.png)
Cómo optimizar su modelo con TF-TRT para Jetson Nano




En esta publicación, tomaremos un modelo de Tensorflow 2, lo optimizaremos con NVIDIA TensorRT y lo implementaremos para inferencias en un JetsonNano.
En primer lugar, es necesaria la optimización? Respuesta corta: no. Es posible que hayas llegado a la conclusión de que usar TensorRT (TRT) era obligatorio para ejecutar modelos en el Jetson Nano; sin embargo, este no es el caso si tu modelo sin procesar cabe en la memoria del Jetson podrás ejecutarlo sin ninguna optimización.
¿Por qué decimos esto? Porque optimizar el modelo podría ser demasiada molestia, y si el tiempo de inferencia no es un problema, puedes dejar este paso para más adelante, ya que los cambios de código en el lado de la inferencia son mínimos.
Sin embargo, si estás preparado para un desafío, las ganancias potenciales son muy buenas, hasta Mejora del doble en los FPS, y sobre la mitad del uso de memoria.
1. Contexto
¿Qué es TensorRT?
No vamos a entrar en muchos detalles aquí, ya que es demasiado complejo, pero básicamente TRT es una biblioteca para optimice y ejecute modelos de aprendizaje profundo de alto rendimiento. Su núcleo está escrito en C++ y tiene varias formas de usarse:
- Uso independiente sin ningún marco
- Utilízalo junto con Tensorflow
La primera forma ejecuta el modelo de principio a fin en el tiempo de ejecución de TRT, y es muy diferente (con código de nivel inferior) a lo que estamos acostumbrados con los marcos de aprendizaje profundo modernos, tiene la ventaja de ser potencialmente más rápido y también evita cualquier sobrecarga de Tensorflow (principalmente en lo que respecta al tamaño de la instalación). Con este método, puedes importar modelos de cualquier otro marco, como PyTorch, y convertirlos a TRT (si te interesa Torch, consulta: a rc2trt).
El segundo, es un híbrido entre TRT y Tensorflow (llamado TF-TRT), en el que el protagonista principal es Tensorflow (TF), pero a diferencia de lo habitual, delega la ejecución de algunas operaciones a un componente del tiempo de ejecución de TRT, llamado Motor TRT. Esta opción tiene la ventaja de ser bastante similar al flujo de trabajo normal de TF, con la adición de un paso de optimización entre el entrenamiento y la inferencia.
Además, TF-TRT puede gestionar modelos que contienen operaciones de TRT no compatibles, optimizando únicamente los «segmentos» con operaciones compatibles. Pure TRT no podría ejecutar ese modelo.
En esta publicación, seguiremos el segundo enfoque para los beneficios ya explicados.
¿Cómo funciona?
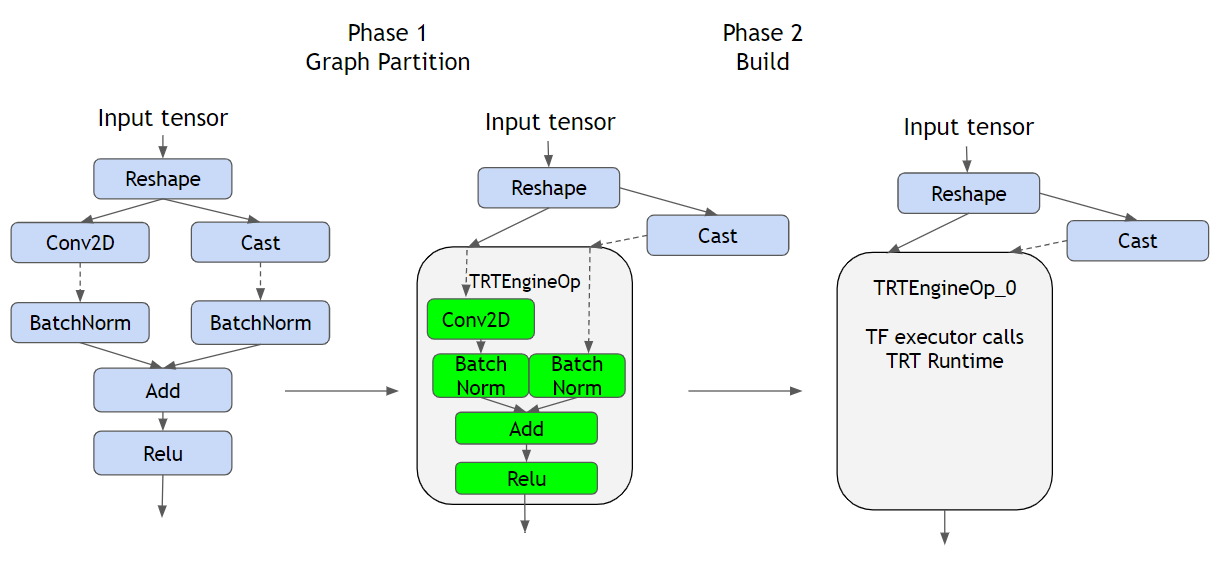
Como puede ver en la figura anterior, a la izquierda vemos un gráfico TF regular que representa las operaciones definidas por el modelo, en el medio tenemos el convertido modelo, y a la derecha tenemos el construido híbrido con Motor TRT.
En primer lugar, el conversión El paso (Fase 1) identifica los segmentos o subgráficos compatibles con TRT para reemplazarlos por TRTEnginesOps. Para entender qué es un TRTEngineOp, primero debemos entender cómo ejecuta TF la inferencia cuando proporcionamos una entrada; los datos siguen el gráfico de la operación, orquestado por TF (muy probablemente en código C++ de la CPU), esto significa que TF recopila las salidas de las operaciones principales y las envía a sus descendientes como entradas.
Si la operación es GPU compatible, como Conv2D, lo más probable es que se cree un Cuda Kernel y la operación la realice la GPU, pero una vez que genere su resultado, TF lo obtendrá y continuará. A Trt Engine OP (que contiene varias operaciones en su interior) es una operación especial proporcionada por el complemento TF-TRT, que se ejecuta como si se tratara de un gráfico TRT nativo. Esto delega la responsabilidad de TF de ejecutar las operaciones de la GPU en el tiempo de ejecución de TRT, lo que permite un control total del gráfico y de la forma en que se ejecutan las operaciones, lo que permite optimizar el hardware de destino. Para ver qué tipo de optimizaciones realiza TRT, consulte https://docs.nvidia.com/deeplearning/tensorrt/best-practices/index.html#enable-fusion.
En segundo lugar, el construir el paso es donde realmente se realizan las optimizaciones, es bastante confuso al principio, pero el solo comprobaciones y marcas en la etapa de conversión las partes del gráfico que son compatibles (y que, a su vez, se optimizarán). Hay algo muy importante a tener en cuenta:
Este paso DEBE ejecutarse en el hardware de destino, porque es específico de la GPU -ya que aprovecha las capacidades específicas de la unidad- esto significa que si tiene la intención de ejecutar una inferencia en el Jetson Nano, debe ejecutar este paso en él.
2. Cómo optimizar
A continuación, encontrarás los pasos necesarios para pasar de un modelo de Tensorflow-Keras a ejecutar una inferencia rápida en tu Jetson Nano.
Los pasos principales son:
- Entrena al modelo
- Guardar
- Optimizar
- Despliegue
- Inferir
A pesar del paso de optimización, este parece el flujo de trabajo habitual para la mayoría de los proyectos de aprendizaje automático. En esta publicación, nos centraremos en los pasos 3, 4 y 5.
Configuración de Jetson
desde __future__ import absolute_import, division, print_function, unicode_literals %env TF_GPU_allocator=cuda_malloc %env protocol_buffers_python_implementation=CPP import os import time import numpy as np import tensorflow como tf desde tensorflow importar keras desde tensorflow.python.saved_model importar tag_constants desde tensorflow.keras.preprocesamiento importar imagen desde google import protobuf print («Tensorflow version: «, tf.version.version) print («Protobuf version:», protobuf. __versión__) print («Versión de TensorRT: «)! dpkg -l | grep nvinfer-bin Versión de Tensorflow: 2.3.1 Versión de Protobuf: 3.8.0 Versión de TensorRT: libnvinfer-bin 7.1.3-1+cuda10.2
DESCARGO DE RESPONSABILIDAD: Lamentablemente, hemos experimentado que el proceso es muy frágil para las versiones de las bibliotecas, por lo que enumeramos las versiones actuales, así que si tienes la posibilidad, intenta instalarlas. En particular, estamos usando JetPack 4.4.1, TF 2.3.1 para lo cual debes sigue esta guía para instalarlo.
%env TF_GPU_ALLOCATOR=CUDA_MALLOC establece un variable de entorno dentro de una celda de Jupyter notebook, si se ejecuta como un script de Python, ejecute antes exportar TF_GPU_ALLOCATOR=CUDA_MALLOC
Gestión de memoria de Jetson
En el Nano, dado que la GPU no tiene memoria propia, comparte la RAM con la CPU, lo que lleva a Problemas de falta de memoria (OOM), tras un proceso de prueba y error, hemos descubierto que establecer un límite de memoria de 2 GB soluciona todos los problemas. Tenga cuidado, si el modelo que está utilizando es más grande, es posible que tenga que jugar con este valor.
gpu_devices = tf.config.experimental.list_physical_devices ('GPU') tf.config.experimental.set_memory_growth (gpu_devices [0], True) tf.config.experimental.set_virtual_device_configuration (gpu_devices [0], [tf.config.experimental.VirtualDeviceConfiguration (memory_limit=2048)] #Crucial valor, establecido por debajo de la memoria de GPU disponible (tenga en cuenta que Jetson comparte la memoria de la GPU con la CPU)
Preparación del modelo
Antes de optimizar nuestro modelo, primero debemos convertirlo al Modelo guardado formato, ya que se requiere en un paso posterior. Estamos usando un ResNet 50 para fines de demostración, aquí utilizaría su ya entrenado modelo.
desde tensorflow.keras.applications.resnet50 importe ResNet50 desde tensorflow.keras.applications.resnet50 importe preprocess_input, decode_predictions model = ResNet50 (weights='imagenet') model.save (f'resnet50_saved_model')
Paso de conversión
Como hablamos anteriormente, en este paso TF-TRT identifica las partes del gráfico que están disponibles para la conversión; en nuestro caso, se reemplaza toda la red.
%env TF_CPP_VModule=segment=2, convert_graph=2, convert_nodes=2, trt_engine=1, trt_logger=2 desde tensorflow.python.compiler.tensorrt importar trt_convert como trt conversion_params = trt.DEFAULT_TRT_CONVERSION_PARAMS conversion_params = conversion_params _parámetros. _replace (max_workspace_size_bytes =( 1<<30)) conversion_params = conversion_params. _replace (precision_mode="fp16") conversion_params = conversion_params. _replace (maximum_cached_engines=10) converter = trt.trtGraphConverterV2 (input_saved_model_dir="resnet50_saved_model», conversion_params=conversion_params) converter.convert ()
En primer lugar, estamos configurando algunos valores muy importantes:
tamaño_de_bytes de espacio de trabajo máximo: Esto le indica a TRT cuánto espacio tiene para optimizar. Su valor es crucial, ya que si es demasiado alto o demasiado bajo, no funcionará. En un paso posterior hablaremos sobre cómo saber si el valor se estableció correctamente.1<<30es igual a 1 GiB.modo de precisión: Esto indica a TRT en qué modo almacenar las variables,FP16significa punto flotante de 16 bits, que no es el modo normal para las operaciones de TF (de forma predeterminada, las operaciones en la GPU se ejecutan con variables FP32). Como lo implica el nombre, FP16 ocupa la mitad de la cantidad de bits por lo que el consumo de memoria se reduce aproximadamente a la mitad, y dado que la cantidad de bits por variable es mucho menor, las operaciones entre variables son mucho más rápidas. Esta es una de las razones (pero no la única) por las que ganamos tanto rendimiento. La FP32 es necesaria durante el entrenamiento para permitir pequeños incrementos de peso, pero tiene un impacto muy pequeño en la precisión durante la inferencia.número máximo de motores en caché: Este valor no es tan crítico como los demás, tiene que ver con una parte de TF-TRT que se explicará más adelante, llamada TRTEngines.
Motores TRT: Como hemos dicho antes, para cada subgrafo compatible con TRT, un Motor TRT se crea. Los motores se crean para cada tamaño de entrada; en la mayoría de los casos, el tamaño de entrada del modelo se fija en un valor determinado (224x224x3 en nuestro caso), pero este no es el caso de todos los modelos. Si el tamaño de entrada de nuestro modelo fuera dinámico, habríamos creado varios motores, uno para cada tamaño. número máximo de motores en caché especifica cuántos podemos tener en caché, si la entrada de su modelo es estática, ignore este valor.
Paso de construcción
Aquí es donde ocurre la magia, donde se hace el procesamiento real. En esta etapa, TRT construye los TRTEngines optimizados para su posterior inferencia. En realidad, esta fase es opcional, ya que si no se hace, se ejecutará automáticamente en la primera inferencia.
batch_size = 2 def input_fn (): # Sustituye por tu tamaño de entrada Inp1 = np.random.normal (size= (batch_size, 224, 224, 3)) .astype (np.float32) yield (Inp1,) converter.build (input_fn=input_fn) converter.save («Resnet50_TF-TRTF Modelo_guardado»)
La función build requiere otra función que rendimientos el tamaño de entrada del modelo, ¿por qué? Como mencionamos antes, para cada tamaño de entrada posible se necesita un nuevo TRTEngine, y esto es lo curioso, el tamaño del lote también forma parte del tamaño de entrada. Lo que esto significa es que si construyes tu modelo con un tamaño del lote de 2, y luego ejecutar la inferencia con un tamaño de 8, cuando el modelo reciba la primera llamada de inferencia, se dará cuenta de que no tiene un motor para este tamaño y lo construirá, lo que llevará mucho tiempo. título; aquí debe poner el mismo tamaño de lote que pretende utilizar en la inferencia, incluso si ese tamaño es 1.
¿Cuáles son los beneficios de ejecutar este paso por adelantado antes de la inferencia? Bueno, como ya habrás experimentado, el Jetson Nano no es tan rápido como una máquina V100..., el paso de construcción de una máquina rápida se ejecuta casi al instante, pero en el Jetson se tarda unos 30 minutos, si no quieres esperar media hora cada vez que comience tu programa, te beneficiarás de esto.
¿Cómo comprobamos si la conversión ha funcionado?
Si tuviste la suerte de completar cada paso sin ningún error, puedes creer que todo ha ido bien y que ahora tienes un modelo increíblemente rápido, bueno, sinceramente, nosotros también lo hicimos, pero desafortunadamente a todo el proceso le gusta fallar silenciosamente.
Entonces, ¿cómo compruebas si realmente funcionó? El siguiente resultado es lo que necesitas NO quiero ver:
tensorflow/core/common_runtime/bfc_allocator.cc:246] Allocator (GPU_0_BFC) se quedó sin memoria al intentar asignar 4,00 GiB con freed_by_count=0. La persona que llama indica que no se trata de un error, pero puede significar que podría haber mejoras de rendimiento si hubiera más memoria disponible. tensorflow/compiler/tf2tensorrt/utils/trt_logger.cc:43] DefaultLogger No se pudo asignar la cantidad de memoria de GPU solicitada (4294967296 bytes). Es posible que no haya suficiente memoria libre para que la asignación se realice correctamente. tensorflow/compiler/tf2tensorrt/utils/trt_logger.cc:43] DefaultLogger /home/jenkins/workspace/tensorrt/helpers/REL-7.1/l1_nightly_internal/build/source/rtsafe/resources.h (181) - Error de memoria insuficiente en GPUMemory: 0 tensorflow/rtsafe/resources.h (181) /compiler/tf2tensorrt/utils/trt_logger.cc:43] DefaultLogger /home/jenkins/workspace/tensorrt/helpers/REL-7.1/l1_nightly_internal/build/source/rtsafe/resources.h (181) - Error de falta de memoria en la memoria de la GPU: 0 tensorflow/compiler/tf2tensorrt/kernels/tr_t_engine_op.cc:757] Advertencia de TF-TRT: No se pudo crear el motor para TRTEngineOP_0_0. En su lugar, se utilizará el segmento nativo. Motivo: interno: no se pudo compilar el motor TensorRT tensorflow/compiler/tf2tensorrt/kernels/trt_engine_op.cc:629] TF-TRT Advertencia: el motor no pudo recuperar las formas de entrada: [[8,224,224,3]]. Al ejecutar el segmento nativo para TRTEngineOP_0_0 Lo que ocurrió aquí es que TRT solicitó más memoria de la que estaba disponible, pidió 4 GB (porque este era el valor de tamaño_de_bytes de espacio de trabajo máximo) y el límite de memoria de TF se estableció en 2 GB, lo que llevó a que no se construyera TRTEngine, recurriendo al modelo no optimizado. Para fijar esto, número máximo de bytes de espacio de trabajo debe ser inferior a límite de memoria y ambos más pequeños que la RAM disponible actualmente.
Por último, ¿cómo ejecutar el modelo?
¡Por fin hemos terminado! ahora podemos ejecutar nuestro modelo en el Nano. A continuación encontrará un script para cargar el modelo y comparar sus fps.
importar tensorflow como tf desde tensorflow.python.saved_model importar signature_constants desde tensorflow.python.saved_model importar tag_constants desde tensorflow.python.framework importar convert_to_constants saved_model_loaded = tf.saved_model.load («RESNET50_TF-TRT_saved_model», tag_model s= [tag_constants.serving]) graph_func = saved_model_loaded.signatures [signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY] frozen_func = convert_to_constants.convert_variables_to_constants_v2 (graph_func) inp = tf.convert_to_tensor (next (input_f_constants_v2 (graph_func) n ()) [0]) # Rendimiento de evaluación comparativa N_ warmup_run = 50 N_run = 1000 elapsed_time = [] para i dentro del rango (N_warmup_run): preds = frozen_func (inp) para i dentro del rango (N_run): start_time = time.time () preds = frozen_func (inp) end_time = time.time () elapsed_time = np.append d (elapsed_time, end_time - start_time) si i% 50 == 0: print ('Step {}: {:4.1f} ms'.format (i, (elapsed_time [-50:] .mean ()) * 1000)) print ('Rendimiento: {:.0f} imágenes/s'.format (N_run * batch_size/ elapsed_time.sum ()))
Nos las arreglamos para conseguir 37 fotogramas por segundo con un Resnet50, que por cierto es el mismo número informado por NVIDIA usando TRT puro.
Referencias:
Al intentar este proceso, encontramos algunos artículos útiles, de los que se recopiló gran parte de la información y las cifras:



.png)