artículo titulado «StyleGan2 Distillation for Feed-forward Image Manipulation» [3] Esta técnica consiste en hacer que una red de estudiantes aprenda de los resultados de una red de profesores más grande. En nuestro caso, este concepto se aplica generando imágenes aleatorias y sus respectivos vectores latentes con StyleGan2, aplicando las transformaciones de características a los vectores y generando los pares con la imagen original y la modificada. De esta manera, pudimos crear un conjunto de datos sintético de 10 000 imágenes de alta calidad para entrenar a Pix2PixHD. Realizamos una prueba cualitativa sobre la calidad de las imágenes generadas por StyleGan2 y descubrimos que, aproximadamente, el 86% de las imágenes tenían una calidad aceptable. Teníamos que encontrar una manera de limpiar el 14% restante.
Preparación de los datos
Como el sistema original solo se usaba en adultos, decidimos filtrar el conjunto de datos generado, dado que StyleGan2 genera rostros de todas las edades. Para ello, utilizamos la API Face de Azure para clasificar cada imagen y filtrar todas las imágenes que estén fuera de nuestro rango objetivo. Esto también tuvo una ventaja adicional: filtramos las imágenes con demasiados artefactos en las que la API no podía reconocer su antigüedad. De esta forma, nos aseguramos de que las imágenes tuvieran una calidad aceptable a un coste muy bajo.

Entrenamiento
Con el conjunto de datos listo, procedimos a la capacitación. Optamos por una instancia AWS EC2 de g4dn.xlarge, con un coste por hora de 0,526 USD y un tiempo estimado para completar los 200 períodos de 22 días (anteriormente analizamos algunos períodos para calcular esta estimación), lo que resultó en un coste aproximado de 277 USD para toda la formación.
Resultados
Los resultados superaron las expectativas en cuanto a tiempo de cálculo y costo de hardware, manteniendo la excelente calidad de las imágenes y generando transformaciones realistas tanto para las imágenes reales como para las generadas por StyleGan2.




Teníamos el tiempo promedio de la versión anterior, 19,36 segundos en una instancia de g3s.xlarge con un coste por hora de 0,75 USD como punto de referencia. El tiempo de inferencia del nuevo modelo, promediado a partir de 500 imágenes en la misma instancia, fue de 0,11 segundos, 176 veces más bajo. Al mismo tiempo, al eliminar la necesidad del codificador de encontrar los vectores latentes, fue posible ejecutar el modelo en instancias sin GPU, con tiempos de inferencia también mejores que en la versión original. Por ejemplo, el tiempo de inferencia en una CPU (solo c5.2xlarge) es de 1,5 segundos; incluso un t2.medium puede ejecutar el modelo con un tiempo de inferencia de 7,23 segundos.
Conclusiones clave
- StyleGan2 genera imágenes de alta calidad, con muchas capacidades de transformación. Se puede usar con imágenes reales con la ayuda de un codificador, pero ha demostrado ser lento y caro.
- Sin embargo, StyleGan2 demostró tener el potencial suficiente para generar un conjunto de datos sintéticos diverso y de alta calidad. Este conjunto de datos se puede utilizar para entrenar un modelo condicional sin las desventajas de tener que incorporar un codificador.
- Pix2PixHD se puede usar para generar transformaciones automáticas en imágenes realistas con un conjunto de datos lo suficientemente grande. Se adapta muy bien a los conjuntos de datos generados por StyleGan.
- Las API externas, como la API Face de Azure, se pueden usar como validación automática de datos.
Referencias
[1] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Análisis y mejora de la calidad de imagen de Stylegan. arXiv preprint arXiv: 1912.04958 (2019) [2] Wang, Ting-Chun et al. «Síntesis de imágenes de alta resolución y manipulación semántica con GAN condicionales». Conferencia IEEE/CVF de 2018 sobre visión artificial y reconocimiento de patrones (2018) [3] Viazovetskyi, Yuri, Vladimir Ivashkin y Evgeny Kashin. «Destilación de StyleGan2 para la manipulación de imágenes con retroalimentación». Apuntes de clase sobre informática (2020)



.png)