.png)
DinoV2: Explorando los transformadores de visión autosupervisados




Los transformadores de visión están ganando popularidad rápidamente en el campo de la visión artificial. Estos transformadores, que se basan en los mismos principios que los transformadores utilizados en el procesamiento del lenguaje natural (PNL), han mostrado excelentes resultados en diversas tareas de visión artificial, como la clasificación de imágenes, la detección de objetos, la segmentación, etc.
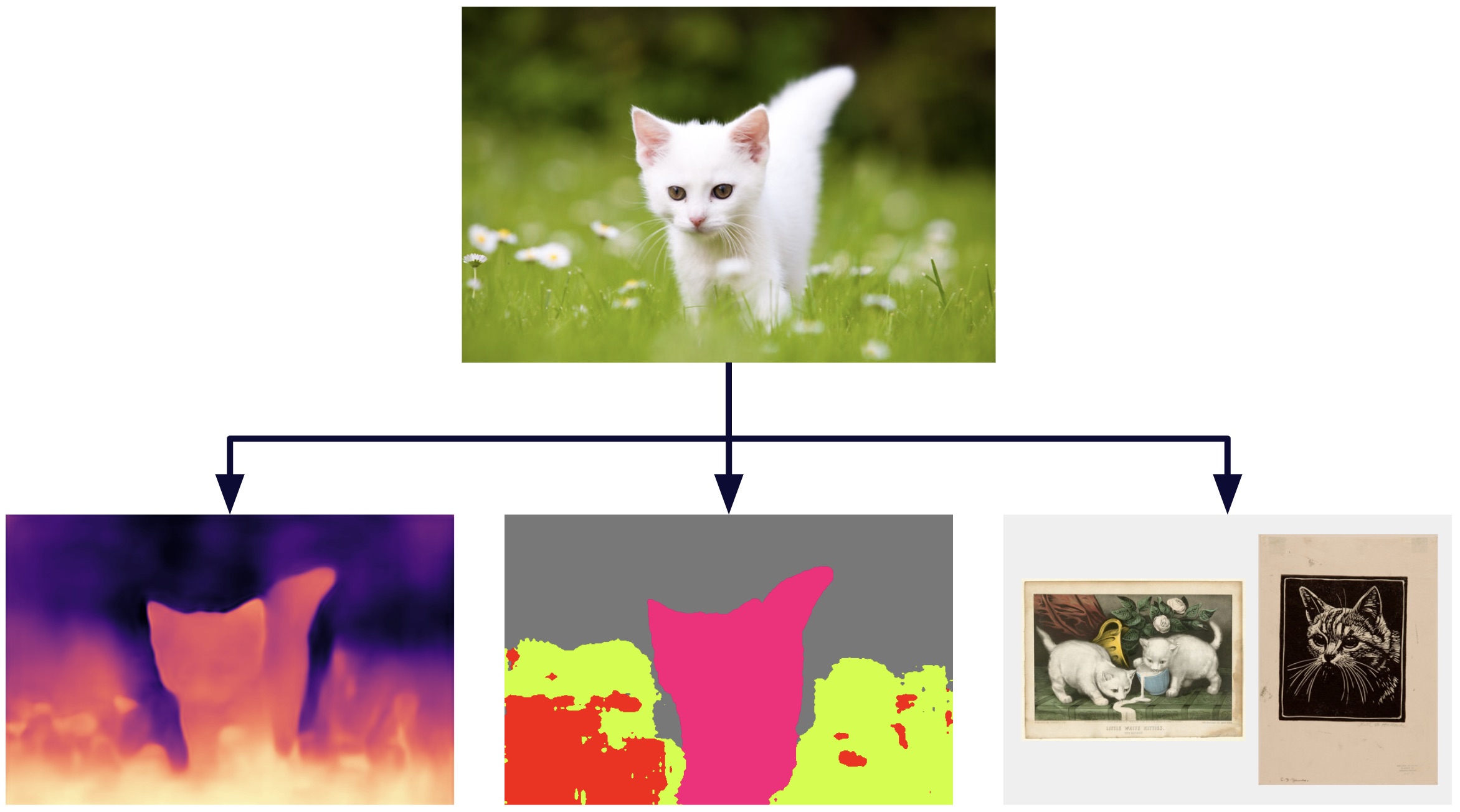
Imagen creada con las salidas de la herramienta que se encuentra en demo de DinoV2 [1]
Al igual que en la PNL, existe la necesidad de un modelo troncal que pueda servir como extractor de características generales para diversas tareas de visión artificial. Este modelo permitiría a los investigadores y profesionales desarrollar modelos más especializados que puedan realizar tareas específicas con mayor precisión y eficiencia.
Recientemente, ha surgido un nuevo transformador de visión llamado DinoV2, que ha mostrado resultados prometedores en el aprendizaje autosupervisado para extraer características importantes de la columna vertebral. Veamos más de cerca los detalles de DinoV2 y veamos cómo ha podido lograr resultados tan impresionantes mediante el aprendizaje autosupervisado.
Una mirada más cercana a DinoV2
DinoV2 (autodestilación sin etiquetas) es un innovador algoritmo de aprendizaje autosupervisado desarrollado por Meta, que mejora la eficiencia y el rendimiento de su predecesor, DINO o DinoV1. Utiliza transformadores de visión (ViT) para extraer conocimiento de las imágenes sin necesidad de datos etiquetados y, además, permite el aprendizaje multimodal. Esto lo convierte en una opción atractiva para quienes buscan reducir la dependencia de los datos etiquetados en el aprendizaje automático y mejorar el rendimiento en las tareas posteriores.
El uso de datos sin etiquetar es una técnica que también se usa comúnmente en el entrenamiento previo de imágenes y texto, esto tiene sus limitaciones. Esta técnica no suele tener en cuenta la información crítica que no se menciona explícitamente en las descripciones de los textos, lo que puede afectar a la capacidad del modelo para aprender ciertos patrones. Además, el proceso de entrenamiento previo entre imágenes y texto puede requerir grandes cantidades de datos etiquetados para entrenar los modelos adecuados, lo que puede resultar costoso y llevar mucho tiempo.
Por ejemplo, si una imagen pertenece a un conjunto de datos de entrenamiento y viene con una descripción detallada, como «Primer plano de una planta que crece por encima del suelo». Los colores dominantes de la imagen son el verde y el amarillo. El fondo es borroso y de color negro verdoso. El entorno parece estar al aire libre o en un bosque, ya que alrededor de la planta hay césped y otra vegetación visible». El algoritmo de aprendizaje automático puede pasar por alto información importante que no se menciona en la descripción, como la posición de la planta en la imagen, el tamaño relativo entre la planta y la imagen, entre otros aspectos. Esto se debe a que el algoritmo aprende a relacionar la imagen con el texto proporcionado y puede pasar por alto otras características visuales relevantes.

En resumen, DinoV2 es una técnica de aprendizaje autosupervisada que no se basa en descripciones de texto para aprender, cuál le permite capturar información más completa y relevante de las imágenes en comparación con otras técnicas que se basan en descripciones de texto.
Si bien DinoV2 usa imágenes que no están etiquetadas, para obtener buenos resultados es clave que la base de datos esté seleccionada. La metodología para obtener una gran base de datos seleccionada se explica a continuación.
Construcción del conjunto de datos
Se creó una base de datos de 142 millones de imágenes llamada LVD-142M, que se extrajeron de un conjunto no curado de 1200 millones de imágenes.
El primer paso del proceso es tomar un conjunto inicial de imágenes, que se seleccionan de 25 conjuntos de datos de terceros, como ImageNet-22k y Google Landmarks. A continuación, se eliminan las imágenes duplicadas. A continuación, procedemos a calcular la incrustación de una imagen utilizando una red autosupervisada de Vit-H/16 previamente entrenada con ImageNet-22K y utilizamos la medida de similitud de cosenos para determinar la distancia entre las imágenes y seleccionar aquellas que sean similares a las que se encuentran en los datos seleccionados. Para realizar esta tarea de manera eficiente, se utilizó la biblioteca Faiss.
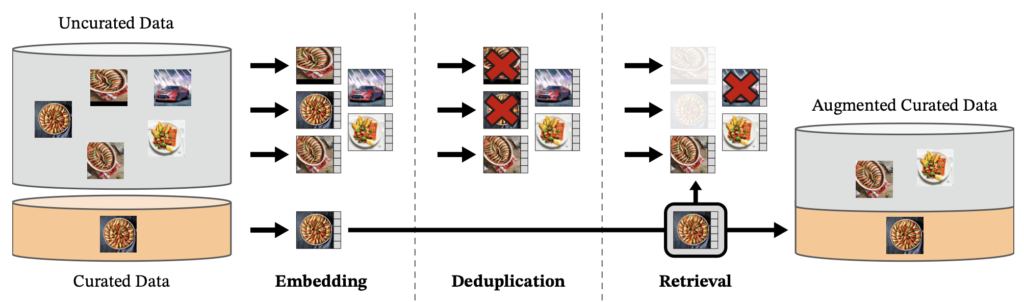
Imagen extraída del artículo oficial de DinoV2 [2]
Cómo funciona
Antes de profundizar en más detalles sobre DinoV2, es importante entender qué son los transformadores visuales. Es por ello que aquí se presenta una breve explicación de los mismos.
Una breve explicación de Visual Transformers (ViT)
En 2017, la arquitectura Transformer se introdujo en el campo del procesamiento del lenguaje natural con el artículo «La atención es todo lo que necesita». Luego, en 2021, se presentó el concepto Vision Transformer (ViT) en la ponencia «Una imagen vale 16*16 palabras». ViT es una adaptación de la arquitectura Transformer para el procesamiento de imágenes, que permite a una red neuronal aprender de grandes conjuntos de datos de imágenes. ViT ha mostrado resultados sobresalientes en una variedad de tareas y, en algunos casos, puede ser una alternativa a las redes convolucionales.
En los VIT, las imágenes de entrada se tratan como una secuencia de parches en la que cada parche se aplana en un solo vector concatenando los canales de todos los píxeles de un parche y, a continuación, se proyecta linealmente en la dimensión de entrada deseada.
Exploremos los pasos:
- Divida una imagen en parches.
- Aplana los parches.
- Produzca incrustaciones lineales de dimensiones más pequeñas a partir de los parches aplanados.
- Agregue incrustaciones posicionales.
- Utilice la secuencia como entrada para un codificador de transformador estándar.
- Entrene previamente el modelo con etiquetas de imagen en el caso del aprendizaje supervisado, que es el más común. Sin embargo, a continuación se explica cómo DinoV2 utiliza los transformadores de visión en el aprendizaje autosupervisado.
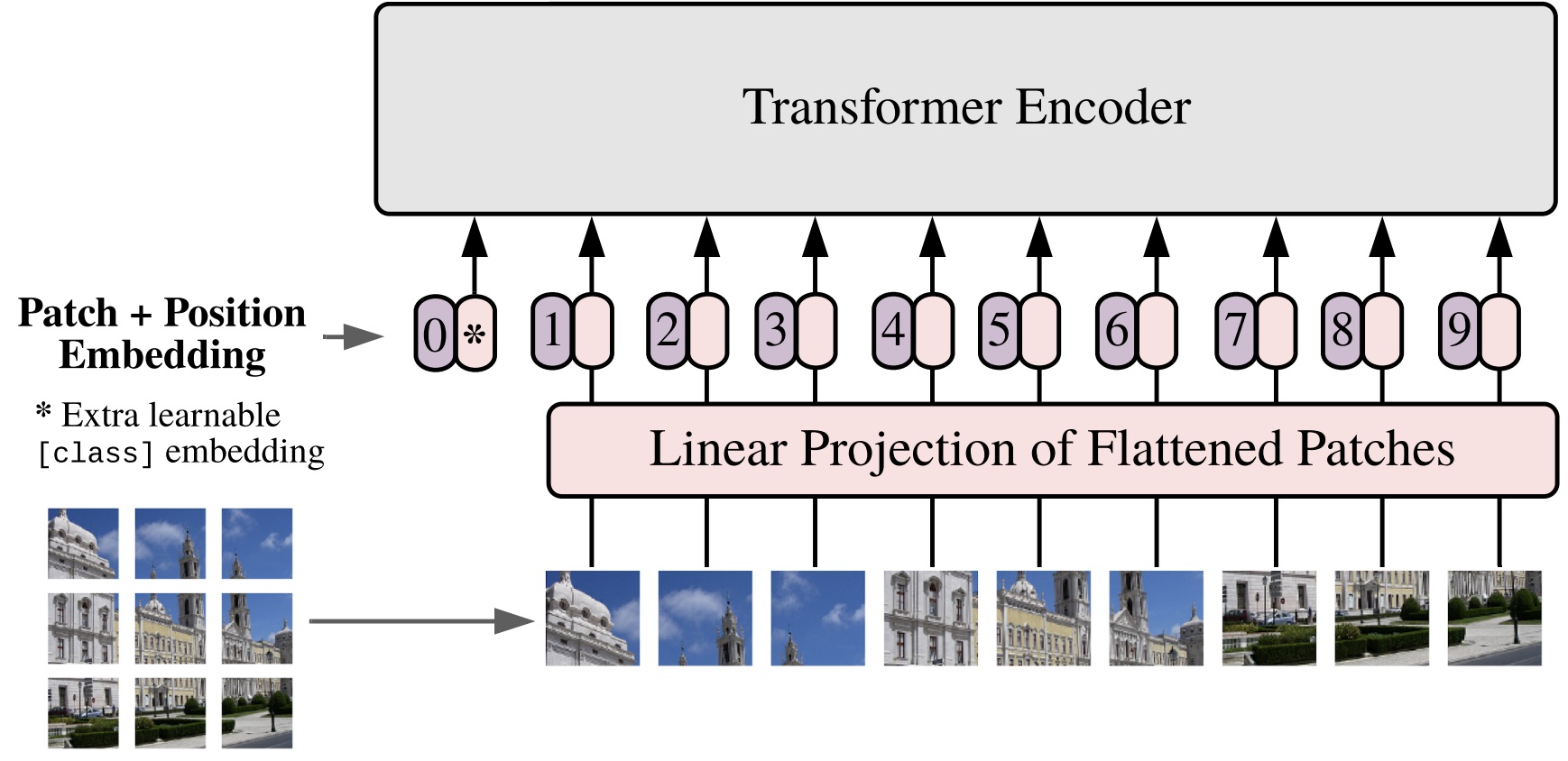
Imagen extraída del documento de presentación de Vision Transformers [3]
Conceptos básicos del funcionamiento de DinoV2
La red troncal de DinoV2 consiste en una red de transformadores que procesa la entrada de imágenes y genera una representación vectorial de alta dimensión que captura las características relevantes de la imagen. Esta representación vectorial es común a todas las tareas de visión artificial que se puede realizar con DinoV2. El modelo tiene mil millones de parámetros y se aplicó la autodestilación para generar modelos más pequeños, lo que dio como resultado cuatro modelos finales: VIt-small, vit-base y vit-large, que se obtuvieron de la versión VIT-Giant.
El cabezal DinoV2 se adapta a la tarea específica que se está realizando y está conectado al extremo de la columna vertebral. Por ejemplo, si se está realizando una clasificación de imágenes, el cabezal consistiría en una capa de clasificación lineal que tomaría la representación vectorial generada por la columna vertebral y la utilizaría para clasificar la imagen en diferentes categorías. Si se realiza la detección de objetos, el cabezal consistiría en una red de detección que utiliza la representación vectorial para localizar y clasificar los objetos de la imagen.
En resumen, DinoV2 tiene una columna vertebral común a todas las tareas de visión artificial y un cabezal que se adapta a la tarea específica que se está realizando.
Objetivo a nivel de imagen, objetivo a nivel de parche y más
DinoV2 combina elementos clave de DinoV1 e IBot, incluidos los conceptos de un objetivo a nivel de imagen, un objetivo a nivel de parche, diferencias de peso entre ambos objetivos y más. A continuación, proporcionaremos una breve explicación, empezando por uno de los conceptos más importantes.
Objetivo a nivel de imagen: Se utilizan dos tipos de redes neuronales, una red de profesores y una red de estudiantes, ambas con la misma arquitectura pero con parámetros diferentes. La arquitectura consiste en una red troncal (ViT o ResNet) y un cabezal de proyección que consiste en un perceptrón multicapa (MLP) de tres capas.
Para capacitar a la red de estudiantes, se utiliza el concepto de «destilación del conocimiento». Este enfoque implica capacitar a la red de estudiantes para que imite los resultados de la red de profesores, permitiendo así que la red de estudiantes adquiera los conocimientos de la red de profesores.
En la primera etapa de la capacitación, se generan diferentes visiones globales y locales de menor resolución. Todas estas vistas o recortes se transmiten como información a la red de estudiantes, mientras que solo las vistas globales se utilizan como entrada a la red de profesores. Esto anima a la red de estudiantes a aprender las correspondencias locales y globales.
Luego, con la red neuronal del profesor fija, la función de costo de entropía cruzada se minimiza para que la red de estudiantes copie con precisión la red del profesor. El SGD (Stochastic Gradient Descent) se utiliza como optimizador.
A diferencia del enfoque clásico de destilación del conocimiento, DinoV2 no utiliza una red de profesores preexistente. En cambio, se emplea un método de aprendizaje autosupervisado en el que la red de profesores se construye a partir de iteraciones anteriores de la red de estudiantes utilizando una media móvil exponencial (EMA).
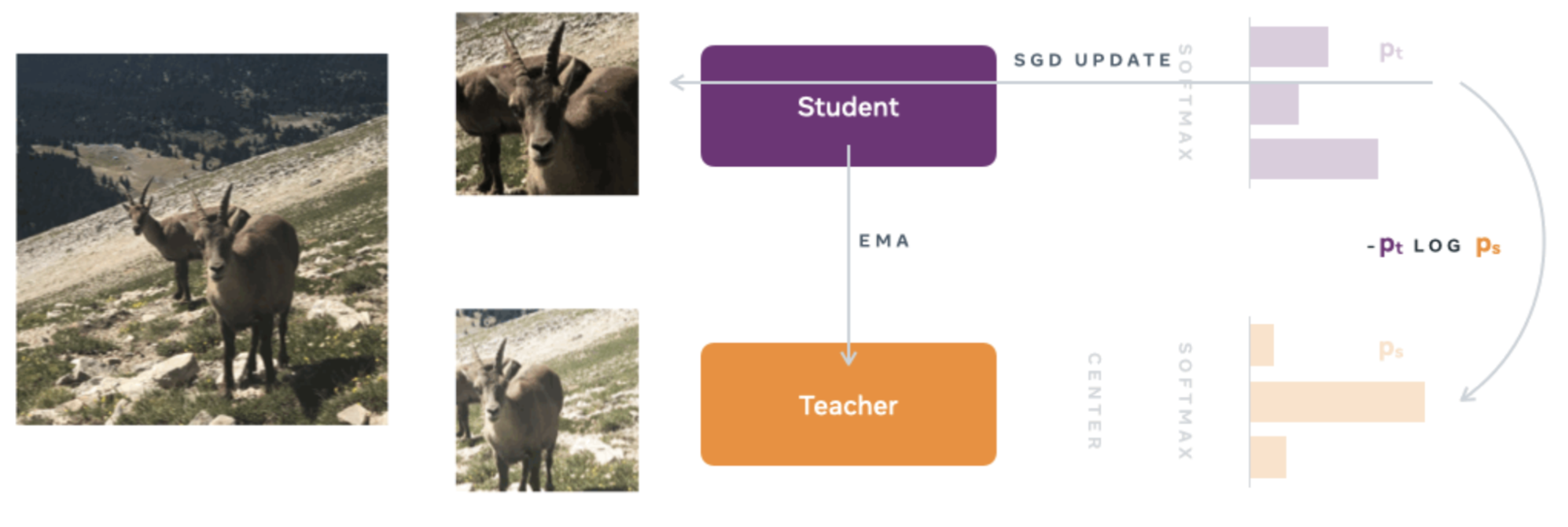
Imagen extraída del blog oficial de DinoV1 [4]
El resto de conceptos utilizados en DinoV2 se explican a continuación.
Objetivo a nivel de parche: algunos parches de la imagen están ocultos/enmascarados para la red de estudiantes, pero no para la red de profesores, y luego se calcula la entropía cruzada entre las características de los dos parches. Esta función de coste se combina con la que se explicó anteriormente en el apartado «Objetivo a nivel de imagen».
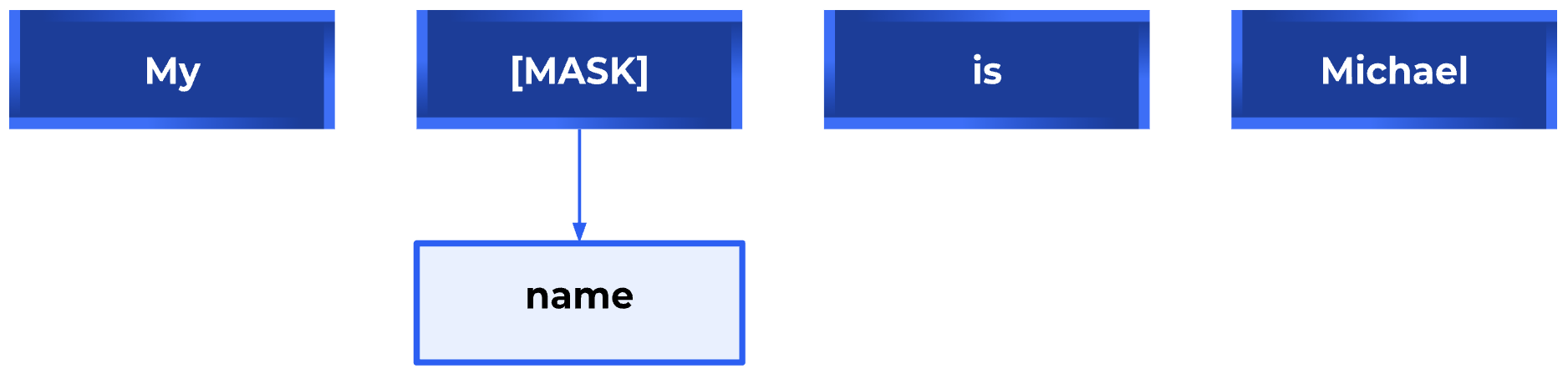
Cabe destacar la relación entre el enmascaramiento de imágenes o parches, también conocido como modelado de imágenes enmascaradas (MIM), y el modelado de lenguaje enmascarado (MLM) utilizado en la PNL. MLM es para Transformers en PNL lo que MIM es para Vision Transformers. Al igual que en el MLM, donde se enmascara una parte del texto y se usa para predecir la palabra que falta, en el MIM, una parte de la imagen se oculta o se enmascara y se usa para predecir la parte oscurecida, utilizando el resto de la imagen como contexto. En ambos casos, el objetivo es aprender una representación densa y continua del texto o la imagen que capture el significado y la relación semántica entre las palabras o los píxeles.
Ejemplo de modelado de lenguaje enmascarado
Ejemplo de modelado de imágenes enmascaradas

extraído del artículo de SimMim [5]
Por lo tanto, tanto el MLM como el MIM son técnicas que permiten a los modelos de aprendizaje profundo en NLP y Computer Vision, respectivamente, capturar mejor la información contextual de los datos de entrada y mejorar su capacidad para realizar tareas específicas, como la generación de texto o la reconstrucción de imágenes, entre otras.
Desvincular los pesos de cabeza entre ambos objetivos: Si los pesos (o parámetros) de la red neuronal asociados a ambos objetivos (a nivel de imagen y a nivel de parche) están empatados, la red puede no ajustarse adecuadamente en la tarea de clasificación a nivel de parche y sobreajustarse en la tarea de clasificación a nivel de imagen. La desvinculación de estos pesos resuelve este problema y mejora el rendimiento de la red en ambas tareas.
Adaptación de la resolución de la imagen: El aumento de la resolución de la imagen es importante para tareas detalladas como la segmentación o la detección de objetos pequeños, pero la formación en alta resolución requiere mucho tiempo y memoria. En su lugar, aumentamos la resolución de la imagen a 518 x 518 al final del entrenamiento previo durante un breve período de tiempo.
Conceptos adicionales: El artículo menciona conceptos más específicos que sirvieron para obtener buenos resultados, como la sugerencia de utilizar un método diferente para normalizar los datos en el proceso de entrenamiento de ciertos algoritmos. En lugar de utilizar la técnica actual de centraje softmax de la red de profesores en DinoV1 e IBot, se propone utilizar una técnica llamada Sinkhorn-Knopp (SK) para normalizar por lotes otro algoritmo llamado Swav. También se recomienda utilizar la norma L2 y luego aplicar el regularizador KoLeo. Para obtener más información, consulte el documento «DinoV2: aprendizaje de funciones visuales sólidas sin supervisión» [2].
DinoV2 en acción
Como se mencionó anteriormente, DinoV2 utiliza representaciones vectoriales o incrustaciones de alta dimensión para extraer conocimiento de las imágenes. Esta información se puede utilizar en varias modalidades, incluida la estimación de profundidad, la segmentación semántica y la recuperación de instancias. A continuación, mostramos algunos ejemplos de estas aplicaciones. También puedes ver una demostración oficial de DinoV2 en dinov2.metademolab.com [1], donde se generaron los siguientes ejemplos.

Estimación de profundidad
⇒


Segmentación semántica
⇒


Recuperación de instancias
⇒


Conclusiones y próximos pasos
En conclusión, DinoV2 es un poderoso marco de aprendizaje autosupervisado que permite el entrenamiento de transformadores de visión como columna vertebral para la comprensión de imágenes. La posibilidad de obtener una columna vertebral previamente entrenada y añadir un cabezal para tareas específicas sin necesidad de etiquetar exhaustivamente es una ventaja significativa.
El éxito de DinoV2 destaca el potencial del aprendizaje autosupervisado para desarrollar modelos de aprendizaje profundo más avanzados y versátiles. La investigación futura en áreas relacionadas, como el Segment Anything Model (SAM), el Track Anything Model (TAM) y el Caption Anything Model (CAM), podrían contribuir al desarrollo de modelos aún más sofisticados.
Referencias
Referencias mencionadas explícitamente en este blog:
- Demo oficial de DinoV2
- «DinoV2: aprendizaje de funciones visuales sólidas sin supervisión» (Artículo de DinoV2)
- «Una imagen vale 16x16 palabras: transformadores para el reconocimiento de imágenes a escala» (Documento de presentación de Vision Transformers)
- Blog oficial de DinoV1
- «SimMim: un marco simple para el modelado de imágenes enmascaradas»
Fuentes valiosas adicionales:



.png)