
Explorando el OSS de Unity Catalog: redefiniendo la interoperabilidad




En el mundo de TI actual, abundan las herramientas, las plataformas, los marcos y mucho más. Parece que hay al menos una solución para satisfacer cada necesidad. Por eso, cuando algo promete ser «universal», suena muy prometedor. Unity Catalog se define a sí mismo como catálogo de datos universal. Analicemos las características clave que respaldan esta afirmación.
Presentamos Unity Catalog OSS: descripción general de la gobernanza de datos
Unity Catalog organiza los datos en un espacio de nombres de tres niveles: Catálogo → Esquema → Activo de datos.
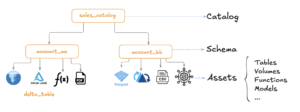
Crédito de imagen Catálogo Unity 101
- Catálogos son la unidad de nivel superior y, por lo general, representan unidades de negocio o categorías amplias.
- Esquemas agrupe los datos y los activos de IA en categorías lógicas, a menudo para proyectos o casos de uso específicos (que no deben confundirse con los esquemas de tablas).
- Activos de datos incluyen varios objetos como tablas, volúmenes, modelos y funciones para su procesamiento y análisis.
Unity Catalog es multimodal, lo que significa que admite múltiples formatos, motores y activos de datos.
- Soporte para múltiples formatos: CSV, JSON, Delta, Iceberg, entre muchos otros.
- Soporte para varios motores: La premisa es permitir el uso de Unity Catalog desde cualquier motor de procesamiento.
- Multimodal: No solo centraliza las tablas, sino que también integra modelos, conjuntos de datos y funciones de ML.
Formatos puente: cómo Unity Catalog OSS conecta Delta Lake y Apache Iceberg
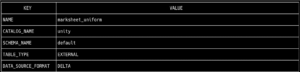
Los formatos más populares en una arquitectura de almacenamiento de datos son actualmente Delta e Iceberg. Una de las principales ventajas de Unity Catalog es la capacidad de usar ambos formatos y aprovechar las ventajas de cada uno de ellos, al mismo tiempo que se evitan los problemas de compatibilidad. La base del soporte multiformato es UniForm. Este formato de tabla permite que cada tabla incluya metadatos en los formatos Delta e Iceberg, lo que permite leerlos con cualquiera de los dos conectores. En primer lugar, verificamos que la tabla esté en Formato Delta ejecutando el comando para recuperar los metadatos de la tabla: tabla bin/uc get --full_name unity.default.marksheet_uniform
Ahora, leeremos la tabla usando Apache Spark, pero esta vez apuntando al catálogo de datos a través del Configuración de Iceberg, lo que permitirá que se lea sin problemas. desde pyspark.sql import SparkSession spark = SparkSession.Builder\ .AppName («Iceberg with Unity Catalog»)\ .config («spark.jars.packages», «org.apache.iceberg:iceberg-spark-runtime-3.4_2. 12:1.3 .1")\ .config («spark.sql.extensions», «org.apache.iceicetime-3.4_2. 12:1.3 .1")\ .config («spark.sql.extensions», «org.apache.iceicetime-3.4_2. 12:1.3 .1")\ .config («spark.sql.extensions», «org.apache.iceicetime-3.4_2. 12:1.3 .1")\ .config («spark.sql.extensions», «org.apache.iceiceiceberg.spark.extensions.IcebergSparkSessionExtensions»)\ .config («spark.sql.catalog.iceberg», «org.apache.iceberg.spark.spark.SparkCatalog»)\ .config («spark.sql.catalog.iceberg.catalog-impl», «org.apache.iceberg.rest.restCatalog»)\ .config («spark.sql.catalog.iceberg.uri»,» http://127.0.0.1:8080/api/2.1/unity-catalog/iceberg «)\ .config («spark.sql.catalog.iceberg.warehouse», «unity»)\ .config («spark.sql.catalog.iceberg.token», «not_used»)\ .getOrCreate () spark.sql («seleccione * de unity.default.marksheet_uniform») .show ()

Potenciar las canalizaciones de aprendizaje automático: administración de modelos con Unity Catalog OSS
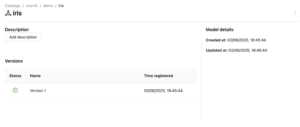
Uno de los mayores desafíos para los catálogos de datos es integrar realmente todos los activos dentro de una organización. Catálogo de Unity se destaca al permitir Modelos ML registrarse como objetos de catálogo, un componente fundamental para cualquier organización basada en datos. Una vez que se hayan registrado todas las tablas, fuentes de datos y archivos, agregue modelos y sus versiones se convierte en una tarea sencilla en Catálogo de Unity. Usando el MLFlow biblioteca, podemos conectarnos al catálogo de datos y registrar la versión del modelo entrenado sin problemas. Para ello, entrenaremos a un Bosque aleatorio modelo y, a modo de prueba, regístralo en nuestro catálogo de datos creado para este propósito. import mlflow mlflow.set_tracking_uri (» http://127.0.0.1:5000 «) mlflow.set_registry_uri («uc: http://127.0.0.1:8080 «) importar sistemas operativos desde sklearn importar conjuntos de datos desde sklearn.ensemble importar RandomForestClassifier desde sklearn.model_selection import train_test_split import pandas como pd X, y = datasets.load_iris (return_x_y=true, as_frame=true) x_train, x_test, y_train, y_test = train_test_split (X, y, test_size=0.2, random_state=42) con mlflow.start_run (): # Entrene un modelo sklearn en el conjunto de datos de iris clf = RandomForestClassifier (max_depth=7) clf. fit (x_train, y_train) # # Tome la primera fila del conjunto de datos de entrenamiento como ejemplo de entrada del modelo. input_example = x_train.ILOC [[0]] # Registra el modelo y regístralo como una nueva versión en UC. mlflow.sklearn.log_model (sk_model=clf, artifact_path="model», # La firma se deduce automáticamente del ejemplo de entrada # y su salida prevista. input_example=input_example, registered_model_name="marvik.demo.iris»,) Al navegar por el UI de Unity Catalog, encontraremos el modelo registrado con su versión correspondiente y estado activo, indicando que está en uso actualmente:
Desafíos del OSS: limitaciones en comparación con la versión empresarial de Databricks
- Evitar que los lagos de datos o los lagos se conviertan en pantanos de datos es esencial, por lo que el linaje y un diccionario de datos son tan importantes para una gobernanza eficaz. Si bien la versión de código abierto de Unity Catalog aún no ofrece el rastreo de objetos, esta funcionalidad está en la hoja de ruta y se alinea con las mejores prácticas para mantener un entorno de datos bien gobernado.
- Lake Federation, una función que simplifica la inclusión de fuentes externas, como bases de datos de diferentes proveedores de nube o incluso catálogos de Snowflake, también está prevista para futuras versiones de la versión de código abierto. Esto agilizará aún más la catalogación y la gobernanza en diversos ecosistemas de datos.
- En cuanto a la gobernanza de datos, la versión actual de código abierto ya admite la creación de usuarios para acceder a Unity Catalog, y las actualizaciones futuras ampliarán los permisos a nivel de objeto, el acceso a nivel de fila y otros controles granulares. Estas incorporaciones ayudarán a fortalecer la gobernanza y la seguridad generales de la plataforma.
- Si bien la barra de búsqueda global no está disponible actualmente en la versión de código abierto, los usuarios aún pueden buscar dentro de categorías específicas, como catálogos, esquemas y tablas. Se está desarrollando una experiencia de búsqueda mejorada para mejorar la navegación en grandes lagos de datos, y se planean mejoras adicionales en la interfaz de usuario para acercar la experiencia de código abierto a la versión empresarial.
Conclusiones
Es cierto que Catálogo de Unity cumple su promesa de ser universal—se puede usar en varios motores, admite varios formatos de datos y organiza todos los activos de la organización, incluidos tablas, archivos, funciones e incluso modelos ML. Sin embargo, el versión de código abierto aún está lejos de estar listo para la producción. Sigue siendo un concepto prometedor en desarrollo, actualmente en la versión 0,2. Según el hoja de ruta oficial, versión 0,5 puede introducir funciones clave que faltan en comparación con Implementación de Databricks, como Federación de Lagos y Linaje de datos



.png)