
Computação de ponta: implantando modelos de IA em vários dispositivos de ponta




Imagine que você precise desenvolver um aplicativo de visão computacional que deve ser executado em um ambiente industrial ou agrícola com conectividade limitada. Pense, por exemplo, em um aplicativo que detecta pragas usando uma câmera montada em máquinas agrícolas. Agora imagine um aplicativo que monitora alguma máquina em uma planta industrial e precisa acionar um alarme de desligamento em tempo real toda vez que um problema é detectado, para evitar danos graves à máquina. Esses são apenas alguns exemplos de aplicativos em que há limitações relevantes em termos de conectividade entre o local em que os dados são capturados e o servidor em que o aplicativo de aprendizado de máquina será executado. Essas limitações se tornam ainda mais significativas quando há a necessidade de uma resposta quase em tempo real, o que geralmente leva à solução do problema com arquiteturas de computação de ponta. Em uma visão geral de alto nível, um aplicativo típico de aprendizado de máquina será semelhante ao diagrama a seguir:
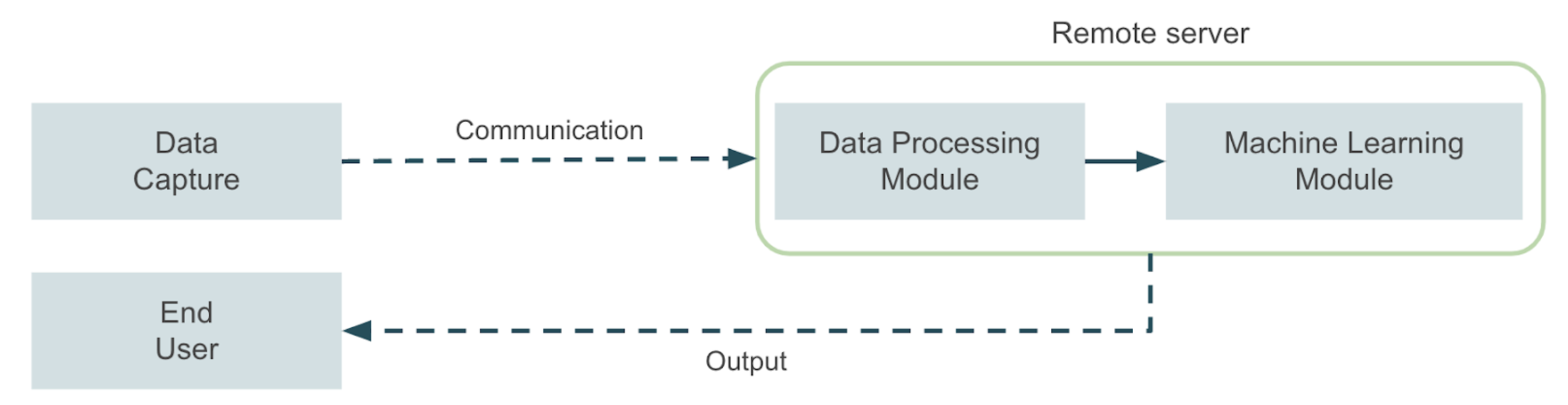
Um módulo de captura de dados envia os dados para um servidor remoto, onde todas as tarefas de aprendizado de máquina ocorrem. Em seguida, o servidor envia a saída do aplicativo para um usuário final, também por meio de comunicação remota. Agora, em nossos exemplos, talvez não seja possível implementar essa solução devido às limitações mencionadas, portanto, devemos nos perguntar como podemos resolver esse tipo de problema de maneira mais eficaz. A resposta a essa pergunta está no campo dos aplicativos de computação de ponta. Nesse caso, um dispositivo de hardware otimizado para tarefas de aprendizado de máquina é usado para trazer a inferência o mais próximo possível de onde os dados são produzidos. Essa abordagem melhora os tempos de inferência e possibilita o aproveitamento de soluções de IA em um conjunto mais amplo de ambientes. Neste post, exploraremos algumas alternativas para projetar arquiteturas para implantar aplicativos de computação de ponta prontos para produção para aprendizado de máquina em vários dispositivos de ponta usando diferentes alternativas de fornecedores de nuvem para centralizar os estágios de treinamento e implantação.
Enquadrando o problema
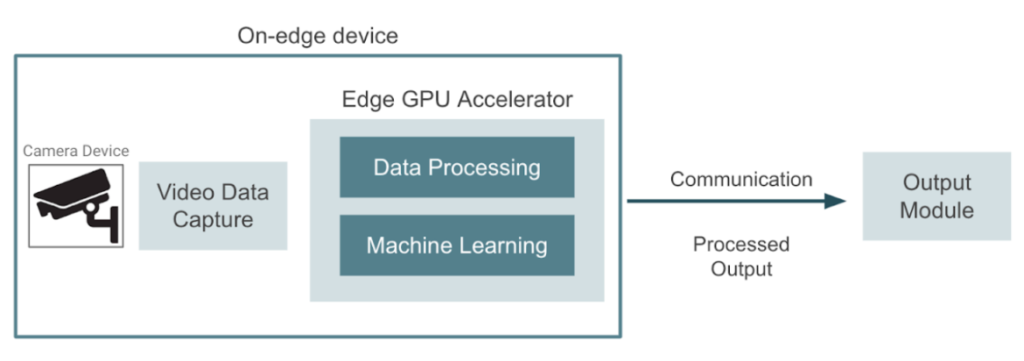
A imagem abaixo mostra um diagrama de alto nível do que estamos tentando construir. Um dispositivo captura vídeo em tempo real que precisa ser processado, e o objetivo é aproveitar os dispositivos de computação de ponta que podem ser usados para aproximar o aprendizado de máquina dos dispositivos de câmera. Nesse caso, o dispositivo de ponta cuida das tarefas de pré-processamento de dados e aprendizado de máquina. O aplicativo pode envolver detecção de objetos, reconhecimento facial, segmentação de imagens ou qualquer outra tarefa de visão computacional. Finalmente, o dispositivo de ponta envia o resultado para um módulo de saída onde os usuários finais podem consumi-lo. Para executar a inferência de aprendizado de máquina nesse ambiente, é necessário implantar os modelos treinados usando aceleradores de GPU externos que possibilitam a execução da inferência no local.
Por outro lado, a abordagem mais comum seria usar os dispositivos de câmera apenas para captura de dados e enviar o vídeo para um provedor de nuvem ou servidor dedicado. Esse servidor geralmente gerencia todo o processamento de dados, inferência de aprendizado de máquina e geração de saída. Nesse outro caso, os pipelines de treinamento de modelos e os trabalhos de implantação ocorrem no mesmo ambiente de nuvem. O diagrama a seguir representa essa abordagem:
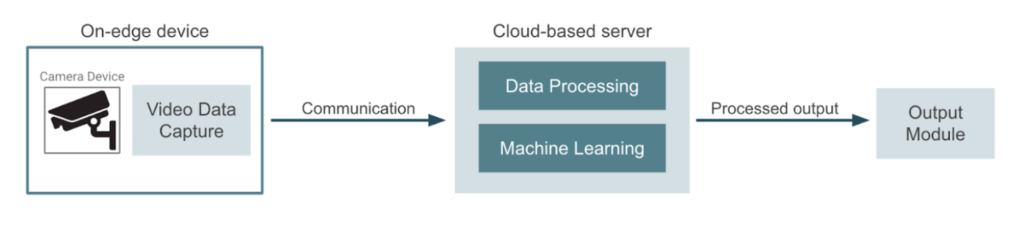
Computação de ponta versus computação baseada em nuvem
Nesse ponto, podemos nos perguntar qual abordagem nos dará o melhor resultado de custo/benefício. Se decidirmos adotar uma abordagem baseada na borda, podemos pensar nas seguintes vantagens:
- Os aplicativos sensíveis à latência podem ser executados ao lado de onde os dados estão sendo gerados, o que melhora a latência da resposta.
- É possível tolerar uma conectividade instável com a Internet. Esse cenário não permitiria, por exemplo, transmitir um vídeo para ser enviado quadro a quadro para um servidor.
- Podemos garantir a privacidade dos dados, pois os dados de entrada nunca sairão do dispositivo de ponta.
- É possível lidar com um grande número de dispositivos realizando inferências usando os mesmos modelos em locais diferentes.
Naturalmente, também há algumas desvantagens que precisam ser consideradas ao projetar a solução:
- A carga computacional em dispositivos de ponta é relativamente alta e qualquer falha nos dispositivos de borda acabará interrompendo o aplicativo.
- Os custos do projeto podem aumentar devido ao hardware dedicado usado em cada dispositivo de ponta. Isso pode ser proibitivo em aplicativos com grandes quantidades de dispositivos.
- Os recursos da GPU são estáticos e não é possível aumentar ou diminuir a escala com base na carga de trabalho.
- É necessário algum trabalho adicional para coordenar a implantação e as atualizações dos modelos em todos os dispositivos.
Em última análise, a decisão de optar por uma solução baseada na borda ou na nuvem dependerá de uma compensação entre latência e custo. Se a latência for um fator crítico ou se o ambiente operacional for complexo, uma abordagem baseada na borda seria a melhor escolha. Se o aplicativo projetado suportar alguma tolerância à latência (inferência quase em tempo real), uma abordagem baseada na nuvem pode ser a melhor opção. Como queremos nos concentrar na implantação de aplicativos baseados em bordas, no restante desta postagem, exploraremos algumas alternativas para implantar modelos em vários dispositivos.
Implantação de modelos treinados em vários dispositivos de ponta
O principal desafio que abordaremos neste blog está relacionado ao treinamento de um modelo em dados rotulados e, em seguida, à implantação desse modelo em muitos dispositivos periféricos distribuídos em diferentes locais. A imagem abaixo mostra um diagrama independente da nuvem desse processo:

Aqui está o lado técnico de como isso funciona:
- A fase de treinamento ocorre em um servidor especializado com recursos de GPU. Nesse estágio, os desenvolvedores iteram até chegarem a um modelo com o desempenho de saída desejado. Quando terminarmos o treinamento, podemos colocar o modelo em contêineres em uma imagem. Precisaremos implantar essa imagem em cada dispositivo de ponta.
- Os aplicativos em contêiner são enviados para um registro de contêiner do qual os dispositivos podem extrair a imagem e executar a implantação.
- Para a implantação do modelo, precisamos estabelecer uma conexão remota segura entre o servidor e cada dispositivo periférico. Em seguida, a imagem do modelo é retirada do registro do contêiner. Esse canal seguro garante uma comunicação criptografada e confiável.
- Todos os dispositivos de ponta são instrumentados com placas de GPU que executam o algoritmo implantado. Essas placas de GPU aumentam os recursos computacionais dos dispositivos de ponta, permitindo que eles lidem com a complexidade dos modelos implantados com eficiência.
- Depois que o modelo é implantado e executado em todos os dispositivos, os resultados de cada dispositivo são enviados para uma API externa. Essa API serve como um canal para receber notificações de eventos dos dispositivos, fornecendo feedback em tempo real sobre o status e o desempenho do dispositivo.
A maioria dos fornecedores de nuvem fornece um serviço ou conjunto de serviços que podem ser usados para desenvolver um fluxo de implantação semelhante ao descrito acima. Vamos nos aprofundar em cada um dos fornecedores e explorar algumas alternativas nas seções a seguir.
Estendendo os recursos da AWS por meio do IoT Greengrass
A nuvem da Amazon fornece um serviço chamado AWS IoT Greengrass, que é útil para estender a funcionalidade da AWS aos dispositivos periféricos, permitindo que eles atuem localmente nos dados que geram, mesmo quando não estão conectados à nuvem. Ao usar esse serviço, podemos realizar inferências de aprendizado de máquina localmente em dispositivos periféricos, usando modelos que criamos, treinamos e otimizamos na nuvem. Ele permite a implantação de funções e aplicativos em contêineres do AWS Lambda em dispositivos periféricos. A imagem abaixo mostra uma visão geral de uma arquitetura de implantação usando esse serviço:

Resumindo, a arquitetura inclui treinar um modelo na nuvem com dados armazenados e depois implantá-lo em vários dispositivos. Ao instalar o cliente AWS Iot Greengrass nos dispositivos periféricos, é possível realizar essa implantação sem problemas. Alguns dos principais recursos da arquitetura mostrada acima são os seguintes:
- Treinamos o Machine Learning usando um pipeline do SageMaker e usamos o SageMaker Model Registry para controle de versão e armazenamento de modelos. Seria possível substituir essa etapa por um pipeline treinado mais sob demanda executado em uma instância de GPU do EC2.
- Estabelecemos uma conexão remota entre a nuvem e o dispositivo de ponta por meio do serviço AWS IoT Greengrass, que precisa ser instalado em todos os dispositivos.
- Implantamos o modelo em uma função Lambda dentro da placa GPU no lado do dispositivo periférico.
- Além disso, podemos usar o serviço AWS IoT Core para enviar logs de inferência de volta para a nuvem.
Implantação do Microsoft Azure usando o IoT Edge
Ao analisar os serviços disponíveis, podemos observar que uma arquitetura quase equivalente à descrita para a AWS pode ser desenvolvida usando IoT Edge, que é um serviço que estende os recursos das soluções de IoT do Azure para dispositivos periféricos. Ele nos permite executar a inteligência em nuvem diretamente em dispositivos de IoT, permitindo a análise de dados em tempo real e a tomada de decisões na borda. A imagem abaixo mostra como seria a arquitetura quando desenvolvida no Azure:
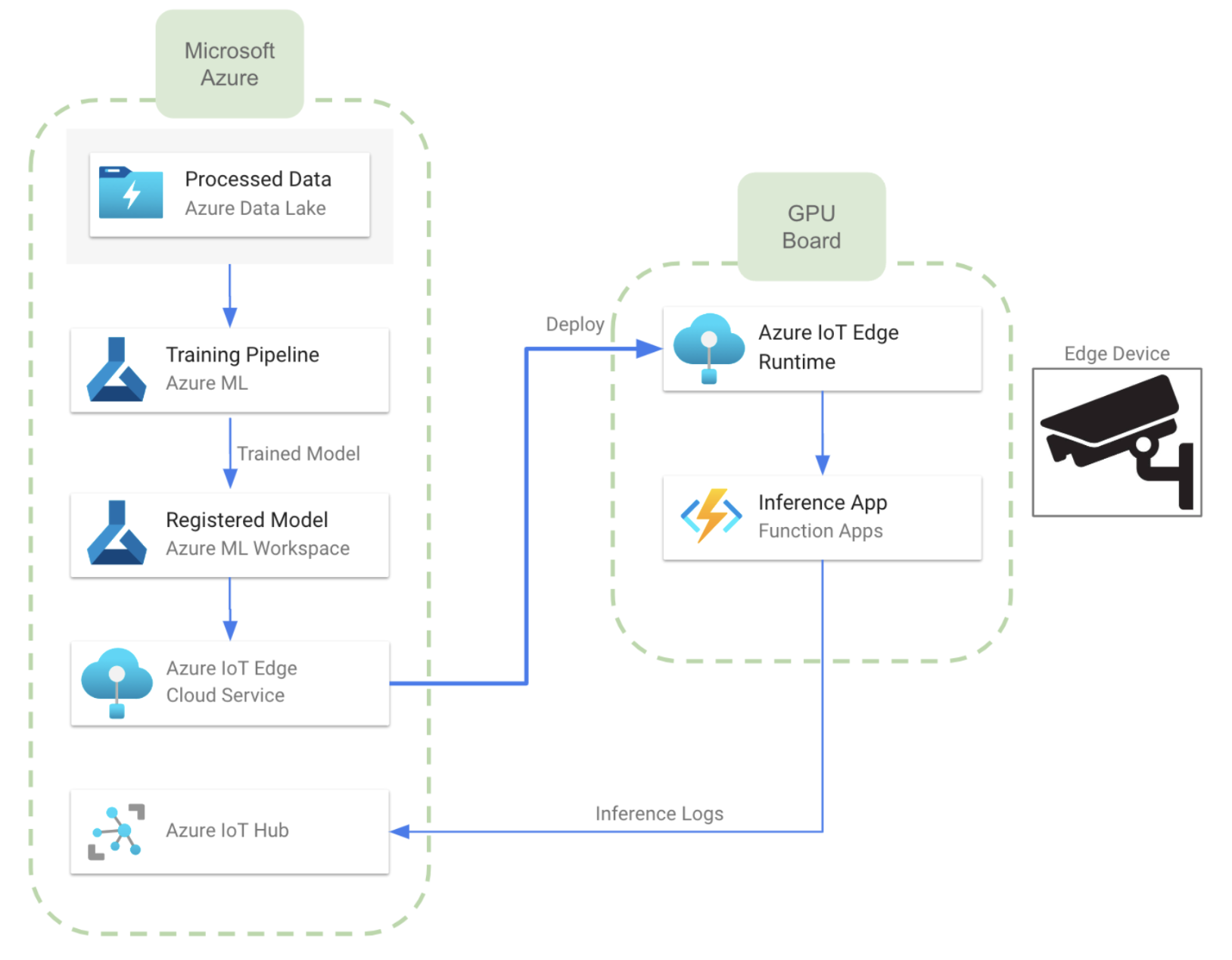
- Nesse caso, podemos treinar o modelo usando os recursos de ML do Azure. Também podemos usar um Azure ML Workspace para controle de versão e armazenamento de modelos. Isso permitirá que o usuário gerencie diferentes versões do mesmo modelo, ou até mesmo modelos diferentes.
- A comunicação entre a nuvem e os dispositivos de borda é realizada pelo serviço Azure IoT Edge. Para isso, precisaremos instalar o tempo de execução do IoT Edge em todos os dispositivos de ponta.
- Depois de transferir o modelo para os dispositivos, podemos implantá-los em uma Função do Azure, como no diagrama acima. Também é possível usar um aplicativo docker em contêiner.
- Semelhante ao caso da AWS, podemos enviar registros de inferência para a nuvem usando o hub de IoT do Azure. Isso fornece conexão bidirecional entre a nuvem e o dispositivo de borda.
Como comentário adicional, uma abordagem alternativa seria usar Azure Stack Edge, que é uma plataforma de computação de ponta gerenciada em nuvem que combina componentes proprietários de hardware e software para levar os serviços e recursos do Azure até a borda. O hardware Stack Edge inclui hardware de aceleração de computação projetado para melhorar o desempenho da inferência de IA na borda e, como os serviços de hardware e nuvem são fornecidos pelo mesmo fornecedor, espera-se que a integração seja perfeita, mas a interoperabilidade na nuvem (com outros fornecedores) pode ser difícil.
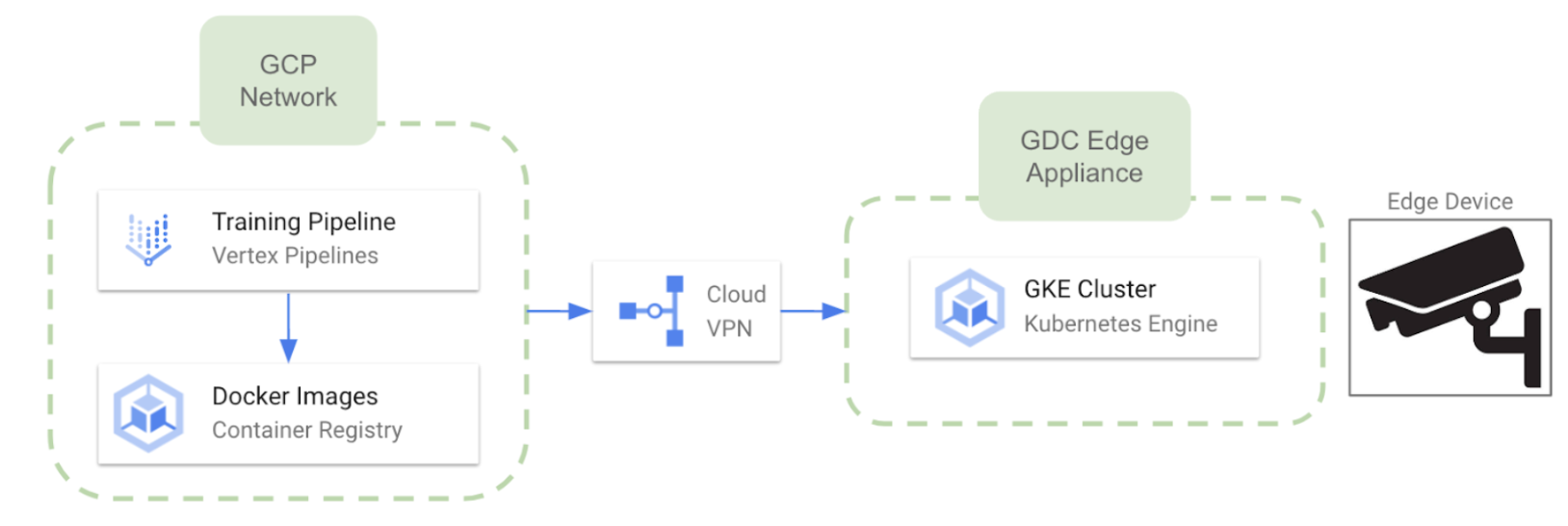
Implantação Edge no Google Cloud Platform
Como o Google decidiu recentemente descontinuar seus serviços IoT Core, podemos esperar uma conexão um pouco mais difícil com dispositivos de ponta em comparação com outros provedores de nuvem. No entanto, é possível alavancar Cloud Edge distribuído do Google que permite executar clusters do Google Kubernetes Engine em hardware dedicado fornecido e mantido pelo Google. O Google entrega e instala o hardware do Distributed Cloud Edge em suas instalações (com limitações de região no momento). Algumas características relevantes sobre essa abordagem são as seguintes:
- O hardware dedicado é Dispositivo Cloud Edge distribuído do Google
- Quando o hardware estiver pronto, podemos implantar vários clusters do GKE no Edge a partir do ambiente GCP.
- A comunicação bidirecional entre a nuvem e os dispositivos está disponível
Alternativas de hardware para aplicativos de computação de ponta
Conforme comentado anteriormente, realizar inferência de aprendizado de máquina nos dispositivos de ponta envolve o uso de algum tipo de acelerador de GPU. Para esse fim, a NVIDIA e o Google Coral oferecem várias alternativas de hardware para selecionar, dependendo das diferentes necessidades de desempenho. O principal objetivo desses dispositivos é levar recursos de computação poderosos ao limite, mantendo uma forma compacta. A seguir está apenas uma lista das possíveis alternativas de hardware disponíveis no mercado:
Série NVIDIA Jetson
- Jetson Nano: Posicionado como um dispositivo básico, o Jetson Nano possui uma GPU compatível com CUDA, permitindo a execução paralela de várias redes neurais. Embalado com várias interfaces de E/S, seu preço começa em $100.
- Jetson Xavier NX: Indo além em recursos de desempenho, o Jetson Xavier NX pode lidar com várias redes neurais e oferece suporte à codificação e decodificação de vídeo 4K. Seu preço começa em aproximadamente $400.
- Jetson AGX Xavier: No topo das ofertas da NVIDIA, o Jetson AGX Xavier tem melhores recursos de hardware em comparação com o Xavier NX. Este módulo topo de linha vem com um preço de cerca de $1000.
Plataforma de computação de ponta do Google Coral
- Conselho de desenvolvimento do Coral: O Coral Dev é um computador de placa única, semelhante a um Raspberry Pi. Com um preço de aproximadamente $130, ele serve como uma plataforma de desenvolvimento para executar e prototipar modelos de IA na borda. Ele é equipado com uma TPU Edge integrada, que facilita a inferência eficiente no dispositivo.
- Acelerador USB Coral: É uma solução de hardware baseada em USB que pode ser conectada a dispositivos existentes, incluindo placas Raspberry Pi. Com um preço de cerca de $60, ele reflete os recursos de TPU Edge do Coral Dev Board, oferecendo uma opção econômica para inferência acelerada no dispositivo.
Conclusões
Um dos principais desafios no campo da IA de computação de ponta é implantar um modelo ou aplicativo treinado em vários dispositivos de forma coordenada. Abordamos algumas alternativas para desenvolver uma estratégia de implantação em diferentes fornecedores de nuvem. Além disso, exploramos algumas alternativas de hardware que desempenham um papel crucial nesse tipo de arquitetura. Seja detecção de objetos em tempo real, reconhecimento facial, segmentação de imagens ou outras tarefas de visão computacional, o objetivo é aproveitar o poder dos aceleradores de GPU e aproximar o aprendizado de máquina dos dispositivos de câmera. Essa abordagem não apenas simplifica o processamento de dados, mas também aprimora a eficiência geral da inferência de aprendizado de máquina no local.



.png)