.png)
Ajustando LLMs: aprimorando as descrições de produtos com eficiência




Continuando com nossa série de blogs sobre Grandes Modelos de Linguagem (LLMs), hoje falaremos sobre um caso de ajuste fino bem-sucedido. Embora um prompt bem elaborado possa realizar o trabalho em muitos cenários, há momentos em que pode não ser suficiente. O ajuste fino ocorre quando precisamos de resultados de maior qualidade em comparação com o uso exclusivo de prompts. Também nos permite treinar o modelo em um conjunto mais extenso de exemplos, ultrapassando os limites das abordagens baseadas em prompts. Neste blog, exploraremos um aplicativo de ajuste fino do LLM para gerar descrições de produtos de comércio eletrônico.
O caso de uso
As plataformas de comércio eletrônico podem lidar com milhares de novos produtos à venda todos os dias. Escrever descrições de produtos comercialmente atraentes não é uma tarefa fácil. No entanto, grandes modelos de linguagem podem ajudar na criação de descrições atraentes adaptadas a um público-alvo específico. Por meio de engenharia imediata Bate-papo do Llama V2 13B desenvolvemos um pipeline para gerar descrições com base em uma lista de atributos do produto e sua descrição original (geralmente pouco atraente).

O pipeline que desenvolvemos inclui duas inferências consecutivas com o modelo, combinando várias instruções para atender à qualidade e ao formato esperados para as saídas. Os resultados atenderam aos requisitos de qualidade que esperávamos. No entanto, duas inferências significaram que o tempo de geração dobrou, reduzindo o rendimento da geração e aumentando os custos.
Por que ajustar
A decisão de iniciar o ajuste fino resultou de um objetivo importante: aumentar a produtividade do modelo e, ao mesmo tempo, reduzir os custos de inferência. O objetivo principal era agilizar o processo, alcançando os resultados desejados com uma única inferência em um modelo mais compacto. O ajuste fino, nesse contexto, tornou-se a abordagem para melhorar o equilíbrio entre desempenho e utilização de recursos, resultando em uma solução mais eficiente e econômica.
Construindo o conjunto de dados
Construímos um conjunto de dados diversificado de 1000 descrições geradas junto com seus atributos de produtos de origem e descrições originais. Os produtos foram escolhidos para abranger uma ampla variedade de categorias e comprimentos de descrições originais. Novas descrições foram geradas com o pipeline Llama V2 13B, envolvendo duas inferências consecutivas para o modelo.
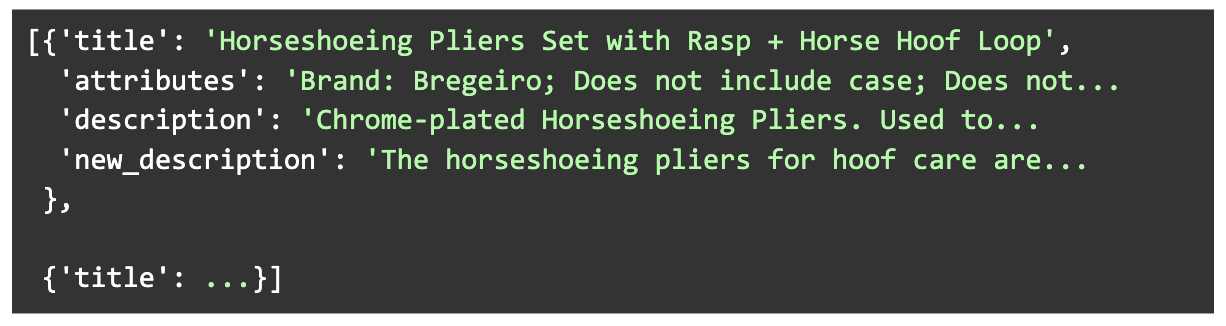
Além disso, para atender à disponibilidade de memória de hardware, filtramos ainda mais o conjunto de dados para que o número total de tokens da entrada + saída dos exemplos não excedesse um determinado limite.
Configuração
Para o treinamento que usamos Ludwig que é uma interface Python de alto nível para criar modelos de IA. Ele permite o treinamento de modelos de linguagem grande fornecendo apenas um arquivo de configuração e obtendo os dados de treinamento no formato correto (enquanto usa Pytorch e HuggingFace nos bastidores). O modelo que escolhemos para ajustar foi Bate-papo do Llama V2 7B. Usamos a versão de quantização de 4 bits do modelo e realizamos um ajuste fino eficiente dos parâmetros LORA (Low Rank Adaptation). O LORA é uma técnica de ajuste fino em que, em vez de treinar todos os parâmetros do modelo, camadas de baixa classificação são injetadas e somente essas camadas são treinadas. No nosso caso, isso significa um tamanho de treinamento de apenas 0,06% do modelo completo. Combinando a quantização de 4 bits com o LORA para treinamento (QLORA) é uma abordagem altamente eficiente em termos de memória que não sacrifica o desempenho da tarefa.
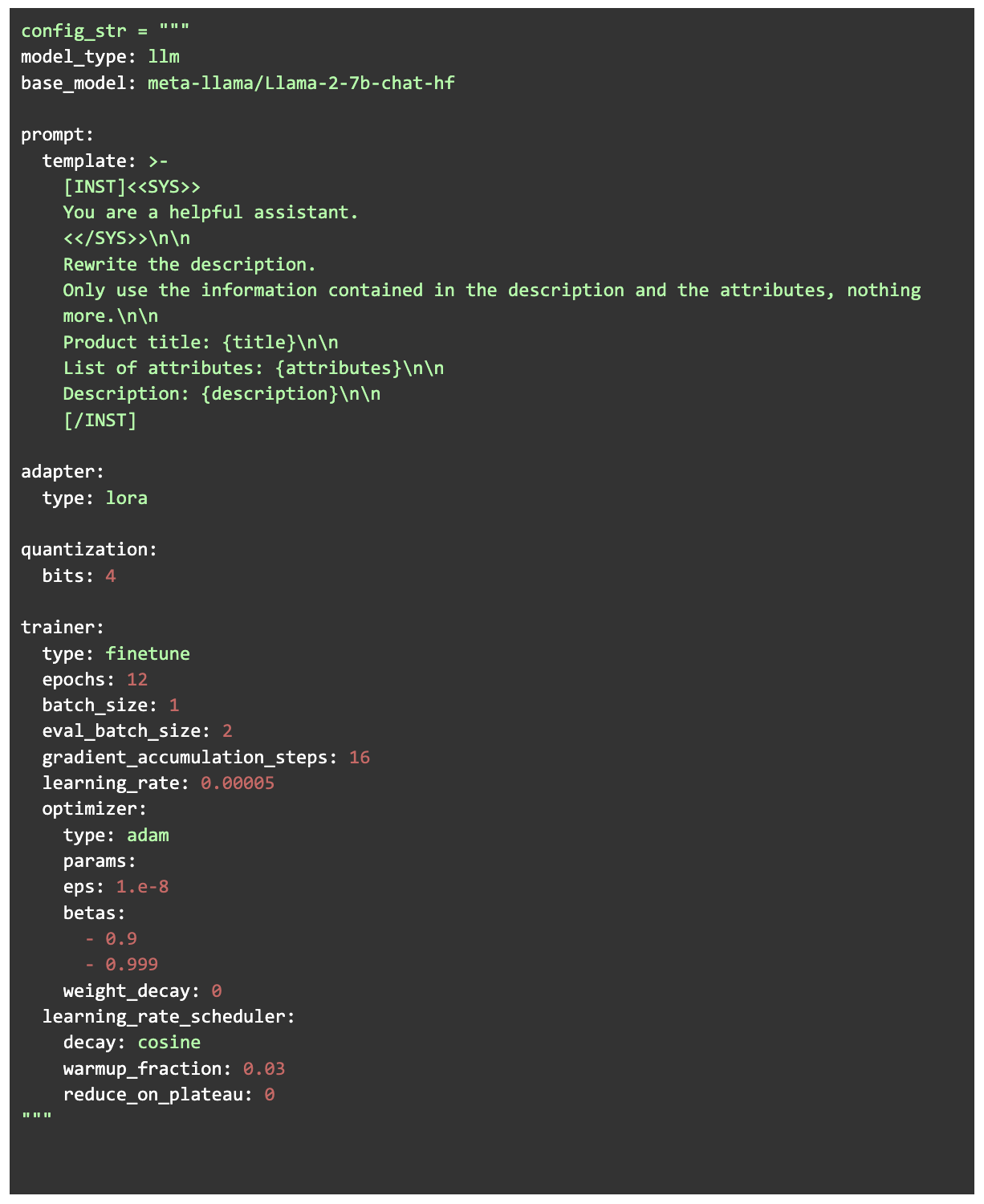
Processo de treinamento
O treinamento foi feito por 12 épocas em uma GPU A100 com 40 GB de RAM, com um tempo total de treinamento de cerca de 3 horas. Uma das coisas que o modelo aprendeu primeiro foi replicar o estilo da saída, respondendo em parágrafos do tamanho esperado. No entanto, o modelo passou por alguns 'vícios' nas primeiras épocas, que foram superados à medida que o treinamento avançava.

Como uma nota engraçada, na época 5, o modelo estava seguindo sistematicamente um estilo de resposta específico, iniciando a descrição com uma frase de produto criada de forma criativa começando com “Ninguém”. Alguns LLMs mostram um sabor particularmente criativo em suas respostas, sendo o Llama V2 Chat definitivamente um deles. (Estamos planejando uma futura postagem no blog com uma compilação de respostas engraçadas de LLM que estamos recebendo — fique ligado!)
Resultados e avaliação humana
Ficamos muito felizes com os resultados! O modelo ajustado (Llama V2 7B, quantizado em 4 bits) tem cerca de 25% do tamanho do modelo original que usamos para gerar as saídas reais (Llama V2 13B, quantizado em 8 bits). No entanto, as novas saídas são muito semelhantes em qualidade e, em alguns casos, até melhores que as originais.

Para quantificar a comparação dos resultados dos dois modelos, realizamos uma avaliação humana. Apresentamos aos colegas de equipe que trabalharam em projetos relacionados ao domínio respostas embaralhadas e escolhidas aleatoriamente dos dois modelos para escolher o preferido (ou “empate”). Esses foram os resultados.
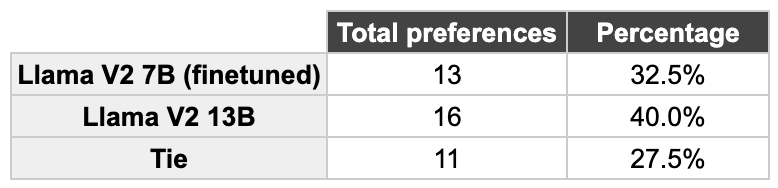
Em 60% dos exemplos houve empate ou a resposta do Llama 7B foi preferida. Além disso, há apenas uma diferença de 7,5% entre a preferência do Llama 13B em comparação com o Llama 7B. Esses são resultados muito precisos, para um modelo quatro vezes menor que o original!
Objetivo cumprido
Ao fazer a geração da descrição em uma única inferência com um modelo menor, em comparação com as duas inferências exigidas com o modelo maior original, obtivemos um ganho de taxa de transferência de 4 vezes. Além disso, a redução de 75% na memória total de inferência permite otimizar a infraestrutura necessária para hospedar o modelo e utilizar máquinas virtuais menores (e, portanto, mais baratas). Essas otimizações foram alcançadas de forma que a alta qualidade de saída não seja sacrificada e, assim, permita uma redução de mais de 80% do custo de cada descrição gerada. Ficamos muito satisfeitos com o resultado.
Conclusão
Nossa exploração sobre o ajuste fino de modelos de linguagem grande (LLMs) revelou uma aplicação promissora na geração de descrições de produtos de comércio eletrônico. Ao criar cuidadosamente um conjunto de dados de alta qualidade, o ajuste fino pode elevar o desempenho dos resultados além das capacidades apenas dos prompts. O ajuste estratégico do modelo Llama V2 7B Chat alcançou um equilíbrio notável entre desempenho e uso de recursos. Ao implementar o QLORA em uma versão de modelo quantizado de 4 bits, otimizamos significativamente a utilização da memória e a eficiência computacional. Essa abordagem não apenas reduziu substancialmente os custos de inferência, mas também manteve a alta qualidade dos resultados gerados, mostrando que o ajuste fino dos LLMs pode ser uma ferramenta inestimável para transferir conhecimento de modelos maiores e mais complexos para modelos menores, otimizando consideravelmente a utilização de recursos.



.png)