.png)
Puesta a punto de los LLM: mejora eficiente de las descripciones de los productos




Continuando con nuestra serie de blogs sobre modelos lingüísticos grandes (LLM) de hoy, hablaremos sobre un caso exitoso de ajuste fino. Si bien un mensaje bien diseñado puede funcionar en muchos escenarios, hay ocasiones en las que puede que no sea suficiente. La optimización interviene cuando necesitamos resultados de mayor calidad en comparación con el uso exclusivo de indicaciones. También nos permite entrenar el modelo a partir de un conjunto más amplio de ejemplos, superando los límites de los enfoques basados en indicaciones. En este blog exploraremos una aplicación de perfeccionamiento de la maestría para generar descripciones de productos de comercio electrónico.
El caso de uso
Las plataformas de comercio electrónico pueden gestionar miles de productos nuevos a la venta todos los días. Redactar descripciones de productos atractivas desde el punto de vista comercial no es una tarea fácil. Sin embargo, los modelos lingüísticos extensos pueden ayudar a elaborar descripciones atractivas adaptadas a un público objetivo específico. Mediante una ingeniería rápida Chat Llama V2 13B hemos desarrollado un proceso para generar descripciones basadas en la lista de atributos de un producto y su descripción original (a menudo poco atractiva).

La canalización que desarrollamos incluye dos inferencias consecutivas con el modelo, que combinan varias instrucciones para cumplir con la calidad y el formato esperados para los resultados. Los resultados cumplieron con los requisitos de calidad que esperábamos. Sin embargo, dos inferencias hicieron que el tiempo de generación se duplicara, lo que redujo el rendimiento de la generación y aumentó los costos.
Por qué finetune
La decisión de emprender el ajuste surgió de un objetivo importante: aumentar el rendimiento del modelo y, al mismo tiempo, reducir los costos de inferencia. El objetivo principal era simplificar el proceso y lograr los resultados deseados con una única inferencia en un modelo más compacto. El ajuste fino, en este contexto, se convirtió en el enfoque para mejorar el equilibrio entre el rendimiento y la utilización de los recursos, lo que resultó en una solución más eficiente y rentable.
Creación del conjunto de datos
Creamos un conjunto de datos diverso de 1000 descripciones generadas junto con sus productos de origen, atributos y descripciones originales. Los productos se eligieron para cubrir una amplia gama de categorías y longitudes de descripciones originales. Se generaron nuevas descripciones con el proceso Llama V2 13B, que implicaron dos inferencias consecutivas del modelo.
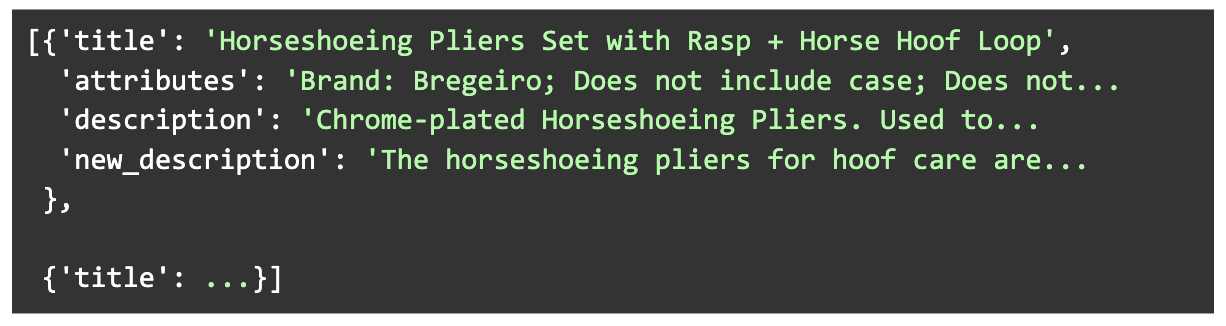
Además, para cumplir con la disponibilidad de la memoria del hardware, filtramos aún más el conjunto de datos para que la cantidad total de tokens de la entrada y la salida de los ejemplos no superara un límite determinado.
Configuración
Para la formación que utilizamos Ludwig que es una interfaz Python de alto nivel para crear modelos de IA. Permite el entrenamiento de modelos de lenguaje extensos simplemente proporcionando un archivo de configuración y obteniendo los datos de entrenamiento en el formato correcto (mientras se utilizan Pytorch y HuggingFace de forma automática). El modelo que elegimos para afinar fue Chat Llama V2 7B. Usamos la versión de cuantificación de 4 bits del modelo y realizamos un ajuste eficiente de los parámetros LORA (adaptación de rango bajo). LORA es una técnica de ajuste fino en la que, en lugar de entrenar todos los parámetros del modelo, se inyectan capas de bajo rango y solo se entrenan estas capas. En nuestro caso, esto significa un tamaño de entrenamiento de solo el 0,06% del modelo completo. Combinar la cuantificación de 4 bits con LORA para el entrenamiento (ÁLORA) es un enfoque muy eficiente en cuanto a la memoria que no sacrifica el rendimiento de las tareas.
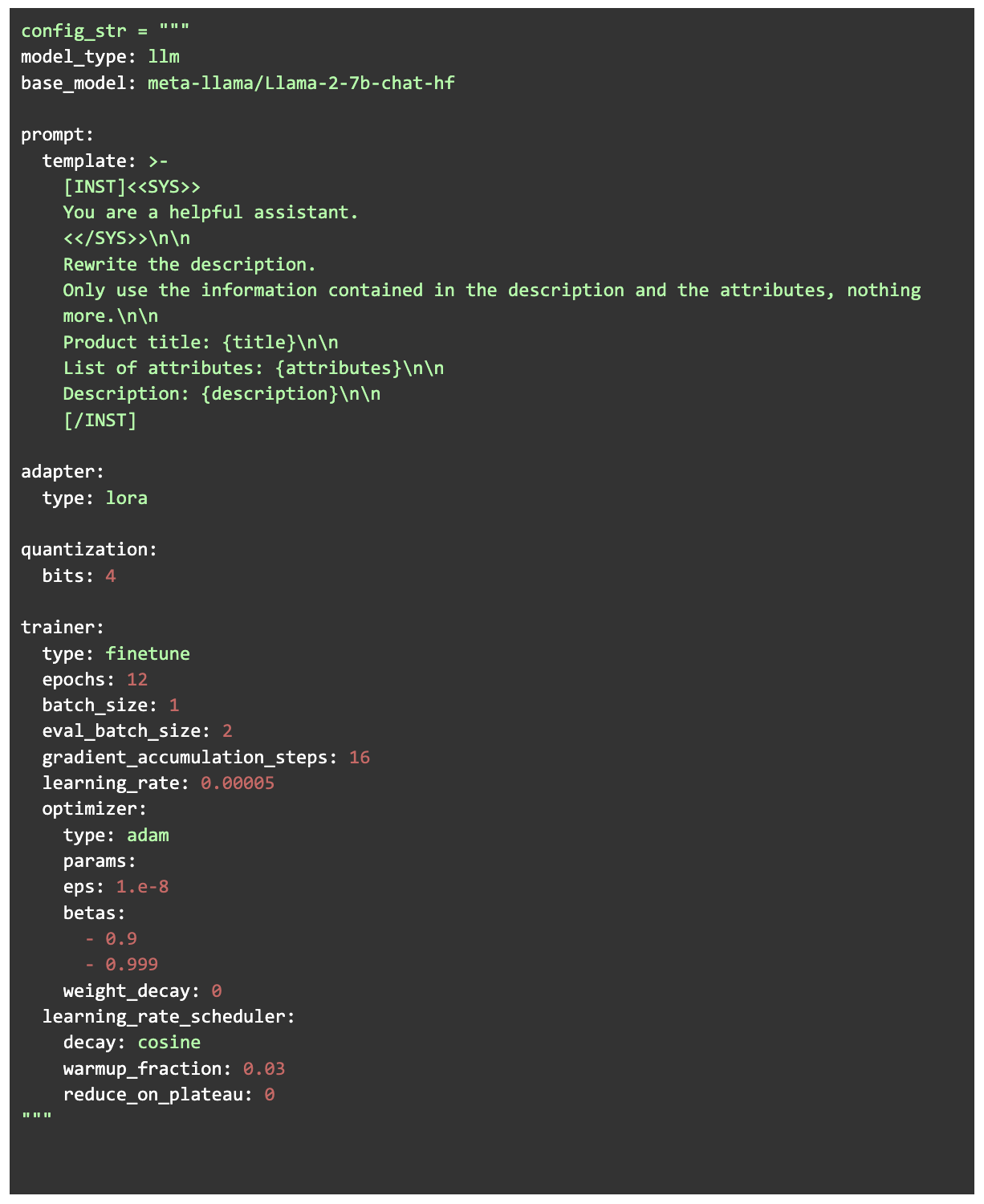
Proceso formativo
El entrenamiento se realizó durante 12 épocas en una GPU A100 con 40 GB de RAM, con un tiempo total de entrenamiento de aproximadamente 3 horas. Una de las primeras cosas que el modelo aprendió fue replicar el estilo de la salida, respondiendo en párrafos con la longitud esperada. Sin embargo, el modelo sufrió algunos «vicios» en las primeras épocas, que fueron superados a medida que avanzaba la formación.

Como nota curiosa, en la época 5, el modelo seguía sistemáticamente un estilo de respuesta particular, comenzando la descripción con una frase de producto creada de forma creativa que comenzaba con «Nadie». Algunos LLMs muestran un sabor particularmente creativo en sus respuestas, y Llama V2 Chat es sin duda uno de ellos. (Estamos planificando una futura entrada en el blog con una recopilación de las divertidas respuestas de LLM que hemos ido encontrando, ¡estad atentos!)
Resultados y evaluación humana
¡Quedamos muy contentos con los resultados! El modelo afinado (Llama V2 7B, cuantificado en 4 bits) tiene aproximadamente un 25% del tamaño del modelo original que utilizamos para generar las salidas reales (Llama V2 13B, cuantificado en 8 bits). Sin embargo, las nuevas salidas tienen una calidad muy similar y, en algunos casos, incluso mejores que las originales.

Para cuantificar la comparación de los resultados de los dos modelos, realizamos una evaluación humana. Presentamos a los compañeros de equipo que habían trabajado en proyectos relacionados con un dominio las respuestas de los dos modelos, mezcladas y seleccionadas al azar para que eligieran la que preferían (o «empatar»). Estos fueron los resultados.
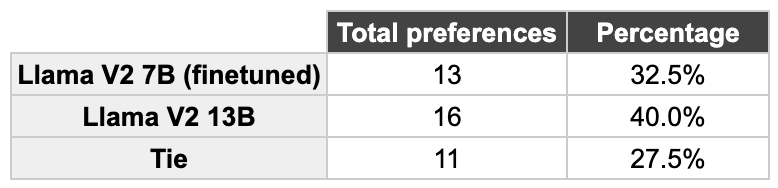
En el 60% de los ejemplos hubo un empate o se prefirió la respuesta Llama 7B. Además, solo hay una diferencia del 7,5% entre la preferencia del Llama 13B y la del Llama 7B. ¡Son resultados muy ajustados para un modelo cuatro veces más pequeño que el original!
Objetivo cumplido
Al generar la descripción en una sola inferencia con un modelo más pequeño, en comparación con las dos inferencias requeridas con el modelo más grande original, logramos una ganancia de rendimiento 4 veces mayor. Además, la reducción del 75% en la memoria de inferencia total permite optimizar la infraestructura necesaria para alojar el modelo y utilizar máquinas virtuales más pequeñas (y, por lo tanto, más baratas). Estas optimizaciones se lograron sin sacrificar la alta calidad de los resultados y, por lo tanto, permitieron reducir más del 80% del costo de cada descripción generada. Quedamos muy satisfechos con el resultado.
Conclusión
Nuestra investigación sobre el perfeccionamiento de los modelos lingüísticos extensos (LLM) reveló una aplicación prometedora para generar descripciones de productos de comercio electrónico. Al crear cuidadosamente un conjunto de datos de alta calidad, el ajuste puede aumentar el rendimiento de los resultados más allá de las posibilidades que ofrecen las indicaciones. Al ajustar estratégicamente el modelo de chat Llama V2 7B, se logró un equilibrio notable entre el rendimiento y el uso de los recursos. Al implementar QLORA en una versión de modelo cuantificado de 4 bits, optimizamos significativamente la utilización de la memoria y la eficiencia computacional. Este enfoque no solo redujo sustancialmente los costos de inferencia, sino que también mantuvo la alta calidad de los resultados generados, lo que demuestra que ajustar los LLM puede ser una herramienta inestimable para transferir conocimientos de modelos más grandes y complejos a otros más pequeños, lo que optimiza en gran medida la utilización de los recursos.



.png)