
Explorando o Unity Catalog OSS: redefinindo a interoperabilidade




No mundo atual da TI, ferramentas, plataformas, estruturas e muito mais são abundantes. Parece que há pelo menos uma solução para atender a cada necessidade. É por isso que, quando algo promete ser “universal”, parece muito promissor. O Unity Catalog se define como o catálogo de dados universal. Vamos analisar os principais recursos que sustentam essa afirmação.
Revelando o Unity Catalog OSS: uma visão geral da governança de dados
O Unity Catalog organiza os dados em um namespace de três níveis: Catálogo → Esquema → Ativo de dados.
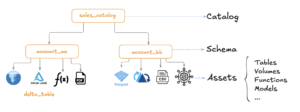
Crédito da imagem Catálogo Unity 101
- Catálogos são a unidade de nível superior, normalmente representando unidades de negócios ou categorias amplas.
- Esquemas agrupe dados e ativos de IA em categorias lógicas, geralmente para projetos ou casos de uso específicos (não confunda com esquemas de tabela).
- Ativos de dados incluem vários objetos, como tabelas, volumes, modelos e funções para processamento e análise.
O Unity Catalog é multimodais, o que significa que ele suporta vários formatos, mecanismos e ativos de dados.
- Suporte para vários formatos: CSV, JSON, Delta, Iceberg, entre muitos outros.
- Suporte para vários mecanismos: A premissa é permitir o uso do Unity Catalog a partir de qualquer mecanismo de processamento.
- Multimodal: Ele não apenas centraliza tabelas, mas também integra modelos, conjuntos de dados e funções de ML.
Formatos de ponte: como o Unity Catalog OSS conecta o Delta Lake e o Apache Iceberg
Atualmente, os formatos mais populares em uma arquitetura de data lakehouse são Delta e Iceberg. Uma grande vantagem do Unity Catalog é a capacidade de usar os dois formatos e aproveitar os benefícios de cada um, evitando problemas de compatibilidade. A espinha dorsal do suporte multiformato é o UniForm. Esse formato de tabela permite que cada tabela inclua metadados nos formatos Delta e Iceberg, permitindo que sejam lidos por qualquer um dos dois conectores. Primeiro, verificamos se a tabela está em Formato Delta executando o comando para recuperar os metadados da tabela: tabela bin/uc get --full_name unity.default.marksheet_uniform
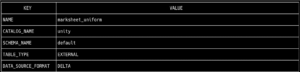
Agora, vamos ler a tabela usando Apache Spark, mas desta vez apontando para o catálogo de dados através do Configuração do iceberg, o que permitirá que ele seja lido sem problemas. de pyspark.sql import SparkSession spark = sparkSession.Builder\ .appName (“Iceberg with Unity Catalog”)\ .config (“spark.jars.packages”, “org.apache.iceberg:iceberg-spark-runtime-3.4_2. 12:1.3 .1")\ .config (“spark.sql.extensions”, “org.apache.iceberg.spark.extensions.icebergSparkSessionExtensions”)\ .config (“spark.sql.catalog.iceberg”, “org.apache.iceberg.sparkcatalog”)\ .config (“spark.sql.catalog.iceberg.catalog-impl”, “org.apache.iceberg.rest.catalog”)\ .config (“spark.sql.catalog.iceberg.uri”,” http://127.0.0.1:8080/api/2.1/unity-catalog/iceberg “)\ .config (“spark.sql.catalog.iceberg.warehouse”, “unidade”)\ .config (“spark.sql.catalog.iceberg.token”, “not_used”)\ .getOrCreate () spark.sql (“selecione * de unity.default.marksheet_uniform”) .show ()

Capacitando canais de aprendizado de máquina: gerenciando modelos com o Unity Catalog OSS
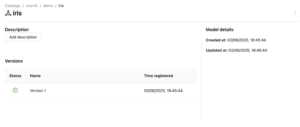
Um dos maiores desafios dos catálogos de dados é realmente integrar todos os ativos dentro de uma organização. Catálogo Unity se destaca por permitir Modelos de ML serem registrados como objetos de catálogo, um componente fundamental para qualquer organização orientada por dados. Depois que todas as tabelas, fontes de dados e arquivos estiverem registrados, adicionando modelos e suas versões se torna uma tarefa simples em Catálogo Unity. Usando o Fluxo de ml biblioteca, podemos nos conectar ao catálogo de dados e registrar a versão do modelo treinado sem problemas. Para fazer isso, treinaremos um Floresta aleatória modele e, como teste, registre-o em nosso catálogo de dados criado para essa finalidade. importe mlflow mlflow.set_tracking_uri (” http://127.0.0.1:5000 “) mlflow.set_registry_uri (“uc: http://127.0.0.1:8080 “) importe os do sklearn importe conjuntos de dados do sklearn.ensemble importe RandomForestClassifier do sklearn.model_selection importe train_test_split importe pandas como pd X, y = datasets.load_iris (Return_x_y=true, as_frame=true) X_train, X_test, y_train, y_test = train_test_split (X, y, test_size=0.2, random_state=42) com mlflow.start_run (): # Treine um modelo sklearn no conjunto de dados da íris clf = RandomForestClassifier (max_depth=7) clf. fit (X_train, y_train) # # Pegue a primeira linha do conjunto de dados de treinamento como exemplo de entrada do modelo. input_example = X_train.iloc [[0]] # Registre o modelo e registre-o como uma nova versão na UC. mlflow.sklearn.log_model (sk_model=clf, artifact_path="model”, # A assinatura é automaticamente inferida da entrada exemplo # e sua saída prevista. input_example=input_example, registered_model_name="marvik.demo.iris”,) Ao navegar pelo UI do catálogo Unity, encontraremos o modelo registrado com sua versão correspondente e status ativo, indicando que está em uso atualmente:
Desafios do OSS: limitações em comparação com a versão corporativa do Databricks
- É essencial evitar que lagos de dados ou casas lacustres se tornem pântanos de dados, e é por isso que a linhagem e um dicionário de dados são tão importantes para uma governança eficaz. Embora a versão de código aberto do Unity Catalog ainda não ofereça rastreamento de objetos, essa funcionalidade está no roteiro, alinhando-se às melhores práticas para manter um ambiente de dados bem governado.
- O Lake Federation, um recurso que simplifica a inclusão de fontes externas, como bancos de dados de diferentes provedores de nuvem ou até mesmo catálogos da Snowflake, também está planejado para futuros lançamentos da versão de código aberto. Isso simplificará ainda mais a catalogação e a governança em diversos ecossistemas de dados.
- Em termos de governança de dados, a versão atual de código aberto já oferece suporte à criação de usuários para acessar o Unity Catalog, e futuras atualizações expandirão as permissões em nível de objeto, acesso em nível de linha e outros controles granulares. Essas adições ajudarão a fortalecer a governança geral e a segurança na plataforma.
- Embora uma barra de pesquisa global não esteja disponível atualmente na versão de código aberto, os usuários ainda podem pesquisar em categorias específicas, como catálogos, esquemas e tabelas. Uma experiência de pesquisa aprimorada está em desenvolvimento para melhorar a navegação em grandes lagos de dados, e melhorias adicionais na interface do usuário estão planejadas para aproximar a experiência de código aberto da versão corporativa.
Conclusões
É verdade que Catálogo Unity cumpre sua promessa de ser universal—ele pode ser usado em vários mecanismos, oferece suporte a vários formatos de dados e organiza todos os ativos organizacionais, incluindo tabelas, arquivos, funções e até modelos de ML. No entanto, o versão de código aberto ainda está longe de estar pronto para a produção. Continua sendo um conceito promissor em desenvolvimento, atualmente na versão 0,2. De acordo com o roteiro oficial, versão 0,5 pode introduzir os principais recursos ausentes em comparação com Implementação do Databricks, como Federação dos Lagos e Linhagem de dados



.png)