
Computación perimetral: implementación de modelos de IA en varios dispositivos periféricos




Imagine que tiene que desarrollar una aplicación de visión artificial que debe ejecutarse en un entorno industrial o agrícola con conectividad limitada. Piense, por ejemplo, en una aplicación que detecta plagas mediante una cámara montada en maquinaria agrícola. Ahora imagine una aplicación que monitorea una máquina de una planta industrial y necesita emitir una alarma de apagado en tiempo real cada vez que se detecta un problema, para evitar que la máquina sufra daños graves. Estos son solo algunos ejemplos de aplicaciones en las que existen limitaciones importantes en términos de conectividad entre el lugar donde se capturan los datos y el servidor donde se ejecutará la aplicación de aprendizaje automático. Estas limitaciones se vuelven aún más importantes cuando se requiere una respuesta casi en tiempo real, lo que normalmente lleva a resolver el problema con las arquitecturas de computación perimetral. En una descripción general de alto nivel, una aplicación típica de aprendizaje automático se parecerá al siguiente diagrama:
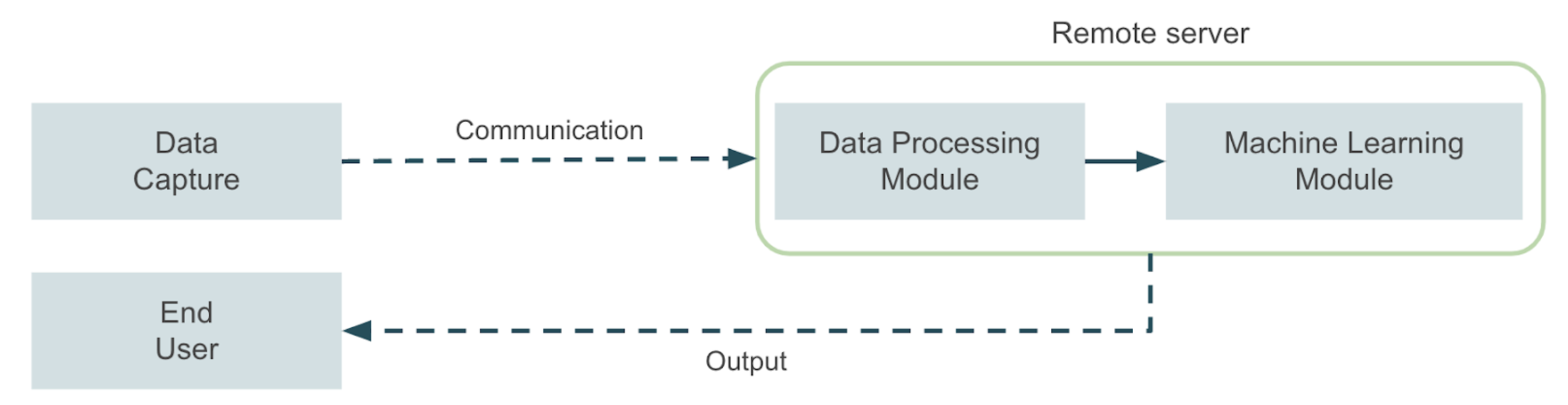
Un módulo de captura de datos envía los datos a un servidor remoto donde se llevan a cabo todas las tareas de aprendizaje automático. A continuación, el servidor envía la salida de la aplicación a un usuario final, también mediante una comunicación remota. Ahora bien, en nuestros ejemplos, es posible que no sea posible implementar una solución de este tipo debido a las limitaciones mencionadas, por lo que debemos preguntarnos cómo podemos abordar este tipo de problema de una manera más eficaz. La respuesta a esta pregunta se encuentra en el campo de las aplicaciones informáticas de vanguardia. En este caso, se utiliza un dispositivo de hardware optimizado para las tareas de aprendizaje automático para acercar la inferencia lo más posible al lugar donde se producen los datos. Este enfoque mejora los tiempos de inferencia y permite aprovechar las soluciones de inteligencia artificial en un conjunto más amplio de entornos. En este artículo, analizaremos algunas alternativas para diseñar arquitecturas para implementar aplicaciones de computación periférica listas para la producción para el aprendizaje automático en dispositivos de múltiples bordes, utilizando diferentes alternativas de proveedores de nube para centralizar las etapas de capacitación e implementación.
Enmarcar el problema
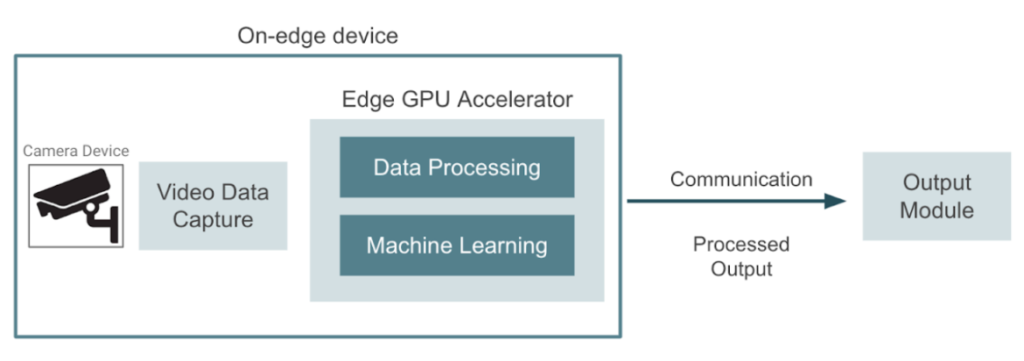
La imagen de abajo muestra un diagrama de alto nivel de lo que estamos intentando construir. Un dispositivo captura vídeos en tiempo real que deben procesarse, y el objetivo es aprovechar los dispositivos informáticos de vanguardia que se pueden utilizar para acercar el aprendizaje automático a los dispositivos de cámara. En este caso, el dispositivo periférico se encarga tanto de las tareas de preprocesamiento de los datos como de las de aprendizaje automático. La aplicación puede incluir la detección de objetos, el reconocimiento facial, la segmentación de imágenes o cualquier otra tarea de visión artificial. Finalmente, el dispositivo periférico envía el resultado a un módulo de salida donde los usuarios finales pueden consumirlo. Para ejecutar la inferencia mediante aprendizaje automático en un entorno de este tipo, es necesario implementar los modelos entrenados mediante aceleradores de GPU externos que permitan ejecutar la inferencia in situ.
Por el contrario, el enfoque más habitual sería utilizar los dispositivos de cámara solo para la captura de datos y enviar el vídeo a un proveedor de nube o a un servidor dedicado. Este servidor normalmente gestiona todo el procesamiento de datos, el aprendizaje automático, la inferencia y la generación de resultados. En este otro caso, las canalizaciones de entrenamiento de modelos y los trabajos de implementación se llevan a cabo en el mismo entorno de nube. El siguiente diagrama representa este enfoque:
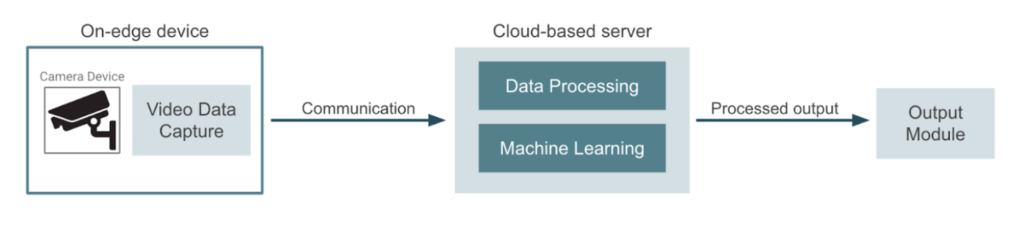
Computación perimetral versus computación basada en la nube
Llegados a este punto, podríamos preguntarnos qué enfoque nos proporcionará el mejor resultado en términos de costo/beneficio. Si decidimos optar por un enfoque basado en la periferia, podemos pensar en las siguientes ventajas:
- Las aplicaciones sensibles a la latencia se pueden ejecutar justo al lado de donde se generan los datos, lo que mejora la latencia de respuesta.
- Es posible tolerar una conectividad a Internet inestable. Este escenario no permitiría, por ejemplo, transmitir un vídeo para enviarlo cuadro por cuadro a un servidor.
- Podemos garantizar la privacidad de los datos, ya que los datos de entrada nunca saldrán del dispositivo periférico.
- Es posible manejar una gran cantidad de dispositivos que realizan inferencias utilizando los mismos modelos en diferentes ubicaciones.
Naturalmente, también hay algunas desventajas que deben tenerse en cuenta al diseñar la solución:
- La carga computacional en los dispositivos periféricos es relativamente alta, y cualquier fallo en los dispositivos periféricos acabará interrumpiendo la aplicación.
- Los costos del proyecto podrían aumentar debido al hardware dedicado utilizado en cada dispositivo periférico. Esto puede resultar prohibitivo en aplicaciones con cantidades masivas de dispositivos.
- Los recursos de la GPU son estáticos y no es posible aumentar o reducir la escala en función de la carga de trabajo.
- Se necesita más trabajo para coordinar la implementación y las actualizaciones de los modelos en todos los dispositivos.
En última instancia, la decisión de optar por una solución perimecida o basada en la nube dependerá del equilibrio entre la latencia y el costo. Si la latencia es un factor crítico, o si el entorno operativo es complejo, la mejor opción sería un enfoque basado en la periferia. Si la aplicación diseñada admite cierta tolerancia a la latencia (inferencia casi en tiempo real), entonces un enfoque basado en la nube podría ser la mejor opción. Como queremos centrarnos en la implementación de aplicaciones basadas en el borde, durante el resto de esta publicación exploraremos algunas alternativas para implementar modelos en varios dispositivos.
Implementación de modelos entrenados en varios dispositivos periféricos
El principal desafío que abordaremos en este blog está relacionado con el entrenamiento de un modelo con datos etiquetados y luego la implementación de este modelo en muchos dispositivos periféricos distribuidos en diferentes ubicaciones. La siguiente imagen muestra un diagrama de este proceso independiente de la nube:

Este es el aspecto técnico de cómo funciona:
- La fase de entrenamiento se lleva a cabo en un servidor especializado con capacidades de GPU. En esta etapa, los desarrolladores repiten hasta llegar a un modelo con el rendimiento de salida deseado. Una vez que hayamos terminado el entrenamiento, podemos contenedorizar el modelo en una imagen. Tendremos que implementar esta imagen en cada dispositivo periférico.
- Las aplicaciones en contenedores se envían a un registro de contenedores desde el que los dispositivos pueden extraer la imagen y ejecutar la implementación.
- Para la implementación del modelo, necesitamos establecer una conexión remota segura entre el servidor y cada dispositivo periférico. A continuación, la imagen del modelo se extrae del registro del contenedor. Este canal seguro garantiza una comunicación cifrada y fiable.
- Todos los dispositivos periféricos están equipados con placas GPU que ejecutan el algoritmo implementado. Estas placas GPU aumentan las capacidades computacionales de los dispositivos periféricos, lo que les permite gestionar la complejidad de los modelos implementados de manera eficiente.
- Una vez que el modelo se implementa y se ejecuta en todos los dispositivos, los resultados de cada dispositivo se envían a una API externa. Esta API sirve como conducto para recibir notificaciones de eventos de los dispositivos y proporciona información en tiempo real sobre el estado y el rendimiento del dispositivo.
La mayoría de los proveedores de nube proporcionan un servicio o conjunto de servicios que se pueden usar para desarrollar un flujo de implementación similar al que describimos anteriormente. En las siguientes secciones, profundizaremos en cada uno de los proveedores y exploraremos algunas alternativas.
Ampliación de las capacidades de AWS mediante IoT Greengrass
La nube de Amazon ofrece un servicio llamado AWS IoT Greengrass, lo que resulta útil para extender la funcionalidad de AWS a los dispositivos periféricos, lo que les permite actuar localmente en función de los datos que generan, incluso cuando no están conectados a la nube. Al utilizar este servicio, podemos realizar inferencias de aprendizaje automático de forma local en dispositivos periféricos, mediante modelos que creamos, entrenamos y optimizamos en la nube. Permite la implementación de funciones de AWS Lambda y aplicaciones en contenedores en dispositivos periféricos. La siguiente imagen muestra una descripción general de una arquitectura de implementación que utiliza este servicio:

En pocas palabras, la arquitectura incluye entrenar un modelo en la nube con datos almacenados y luego implementarlo en varios dispositivos. Al instalar el cliente AWS Iot Greengrass en los dispositivos periféricos, es posible realizar esta implementación sin problemas. Algunas características clave de la arquitectura que se muestran arriba son las siguientes:
- Entrenamos el aprendizaje automático mediante una canalización de SageMaker y utilizamos SageMaker Model Registry para el control de versiones y el almacenamiento de modelos. Sería posible reemplazar este paso por un proceso entrenado bajo demanda que se ejecutara en una instancia de GPU EC2.
- Establecemos una conexión remota entre la nube y el dispositivo periférico mediante el servicio AWS IoT Greengrass, que debe instalarse en todos los dispositivos.
- Implementamos el modelo en una función Lambda dentro de la placa de la GPU en el lado del dispositivo de Edge.
- Además, podemos usar el servicio AWS IoT Core para enviar los registros de inferencias a la nube.
Implementación de Microsoft Azure mediante IoT Edge
Al analizar los servicios disponibles, podemos observar que se puede desarrollar una arquitectura casi equivalente a la descrita para AWS utilizando IoT Edge, que es un servicio que amplía las capacidades de las soluciones de Azure IoT a los dispositivos periféricos. Nos permite ejecutar la inteligencia de la nube directamente en los dispositivos de IoT, lo que permite el análisis de datos en tiempo real y la toma de decisiones en el borde. La siguiente imagen muestra el aspecto que tendría la arquitectura cuando se desarrollara en Azure:
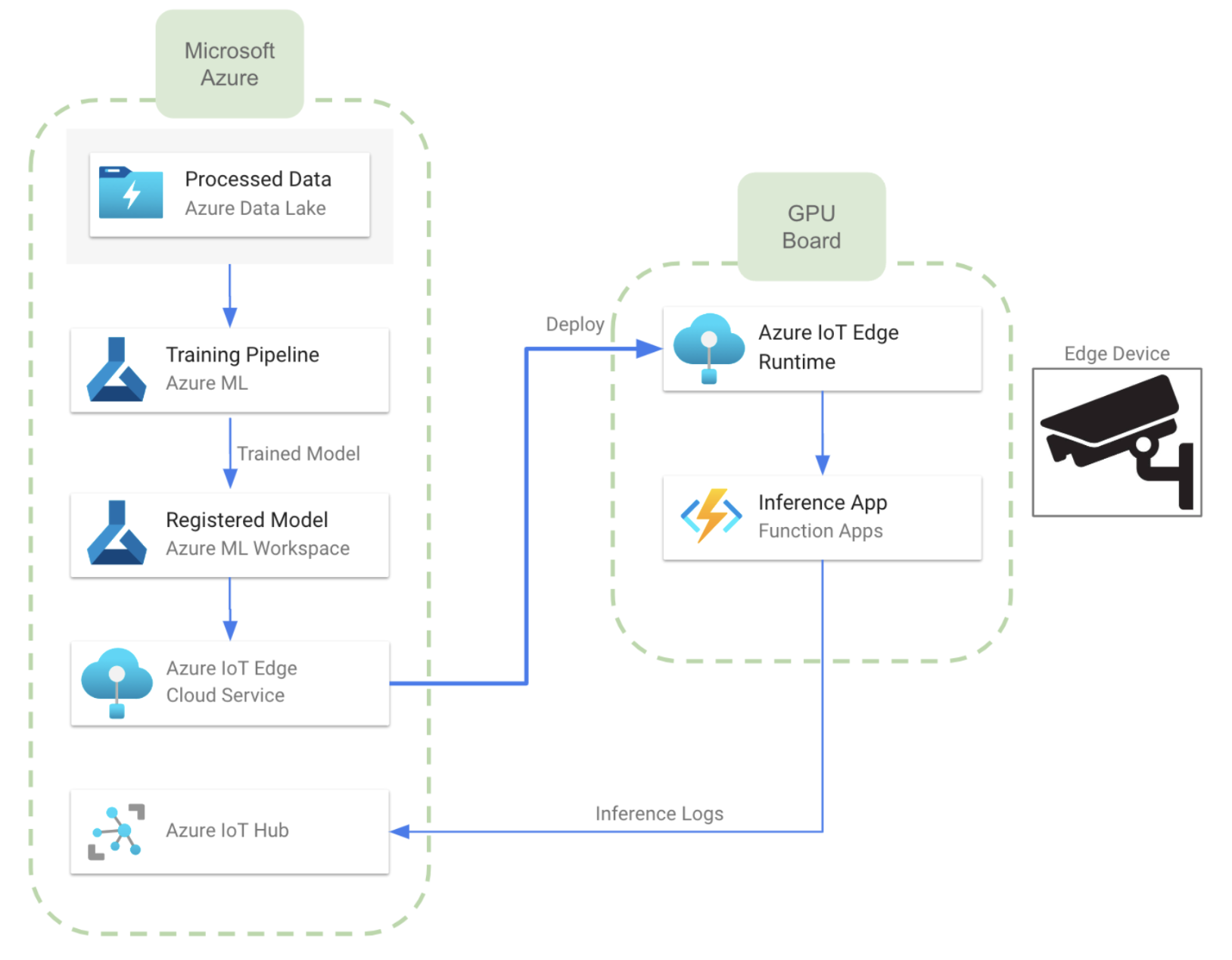
- En este caso, podemos entrenar el modelo con las capacidades de Azure ML. También podemos usar un espacio de trabajo de Azure ML para el control de versiones y el almacenamiento de modelos. Esto permitirá al usuario administrar diferentes versiones del mismo modelo o, incluso, diferentes modelos
- La comunicación entre la nube y los dispositivos periféricos se lleva a cabo mediante el servicio Azure IoT Edge. Para ello, necesitaremos instalar IoT Edge Runtime en todos los dispositivos periféricos.
- Una vez que transferimos el modelo a los dispositivos, podemos implementarlos en una función de Azure, como se muestra en el diagrama anterior. También es posible utilizar una aplicación Docker en contenedores.
- Al igual que en el caso de AWS, podemos enviar registros de inferencia a la nube mediante Azure IoT Hub. Esto proporciona una conexión bidireccional entre la nube y el dispositivo periférico.
Como comentario adicional, un enfoque alternativo consistiría en utilizar Azure Stack Edge, que es una plataforma de computación perimetral administrada en la nube que combina componentes de hardware y software patentados para llevar los servicios y las capacidades de Azure al límite. El hardware de Stack Edge incluye un hardware de aceleración de la computación diseñado para mejorar el rendimiento de la inferencia de inteligencia artificial en la periferia y, dado que tanto el hardware como los servicios en la nube los proporciona el mismo proveedor, se espera que la integración sea perfecta, pero la interoperabilidad de la nube (con otros proveedores) puede resultar difícil.
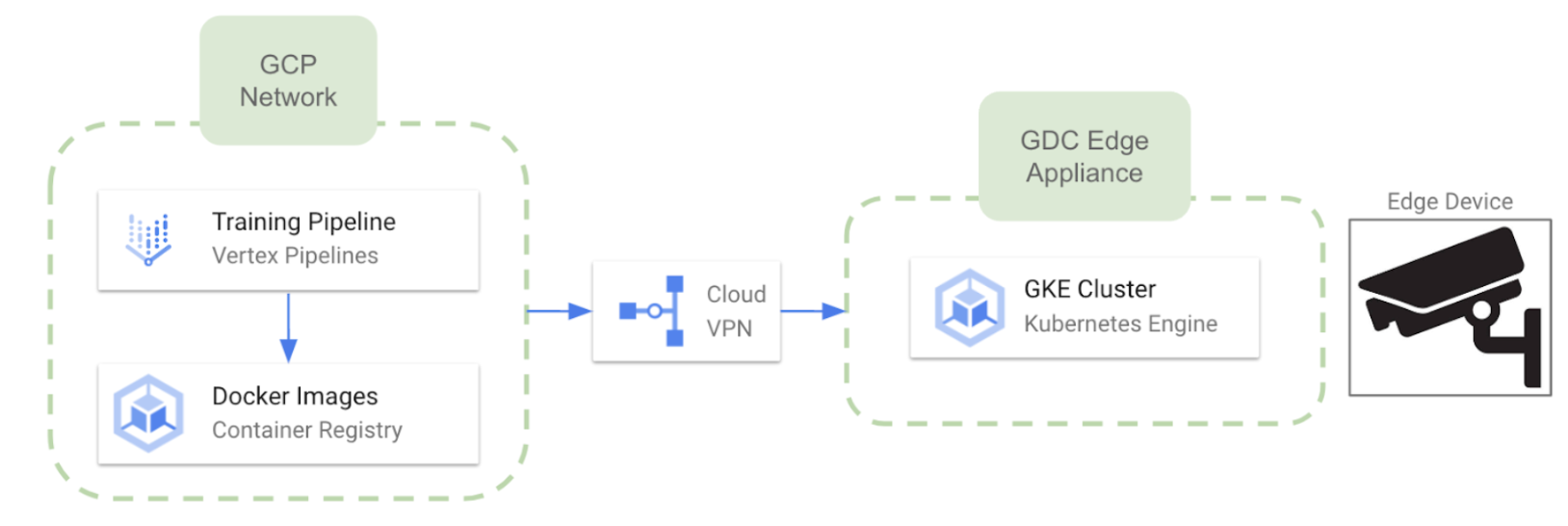
Implementación perimetral en Google Cloud Platform
Dado que Google ha decidido recientemente desaprobar sus servicios IoT Core, podemos esperar una conexión un poco más difícil con los dispositivos periféricos en comparación con los otros proveedores de nube. Sin embargo, es posible aprovechar Cloud Edge distribuido de Google que permite ejecutar clústeres de Google Kubernetes Engine en hardware dedicado proporcionado y mantenido por Google. Google entrega e instala el hardware Distributed Cloud Edge en tus instalaciones (con limitaciones regionales en este momento). Algunas características relevantes de este enfoque son las siguientes:
- El hardware dedicado es Dispositivo Cloud Edge distribuido de Google
- Una vez que el hardware esté listo, podemos implementar varios clústeres de GKE en Edge desde el entorno de GCP.
- La comunicación bidireccional entre la nube y los dispositivos está disponible
Alternativas de hardware para aplicaciones de computación perimetral
Como se comentó anteriormente, la realización de inferencias de aprendizaje automático en los dispositivos periféricos implica el uso de algún tipo de acelerador de GPU. Con este fin, NVIDIA y Google Coral ofrecen varias alternativas de hardware para seleccionar, según las diferentes necesidades de rendimiento. El objetivo principal de estos dispositivos es ofrecer potentes capacidades informáticas al límite y, al mismo tiempo, mantener una forma compacta. La siguiente es solo una lista de las posibles alternativas de hardware disponibles en el mercado:
Serie NVIDIA Jetson
- Jetson Nano: Posicionado como un dispositivo básico, el Jetson Nano cuenta con una GPU compatible con CUDA, que permite la ejecución en paralelo de múltiples redes neuronales. Equipado con varias interfaces de E/S, su precio comienza en 100 dólares.
- Jetson Xavier Nueva Zelanda: Yendo más allá en cuanto a capacidades de rendimiento, el Jetson Xavier NX puede gestionar múltiples redes neuronales y admite la codificación y decodificación de vídeo 4K. Su precio comienza en aproximadamente 400 dólares.
- Jetson AGX Xavier: Entre las mejores ofertas de NVIDIA, la Jetson AGX Xavier ofrece mejores capacidades de hardware en comparación con la Xavier NX. Este módulo de gama alta tiene un precio de alrededor de 1000 dólares.
La plataforma Edge Computing de Google Coral
- Junta de desarrollo de Coral: El Coral Dev es un ordenador de placa única, similar a una Raspberry Pi. Con un precio aproximado de 130 dólares, sirve como plataforma de desarrollo para ejecutar y crear prototipos de modelos de IA de forma avanzada. Está equipado con una TPU Edge integrada, que facilita la inferencia eficiente en el dispositivo.
- Acelerador USB Coral: Es una solución de hardware basada en USB que se puede conectar a los dispositivos existentes, incluidas las placas Raspberry Pi. Con un precio aproximado de 60 dólares, refleja las capacidades de TPU Edge de la placa de desarrollo Coral, lo que proporciona una opción económica para realizar inferencias aceleradas en el dispositivo.
Conclusiones
Uno de los principales desafíos en el campo de la IA de la computación perimetral es implementar un modelo o una aplicación entrenados en varios dispositivos de manera coordinada. Hemos abordado algunas alternativas para desarrollar una estrategia de implementación en diferentes proveedores de nube. Además, hemos explorado algunas alternativas de hardware que desempeñan un papel crucial en este tipo de arquitectura. Ya se trate de la detección de objetos en tiempo real, el reconocimiento facial, la segmentación de imágenes u otras tareas de visión artificial, el objetivo es aprovechar la potencia de los aceleradores de GPU y acercar el aprendizaje automático a los dispositivos de cámara. Este enfoque no solo agiliza el procesamiento de datos, sino que también mejora la eficiencia general de la inferencia mediante aprendizaje automático in situ.



.png)