.png)
Como otimizar seu modelo com o TF-TRT para Jetson Nano




Neste post, pegaremos um modelo Tensorflow 2, otimizaremos com o NVIDIA TensorRT e o implantaremos para inferência em um JetsonNano.
Primeiro de tudo, a otimização é necessária? Resposta curta: não. Você pode ter chegado à conclusão de que o uso do TensorRT (TRT) era obrigatório para executar modelos no Jetson Nano; no entanto, esse não é o caso, se seu modelo bruto couber na memória do Jetson você poderá executá-lo sem qualquer otimização.
Por que estamos afirmando isso? Porque otimizar o modelo pode ser muito incômodo, e se o tempo de inferência não for um problema, você pode deixar essa etapa para mais tarde, pois o as alterações de código no lado da inferência são mínimas.
No entanto, se você estiver pronto para um desafio, os ganhos potenciais são muito bons, até Melhoria de duas vezes no FPS, e sobre metade do uso de memória.
1. Contexto
O que é TensorRT?
Não entraremos em muitos detalhes aqui, pois é muito complexo, mas basicamente o TRT é uma biblioteca para otimize e execute modelos de aprendizado profundo de alto desempenho. Seu núcleo é escrito em C ++ e tem várias maneiras de ser usado:
- Uso autônomo sem qualquer estrutura
- Use em conjunto com o Tensorflow
A primeira maneira executa o modelo de ponta a ponta no tempo de execução do TRT, e é muito diferente (com código de nível inferior) do que estamos acostumados com as estruturas modernas de aprendizado profundo, tem a vantagem de ser potencialmente mais rápido e também evita qualquer sobrecarga do Tensorflow (principalmente em relação ao tamanho da instalação). Com esse método, você pode importar modelos de qualquer outra estrutura, como o PyTorch, e convertê-los em TRT (se estiver interessado no Torch, consulte: torc 2 trt).
O segundo, é um híbrido entre TRT e Tensorflow (chamado de TF-TRT), no qual o principal player é o Tensorflow (TF), mas diferente do normal, ele delega a execução de algumas operações a um componente do tempo de execução do TRT, chamado Motor TRT. Essa opção tem a vantagem de ser bastante semelhante ao fluxo de trabalho normal do TF, com a adição de uma etapa de otimização entre treinamento e inferência.
Além disso, o TF-TRT é capaz de lidar com modelos que contêm operações TRT não suportadas, otimizando apenas os “segmentos” com operações suportadas. O TRT puro não seria capaz de executar esse modelo.
Neste post, seguiremos a segunda abordagem para os benefícios já explicados.
Como isso funciona?
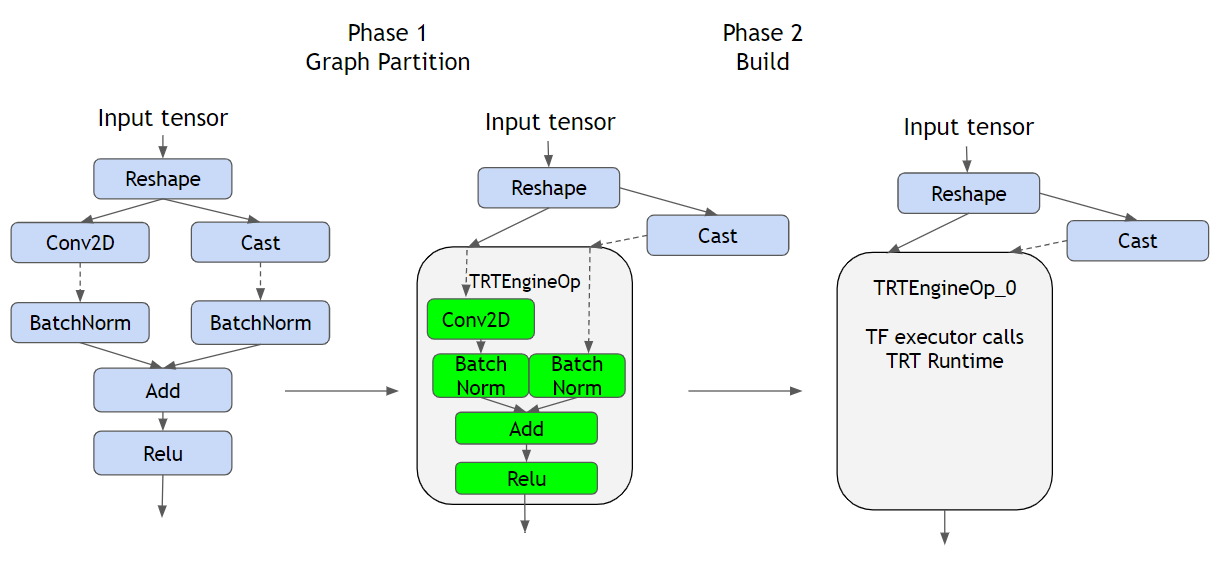
Como você pode ver na figura acima, à esquerda, vemos um gráfico TF regular representando as operações definidas pelo modelo; no meio, temos o convertida modelo, e à direita temos o construída híbrido com o Motor TRT.
Primeiro, o conversão A etapa (Fase 1) identifica segmentos ou subgráficos compatíveis com TRT a serem substituídos por TRTEngineSops. Para entender o que é um TRTEngineop, precisamos primeiro entender como o TF executa a inferência quando fornecemos uma entrada; os dados seguem o gráfico da operação, orquestrado pelo TF (provavelmente no código C ++ na CPU), isso significa que o TF reúne as saídas das operações principais e as envia para seus descendentes como entradas.
Se a operação for GPU compatível, como Conv2D, provavelmente um kernel Cuda será criado e a operação será executada pela GPU, mas depois de gerar o resultado, o TF o obterá e prosseguirá. UM TRT EngineOP (que contém várias operações internas) é uma operação especial fornecida pelo plug-in TF-TRT, que é executada como se fosse um gráfico TRT nativo. Isso delega a responsabilidade do TF de executar as operações da GPU ao tempo de execução do TRT, permitindo o controle total do gráfico e de como as operações são executadas, resultando na capacidade de otimizar o hardware de destino. Para ver quais tipos de otimizações são feitas pelo TRT, consulte https://docs.nvidia.com/deeplearning/tensorrt/best-practices/index.html#enable-fusion.
Em segundo lugar, o construir a etapa é onde as otimizações são realmente feitas, é bastante confuso no início, mas o etapa de conversão somente verifica e marca as partes do gráfico que são suportadas (e que, por sua vez, serão otimizadas). Há uma coisa muito importante a ser observada:
Esta etapa DEVE ser executado no hardware de destino, porque é específico para GPU -uma vez que aproveita as capacidades específicas da unidade- isso significa que, se você pretende executar a inferência no Jetson Nano, precisará executar esta etapa nele.
2. Instruções de otimização
Abaixo, você encontrará as etapas necessárias para passar de um modelo Tensorflow-Keras para executar uma inferência rápida em seu Jetson Nano.
As etapas principais são:
- Treine o modelo
- Salvar
- Otimizar
- Implantar
- Inferir
Apesar da etapa de otimização, esse parece ser o fluxo de trabalho usual para a maioria dos projetos de aprendizado de máquina. Neste post, vamos nos concentrar nas etapas 3, 4 e 5.
Configuração do Jetson
de __future__ import absolute_import, division, print_function, unicode_literals %env tf_gpu_allocator=CUDA_malloc %env Protocol_buffers_python_implementation=Cpp import os import time import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.python.saved_model import tag_constants de tensorflow.keras.preprocessing importa imagem do google import protobuf print (“Versão Tensorflow: “, tf.version.version) print (“Versão Protobuf:”, protobuf. __version__) print (“Versão TensorRT: “)! dpkg -l | grep nvinfer-bin Versão do Tensorflow: 2.3.1 Versão do Protobuf: 3.8.0 Versão do TensorRT: libnvinfer-bin 7.1.3-1+cuda10.2
ISENÇÃO DE RESPONSABILIDADE: Infelizmente, percebemos que o processo é muito frágil para as versões das bibliotecas, então estamos listando as versões atuais; portanto, se você tiver a possibilidade, tente instalá-las. Em particular, estamos usando JetPack 4.4.1, TF 2.3.1 para o qual você deve siga este guia para instalá-lo.
%env TF_GPU_ALLOCATOR=CUDA_malloc define um variável de ambiente dentro de uma célula do notebook Jupyter, se estiver executando isso como um script python, execute antes exportar TF_GPU_ALLOCATOR = CUDA_MALLOC
Gerenciamento de memória da Jetson
No Nano, como a GPU não tem memória própria, ela compartilha a RAM com a CPU, o que leva a Problemas de falta de memória (OOM), descobrimos, após tentativa e erro, que definir um limite de memória de 2 GB resolve todos os problemas. Cuidado, se o modelo que você está usando for maior, talvez seja necessário mexer nesse valor.
gpu_devices = tf.config.experimental.list_physical_devices ('GPU') tf.config.experimental.set_memory_growth (gpu_devices [0], True) tf.config.experimental.set_virtual_device_configuration (gpu_devices [0], [tf.config.experimental.VirtualDeviceConfiguration (memory_limit=20] 48)]) ## Valor crucial, definido abaixo da memória de GPU disponível (observe que a Jetson compartilha a memória da GPU com a CPU)
Preparação do modelo
Antes de otimizarmos nosso modelo, precisamos primeiro convertê-lo em Modelo salvo formato, conforme exigido em uma etapa posterior. Estamos usando um ResNet 50 para fins de demonstração, aqui você usaria seu já treinado modelo.
de tensorflow.keras.applications.resnet50 importe ResNet50 de tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions model = ResNet50 (weights='imagenet') model.save (f'resnet50_saved_model')
Etapa de conversão
Como falamos anteriormente, nesta etapa, o TF-TRT identifica partes do gráfico que estão disponíveis para conversão; no nosso caso, toda a rede é substituída.
%env TF_cpp_vmodule=segment=2, convert_graph=2, convert_nodes=2, trt_engine=1, trt_logger=2 de tensorflow.python.compiler.tensorrt importe trt_convert como trt conversion_params = trt.default_trt_conversion_params conversion_params = parâmetros de conversão. _replace (max_workspace_size_bytes= (1<<30)) conversion_params = conversion_params. _replace (precision_mode="FP16") conversion_params = conversion_params. _replace (maximum_cached_engines=10) converter = trt.trtGraphConverterV2 (input_saved_model_dir="resnet50_saved_model”, conversion_params=conversion_params) converter.convert ()
Primeiro, estamos definindo alguns valores muito importantes:
tamanho máximo do espaço de trabalho: Isso indica ao TRT quanto espaço ele tem para otimizar. Seu valor é crucial, pois se for muito alto ou muito baixo, não funcionará. Em uma etapa posterior, falaremos sobre como saber se o valor foi definido corretamente.1<<30é igual a 1 GiB.modo_de_precisão: Isso indica TRT em qual modo armazenar as variáveis,FP16significa Floating Point de 16 bits, que não é o modo normal para as operações do TF (por padrão, as operações na GPU são executadas com variáveis FP32). Como está implícito no nome, O FP16 ocupa metade da quantidade de bits portanto, o consumo de memória é reduzido pela metade, além disso, como a quantidade de bits por variável é muito menor, as operações entre as variáveis são muito mais rápidas. Esse é um dos motivos (mas não o único) pelo qual obtemos tanto rendimento. O FP32 é necessário durante o treinamento para permitir pequenos incrementos nos pesos, mas tem um impacto muito pequeno na precisão durante a inferência.maximum_cached_engines: Esse valor não é tão crítico quanto os outros, tem a ver com uma parte do TF-TRT que será explicada posteriormente, chamada TRTEngines.
Motores TRT: Como falamos antes, para cada subgráfico compatível com TRT, um Motor TRT é criado. Os motores são criados para cada tamanho de entrada; na maioria dos casos, o tamanho de entrada do modelo é fixado em um determinado valor (224x224x3 no nosso caso), mas esse não é o caso de todos os modelos. Se o tamanho de entrada do nosso modelo fosse dinâmico, teríamos vários motores criados, um para cada tamanho. maximum_cached_engines especifica quantos podemos ter em cache, se a entrada do seu modelo for estática, ignore esse valor.
Etapa de construção
É aqui que a mágica acontece, onde a trituração real é feita. Nesse estágio, o TRT constrói os motores TRT otimizados para inferência posterior. Na verdade, essa fase é opcional, pois, se não for concluída, será executada automaticamente na primeira inferência.
batch_size = 2 def input_fn (): # Substitua pelo seu tamanho de entrada Inp1 = np.random.normal (size= (batch_size, 224, 24, 3)) .astype (np.float32) yield (Inp1,) converter.build (input_fn=input_fn) converter.save (“Resnet50_fn) TF-TRT_Saved_Model”)
A função de construção requer outra função que rendimentos o tamanho da entrada do modelo, por que isso? Como mencionamos anteriormente, para cada tamanho de entrada possível, é necessário um novo motor TRT, e aqui está a coisa engraçada, a tamanho do lote também faz parte do tamanho da entrada. O que isso significa é que se você construir seu modelo com um tamanho do lote de 2 e, em seguida, execute a inferência com um tamanho de 8, quando o modelo receber a primeira chamada de inferência, ele perceberá que não tem um mecanismo para esse tamanho e o construirá, demorando muito tempo. tldr; aqui você deve colocar o mesmo tamanho de lote que pretende usar na inferência, mesmo que esse tamanho seja 1.
Quais são os benefícios de executar essa etapa com antecedência antes da inferência? Bem, como você já deve ter experimentado, o Jetson Nano não é tão rápido quanto uma máquina V100..., a etapa de construção em uma máquina rápida é executada quase instantaneamente, mas no Jetson leva cerca de 30 minutos, se você não quiser esperar meia hora toda vez que o programa começar, você se beneficiará disso.
Como verificamos se a conversão funcionou?
Se você teve a sorte de concluir todas as etapas sem erros, pode acreditar que tudo correu bem e que agora você tem um modelo extremamente rápido, bem, com toda a honestidade, nós também fizemos, mas infelizmente todo o processo gosta de falhar silenciosamente.
Então, como você verifica se realmente funcionou? A saída a seguir é o que você NÃO quero ver:
tensorflow/core/common_runtime/bfc_allocator.cc:246] O alocador (GPU_0_BFC) ficou sem memória tentando alocar 4,00 GiB com freed_by_count=0. O chamador indica que isso não é uma falha, mas pode significar que poderia haver ganhos de desempenho se mais memória estivesse disponível. tensorflow/compiler/tf2tensorrt/utils/trt_logger.cc:43] DefaultLogger A quantidade solicitada de memória da GPU (4294967296 bytes) não pôde ser alocada. Pode não haver memória livre suficiente para que a alocação seja bem-sucedida. tensorflow/compiler/tf2tensorrt/utils/trt_logger.cc:43] defaultLogger /home/jenkins/workspace/tensorrt/helpers/rel-7.1/L1_nightly_internal/build/source/rtsafe/resources.h (181) - Erro de falta de memória em GPUMemory: 0 tensorflow/compiler/tf2tensorrt/utils/trt_logger.cc:43] DefaultLogger /home/jenkins/workspace/tensorrt/helpers/rel-7.1/L1_nightly_internal/build/source/rtsafe/resources.h (181) - Erro de falta de memória na memória GPU: 0 tensor sorflow/compiler/tf2tensorrt/kernels/trt_engine_op.cc: 757] Aviso TF-TRT: A criação do mecanismo para TRTEngineop_0_0 falhou. Em vez disso, o segmento nativo será usado. Motivo: Interno: Falha ao construir o motor Tensorflow/compiler/tf2tensorrt/kernels/trt_engine_op.cc:629] Aviso TF-TRT: Falha na recuperação do mecanismo para formatos de entrada: [[8,224,224,3]]. Executando o segmento nativo para TRTEngineop_0_0 O que aconteceu aqui é que O TRT pediu mais memória do que a disponível, pediu 4 GB (porque esse era o valor de tamanho máximo do espaço de trabalho) e o limite de memória do TF foi definido para 2 GB, o que fez com que nenhum motor TRT fosse construído, voltando ao modelo não otimizado. Para fixar isso, máximo de bytes de espaço de trabalho deve ser menor que limite_de_memória e ambos menores do que sua RAM disponível atualmente.
Finalmente, como executar o modelo?
Finalmente terminamos! agora podemos executar nosso modelo no Nano. Abaixo, você encontrará um script para carregar o modelo e comparar seu fps.
importe tensorflow como tf de tensorflow.python.saved_model importe signature_constants de tensorflow.python.saved_model importe tag_constants de tensorflow.python.framework import convert_to_constants saved_model_loaded = tf.saved_model.load (“Resnet50_TF-TRT_saved_model”, tags= [Tag_constants.serving]) graph_func = saved_model_loaded.signatures [signature_constants.default_serving_signature_def_key] frozen_func = convert_to_constants.convert_variables_to_constants_v2 (graph_func) inp = tf.convert_to_to_constants_v2 (graph_func) inp = tf.convert_to_to_tensor (next (input_fn ()) [0]) # Taxa de transferência de benchmarking N_ warmup_run = 50 N_run = 1000 tempo decorrido = [] para i no intervalo (N_warmup_run): preds = frozen_func (inp) para i no intervalo (N_run): start_time = time.time () preds = frozen_func (inp) end_time = time.time () elapsed_time = np.anexar (tempo decorrido, horário_final - horário_início) se i% 50 == 0: print ('Step {}: {:4.1f} ms'.format (i, (elapsed_time [-50:] .mean ()) * 1000)) print ('Taxa de transferência: {:.0f} images/s'.format (N_run * batch_size/tempo_decorrido.sum ()))
Conseguimos obter 37 quadros por segundo com um Resnet50, que por sinal é o mesmo número relatado pela NVIDIA usando TRT puro.
Referências:
Ao tentar esse processo, encontramos alguns artigos úteis, dos quais muitas das informações e números foram coletados:



.png)