.png)
Explorando RetNet: la evolución de los transformadores




Desde 2017, los transformadores han demostrado su superioridad en rendimiento y eficiencia computacional, superando a las redes neuronales recurrentes (RNN). El mecanismo de atención presentado en el artículo «La atención es todo lo que necesitas» y su capacidad para paralelizar el entrenamiento (una hazaña con la que las RNN tradicionales no han tenido éxito) le atribuyen esta superioridad. Sin embargo, los transformadores presentan un desafío: los costos de memoria e inferencia asociados a su arquitectura. En esta entrada del blog exploraremos el modelo RetNet, una iniciativa del equipo de investigación de Microsoft destinada a abordar los desafíos que plantean los transformadores y, al mismo tiempo, lograr un rendimiento competitivo.
Los predecesores: redes neuronales recurrentes y transformadores
El procesamiento secuencial en los RNN limita el entrenamiento paralelo debido a los cálculos lineales. Los RNN procesan cada token de forma secuencial, lo que dificulta la paralelización. Los RNN avanzados, como LSTM y GRU, mantienen un flujo secuencial, lo que impide una paralelización eficiente. Por el contrario, los transformadores introducen un cambio de paradigma al incorporar un mecanismo de autoatención. Este mecanismo, junto con una «máscara causal», garantiza que cada token de una secuencia conozca todos los tokens anteriores. La aplicación del enmascaramiento causal permite el entrenamiento paralelo, ya que cada token puede procesarse simultáneamente, sin perder de vista su contexto histórico. En consecuencia, cada token funciona como un ejemplo de entrenamiento independiente, lo que permite a los Transformers recibir entrenamiento con todos los tokens simultáneamente. En resumen, los Transformers superan las limitaciones de la RNN en el entrenamiento secuencial. Los mecanismos de atención y el enmascaramiento causal hacen que su proceso de entrenamiento sea más eficiente y paralelizable. Sin embargo, el mecanismo de autoatención plantea desafíos en la inferencia y en el uso de la memoria, como se detalla más adelante.
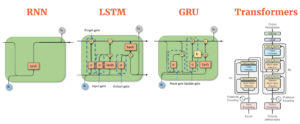
— Fuente: AIML: compare los diferentes modelos de secuencia (RNN, LSTM, GRU y Transformers)
Comprender los paradigmas de cómputos involucrados:
Para entender las diferencias entre la computación recurrente y paralela, analizaremos un caso sencillo. Dada una ecuación lineal:
ax + por + cz = 👾
¿Cómo se puede calcular esta ecuación tanto de forma recurrente como paralela?
Computación recurrente
La ecuación se divide en cálculos más pequeños, cada uno almacenado en un búfer (denotado como).
- En primer lugar, hacha se calcula y almacena en.
- A continuación, Max + por se calcula sumando por al valor del búfer existente y almacenándolo de nuevo en.
- Por último, ax + por + cz se calcula de manera similar, lo que arroja el resultado, que es igual a 👾.
Este es un cálculo recurrente, ya que reutiliza el búfer, acumulando datos paso a paso a lo largo del tiempo. Básicamente, un RNN acumula datos de forma iterativa. Por lo general, las no linealidades se asocian a cada paso de un RNN. Por ejemplo, una función sigmoidea σx (x) acompañaría Max, por, y cz. Esta secuencia debe calcularse primero, evitando la posibilidad de paralelizar los RNN.
Computación paralela
En la computación paralela, la ecuación (a. x) + (b. y) + (c. z) = 👾 se puede calcular simultáneamente: (a) (x) (b) (.) (y) = 👾 (c) (z) Aquí, todos los términos se calculan a la vez, haciendo que el proceso sea paralelo.
El enfoque RetNet
En arquitecturas como Transformers, diseñadas específicamente para la computación en paralelo, los cálculos recurrentes no son posibles. La función softmax introduce la falta de linealidad, lo que provoca esta limitación y requiere la adición de todos los términos antes de la aplicación. Si bien softmax ofrece una ventaja crucial para los Transformers, ya que proporciona un peso relativo de atención y preserva las dependencias a largo plazo, presenta un inconveniente. El cálculo de softmax (Q.K) contribuye a un rendimiento deficiente del tiempo de inferencia, ya que requiere retener los valores de softmax en una matriz de NxN que crece cuadráticamente con la longitud de la secuencia, lo que aumenta la demanda de memoria.

— Fuente: Retentive Network: sucesora de Transformer for Large Language Models
RetNet presenta una arquitectura fundamental para modelos lingüísticos de gran tamaño, que logra un paralelismo de entrenamiento, una inferencia rentable y un alto rendimiento. Aborda la limitación de los transformadores al omitir la función softmax, lo que permite la computación tanto paralela como recurrente. A pesar de la preocupación por los posibles inconvenientes derivados de la pérdida de capacidades no lineales, las investigaciones citadas en este documento indican que este cambio no afecta negativamente al rendimiento e incluso puede conducir a mejoras.
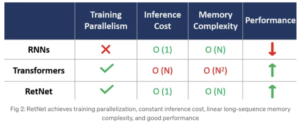
— Fuente: Retentive Networks (RetNet) Explicación: El tan esperado asesino de los Transformers ya está aquí
Al comparar los modelos Transformer y RETnet, ambos muestran capacidades de paralelización del entrenamiento. Sin embargo, surge una distinción notable en términos del costo de la inferencia. El Transformer incurre en gastos elevados, por lo que es necesario retener todo el conjunto de datos en la memoria para poder realizar una inferencia satisfactoria, lo que se traduce en un aumento de la complejidad de la memoria de forma cuadrática en el caso de secuencias largas. Por el contrario, el modelo RETnet acumula datos en un búfer y utiliza únicamente el búfer más reciente para el siguiente token de forma recurrente.
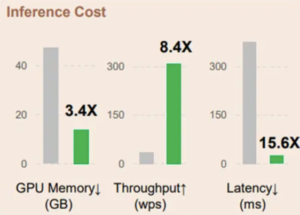
— Fuente: Retentive Network: sucesora de Transformer for Large Language Models
(Verde: RetNet | Gris: Transformers)
Retención
La arquitectura RetNet introduce un concepto novedoso llamado «Retención», que lo define de la siguiente manera:

En esta ecuación, Q, K y V representan consultas, claves y valores que se encuentran comúnmente en los mecanismos de atención. El símbolo (.) indica la multiplicación por elementos, y RETNet introduce D como una matriz adicional, que sirve como puerta o modificador del mecanismo de atención. He aquí una explicación general de lo que hace la ecuación sin entrar en detalles técnicos: El término QK⊤ normalmente calcula las similitudes entre las consultas y las claves, actuando como puntuaciones de atención. D funciona como un factor de modulación, ajustando las puntuaciones de atención en función de criterios o condiciones específicos. Por último, estas puntuaciones de atención ajustadas se multiplican por elementos por V, los valores, para obtener el resultado denominado «retención». Este mecanismo innovador permite a RETNet realizar cálculos tanto recurrentes como paralelos. La introducción de D introduce una nueva capa de complejidad, que permite un equilibrio entre la atención y otros factores modificadores. Al utilizar este mecanismo de retención, RETNet pretende mantener, o incluso mejorar, la eficacia de los cálculos sin depender de la función softmax. En última instancia, esto permite el procesamiento paralelo y recurrente de los datos, lo que diferencia a RETNet de las arquitecturas tradicionales, como las RNN, y de las arquitecturas totalmente paralelas, como Transformers.
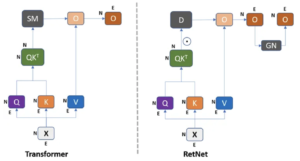
— Fuente: Retentive Network: sucesora de Transformer for Large Language Models
Representación paralela de la retención
En la arquitectura RetNet, D cumple una doble función más allá de funcionar simplemente como una máscara causal. Si bien es cierto que se trata de una matriz triangular diseñada para evitar que cualquier token «mire hacia el futuro» y garantizar que cada token sirva como ejemplo de entrenamiento individual, también integra un factor de deterioro temporal.
La matriz D se define de la siguiente manera:
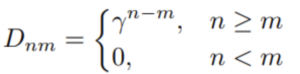
En esta ecuación, γ es un escalar que decae a medida que aumenta el desfase temporal entre n y m. En otras palabras, cuanto más retrocedas en el tiempo, más decae la señal. Esto representa una mejora con respecto a una máscara causal básica al integrar el concepto de decaimiento temporal, lo que hace que la arquitectura RETnet sea más adaptable y eficaz a la hora de captar la dinámica temporal. Este factor de disminución temporal desempeña un papel fundamental en lo que la arquitectura denomina «retención multiescala». El factor de disminución temporal γ añade un nivel de complejidad y adaptabilidad al modelo RETnet. Permite que el modelo valore más los tokens recientes que los antiguos, lo que resulta particularmente útil en aplicaciones en las que la secuencia temporal de los datos es importante, como el análisis de series temporales o el procesamiento del lenguaje natural.

El diagrama ilustra cómo el factor de decaimiento temporal γ se aplica de manera diferente en varias posiciones de la secuencia, enfatizando la importancia de los puntos de datos recientes y reduciendo progresivamente el peso a medida que retrocedemos en el tiempo.
Representación recurrente de la retención
En ausencia de la función softmax, la arquitectura RETNet permite una representación lineal del mecanismo de atención, lo que facilita la computación recurrente durante la inferencia.

— Fuente: Retentive Network: sucesora de Transformer for Large Language Models
En términos prácticos, se puede recorrer la secuencia en iteración, acumulando datos en un búfer, de forma similar a como lo haría una red neuronal recurrente. Los diagramas que ilustran este proceso resaltan claramente la distinción entre representaciones paralelas y recurrentes. En la representación paralela, multiplique todos los elementos simultáneamente, mientras que en la representación recurrente, los cálculos se realizan paso a paso. Dentro de la representación recurrente, un estado recurrente se multiplica por un factor γ. Tras esta multiplicación, se emplea otra ecuación para calcular el mecanismo de atención. Esta ecuación, que sería inviable en los modelos tradicionales de Transformer, se multiplica finalmente por la consulta para obtener el mecanismo de retención.
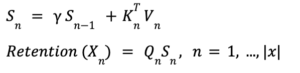
Básicamente, el resultado final de cada consulta de la secuencia se determina solo después de acumular las claves y los valores asociados mediante pasos periódicos. De esta manera, cada token genera sus consultas y analiza el pasado de la secuencia, basándose en las multiplicaciones clave-valor. La representación recurrente permite una interacción más matizada con secuencias pasadas, lo que resulta particularmente útil en tareas que requieren comprender las relaciones temporales o las dependencias entre secuencias. A diferencia de Transformers, RETNet gestiona estos requisitos de manera eficiente mediante su representación recurrente, lo que proporciona una ventaja única en una variedad de aplicaciones.
Representación recurrente de la retención por fragmentos
La arquitectura RetNet introduce una operación inteligente «por partes», que combina a la perfección la computación recurrente con el paralelismo. El concepto implica acumular datos en un búfer R, lo que representa un «fragmento», transformando así todo el cálculo en un proceso recursivo.

- Toma el búfer acumulado de fragmentos anteriores y calcúlalo en paralelo.
- Procesa también el fragmento actual en paralelo.
- Suma estos dos resultados.
Básicamente, «Junkwise» describe la estrategia de agregar información en un búfer R, denominado «fragmento», introduciendo así una naturaleza recurrente en el proceso. Este método armoniza los enfoques recurrentes y paralelos. Concretamente, el pasado lejano se acumula en un búfer utilizando la forma recurrente, mientras que el fragmento pasado o actual inmediato se procesa de forma paralela. Este enfoque híbrido equilibra cuidadosamente el procesamiento recurrente y paralelo. En consecuencia, esta metodología permite al modelo gestionar de manera eficiente secuencias extensas al acumular rápidamente la información de las secuencias largas en el búfer. Esta técnica permite al modelo «ver» con más profundidad el pasado y, al mismo tiempo, conservar las ventajas de la computación en paralelo. Al tener en cuenta los fragmentos actuales y pasados, el modelo puede extraer inferencias más complejas a partir de los datos, lo que resulta muy eficaz para las tareas que requieren comprender las dependencias o secuencias a largo plazo.
Retención multiescala cerrada
La arquitectura RetNet mejora sus capacidades mediante la «retención multiescala cerrada» (MSR), que se basa en la función de reducción temporal introducida anteriormente en la codificación posicional de la máscara causal. El objetivo de este concepto es añadir matices al mecanismo tradicional de atención con múltiples cabezas utilizado en los modelos convencionales.
- El modelo emplea valores de gamma distintos para cada cabeza de atención, lo que permite diversas estrategias de retención. Por ejemplo, algunos usuarios pueden centrarse en los tokens más recientes, mientras que otros se centran en la secuencia completa.
- Fija estos valores de γ en diferentes capas, pero varíalos entre las cabezas, lo que resulta en diferentes dinámicas de atención.
- Introduce una compuerta giratoria para aumentar la no linealidad de la capa y mejorar el poder de representación del modelo.
Este concepto, denominado «atención multiescala cerrada», representa una mejora matizada del mecanismo de atención tradicional. Al incorporar el deterioro temporal inherente en las codificaciones de posición y la máscara causal, los autores introducen un enfoque sofisticado de la atención. En los mecanismos de atención típicos, el sistema utiliza la atención de varios cabezales, transformando los datos en un vector de consulta más grande segmentado en distintas partes. Cada segmento se somete a un procesamiento de atención único y los resultados de los «jefes» individuales se consolidan. Partiendo de esta base, los autores proponen una modificación: aplicar diferentes factores de decaimiento temporal a cada cabeza, lo que permitiría la adaptabilidad a la hora de capturar una gama más rica de información y relaciones dentro de los datos.
Arquitectura general de las redes de retención
La construcción de una red de retención de capa L implica apilar capas de retención multiescala (MSR) y capas de red de alimentación directa (FFN). En esta sección se explica la arquitectura formal del modelo de capa L y se destacan sus capacidades de transformación secuencial.
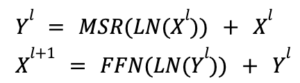
- MSR (retención multiescala): gestiona el mecanismo de atención, lo que permite que la red se centre en diferentes partes de la secuencia de entrada.
- FFN (Feed-Forward Network): actúa como la columna vertebral computacional del modelo, tomando la salida procesada de MSR y aplicando transformaciones adicionales.
- Normalización de capa (LN): normaliza las salidas de capa para estabilizar el proceso de aprendizaje y hacer que la red sea más sólida.
- La arquitectura alterna de MSR y FFN permite que el modelo se beneficie tanto de mecanismos de atención especializados como de cálculos sencillos de retroalimentación.
- La normalización de capas contribuye a un proceso de entrenamiento más estable y eficiente.
- La estructura formal es altamente modular, lo que significa que los componentes se pueden modificar o ampliar fácilmente para adaptarse a diversas tareas y tipos de datos.
Una red de retención de capa L integra de manera efectiva redes de retención y retroalimentación de múltiples escalas, reforzadas aún más por la normalización de capas. Esta arquitectura está diseñada para ser versátil y eficaz, por lo que es ideal para abordar tareas complejas de aprendizaje automático. En esencia, se construye una red de retención mediante la superposición de redes de retención multiescala y de retroalimentación en forma de fichas. En cada etapa, se introduce una conexión residual, en la que se aplica la normalización de capas intermedias. Esta arquitectura es similar a la del modelo de transformador, con la distinción principal que se distingue por la sustitución del mecanismo de atención con varios cabezales por un mecanismo de retención multiescala.
Experimentos
Los autores iniciaron la capacitación sobre modelos lingüísticos de varios tamaños (1,3B, 2,7B y 6,7B) desde cero, compilando el corpus de capacitación de The Pile, C4 y The Stack. Llevaron a cabo experimentos para evaluar la arquitectura de RETnet en función de varios puntos de referencia, que abarcaron el rendimiento de la modelización de lenguajes y el aprendizaje sin ningún intento o con pocos intentos en las tareas posteriores. Tanto en el entrenamiento como en la inferencia, se realizó una comparación exhaustiva, teniendo en cuenta factores como la velocidad, el consumo de memoria y la latencia.
Comparación de modelos de lenguaje
Si bien los avances, particularmente en términos de inferencia, velocidad, memoria y latencia, son notables, es esencial evaluar la arquitectura en las tareas de modelado del lenguaje. En este contexto, los autores introdujeron parámetros tales como la perplejidad, el aprendizaje de cero o de pocos intentos para corroborar la supuesta superioridad de RETnet. Es importante tener en cuenta que, aparte de un tutorial cuando se entrena a una pequeña ResNet, no hay otros recursos disponibles para mostrar el desempeño del modelo en estas tareas.
Perplejidad
El gráfico presenta resultados experimentales que indican que RetNet se perfila como un sólido competidor de Transformer en cuanto a modelos de lenguaje de gran tamaño. Empíricamente, RETNet comienza a superar a Transformer cuando el tamaño del modelo supera los 2B.
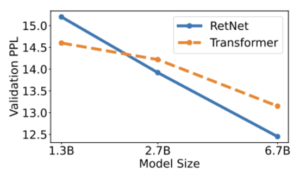
— Fuente: Retentive Network: sucesora de Transformer for Large Language Models
Evaluación de cero y pocos disparos en tareas posteriores
Al utilizar HellasWag (HS), BoolQ, COPA, PIQA, Winograd, Winogrande y StoryCloze (SC) como conjuntos de datos de prueba, los autores evaluaron el aprendizaje de cero y 4 disparos con los modelos 6.7B. Los números de precisión coinciden con la perplejidad del modelado del lenguaje descrita anteriormente. RetNet demuestra un rendimiento comparable al de Transformer en entornos de aprendizaje basados en cero y en contexto, tal y como se muestra en la tabla siguiente.

— Fuente: Retentive Network: sucesora de Transformer for Large Language Models
Coste de formación e inferencia
Coste de formación
La tabla compara la velocidad de entrenamiento y el consumo de memoria de Transformer, Transformer+FlashAttention y RetNet, con la duración de la secuencia de entrenamiento establecida en 8192. Los resultados experimentales revelan que RETNet muestra una mayor eficiencia de memoria y un mayor rendimiento que los Transformers durante el entrenamiento.

— Fuente: Retentive Network: sucesora de Transformer for Large Language Models
Coste de inferencia
Medimos el costo de la inferencia comparando el costo de la memoria, el rendimiento y la latencia. Si bien el documento presenta los resultados basados en el modelo de 6,7 GB probado en una GPU A100-80 GB, con fines de prueba hemos experimentado con esto repositorio github. Debido a las limitaciones de memoria, creamos el punto de referencia utilizando un RETnet de 1,3 B en una GPU T4.
Memoria:
El costo de memoria del transformador aumenta linealmente con la longitud de la secuencia debido a las cachés de KV. Por el contrario, el consumo de memoria de RETnet se mantiene constante en torno a los 4 GB, incluso para secuencias largas que requieren mucha menos memoria de GPU para alojar RETnet. Esto hace que RETNet sea más escalable y eficiente para secuencias más largas.

— Fuente: experimentos internos
Si bien tanto RETnet como Transformer son arquitecturas potentes, el bajo consumo de memoria y el bajo consumo de memoria de RETnet lo convierten en una opción más deseable para aplicaciones con limitaciones en los recursos computacionales, especialmente para gestionar secuencias extensas.
Rendimiento:
RetNet demuestra una ventaja notable en cuanto a rendimiento sobre Transformer en todas las longitudes de secuencia, lo que demuestra su eficiencia superior. Si bien Transformer experimenta una caída en el rendimiento a medida que aumenta la duración de la decodificación, RETNet mantiene un rendimiento mayor e invariable en cuanto a la longitud al aprovechar la representación recurrente de la retención. Concretamente, RETnet logra de manera constante un rendimiento ligeramente superior a los 150 tokens/s, lo que subraya su rendimiento estable incluso con secuencias más largas. Por el contrario, el rendimiento de Transformer se mantiene constantemente bajo en varias longitudes de secuencia, por debajo de los 50 tokens/s. Ambos modelos muestran estabilidad de rendimiento, pero la tasa de Transformer se mantiene estable, mientras que RETNet experimenta pequeñas fluctuaciones, lo que pone de manifiesto la eficiencia general de RETnet a la hora de gestionar secuencias de distintas longitudes.
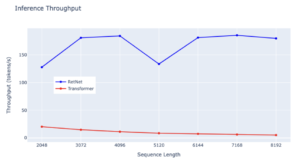
— Fuente: experimentos internos
Al evaluar la eficiencia de estas arquitecturas en términos de rendimiento de inferencia, RETnet se perfila como el líder indiscutible. Su capacidad para procesar datos a velocidades más altas de manera consistente, incluso con longitudes de secuencia cada vez mayores, la convierte en una opción más adecuada para las tareas que requieren una inferencia rápida.
Latencia:
La latencia de los Transformers aumenta más rápido con una entrada más larga. Los resultados experimentales muestran que el aumento del tamaño de los lotes aumenta la latencia de Transformer. Además, la latencia de los Transformers aumenta más rápido con una entrada más prolongada. Por el contrario, la latencia de decodificación de RetNet supera a la de Transformers y se mantiene prácticamente igual en diferentes tamaños de lotes y longitudes de entrada.
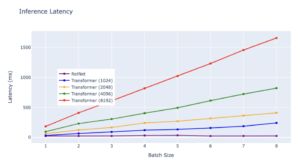
— Fuente: experimentos internos
Reflexiones finales
Los experimentos iniciales arrojan resultados alentadores. Sin embargo, a pesar de que los datos actuales sugieren que RETnet supera al Transformer en todas las tareas, más información podría revelar ámbitos específicos en los que RETnet sobresale y otros en los que no lo hace. Los datos preliminares muestran un panorama optimista, pero lograr la linealidad en todos los procesos no garantiza necesariamente unos resultados óptimos para todos. Si este fuera el caso, revolucionaría el campo, ya que ofrecería una arquitectura escalable con costos de inferencia mínimos, permitiría una gran variedad de técnicas de optimización debido a su linealidad y, potencialmente, ofrecería un rendimiento mejorado. Sin embargo, llegar a tales conclusiones podría ser prematuro. La eficacia general de la arquitectura, especialmente su énfasis en los procesos lineales, sigue siendo objeto de mayor exploración. Para una comprensión más profunda de los grandes modelos lingüísticos (LLM) y sus implicaciones, el artículo 'Una guía de incorporación a los LLM'sirve como un recurso valioso que complementa las ideas presentadas en este debate.
Referencias
- «Retentive Network: una sucesora de Transformer for Large Language Models» https://arxiv.org/pdf/2307.08621.pdf
- «Explicación de Retentive Networks (RetNet): el tan esperado asesino de los Transformers ya está aquí» https://medium.com/ai-fusion-labs/retentive-networks-retnet-explained-the-much-awaited-transformers-killer-is-here-6c17e3e8add8
- Una implementación simple pero sólida de RetNet en PyTorch de «Retentive Network: A Successor to Transformer for Large Language Models» https://github.com/fkodom/yet-another-retnet



.png)