.png)
Destilação de modelos: aproveitando a falta de dados com o StyleGAN2




Neste blog, falaremos sobre uma técnica chamada destilação de modelos e como ela pode ser usada para treinar modelos supervisionados a partir de conjuntos de dados sintéticos criados com GANs. Com essa técnica, podemos aproveitar as propriedades da geração incondicional de imagens e usá-las em modelos condicionais, com um excelente melhoria no tempo de execução (mais de 150 vezes mais rápido) e custo.
Um pouco de teoria
Os modelos generativos são um subgrupo de modelos não supervisionados com a capacidade de generalizar e criar novos elementos a partir de exemplos de dados. Redes adversárias generativas (GANs) podem ser encontrados dentro desse grupo.
GANs
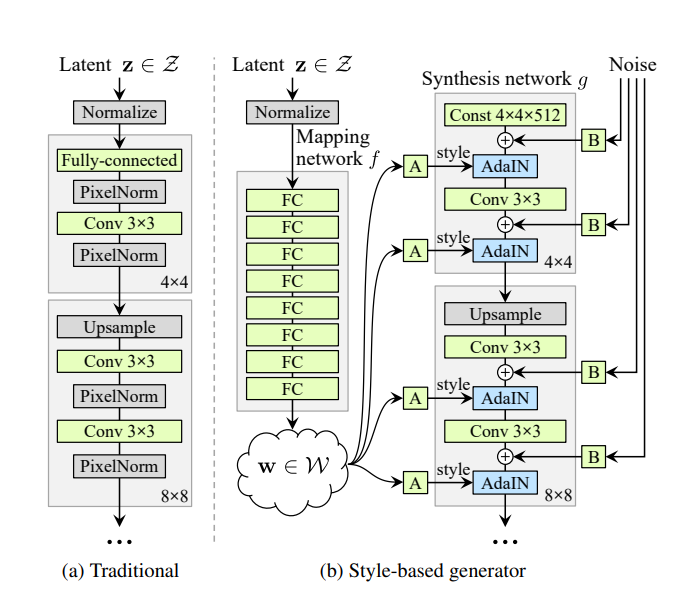
Os GANs definem uma arquitetura de redes generativas baseada em 2 submodelos: o gerador e o discriminador. Ambos competem em um jogo de soma zero, tentando enganar o adversário. O gerador recebe ruído proveniente de um espaço latente predefinido e precisa gerar conteúdo semelhante a partir do conjunto de entrada. O discriminador, por outro lado, deve discernir se o conteúdo fornecido pelo gerador pertence ao conjunto de entrada ou não. Ambos os modelos são treinados em conjunto, dando feedback um ao outro, até que o gerador consiga enganar o discriminador cerca de metade das vezes. Existem muitas aplicações de GANs em visão computacional, desde a criação e edição automática de conteúdo de alta qualidade até o aumento de dados. Estilo GAN 2[1] é uma arquitetura GAN criada pela NVIDIA para geração de imagens, usada principalmente para rostos humanos, cujo gerador tem a capacidade de modificar características individuais de uma imagem de forma altamente desacoplada, permitindo aplicar estilos à imagem gerada com diferentes níveis de granularidade.


Seu gerador incorpora uma rede de mapeamento de 8 camadas totalmente conectadas, que recebe um vetor Z e gera 18 vetores do espaço latente W. Esses vetores alimentam cada uma das 18 camadas do gerador individualmente, possibilitando modificar apenas algumas para aplicar mudanças específicas na imagem, sem alterá-la como um todo.
CGANs
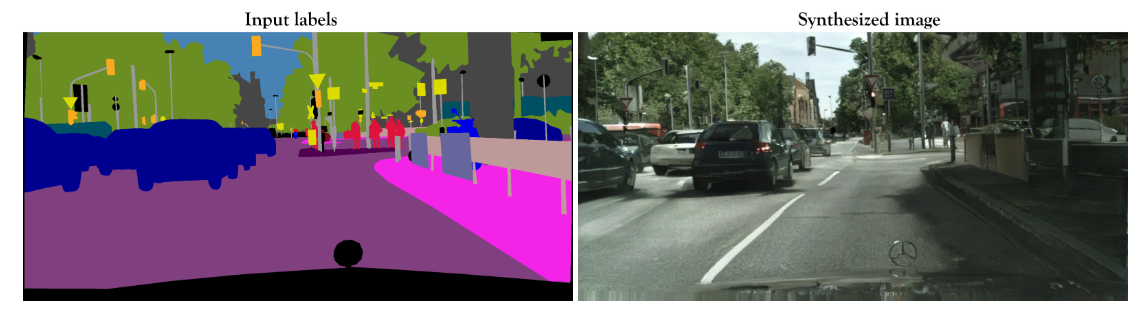
Os GANs condicionais (CGANs), por outro lado, são redes GAN que usam informações adicionais que condicionam a geração de dados. Eles geralmente são treinados com pares de imagens fonte-alvo, tornando a tarefa supervisionada. Pix2Pix HD[2] é um modelo CGaN que permite criar imagens fotorrealistas a partir de mapas de rótulos semânticos. Esse modelo é treinado com pares de imagens e requer um grande conjunto de dados.
Aplicação na vida real
Em um de nossos projetos, tivemos um sistema automático de transformação de imagem feito com o StyleGAN. O sistema usou um codificador para encontrar a representação vetorial de uma imagem real no espaço latente do StyleGAN, depois modificou o vetor aplicando a transformação do recurso e gerou a imagem com o vetor resultante. O problema desse sistema é que, para encontrar o vetor da imagem real, ele deve executar várias iterações de retropropagação, comparando as imagens resultantes com o objetivo, tentando aproximá-lo. Essa tarefa é muito demorada e cara de computação. Nesse caso, nosso trabalho foi reduzir o tempo de execução do sistema sem comprometer a qualidade das imagens.
Destilação modelo
Nossa solução consistiu em usar uma técnica chamada destilação modelo para aproveitar a falta de imagens necessárias para treinar o Pix2pixHD. Foi usada para resolver esse problema no artigo “StyleGaN2 Distillation for Feed-forward Image Manipulation" [3]. Essa técnica consiste em fazer com que uma rede de estudantes aprenda com a produção de uma rede maior de professores. No nosso caso, esse conceito é aplicado gerando imagens aleatórias e seus respectivos vetores latentes com o StyleGAN2, aplicando as transformações de características aos vetores e gerando os pares com a imagem original e a modificada. Dessa forma, conseguimos criar um conjunto de dados sintético de 10.000 imagens de alta qualidade para treinar o Pix2PixHD. Realizamos um teste qualitativo sobre a qualidade das imagens geradas pelo StyleGan2 e descobrimos que, aproximadamente, 86% das imagens tinham uma qualidade aceitável. Precisávamos encontrar uma maneira de limpar os 14% restantes.
Preparando os dados
Como o sistema original era usado apenas em adultos, decidimos filtrar o conjunto de dados gerado, já que o StyleGan2 gera rostos de todas as idades. Para fazer isso, usamos a API Face do Azure para classificar cada imagem e filtrar cada imagem fora do nosso intervalo alvo. Isso também teve um benefício colateral: filtramos imagens com muitos artefatos nos quais a API não conseguia reconhecer a idade. Dessa forma, garantimos que as imagens tivessem uma qualidade aceitável a um custo muito baixo.

Treinamento
Com o conjunto de dados pronto, prosseguimos com o treinamento. Optamos por uma instância g4dn.xlarge do AWS EC2, com um custo por hora de 0,526 USD e um tempo estimado para concluir os 200 períodos de 22 dias (anteriormente, executamos alguns períodos para calcular essa estimativa), resultando em um custo aproximado de 277 USD para todo o treinamento.
Resultados
Os resultados superaram as expectativas em tempo de computação e custo de hardware, mantendo a excelente qualidade das imagens e gerando transformações realistas para imagens reais e geradas pelo StyleGAN2.




Tivemos o tempo médio da versão anterior, 19,36 segundos em uma instância g3s.xlarge com um custo por hora de 0,75 USD como referência. O tempo de inferência do novo modelo, em média de 500 imagens na mesma instância, foi de 0,11 segundos, 176 vezes menor. Ao mesmo tempo, com a necessidade do codificador de encontrar vetores latentes removidos, foi possível executar o modelo em instâncias sem GPU, com tempos de inferência também melhores do que a versão original. Por exemplo, o tempo de inferência em uma CPU somente c5.2xlarge é de 1,5 segundos, até mesmo um t2.medium pode executar o modelo com um tempo de inferência de 7,23 segundos.
Principais conclusões
- O StyleGAN2 gera imagens de alta qualidade, com muitos recursos de transformação. Ele pode ser usado com imagens reais com a ajuda de um codificador, mas provou ser lento e caro.
- No entanto, o StyleGAN2 provou ter potencial suficiente para gerar um conjunto de dados sintético diversificado e de alta qualidade. Esse conjunto de dados pode ser usado para treinar um modelo condicional sem as desvantagens de ter que incorporar um codificador.
- O Pix2pixHD pode ser usado para gerar transformações automáticas em imagens realistas, com um conjunto de dados grande o suficiente. Ele se adapta perfeitamente aos conjuntos de dados gerados pelo StyleGAN.
- APIs externas, como a API Face do Azure, podem ser usadas como validação automática de dados.
Referências
[1] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analisando e melhorando a qualidade da imagem do stylegan. pré-impressão arXiv: 1912.04958 (2019) [2] Wang, Ting-Chun et al. “Síntese de imagens de alta resolução e manipulação semântica com GANs condicionais”. Conferência IEEE/CVF de 2018 sobre visão computacional e reconhecimento de padrões (2018) [3] Viazovetskyi, Yuri, Vladimir Ivashkin e Evgeny Kashin. “Destilação StyleGaN2 para manipulação avançada de imagens.” Notas de aula em Ciência da Computação (2020)



.png)