.png)
Explorando a RetNet: a evolução dos transformadores




Desde 2017, os transformadores demonstraram sua superioridade em desempenho e eficiência computacional, superando as redes neurais recorrentes (RNNs). O mecanismo de atenção apresentado no artigo “Atenção é tudo o que você precisa” e sua capacidade de paralelizar o treinamento — uma façanha com a qual os RNNs tradicionais lutaram — atribuem essa superioridade. No entanto, os transformadores apresentam um desafio: os custos de memória e inferência associados à sua arquitetura. Nesta postagem do blog, exploraremos o modelo RetNet, uma iniciativa da equipe de pesquisa da Microsoft que visa enfrentar os desafios impostos pelos transformadores e, ao mesmo tempo, alcançar um desempenho competitivo.
Os antecessores: redes neurais recorrentes e transformadores
O processamento sequencial em RNNs limita o treinamento paralelo devido a cálculos lineares. Os RNNs processam cada token sequencialmente, impedindo a paralelização. RNNs avançados, como LSTM e GRU, mantêm um fluxo sequencial, impedindo a paralelização eficiente. Em contraste, os Transformers introduzem uma mudança de paradigma ao incorporar um mecanismo de autoatenção. Esse mecanismo, juntamente com uma “máscara causal”, garante que cada token em uma sequência tenha conhecimento de todos os tokens anteriores. A aplicação do mascaramento causal permite o treinamento paralelo, pois cada token pode ser processado simultaneamente, mantendo o foco em seu contexto histórico. Consequentemente, cada token funciona como um exemplo de treinamento independente, permitindo que os Transformers sejam treinados com todos os tokens simultaneamente. Resumindo, os Transformers superam as limitações do RNN no treinamento sequencial. Mecanismos de atenção e mascaramento causal tornam seu processo de treinamento mais eficiente e paralelizável. No entanto, o mecanismo de autoatenção apresenta desafios na inferência e no uso da memória, conforme detalhado posteriormente.
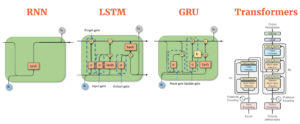
— Fonte: AIML- Compare os diferentes modelos de sequência (RNN, LSTM, GRU e Transformers)
Compreender os paradigmas de computação envolvidos:
Para entender as diferenças entre computação recorrente e paralela, analisaremos um caso simples. Dada uma equação linear:
ax + por + cz = 👾
Como essa equação pode ser calculada de forma recorrente e paralela?
Computação recorrente
A equação é dividida em cálculos menores, cada um armazenado em um buffer (indicado como).
- Primeiro, machado é calculado e armazenado em.
- Em seguida, Max + por é calculado adicionando de ao valor do buffer existente e armazenando-o de volta em.
- Finalmente, max + por + cz é calculado de forma semelhante, produzindo o resultado, que é igual a 👾.
Essa é uma computação recorrente, pois reutiliza o buffer, acumulando dados passo a passo ao longo do tempo. Um RNN basicamente acumula dados de forma iterativa. As não linearidades geralmente estão associadas a cada etapa em um RNN. Por exemplo, uma função sigmóide σ (x) acompanharia Max, por, e cz. Essa sequência deve ser calculada primeiro, evitando a possibilidade de paralelizar RNNs.
Computação paralela
Na computação paralela, a equação (a. x) + (b. y) + (c. z) = 👾 pode ser calculado simultaneamente: (a) (x) (b) (.) (y) = 👾 (c) (z) Aqui, todos os termos são computados de uma só vez, tornando o processo paralelo.
A abordagem RetNet
Em arquiteturas como Transformers, projetadas especificamente para computação paralela, cálculos recorrentes não são possíveis. A função softmax introduz a não linearidade, causando essa limitação e exigindo a adição de todos os termos antes da aplicação. Embora o softmax ofereça uma vantagem crucial para os Transformers, fornecendo pesos de atenção relativos e preservando dependências de longo prazo, ele apresenta uma desvantagem. A computação do softmax (Q.K) contribui para o baixo desempenho do tempo de inferência, exigindo a retenção dos valores do softmax em uma matriz NxN que cresce quadraticamente com o comprimento da sequência, levando a maiores demandas de memória.

— Fonte: Retentive Network: sucessora do Transformer for Large Language Models
O RetNet apresenta uma arquitetura fundamental para grandes modelos de linguagem, alcançando paralelismo de treinamento, inferência econômica e alto desempenho. Ele aborda a limitação dos transformadores ao omitir a função softmax, permitindo a computação paralela e recorrente. Apesar das preocupações com possíveis compensações devido à perda de capacidades não lineares, a pesquisa citada neste artigo indica que essa mudança não afeta adversamente o desempenho e pode até levar a melhorias.
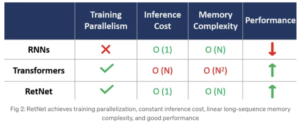
— Fonte: Retentive Networks (RETnet) Explicada: O tão esperado assassino de Transformers está aqui
Ao comparar os modelos Transformer e RetNet, ambos apresentam recursos de paralelização de treinamento. No entanto, surge uma distinção notável em termos de custo de inferência. O Transformer incorre em despesas elevadas, exigindo a retenção de todo o conjunto de dados na memória para uma inferência bem-sucedida, resultando em maior complexidade de memória de forma quadrática para sequências longas. Em contraste, o modelo RetNet acumula dados em um buffer, utilizando somente o buffer mais recente para o token subsequente de forma recorrente.
— Fonte: Retentive Network: sucessora do Transformer for Large Language Models
(Verde: RetNet | Cinza: Transformers)
Retenção
A arquitetura RetNet introduz um novo conceito chamado “Retenção”, definindo-o da seguinte forma:

Nessa equação, Q, K e V representam consultas, chaves e valores comumente encontrados em mecanismos de atenção. O símbolo (.) indica multiplicação por elemento, e o RetNet introduz D como uma matriz adicional, servindo como uma porta ou modificador do mecanismo de atenção. Aqui está uma explicação geral do que a equação faz sem se aprofundar nos detalhes técnicos: O termo QK⊤ normalmente calcula as semelhanças entre consultas e chaves, atuando como pontuações de atenção. D funciona como um fator de modulação, ajustando os escores de atenção com base em critérios ou condições específicos. Finalmente, essas pontuações de atenção ajustadas são multiplicadas elemento a elemento por V, os valores, para produzir a saída, denominada “Retenção”. Esse mecanismo inovador permite que a RetNet realize cálculos recorrentes e paralelos. A introdução de D introduz uma nova camada de complexidade, permitindo um equilíbrio entre a atenção e outros fatores modificadores. Ao usar esse mecanismo de retenção, a RetNet afirma manter, ou até mesmo aprimorar, a eficácia dos cálculos sem depender da função softmax. Em última análise, isso permite o processamento paralelo e recorrente de dados, diferenciando a RetNet de arquiteturas tradicionais, como RNNs, e arquiteturas totalmente paralelas, como Transformers.
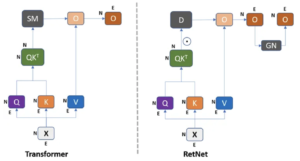
— Fonte: Retentive Network: sucessora do Transformer for Large Language Models
Representação paralela da retenção
Na arquitetura RetNet, D desempenha um papel duplo além de simplesmente funcionar como uma máscara causal. Embora, de fato, seja uma matriz triangular criada para evitar que qualquer token “olhe para o futuro” e garantir que cada token sirva como um exemplo de treinamento individual, ela também integra um fator de decaimento temporal.
A matriz D é definida da seguinte forma:
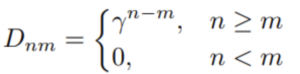
Nessa equação, γ é um escalar que decai à medida que o intervalo de tempo aumenta entre n e m. Em outras palavras, quanto mais você volta no tempo, mais o sinal decai. Isso representa uma melhoria em relação a uma máscara causal básica ao integrar o conceito de decadência temporal, tornando a arquitetura RetNet mais adaptável e proficiente na captura da dinâmica temporal. Esse fator de decaimento temporal desempenha um papel fundamental no que a arquitetura chama de “retenção em várias escalas”. O fator de decaimento temporal γ adiciona uma camada de complexidade e adaptabilidade ao modelo RetNet. Ele permite que o modelo pese mais os tokens recentes do que os tokens mais antigos, o que é particularmente útil em aplicações em que a sequência temporal dos dados é importante, como análise de séries temporais ou processamento de linguagem natural.

O diagrama ilustra como o fator de decaimento temporal γ se aplica de forma diferente em várias posições na sequência, enfatizando a importância dos pontos de dados recentes e reduzindo progressivamente o peso à medida que voltamos no tempo.
Representação recorrente da retenção
Na ausência da função softmax, a arquitetura RetNet permite uma representação linear do mecanismo de atenção, facilitando a computação recorrente durante a inferência.

— Fonte: Retentive Network: sucessora do Transformer for Large Language Models
Em termos práticos, pode-se iterar por meio da sequência, acumulando dados em um buffer, da mesma forma que uma rede neural recorrente faria. Os diagramas que ilustram esse processo destacam claramente a distinção entre representações paralelas e recorrentes. Na representação paralela, multiplique todos os elementos simultaneamente, enquanto que, na representação recorrente, os cálculos prosseguem passo a passo. Dentro da representação recorrente, um estado recorrente sofre multiplicação por um fator γ. Após essa multiplicação, outra equação é empregada para calcular o mecanismo de atenção. Essa equação, que seria inviável nos modelos tradicionais de transformadores, é finalmente multiplicada pela consulta para alcançar o mecanismo de retenção.
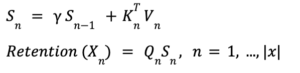
Essencialmente, a saída final de cada consulta na sequência é determinada somente após o acúmulo das chaves e valores associados por meio de etapas recorrentes. Dessa forma, cada token gera suas consultas e analisa o passado da sequência, com base nas multiplicações de valores-chave. A representação recorrente permite uma interação mais matizada com sequências passadas, provando ser particularmente valiosa em tarefas que requerem uma compreensão das relações temporais ou das dependências da sequência. Ao contrário dos transformadores, o RetNet lida eficientemente com esses requisitos por meio de sua representação recorrente, fornecendo uma vantagem única em uma variedade de aplicações.
Representação recorrente de retenção em partes
A arquitetura RetNet introduz uma operação inteligente “em partes”, combinando perfeitamente a computação recorrente com o paralelismo. O conceito envolve acumular dados em um buffer R, representando um “pedaço”, transformando assim toda a computação em um processo recursivo.

- Pegue o buffer acumulado dos blocos anteriores e calcule-o em paralelo.
- Processe também o pedaço atual em paralelo.
- Some esses dois resultados juntos.
Essencialmente, “Junkwise” descreve a estratégia de agregar informações em um buffer R, conhecido como “pedaço”, introduzindo assim uma natureza recorrente no processo. Esse método harmoniza abordagens recorrentes e paralelas. Especificamente, o passado distante se acumula em um buffer usando a forma recorrente, enquanto o passado imediato ou o fragmento atual são processados de maneira paralela. Essa abordagem híbrida equilibra cuidadosamente o processamento recorrente e paralelo. Consequentemente, essa metodologia permite que o modelo gerencie com eficiência sequências extensas acumulando rapidamente informações para sequências longas no buffer. Essa técnica capacita o modelo a “enxergar” mais longe no passado, mantendo as vantagens da computação paralela. Ao considerar as partes atuais e passadas, o modelo pode extrair inferências mais complexas dos dados, mostrando-se altamente eficiente para tarefas que exigem uma compreensão das dependências ou sequências de longo prazo.
Retenção fechada em várias escalas
A arquitetura RetNet aprimora seus recursos por meio do 'Gated Multi-Scale Retention' (MSR), com base no recurso de decaimento temporal introduzido anteriormente na codificação posicional da máscara causal. Esse conceito visa adicionar nuances ao mecanismo tradicional de atenção com várias cabeças usado em modelos convencionais.
- O modelo emprega valores γ distintos para cada chefe de atenção, permitindo diversas estratégias de retenção. Por exemplo, certas cabeças podem se concentrar em tokens mais recentes, enquanto outras atendem a toda a sequência.
- Corrija esses valores γ em diferentes camadas, mas varie-os entre as cabeças, resultando em diferentes dinâmicas de atenção.
- Introduza uma porta giratória para aumentar a não linearidade da camada, aprimorando o poder representacional do modelo.
Esse conceito, denominado “atenção multiescala fechada”, representa um aprimoramento diferenciado do mecanismo de atenção tradicional. Ao incorporar a queda de tempo inerente nas codificações de posição e na máscara causal, os autores introduzem uma abordagem sofisticada à atenção. Em mecanismos de atenção típicos, o sistema utiliza atenção com várias cabeças, transformando dados em um vetor de consulta maior segmentado em partes distintas. Cada segmento passa por um processamento de atenção exclusivo e os resultados de “cabeças” individuais são consolidados. Com base nisso, os autores propõem uma modificação: aplicar vários fatores de decaimento temporal a cada cabeça, permitindo a adaptabilidade na captura de uma variedade mais rica de informações e relacionamentos nos dados.
Arquitetura geral das redes de retenção
A construção de uma rede de retenção de camada L envolve o empilhamento de camadas de retenção em várias escalas (MSR) e camadas de rede Feed-Forward (FFN). Esta seção explica a arquitetura formal do modelo de camada L, destacando seus recursos de transformação sequencial.
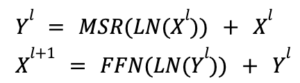
- MSR (Retenção em várias escalas): Isso manipula o mecanismo de atenção, permitindo que a rede se concentre em diferentes partes da sequência de entrada.
- FFN (Feed-Forward Network): atua como a espinha dorsal computacional do modelo, absorvendo a saída processada do MSR e aplicando transformações adicionais.
- Normalização de camadas (LN): normaliza as saídas da camada para estabilizar o processo de aprendizado e tornar a rede mais robusta.
- A arquitetura alternada do MSR e do FFN permite que o modelo se beneficie tanto de mecanismos de atenção especializados quanto de cálculos diretos de avanço.
- A normalização de camadas contribui para um processo de treinamento mais estável e eficiente.
- A estrutura formal é altamente modular, o que significa que os componentes podem ser ajustados ou estendidos facilmente para se adaptarem a várias tarefas e tipos de dados.
Uma rede de retenção de camada L integra efetivamente redes de retenção e alimentação em várias escalas, reforçadas ainda mais pela normalização de camadas. Essa arquitetura foi criada para ser versátil e eficaz, tornando-a adequada para lidar com tarefas complexas de aprendizado de máquina. Em essência, você monta uma rede de retenção colocando em camadas redes de retenção em várias escalas e redes de feedforward baseadas em tokens. Em cada estágio, uma conexão residual é introduzida, com a normalização da camada aplicada no meio. Essa arquitetura tem semelhança com o modelo do transformador, com a principal distinção na substituição do mecanismo de atenção com várias cabeças pela retenção em várias escalas.
Experimentos
Os autores iniciaram o treinamento em modelos de linguagem de vários tamanhos (1,3 B, 2,7 B e 6,7 B) do zero, compilando o corpus de treinamento de The Pile, C4 e The Stack. Eles conduziram experimentos para avaliar a arquitetura RETNet em vários benchmarks, abrangendo desempenho de modelagem de linguagem e aprendizado zero ou reduzido em tarefas posteriores. Tanto no treinamento quanto na inferência, foi feita uma comparação abrangente, considerando fatores como velocidade, consumo de memória e latência.
Comparação de modelagem de linguagem
Embora os avanços, particularmente em termos de inferência, velocidade, memória e latência, sejam dignos de nota, é essencial avaliar a arquitetura nas tarefas de modelagem de linguagem. Nesse contexto, os autores introduziram métricas como perplexidade, aprendizado zero e aprendizado de poucos tiros para comprovar a alegada superioridade da RetNet. É importante observar que, além de um tutorial quando uma pequena ResNet é treinada, não há outros recursos disponíveis para mostrar o desempenho do modelo nessas tarefas.
Perplexidade
O gráfico apresenta resultados experimentais indicando que o RetNet surge como um concorrente robusto do Transformer para grandes modelos de linguagem. Empiricamente, o RetNet começa a superar o Transformer quando o tamanho do modelo excede 2B.
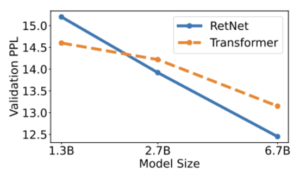
— Fonte: Retentive Network: sucessora do Transformer for Large Language Models
Avaliação Zero-Shot e Few-Shot em tarefas posteriores
Ao utilizar HellAswag (HS), BoolQ, COPA, PIQA, Winograd, Winogrande e StoryCloze (SC) como conjuntos de dados de teste, os autores avaliaram o aprendizado de zero e 4 disparos com os modelos 6.7B. Os números de precisão estão alinhados com a perplexidade da modelagem de linguagem relatada anteriormente. O RetNet demonstra desempenho comparável ao Transformer em configurações de aprendizado zero e em contexto, conforme ilustrado na tabela a seguir.

— Fonte: Retentive Network: sucessora do Transformer for Large Language Models
Custo de treinamento e inferência
Custo do treinamento
A tabela compara a velocidade de treinamento e o consumo de memória de Transformer, Transformer+FlashAttention e RetNet, com a duração da sequência de treinamento definida em 8192. Resultados experimentais revelam que o RetNet exibe maior eficiência de memória e maior rendimento do que os Transformers durante o treinamento.

— Fonte: Retentive Network: sucessora do Transformer for Large Language Models
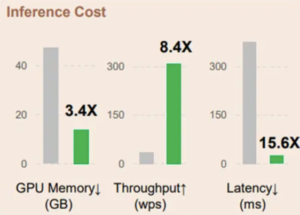
Custo de inferência
Medimos o custo da inferência comparando o custo da memória, a taxa de transferência e a latência. Embora o artigo apresente descobertas com base no modelo 6.7B testado em uma GPU A100-80GB, para fins de teste, experimentamos o uso isso repositório github. Devido às limitações de memória, construímos o benchmark usando uma RetNet de 1,3 B em uma GPU T4.
Memória:
O custo de memória do transformador aumenta linearmente com o comprimento da sequência devido aos caches KV. Em contraste, o consumo de memória do RetNet permanece consistente em torno de 4 GB, mesmo para sequências longas que exigem muito menos memória de GPU para hospedar o RetNet. Isso torna o RetNet mais escalável e eficiente para sequências mais longas.

— Fonte: experimentos internos
Embora o RetNet e o Transformer sejam arquiteturas poderosas, o tamanho consistente e baixo consumo de memória do RetNet o torna uma opção mais desejável para aplicativos com restrições de recursos computacionais, especialmente para lidar com sequências extensas.
Rendimento:
O RetNet demonstra uma vantagem notável na taxa de transferência em relação ao Transformer em todos os comprimentos de sequência, mostrando sua eficiência superior. Enquanto o Transformer experimenta uma queda na taxa de transferência à medida que o comprimento da decodificação aumenta, o RetNet mantém uma taxa de transferência maior e invariável ao aproveitar a representação recorrente da retenção. Especificamente, o RetNet atinge consistentemente uma taxa de transferência ligeiramente acima de 150 tokens/s, ressaltando seu desempenho estável mesmo com sequências mais longas. Em contraste, a taxa de transferência do Transformer permanece consistentemente baixa em vários comprimentos de sequência, consistentemente abaixo de 50 tokens/s. Ambos os modelos exibem estabilidade de transferência, mas a taxa do Transformer permanece estável, enquanto o RetNet experimenta pequenas flutuações, destacando a eficiência geral do RetNet no gerenciamento de diversos comprimentos de sequência.
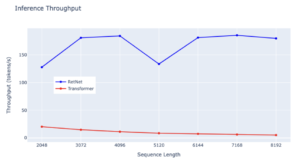
— Fonte: experimentos internos
Ao avaliar a eficiência dessas arquiteturas em termos de taxa de transferência de inferência, o RetNet surge como um claro pioneiro. Sua capacidade de processar dados em taxas mais altas de forma consistente, mesmo com o aumento dos comprimentos de sequência, o torna uma opção mais adequada para tarefas que exigem inferência rápida.
Latência:
A latência dos Transformers cresce mais rápido com entradas mais longas. Resultados experimentais mostram que o aumento do tamanho do lote aumenta a latência do Transformer. Além disso, a latência dos Transformers cresce mais rapidamente com entradas mais longas. Por outro lado, a latência de decodificação do RetNet supera os Transformers e permanece quase a mesma em diferentes tamanhos de lote e comprimentos de entrada.
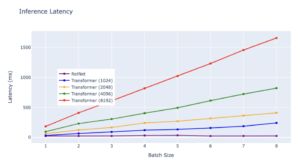
— Fonte: experimentos internos
Considerações finais
Os experimentos iniciais produzem resultados encorajadores. No entanto, apesar dos dados atuais sugerirem que o RETNet supera o Transformer em todas as tarefas, mais informações podem revelar domínios específicos em que o RETnet se destaca e outros em que ele é insuficiente. Os dados preliminares mostram um quadro otimista, mas alcançar a linearidade em cada processo não garante necessariamente resultados universalmente estelares. Se fosse esse o caso, revolucionaria o campo, oferecendo uma arquitetura escalável com custos mínimos de inferência, permitindo uma infinidade de técnicas de otimização devido à sua linearidade e potencialmente oferecendo desempenho aprimorado. No entanto, chegar a essas conclusões pode ser prematuro. A eficácia geral da arquitetura, especialmente sua ênfase em processos lineares, continua sendo objeto de maior exploração. Para uma compreensão mais profunda dos grandes modelos de linguagem (LLMs) e suas implicações, o artigo 'Um guia de integração para LLMs'serve como um recurso valioso, complementando os insights apresentados nesta discussão.
Referências
- “Rede retentiva: uma sucessora do Transformer para grandes modelos de linguagem” https://arxiv.org/pdf/2307.08621.pdf
- “Redes retentivas (RETnet) explicadas: o tão esperado assassino de Transformers está aqui” https://medium.com/ai-fusion-labs/retentive-networks-retnet-explained-the-much-awaited-transformers-killer-is-here-6c17e3e8add8
- Uma implementação PyTorch simples, mas robusta, do RetNet de “Retentive Network: um sucessor do Transformer for Large Language Models” https://github.com/fkodom/yet-another-retnet



.png)