.png)
DinoV2: Explorando transformadores de visão autosupervisionados




Os transformadores de visão estão rapidamente ganhando popularidade no campo da visão computacional. Esses transformadores, baseados nos mesmos princípios dos transformadores usados no processamento de linguagem natural (PNL), têm mostrado excelentes resultados em várias tarefas de visão computacional, como classificação de imagens, detecção de objetos, segmentação e muito mais.
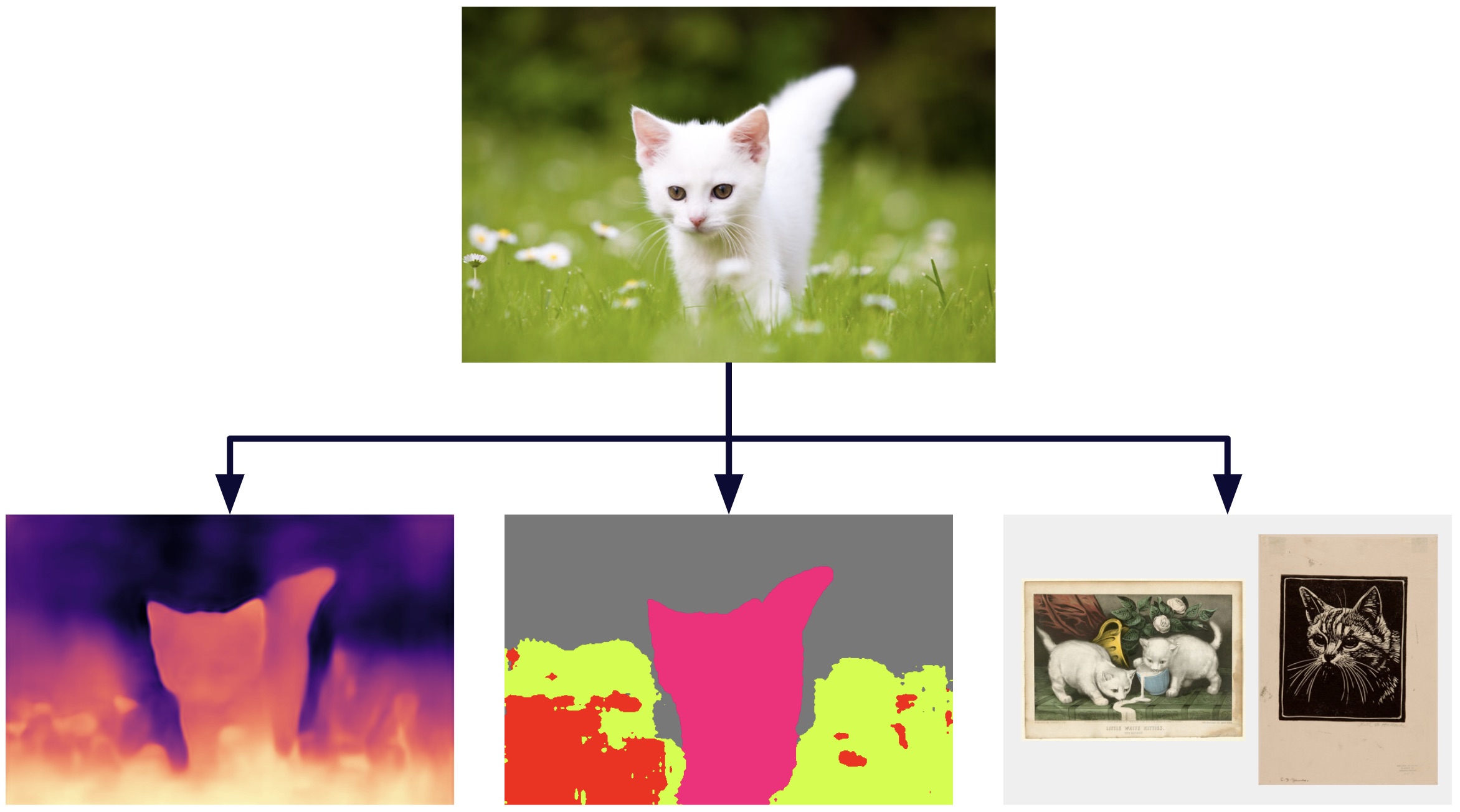
Imagem criada com as saídas da ferramenta encontrada no demonstração do DinoV2 [1]
Assim como na PNL, há a necessidade de um modelo de backbone que possa servir como um extrator de recursos gerais para várias tarefas de visão computacional. Esse modelo permitiria que pesquisadores e profissionais desenvolvessem modelos mais especializados que podem realizar tarefas específicas com melhor precisão e eficiência.
Recentemente, surgiu um novo transformador de visão chamado DinoV2, que mostrou resultados promissores no aprendizado autosupervisionado para extrair características importantes na espinha dorsal. Vamos examinar mais de perto os detalhes do DinoV2 e como ele conseguiu alcançar resultados tão impressionantes por meio do aprendizado autosupervisionado.
Uma análise mais detalhada do DinoV2
O DinoV2 (autodestilação com rótulos NO) é um algoritmo inovador de aprendizado autosupervisionado desenvolvido pela Meta, que melhora a eficiência e o desempenho de seu antecessor, DINO ou DinoV1. Ele usa transformadores de visão (ViT) para extrair conhecimento de imagens sem a necessidade de dados rotulados e, além disso, permite o aprendizado multimodal. Isso o torna uma opção atraente para quem busca reduzir a dependência de dados rotulados no aprendizado de máquina e melhorar o desempenho em tarefas posteriores.
O uso de dados não rotulados é uma técnica que também é comumente usada no pré-treinamento de imagem e texto, mas tem suas limitações. Essa técnica geralmente não considera informações críticas que não são explicitamente mencionadas nas descrições do texto, o que pode afetar a capacidade do modelo de aprender certos padrões. Além disso, o processo de pré-treinamento de imagem e texto pode exigir grandes quantidades de dados rotulados para treinar modelos adequados, o que pode ser caro e demorado.
Por exemplo, se uma imagem pertencer a um conjunto de dados de treinamento e vier com uma descrição detalhada, como “Imagem aproximada de uma planta crescendo acima do solo. As cores dominantes na imagem são verde e amarelo. O fundo está desfocado e preto esverdeado. O ambiente parece estar ao ar livre ou em uma floresta, pois há grama e outra vegetação visível ao redor da planta”, o algoritmo de aprendizado de máquina pode perder informações importantes que não são mencionadas na descrição, como a posição da planta na imagem, o tamanho relativo entre a planta e a imagem, entre outros aspectos. Isso ocorre porque o algoritmo aprende a relacionar a imagem ao texto fornecido e pode perder outros recursos visuais relevantes.

Em resumo, DinoV2 é uma técnica de aprendizado autosupervisionado que não depende de descrições de texto para aprender, que permite capturar informações mais completas e relevantes das imagens em comparação com outras técnicas que dependem de descrições de texto.
Embora o DinoV2 use imagens que não estão rotuladas, para obter bons resultados, é fundamental que o banco de dados seja organizado. A metodologia para obter um grande banco de dados com curadoria é explicada abaixo.
Construção do conjunto de dados
Foi criado um banco de dados de 142 milhões de imagens chamado LVD-142M, que foram extraídas de um conjunto não selecionado de 1,2 bilhão de imagens.
A primeira etapa do processo é obter um conjunto inicial de imagens, que são selecionadas de 25 conjuntos de dados de terceiros, como ImageNet-22k e Google Landmarks. Em seguida, as imagens duplicadas são removidas. Em seguida, procedemos ao cálculo de uma incorporação de imagem usando uma rede autossupervisionada vit-H/16 previamente treinada com ImageNet-22k e usamos a medida de similaridade de cosseno para determinar a distância entre as imagens e selecionar aquelas que são semelhantes às encontradas nos dados selecionados. Para realizar essa tarefa de forma eficiente, foi utilizada a biblioteca Faiss.
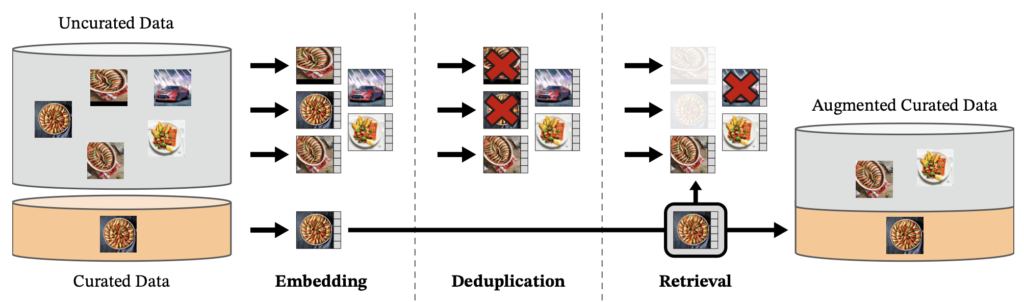
Imagem extraída do papel oficial de DinoV2 [2]
Como funciona
Antes de mergulhar em mais detalhes sobre o DinoV2, é importante entender o que são os Transformadores Visuais. É por isso que uma breve explicação deles é apresentada aqui.
Uma breve explicação dos Transformadores Visuais (ViT)
Em 2017, a arquitetura Transformer foi introduzida no campo do processamento de linguagem natural com o artigo “Atenção é tudo que você precisa”. Então, em 2021, o conceito Vision Transformer (ViT) foi apresentado no artigo “Uma imagem vale 16*16 palavras”. O ViT é uma adaptação da arquitetura Transformer para processamento de imagens, permitindo que uma rede neural aprenda com grandes conjuntos de dados de imagens. O ViT tem mostrado excelentes resultados em uma variedade de tarefas e pode ser uma alternativa às redes convolucionais em alguns casos.
Em VitS, as imagens de entrada são tratadas como uma sequência de patches em que cada patch é achatado em um único vetor por meio da concatenação dos canais de todos os pixels em um patch e, em seguida, projetado linearmente na dimensão de entrada desejada.
Vamos explorar as etapas:
- Divida uma imagem em patches.
- Alise os adesivos.
- Produza incorporações lineares de dimensões menores a partir das manchas achatadas.
- Adicione incorporações posicionais.
- Use a sequência como entrada para um codificador de transformador padrão.
- Pré-treine o modelo com rótulos de imagem no caso de aprendizado supervisionado, que é o mais comum. No entanto, é explicado abaixo como o DinoV2 usa transformadores de visão no aprendizado autosupervisionado.
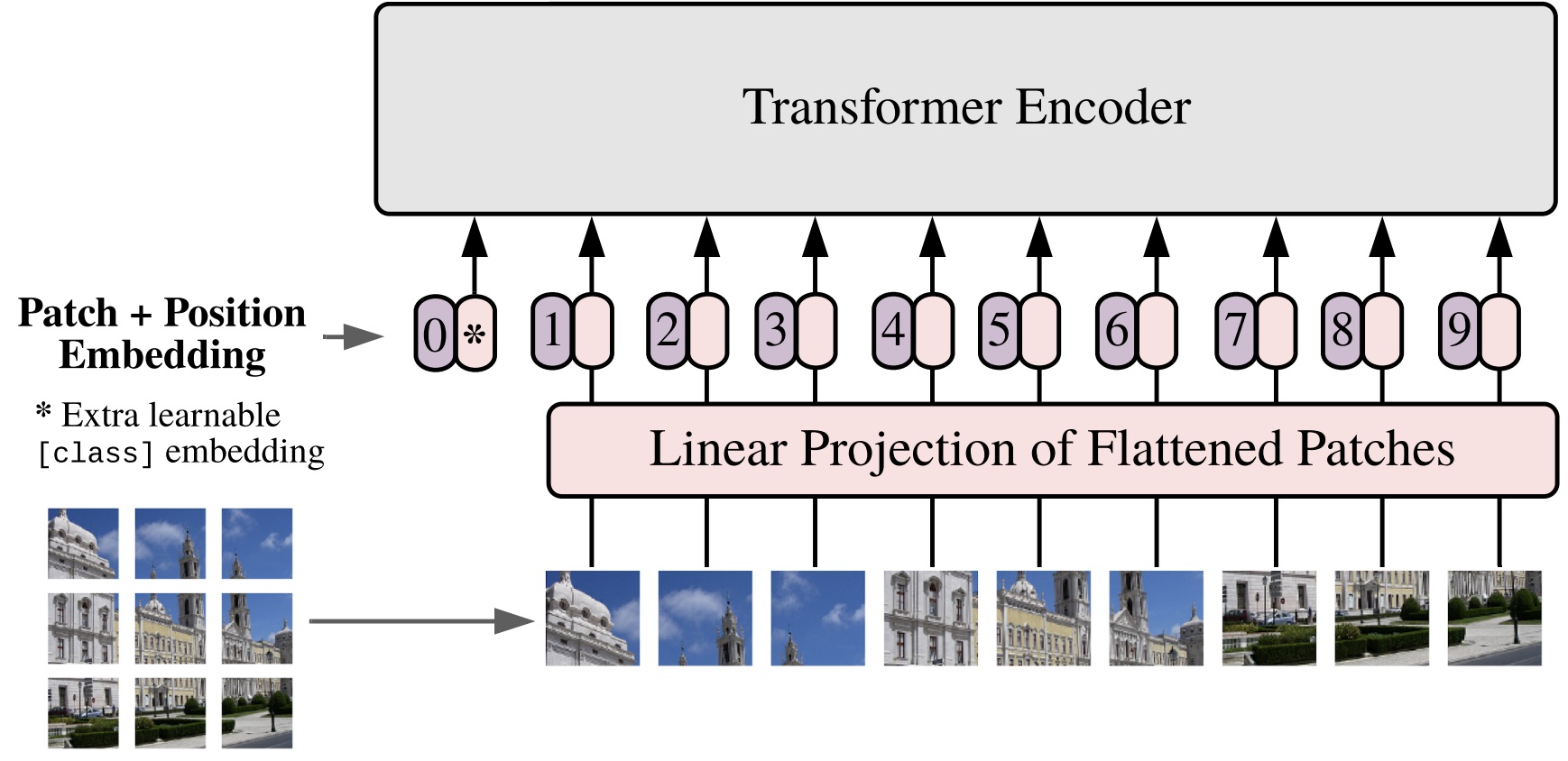
Imagem extraída do artigo apresentando os Vision Transformers [3]
Fundamentos da operação do DinoV2
O backbone DinoV2 consiste em uma rede de transformadores que processa a entrada de imagem e gera uma representação vetorial de alta dimensão que captura as características relevantes da imagem. Essa representação vetorial é comum a todas as tarefas de visão mecânica. que pode ser executado com DinoV2. O modelo tem 1 bilhão de parâmetros e a autodestilação foi aplicada para gerar modelos menores, resultando em quatro modelos finais: Vit-Small, Vit-base e Vit-Large, que foram obtidos da versão VIT-Giant.
A cabeça DinoV2 é adaptada à tarefa específica que está sendo executada e é conectada à extremidade do backbone. Por exemplo, se a classificação da imagem estiver sendo realizada, a cabeça consistirá em uma camada de classificação linear que pega a representação vetorial gerada pelo backbone e a usa para classificar a imagem em diferentes categorias. Se a detecção de objetos estiver sendo realizada, a cabeça consistirá em uma rede de detecção que usa a representação vetorial para localizar e classificar objetos na imagem.
Em resumo, o DinoV2 tem uma espinha dorsal comum a todas as tarefas de visão computacional e uma cabeça que se adapta à tarefa específica que está sendo executada.
Objetivo em nível de imagem, objetivo em nível de patch e muito mais
O DinoV2 combina os principais elementos do DinoV1 e do iBot, incluindo os conceitos de uma objetiva em nível de imagem, uma objetiva em nível de patch, pesos de cabeça desvinculados entre os dois objetivos e muito mais. Abaixo, forneceremos uma breve explicação, começando com um dos conceitos mais cruciais.
Objetivo em nível de imagem: Dois tipos de redes neurais são usados, uma rede de professores e uma rede de estudantes, ambas com a mesma arquitetura, mas com parâmetros diferentes. A arquitetura consiste em um backbone (ViT ou ResNet) e uma cabeça de projeção que consiste em um perceptron multicamada (MLP) de três camadas.
Para treinar a rede de estudantes, o conceito de “Destilação do conhecimento” é usado. Essa abordagem envolve treinar a rede de alunos para imitar a produção da rede de professores, permitindo que a rede de alunos adquira o conhecimento da rede de professores.
Na primeira etapa do treinamento, diferentes visões globais e locais de baixa resolução são geradas. Todas essas visões ou colheitas são passadas como entrada para a rede de estudantes, enquanto somente as visões globais são usadas como entrada para a rede de professores. Isso incentiva a rede estudantil a aprender correspondências locais e globais.
Então, com a rede neural do professor fixa, a função de custo de entropia cruzada é minimizada para que a rede do aluno copie com precisão a rede do professor. O SGD (Stochastic Gradient Descent) é usado como otimizador.
Ao contrário da abordagem clássica de destilação de conhecimento, o DinoV2 não usa uma rede de professores pré-existente. Em vez disso, um método de aprendizado autosupervisionado é empregado no qual a rede de professores é construída a partir de iterações anteriores da rede de alunos usando uma média móvel exponencial (EMA).
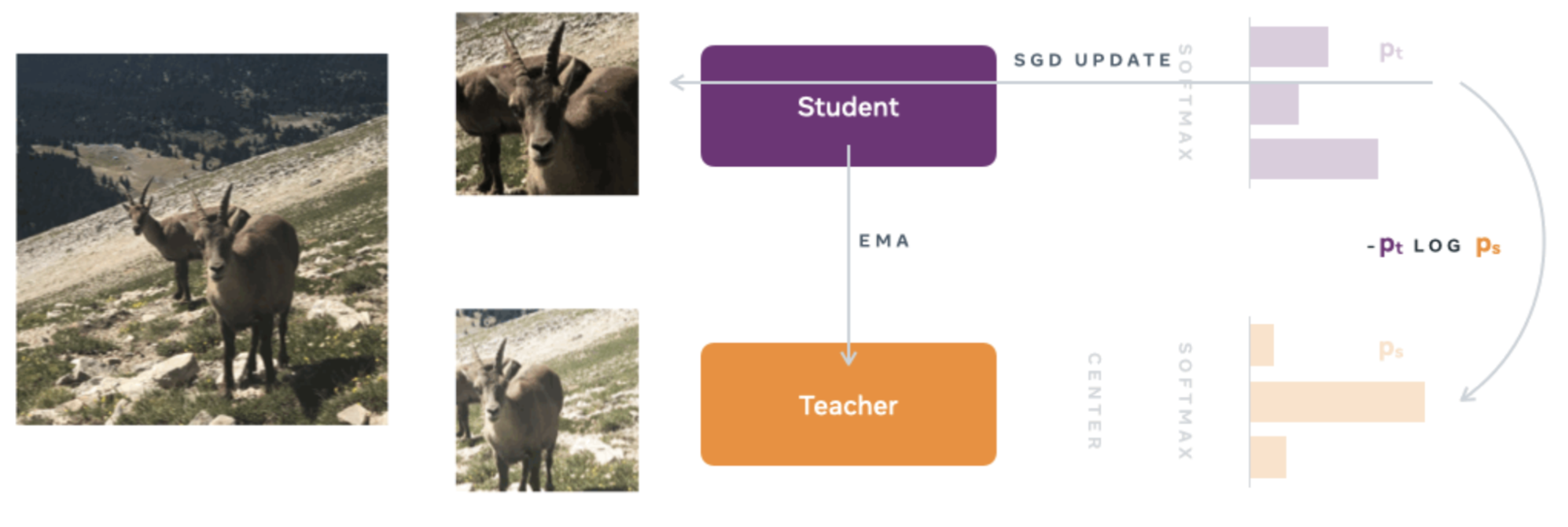
Imagem extraída do blog oficial de DinoV1 [4]
Os demais conceitos usados no DinoV2 são explicados abaixo.
Objetivo em nível de patch: alguns trechos da imagem são ocultados/mascarados para a rede de alunos, mas não para a rede de professores, e então a entropia cruzada entre as características dos dois patches é calculada. Essa função de custo é combinada com a explicada anteriormente em “objetivo em nível de imagem”.
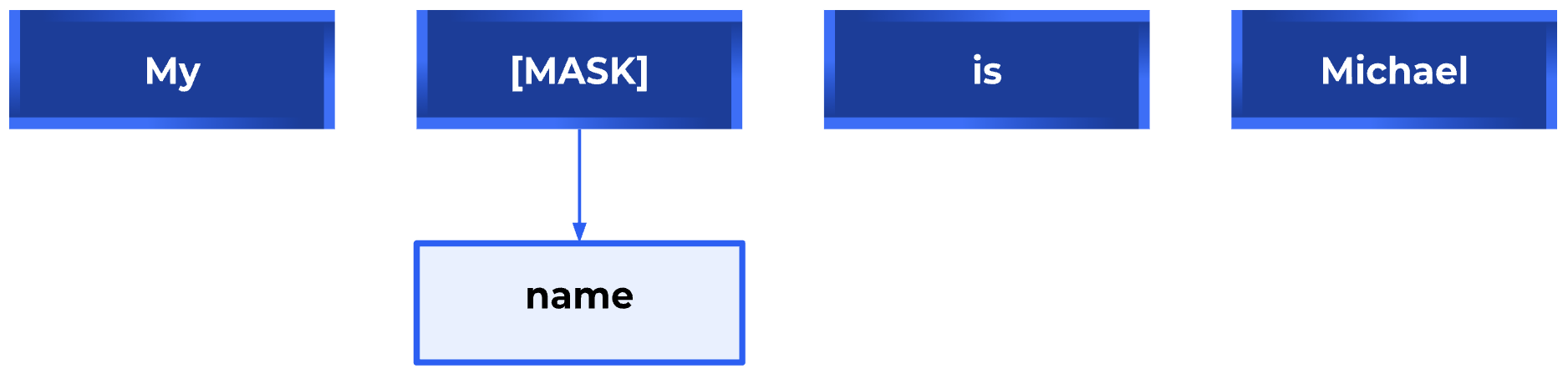
Vale a pena observar a relação entre o mascaramento de imagens ou patches — também conhecido como Masked Image Modeling (MIM) — e o Masked Language Modeling (MLM) usado na PNL. O MLM é para os Transformers na PNL o que o MIM é para os Vision Transformers. Assim como no MLM, em que uma parte do texto é mascarada e usada para prever a palavra que falta, no MIM, uma parte da imagem é oculta ou mascarada e usada para prever a parte obscurecida, usando o resto da imagem como contexto. Em ambos os casos, o objetivo é aprender uma representação densa e contínua do texto ou imagem que capture o significado e a relação semântica entre as palavras ou pixels.
Exemplo de modelagem de linguagem mascarada
Exemplo de modelagem de imagem mascarada

extraído do papel de SimMim [5]
Portanto, tanto o MLM quanto o MIM são técnicas que permitem que modelos de aprendizado profundo em PNL e Visão Computacional, respectivamente, capturem melhor as informações contextuais dos dados de entrada e melhorem sua capacidade de realizar tarefas específicas, como geração de texto ou reconstrução de imagens, entre outras.
Desvincular os pesos da cabeça entre os dois objetivos: Se os pesos (ou parâmetros) da rede neural associados a ambos os alvos (nível da imagem e nível do patch) estiverem vinculados, a rede poderá se encaixar menos na tarefa de classificação em nível de patch e, ao mesmo tempo, se encaixar demais na tarefa de classificação em nível de imagem. A desvinculação desses pesos resolve esse problema e melhora o desempenho da rede em ambas as tarefas.
Adaptando a resolução da imagem: Aumentar a resolução da imagem é importante para tarefas detalhadas, como segmentação ou detecção de objetos pequenos, mas o treinamento em alta resolução é demorado e consome muita memória. Em vez disso, aumentamos a resolução da imagem para 518x518 no final do pré-treinamento por um curto período de tempo.
Conceitos adicionais: O artigo menciona conceitos mais específicos que serviram para obter bons resultados, como a sugestão de usar um método diferente para normalizar os dados no processo de treinamento de determinados algoritmos. Em vez de usar a técnica atual de centralização softmax da rede de professores no DinoV1 e no iBot, propõe-se usar uma técnica chamada normalização em lote Sinkhorn-Knopp (SK) de outro algoritmo chamado sWAV. Também é recomendado usar a norma L2 e depois aplicar o regularizador KoLeo. Para obter mais detalhes, consulte o artigo “DinoV2: Aprendendo recursos visuais robustos sem supervisão” [2].
DinoV2 em ação
Conforme mencionado anteriormente, o DinoV2 usa representações vetoriais de alta dimensão ou incorporações para extrair conhecimento das imagens. Essas informações podem ser utilizadas em várias modalidades, incluindo estimativa de profundidade, segmentação semântica e recuperação de instâncias. Abaixo, mostramos alguns exemplos desses aplicativos. Você também pode explorar uma demonstração oficial do DinoV2 em dinov2.metademolab.com [1], onde os exemplos abaixo foram gerados.

Estimativa de profundidade
⇒


Segmentação semântica
⇒


Recuperação de instâncias
⇒


Conclusões e próximas etapas
Em conclusão, o DinoV2 é uma poderosa estrutura de aprendizado autosupervisionado que permite o treinamento de transformadores de visão como espinha dorsal para a compreensão de imagens. A capacidade de obter uma espinha dorsal pré-treinada e adicionar uma cabeça para tarefas específicas sem a necessidade de rotulagem extensiva é uma vantagem significativa.
O sucesso do DinoV2 destaca o potencial do aprendizado autosupervisionado para o desenvolvimento de modelos de aprendizado profundo mais avançados e versáteis. Pesquisas futuras em áreas relacionadas, como Segment Anything Model (SAM), Track Anything Model (TAM) e Caption Anything Model (CAM), podem contribuir para o desenvolvimento de modelos ainda mais sofisticados.
Referências
Referências explicitamente mencionadas neste blog:
- Demonstração oficial do DinoV2
- “DinoV2: Aprendendo recursos visuais robustos sem supervisão” (Artigo do DinoV2)
- “Uma imagem vale 16X16 palavras: transformadores para reconhecimento de imagem em grande escala” (Artigo apresentando os Vision Transformers)
- Blog oficial de DinoV1
- “SimMim: uma estrutura simples para modelagem de imagens mascaradas”
Fontes valiosas adicionais:



.png)